首先简单介绍下场景:数据是每个月一份的csv文件,字段数目10个左右,单个文件记录数约6-8亿之间,单个文件体积50G+的样子。表中是一条条的带有时间字段的数据,需求是对数据进行汇总统计和简单分析处理(一般而言,数据量巨大的需求处理逻辑都不会特别复杂)。所以,虽然标题称之为大数据,但实际上也没有特别夸张。
01 大数据读取
pandas自带了常用文件的读取方法,例如csv文件对应的读取函数即为pd.read_csv,这也是日常应用中经常接触的方法。然而对于处理这个50G的csv文件而言,直接使用是肯定不行的,当前个人电脑内存普遍在8G-16G内存之间,笔者的是一台8G内存的工作机,除去系统占用基本留给用于加载数据的空间不到6G,另一方面通过多次试验结果:对于一个2G的文件,读取过程中内存占用会达到4G左右,大概是实际文件体积的两倍,加载完毕之后会有有所回落。所以,就8G内存的工作机而言,读取一个2.5G的大文件本身已经存在一定风险。
为此,pandas开发者专为此设计了两组很有用的参数,分别用于控制行和列信息:
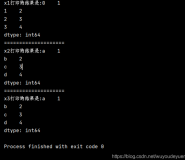
- skiprows + nrows,前者用于控制跳过多少行记录,后者用于控制读取行数,skiprows默认值为0,nrows缺省读取所有行数,这也是最常用的方式。但合理的设置两个参数,可以实现循环读取特定范围的记录
- usecols:顾名思义,仅加载文件中特定的列字段,非常适用于列数很多而实际仅需其中部分字段的情况,要求输入的列名实际存在于表中

pd.read_csv()中相关参数说明
具体到实际需求,个人实现时首先通过循环控制skiprows参数来遍历整个大文件,每次读取后对文件再按天分割,同时仅选取其中需要的3个列字段作为加载数据,如此一来便实现了大表到小表的切分。虽然受限于内存而执行效率有限,但也终究算是一种解决方案。
02 内存管理
仍然是循环读取大文件分表的问题,对于每次循环,读取一个大文件到内存,执行完相应处理流程后,显式执行以下两行代码即可,实测效果很有用。
del xx gc.collect()
03 时间字段的处理
给定的大文件中,时间字段是一个包含年月日时分秒的字符串列,虽然在read_csv方法中自带了时间解析参数,但对于频繁多次应用时间列进行处理时,其实还有更好的方法:转为时间戳。
例如,在个人的实际处理中主要用到的操作包括:按时间排序、按固定周期进行重采样、分组聚合统计等,这几个操作中无一例外都涉及到时间列的比较,如果是字符串格式或者时间格式的时间列,那么在每次比较中实际要执行多次比较,而如果转换为时间戳后,则参与比较的实际上是一个整数值,毫无疑问这是效率最高的比较类型。进一步地,对于重采样需求而言,还可以通过整除特定的时间间隔,然后执行groupby操作即可。例如,执行每5分钟重采样,则可将所有时间戳(秒级)整除300,然后以相应结果作为groupby字段即可。
这里,补充两种将时间格式转换为时间戳的具体实现方法:
# 假设df['dt']列是时间格式,需将其转换为时间戳格式 # 方法一: df['dt'] = (pd.to_datetime(df['dt'])-pd.to_datetime('1970-01-01T08:00:00')).total_seconds() # 方法二: df['dt'] = (pd.to_datetime(df['dt']).values - np.datetime64('1970-01-01T08:00:00Z')) // np.timedelta64(1, 's')