
使用flink on yarn的模式,怎么进行内存资源调优呢,如何配置flink内存
使用了三台机器搭建flink on yarn,想在生产环境进行调优,如何设置呢,或者说怎么调优最为合理,配置文件如何去修改,还请社区中有经验的大佬指教
-

在生产环境中对Flink on YARN进行调优,首先需要明确Flink on Yarn的运行模式有两种:Yarn Session和Flink run。其中,Yarn Session是先在Yarn上启动一个Flink集群,然后向该集群提交Flink任务;而Flink run则是每次提交任务时,在Yarn上新创建一个Flink集群,用于运行该任务,每个任务在一个独立的Flink集群上跑。
资源配置:为任务分配合适的资源是性能调优的第一步。在一定范围内,增加资源的分配与性能的提升是成正比的。提交方式主要是yarn-per-job,资源的分配在使用脚本提交Flink任务时进行指定。理解Flink中的计算资源的核心概念,如Slot、Chain、Task等,有助于我们快速定位生产中的问题。
并行度和资源设置:并行度和资源的配置调优是经常要面对的工作之一。为了控制一个TaskManager能接受多少个task,Flink提出了Task Slot的概念。经验公式如下:slot个数 × tm个数 = 并行度,其中并行度 = kafka的分区个数(例如10分区)。slot的个数应小于yarn设置的单个container最大可以申请的cpu核数(例如5个),因此可以设置为5个slot × 2个tm = 并行度 = kafka分区数。
集群选择:在选择集群大小时,需要考虑任务之间的影响。多个小集群意味着任务分布在不同的集群中,一个任务占用过高的cpu不会导致整个集群重启,从而避免集群中所有任务失败。但同时,管理多个小集群的压力可能会增大。
2024-01-09 09:53:26赞同 展开评论 打赏 -
 面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。在使用Flink on yarn模式进行内存资源调优时,可以配置Flink的参数来优化内存使用。以下是一些关键参数的配置指导:
JobManager参数:
jobmanager.heap.mb:用于设置JobManager的堆内存大小,一般建议不要配置得太大,1-2G足够。jobmanager.rpc.address:指定JobManager的地址。jobmanager.rpc.port:指定JobManager的端口。
TaskManager参数:
taskmanager.heap.mb:用于设置TaskManager的堆内存大小,大小应根据任务量进行合理的配置。taskmanager.numberOfTaskSlots:指定TaskManager的slot数量,在yarn模式下会受到yarn.scheduler.maximum-allocation-vcores值的影响。taskmanager.memory.process.size:用于配置Flink TaskManager任务的总内存,Flink框架会根据默认比例划分各个区域的内存,但有时默认划分可能不适应特定需求,因此可能需要手动调整以避免资源浪费。
资源配置:
- 提交方式可以选择
yarn-per-job,并在使用脚本提交Flink任务时指定资源分配。为任务分配合适的资源是性能调优的第一步,适当增加资源的分配通常与性能提升成正比。确保实现了最优资源配置后,再考虑进一步的性能调优策略。
- 提交方式可以选择
通过合理配置上述参数,您可以更好地优化Flink on yarn模式下的内存资源使用,从而提高任务执行效率和性能。
2024-01-08 13:46:18赞同 展开评论 打赏 -

