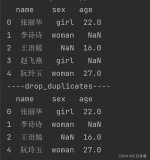
本文主要讲解pandas中的7个聚合统计相关函数,所用数据创建如下:

01 nunique
number of unique,用于统计各列数据的唯一值个数,相当于SQL语句中的count(distinct **)用法。nunique()既适用于一维的Series也适用于二维的DataFrame,但一般用于Series较多,此时返回一个标量数值,表示该series中唯一值的个数。
例如,想统计前面数据表中开课的个数,则可用如下语句:

02 unique
nunique用于统计唯一值个数,而unique则用于统计唯一值结果序列。接收一个series类型作为输入,返回一个去重后的一维ndarray对象作为输出。
正因为各列的返回值是一个ndarray,而对于一个dataframe对象各列的唯一值ndarray长度可能不一致,此时无法重组成一个二维ndarray,从这个角度可以理解unique不适用于dataframe的原因。
仍以前述为例,想统计所有开课的课程名,则可用如下语句:

03 value_counts
如果说unique可以返回唯一值结果的话,那么value_counts则在其基础上进一步统计各唯一值出现的个数;类似的,unique返回一个无标签的一维ndarray作为结果,与之对应value_counts则返回一个有标签的一维series作为结果。
例如,在上述例子中,不仅想知道开课的课程名,还需了解各门课的选课人数,可用语句为:

如果说前面的三个函数主要适用于pandas中的一维数据结构series的话(nunique也可用于dataframe),那么接下来的这两个函数则是应用于二维dataframe。
04 groupby
groupby,顾名思义,是用于实现分组聚合统计的函数,与SQL中的group by逻辑类似。例如想统计前面成绩表中各门课的平均分,语句如下:

当然,groupby的强大之处在于,分组依据的字段可以不只一列。例如想统计各班每门课程的平均分,语句如下:

不只是分组依据可以用多列,聚合函数也可以是多个。例如想同时统计各班每门课程的选修人数和平均分,语句如下:

普通聚合函数mean和agg的用法区别是,前者适用于单一的聚合需求,例如对所有列求均值或对所有列求和等;而后者适用于差异化需求,例如A列求和、B列求最值、C列求均值等等。
另外,groupby的分组字段和聚合函数都还存在很多其他用法:分组依据可以是一个传入的序列(例如某个字段的一种变形),聚合函数agg内部的写法还有列表和元组等多种不同实现。例如,这里想以学生姓氏进行分组统计课程平均分,语句如下:

05 pivot_table
pivot_table是pandas中用于实现数据透视表功能的函数,与Excel中相关用法如出一辙。
何为数据透视表?数据透视表本质上仍然数据分组聚合的一种,只不过是以其中一列的唯一值结果作为行、另一列的唯一值结果作为列,然后对其中任意(行,列)取值坐标下的所有数值进行聚合统计,就好似完成了数据透视一般。
pivot_table函数参数列表如下:

在以上参数中,最重要的有4个:
- values:用于透视统计的对象列名
- index:透视后的行索引所在列名
- columns:透视后的列索引所在列名
- aggfunc:透视后的聚合函数,默认是求均值
这里仍然以求各班每门课程的平均分为例,则应用pivot_table实现此功能的语句为:

aggfunc默认是均值函数'mean'
作为对比,再次给出用groupby实现相同功能的结果:

分组后如不加['成绩']则也可返回dataframe结果
从结果可以发现,与用groupby进行分组统计的结果很是相近,不同的是groupby返回对象是2个维度,而pivot_table返回数据格式则更像是包含3个维度。
既然二者如此相似,那么是否可以实现相互转换呢?答案是肯定的!
06 stack 和 unstack
stack和unstack可以实现在如上两种数据结果中相互变换。从名字上直观理解:
- stack用于堆栈,所以是将3维数据堆成2维
- unstack用于解堆,所以可将2维数据解堆成3维
直接以前述分析结果为例,对pivot_table数据透视结果进行stack,结果如下:
 pivot_table+stack=groupby
pivot_table+stack=groupby
类似地,对groupby分组聚合结果进行unstack,结果如下:
 groupby+unstack=pivot_table
groupby+unstack=pivot_table
看到这里,会不会有种顿悟的感觉:麻雀虽小,玩转的却是整个天空;pandas接口有限,阐释的却有道家思想:一生二、二生三、三生万物……