
Flinkcdc单表同步,checkpoint一会儿大一会儿小这个正常?什么原理?
Flinkcdc单表同步,checkpoint一会儿大一会儿小这个正常?什么原理?并且ck对应的shared目录快10g越来越大,单表同步设置ttl会影响数据最终的准确性?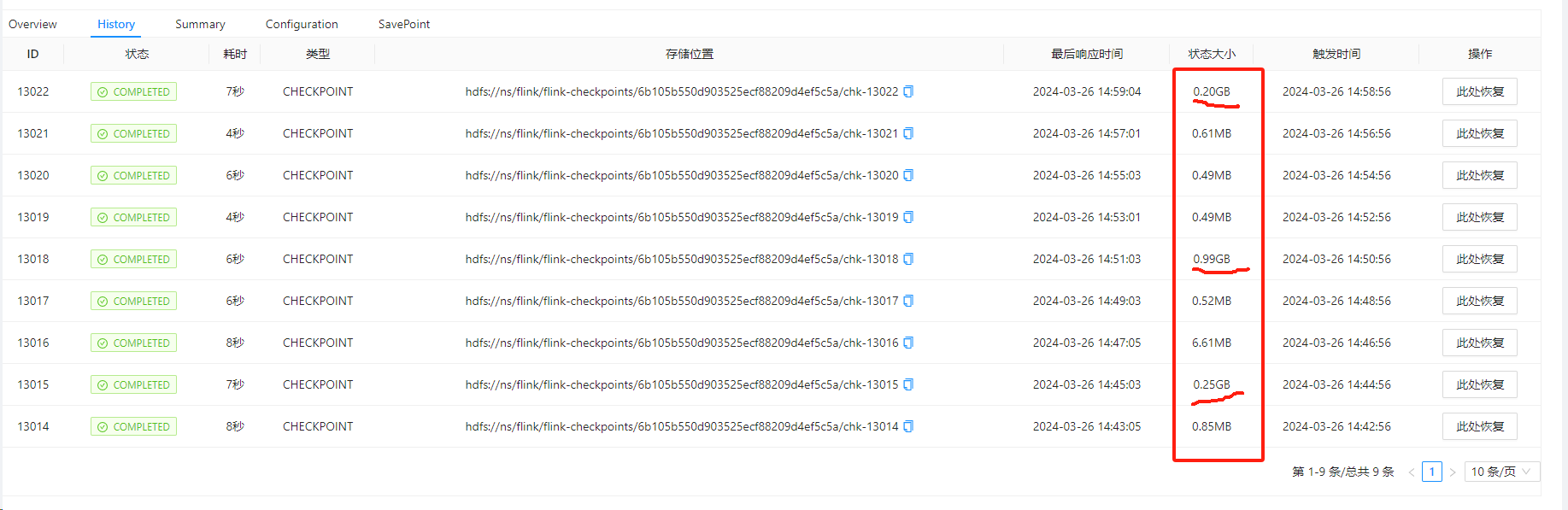
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
1. Flink CDC 单表同步时,Checkpoint 大小波动是否正常?
在 Flink CDC 单表同步过程中,Checkpoint 的大小出现波动是正常现象,具体原因如下:
-
全量与增量阶段的切换:
在全量数据读取阶段,Checkpoint 主要记录的是全量数据的状态信息。当进入增量数据读取阶段后,Checkpoint 记录的是增量数据的状态(如 MongoDB 的 Resume Token 或 MySQL 的 Binlog 位点)。由于全量和增量阶段的数据量差异较大,Checkpoint 的大小可能会出现显著波动。 -
增量快照机制:
如果启用了增量快照功能(如 Postgres CDC),Flink 会在全量数据读取完成后逐步切换到增量模式。在此过程中,Checkpoint 的大小会受到全量数据处理进度的影响。例如,在全量数据未完全写入下游时,Checkpoint 可能会包含较大的状态信息;而在增量阶段,Checkpoint 的大小通常会趋于稳定。 -
缓存与算子状态:
Python UDF 或其他算子内部可能存在缓存,这些缓存中的数据需要在 Checkpoint 时被持久化。如果缓存大小动态变化,也会导致 Checkpoint 大小的波动。
