GetSentry-Snuba
ClickHouse 简单来说它就是一个实时大数据分析引擎,并且相当的牛逼😂。
ClickHouse 中文手册
为什么选择 Snuba?
Sentry 已经在名为 Search,Tagstore(用于事件标签)和 TSDB(时间序列数据库,为大多数图形提供动力)的抽象服务接口上运行。这些服务中的每一个都有自己的生产实现,这些实现由标准关系性 SQL(用于 Search 和 Tagstore )和 Redis(用于 TSDB )支持,这些服务在 Sentry 中已经使用了很多年。
我们的问题始于 Sentry 扩大其客户群和工程团队。一方面,我们每天每秒收到更多事件。另一方面,我们有更多的工程师试图为 Sentry 开发更多功能。
事件量的增加意味着我们必须对大量数据进行非规范化处理,以便可以非常快速地执行已知查询。例如,Tagstore 由五个不同的表组成,记录值(recording values),例如 Sentry 上每个 issue 的每个标签值的 times_seen 计数(您的一个 issue 中可能有一个 browser.name 标签,值为 Chrome 的 times_seen 为 10,值为 Safari 的 times_seen 为 7)。这些非规范化计数器的增量被缓冲,因此我们可以合并它们,最终降低写压力。

通过缓冲到非规范化计数器的增量来降低写压力
这对我们很有用,直到我们想添加一个新的维度来进行查询,比如 environment。重构现有的数据布局以在一个全新的维度上反规范化花费了我们几个月的时间,并且需要对所有事件数据进行完整的回填。

添加 environment 维度意味着重构现有的数据布局,这会引起问题。
很明显,我们需要一个在线分析处理(OLAP)提供的平面事件模型,这个模型可以在没有任何非规范化的情况下进行临时查询。它需要足够快的速度来满足用户的请求,并且当我们想要添加另一种方式让用户查看他们的数据时,不需要对后端进行检修。
当时,我们想到了 Facebook 的专栏商店 Scuba,因为它解决了类似的问题,但它是闭源的。我们的团队和项目需要一个名字,因为我们不像 Scuba 那么成熟,所以就诞生了 Snuba ( snorkel 和 Scuba 的合成词)。
Scuba 论文地址:Scuba: Diving into Data at Facebook
为什么不仅仅分割(Shard)Postgres?
负责聚合和提供 tag 计数的主要数据集(称为 “Tagstore” )达到了一个临界点,即执行的突变数量超过了我们在单个 Postgres 机器上复制它们的能力。我们将其扩展到一组机器上,但却被一组用硬件无法解决的问题所拖累。我们需要一种每当发现新的数据维度时就减少基础设施工作的方法,而不是一种扩展当前数据集的方法。尽管我们有 Postgres 方面的专业知识,我们还是决定是时候扩展到 OLAP 系统了。
在一长串切换到 OLAP 的理由中,以下是我们最喜欢的一些:
- 在大多数情况下,我们的数据是不可变的。Multiversion 并发控制使用的安全机制对我们没有用,最终降低了我们的性能。
- 计算数据的另一个维度或从产品中引入另一种查询形式意味着向 Postgres Query Planner 编写新的 indices 和新的 prayers 以利用它们。
- 删除已过期超过保留窗口的数据意味着对批量删除行发出昂贵的查询。
- 传入和传出行的大量出现对Postgres主堆造成了影响。IO被浪费在梳理死行以找到活行上,并且承载这些数据库的磁盘在缓慢但稳定地增长。
为什么选择 ClickHouse?
我们在 OLAP 场景中研究了许多数据库,包括:Impala、Druid、Pinot、Presto、Drill、BigQuery、Cloud Spanner 和 Spark Streaming。这些都是正在积极开发的功能强大的系统,自 2018 年初以来,每种系统的具体优缺点可能已经发生了变化。我们最终选择了 ClickHouse,因为我们让新成立的搜索和存储团队的工程师们各自为 snuna 在不同系统上的表现做了原型。
这就是 ClickHouse 脱颖而出的原因:
- 它是开源的。我们是开源的。选择专有解决方案会使在我们领域以外运行 Sentry 的每个人都感到冷漠。
- 无论是
scale-up还是scale-down,操作都很简单。它本身不需要任何额外的服务,只引入了ZooKeeper作为复制控制的一种手段。一旦我们了解了它的部署,我们就花了一天时间开始将Sentry 的整个事件volume写入单个集群。 - 行基于主键排序,列单独存储并压缩在物理文件中。这使得 Tagstore 背后的数据在磁盘上从
tb字节变为gb字节。 - 实时写入后即可查询数据。始终如一的读取能力使我们能够将所有为
Alert Rules(警报规则)提供支持的查询移至Snuba,这大约占每秒发出的查询的40%。 query planner没有什么魔力。如果我们想优化查询模式,ClickHouse 提供的解决方案虽然很少,但是很有效。最重要的是,由于强大的过滤条件,它们提供PREWHERE子句的能力使我们能够跳过大量数据。
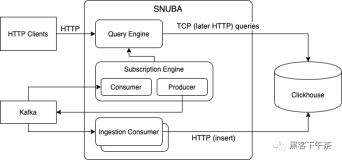
Snuba 内部
Snuba 是一个由两部分组成的服务,旨在将 ClickHouse 与 Sentry 分离开来。除了应用程序代码和 ClickHouse 之外,我们还利用了一些其他的帮助服务来完成 Sentry 的事件数据流。