在生产环境中对 Flink on YARN 进行调优时,主要目标是确保资源的有效利用、提升系统稳定性和作业执行性能。以下是一些关键配置项及其调整策略:
1. YARN 配置
- ResourceManager(RM)和NodeManager(NM)配置:
- 确保 YARN 能够分配足够的容器给 Flink 应用程序。
- 调整
yarn.scheduler.minimum-allocation-mb和yarn.scheduler.maximum-allocation-mb来设定单个容器可申请的最小和最大内存。 - 设置
yarn.nodemanager.resource.memory-mb和yarn.nodemanager.resource.cpu-vcores定义每个节点上可用的总资源。
2. Flink 配置
JobManager(JM)配置:
jobmanager.rpc.address: 指定 JobManager 的主机地址。jobmanager.heap.mb: 设置 JobManager 的堆内存大小,根据实际需求调整。yarn.application-master.vcores: JobManager 在 YARN 上申请的核心数。
TaskManager(TM)配置:
taskmanager.memory.process.size: TaskManager 的总内存大小,包括 JVM 堆内存和其他开销(如直接内存、元空间等)。taskmanager.numberOfTaskSlots: 每个 TaskManager 分配的 slot 数量,影响并发任务的数量,可根据集群 CPU 核心数来调整。yarnslots: 在 Flink on YARN 中,指定每个 TM 向 YARN 申请的 container 数量或资源量。taskmanager.cpu.cores: 指定每个 TaskManager 可使用的 CPU 核心数。
3. 网络与 I/O 调优
- 如果数据传输是一个瓶颈,可以考虑优化网络参数,比如启用 Netty 的高性能网络栈。
4. 检查点与状态后端
- 根据作业的状态大小和恢复时间要求,设置合理的检查点频率和超时时间。
- 选择合适的 state backend(如 RocksDB 或 FsStateBackend),并合理配置其内存和磁盘空间使用。
5. 容器资源分配
- 根据作业类型(批处理还是流处理)、作业特性(是否计算密集型或I/O密集型)以及硬件资源情况,合理分配每个 TaskManager 的内存和 CPU 资源。
6. 监控与日志
- 开启 Flink 的 metrics 监控,并接入 Grafana 或 Prometheus 等工具进行可视化监控,以便实时了解集群运行状况。
- 设置适当的日志级别,以方便问题排查。
具体配置文件修改通常涉及
flink-conf.yaml文件,对于 Flink on YARN,则可能还需要通过命令行参数或者提交作业时的 YAML 配置文件来传递特定于 YARN 的属性。示例配置命令行参数:
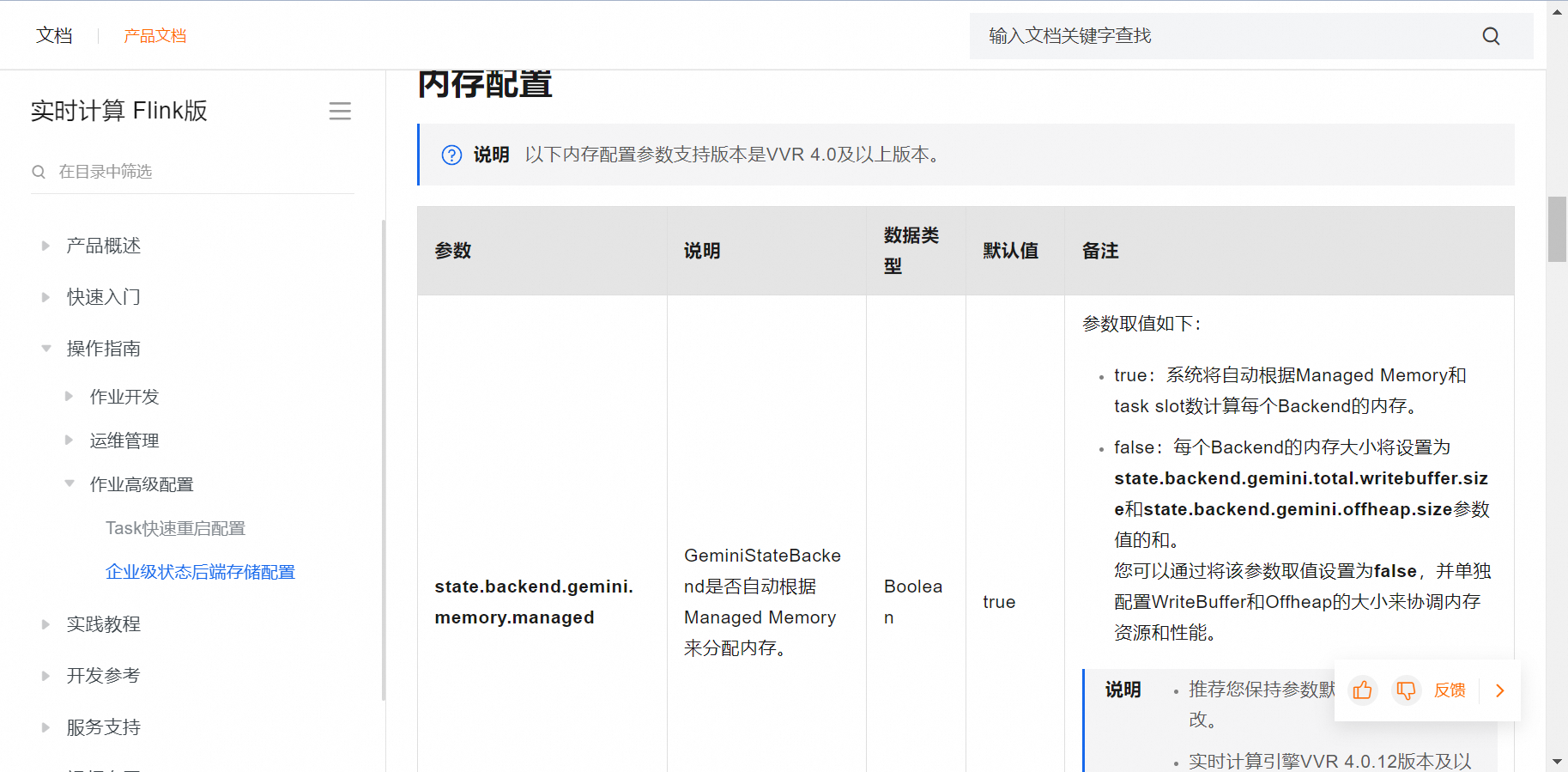
./bin/flink run -m yarn-cluster -yn <number-of-tasks> -ys <slots-per-task-manager> -yjm <job-manager-memory> -ytm <task-manager-memory> ...请查阅最新的 Flink 文档获取更准确的配置信息,并结合实际负载测试进行逐步调优。定期分析作业运行历史记录,根据实际情况动态调整资源配置,达到最优效果。https://help.aliyun.com/zh/flink/user-guide/configurations-of-geministatebackend?spm=a2c4g.11186623.0.i8#section-i2y-bs9-2dg
 2024-01-08 10:49:54赞同 展开评论 打赏
2024-01-08 10:49:54赞同 展开评论 打赏 - ResourceManager(RM)和NodeManager(NM)配置:

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。