因此,Checkpoint 大小的波动通常是正常的,尤其是在全量与增量切换阶段或数据注入不均匀的情况下。
2. Checkpoint 对应的 shared 目录越来越大,如何解决?
原因分析
-
状态存储引擎的影响:
Flink 使用状态存储引擎(如 GeminiStateBackend)来管理 Checkpoint 数据。如果使用的是 VVR 8.x 版本,GeminiStateBackend 的 V4 引擎可能会对旧版本的状态数据进行兼容性处理,导致状态文件逐渐增大。 -
全量与增量状态的累积:
在全量数据同步阶段,Checkpoint 会记录所有源表的状态信息。如果全量数据量较大,且增量阶段的状态未及时清理,shared 目录的大小会持续增长。 -
TTL 配置缺失:
如果未为状态设置 TTL(Time-to-Live),历史状态数据将不会被自动清理,从而导致 Checkpoint 文件不断累积。
解决方案
-
启用状态 TTL:
为状态设置 TTL,确保过期的状态数据能够被自动清理。例如:CREATE TABLE your_table ( ... ) WITH ( 'state.ttl' = '1d' -- 设置状态的生存时间为1天 );这可以有效减少 Checkpoint 文件的大小,但需要注意 TTL 的设置可能会影响数据的最终一致性。
-
优化 Checkpoint 配置:
- 调整
execution.checkpointing.interval参数,缩短 Checkpoint 的时间间隔,避免单次 Checkpoint 包含过多状态数据。 - 启用增量 Checkpoint(Incremental Checkpoint),仅保存状态的增量部分,从而减少 Checkpoint 文件的增长速度。
- 调整
-
定期清理历史 Checkpoint:
配置 Flink 的state.backend.fs.memory-threshold和state.backend.fs.cleanup参数,限制 Checkpoint 文件的保留时间和数量。例如:state.backend.fs.cleanup: true state.backend.fs.retention: 7d -- 保留最近7天的 Checkpoint 文件 -
升级状态存储引擎:
如果使用的是 VVR 6.x 版本,建议升级到 VVR 8.x,以利用更高效的状态存储引擎(如 GeminiStateBackend V4),减少状态文件的大小。
3. 单表同步中设置 TTL 是否会影响数据的最终准确性?
影响分析
- TTL 的作用:
TTL 用于设置状态的生存时间,超过指定时间的状态数据会被自动清理。这可以有效减少 Checkpoint 文件的大小,但可能会导致以下问题:- 数据丢失风险:
如果某些状态数据在 TTL 到期前未被处理,可能会被误删,从而影响数据的最终一致性。 - 恢复能力受限:
当作业从 Checkpoint 恢复时,如果某些状态数据已被清理,可能会导致恢复失败或数据不完整。
- 数据丢失风险:
解决方案
-
合理设置 TTL:
根据业务需求设置合理的 TTL 值,确保状态数据在被清理前已完全处理。例如,对于低延迟场景,可以设置较短的 TTL;而对于高可靠性场景,则应适当延长 TTL。 -
结合增量快照:
如果启用了增量快照功能,可以通过增量 Checkpoint 减少状态数据的累积,从而降低对 TTL 的依赖。 -
监控与调优:
定期监控 Checkpoint 文件的大小和状态数据的清理情况,根据实际运行情况调整 TTL 和其他相关参数。
总结
- Checkpoint 大小波动 是正常现象,尤其是在全量与增量切换阶段。
- shared 目录增长 可通过启用 TTL、优化 Checkpoint 配置和定期清理历史文件来解决。
- 设置 TTL 可能会影响数据的最终准确性,需根据业务需求合理配置,并结合增量快照功能进行优化。

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。