大数据经过多年的潜心发展,在当今可以说是进入到了一个快速发展期。各种围绕大数据的应用开发也迅速火热起来了。政务大数据解决方案、企业级大数据解决方案、智慧城市停车大数据解决方案等已经开始被应用。5月份一条很有意思的娱乐新闻——警方在某歌手的演唱会上抓捕了好几个被网上追逃的人。这同样是大数据技术的应用······
工业大数据分析平台是利用大数据技术开发搭建的为工业企业服务的一体化信息平台。我们国家世界工厂,仅仅成为制造大国是不行的。这些年国家高新技术产业的快速发展,我们应该可以深刻感受到我们正在从制造大国向制造强国迈进!面对这百年难得的机遇,如何跨好这一步,利用好工业大数据正是我们需要深刻思考的地方。
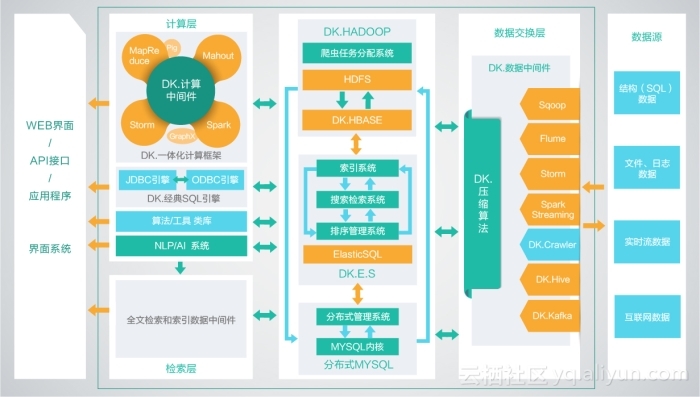
工业大数据作为工业互联网平台的核心组成部分,是当今工业转型升级的必然选择。大数据以及现在大火的人工智能技术对于传统行业转型升级可谓影响深远,工业大数据分析平台功不可没! 那么工业大数据分析平台在传统行业转型升级中到底可以发挥哪些特别的功能或者是价值?
要了解工业大数据分析平台的应用价值,就要先搞清楚这样的分析平台架构。每次一说道某某分析平台的架构总是会让人有点懵!直接化繁为简吧,比如典型的大快搜索以DKhadoop为底层框架开发的工业企业一体化信息分析平台,三个特别重要的架构模块是:分行业统计分析模块、经济增长与税收预测模块、落后产能预警模块。当然还有很多其他的功能模块,感兴趣的就要麻烦自己去了解一下了。
通过这样的一个工业大数据分析平台的应用,可以为工业企业创新、产品的研发、工业企业管理等各个方面服务。比如:在企业产品创新方面:通过大量的数据挖掘、分析,能够帮助企业精准把握客户的需求,为产品创新做出贡献。总的来说,工业大数据分析平台的应用价值主要可以提现在以下几个方面:
1ã 提高行业、企业生产效率,提升产品质量;
2ã 降低生产成本,实现节能降耗;
3ã 加快工业企业产品创新速度,有助于实现大规模定制生产;
4ã 加快实现工厂的智能化管理、生产