Sentry 数据流
读(Reading)
Snuba 的查询服务器由 Flask web service 提供支持,该服务使用 JSON schema 为 Sentry 开发人员提供丰富的查询接口。通过提供一个 Snuba client 而不是直接使用 ClickHouse SQL,我们可以向应用程序开发人员隐藏很多潜在的复杂性。例如,这个 Snuba query 获取过去24小时内发送给项目的最流行的标签:
{ "project": [1], "aggregations": [ ["count()", "", "count"] ], "conditions": [ ["project_id", "IN", [1]], ], "groupby": ["tags_key"], "granularity": 3600, "from_date": "2019-02-14T20:10:02.059803", "to_date": "2019-05-15T20:10:02.033713", "orderby": "-count", "limit": 1000 }
转换为相应的 ClickHouse 风格的 SQL 查询:
SELECT arrayJoin(tags.key) AS tags_key, count() AS count FROM sentry_dist PREWHERE project_id IN 1 WHERE (project_id IN 1) AND (timestamp >= toDateTime('2019-02-14T20:10:02')) AND (timestamp < toDateTime('2019-05-15T20:10:02')) AND (deleted = 0) GROUP BY tags_key ORDER BY count DESC LIMIT 0, 1000
呈现这个更高级别的 Snuba 查询接口 — 而不是鼓励应用程序开发人员直接与 ClickHouse 交互 — 使我们的团队能够保持对 Snuba 内部底层数据模型的更改,而不是要求开发人员在迭代时不断更改查询。
此外,我们现在进行集中更改,这些更改会影响各种各样的不同查询模式。例如,我们使用 Redis 缓存单个查询结果,这会将我们一些更突发和频繁重复的查询合并到单个 ClickHouse 查询中,并从 ClickHouse 集群中消除了不必要的负载。
写(Writing)
向 Snuba 写入数据首先要从 Kafka 主题(topic)中读取 JSON 事件,这些事件已经经过了 Sentry 的规范化和处理步骤。它以批处理方式处理事件,将每个事件转换为映射到单个ClickHouse 行的元组。批量插入 ClickHouse 非常关键,因为每次插入都会创建一个新的物理目录,其中每个列都有一个文件,ZooKeeper 中也有相应的记录。这些目录会被 ClickHouse 的后台线程合并,建议你每秒写一次,这样就不会有太多对 ZooKeeper 或磁盘文件的写操作需要处理。数据是根据时间(time)和留存窗口(retention window)进行划分的,这让我们能够轻松删除超出原始留存窗口的数据。