1. 业务介绍
车纷享是国内首家进行汽车共享开发和运营的公司。旗下共享汽车平台采用新能源汽车作为运营工具,以B2C+C2C汽车共享作为商业运营模式,采用车联网技术作为运营管理技术,目前已与国内多个城市建立合作。
公司打造会员制的分时自助租赁平台“车纷享”与“众车纷享”,以及纯电动新能源汽车分时租赁平台“彩虹车”,向会员提供以分钟加里程为计费单位的自助租车服务。通过公司自助租车系统,用户可以进行车辆预定、费用支付、自助取车、还车及自动结算等,无需人工干预,非常简单,真正实现了家门口或公司门口的自助租车,便捷、时尚、经济。 公司汽车共享(分时自助、智能租车)系统为自主研发,具有完全自主知识产权,能够根据需求进行改进和定制,是国内第一个成功商业运营的汽车共享系统,处于国内领先。
2. 选型
对于车纷享这种初创公司来说,技术选型首要考虑的是:轻运维,业务快速落地。自建机房以及运维团队意味着前期较大的投入以及高昂的运维成本,随着业务规模的扩张,资源水平扩展以及垂直扩展也是未来无法避免的痛点。
技术团队进行了多次内部讨论,同时对类似行业公司的解决方案进行了详细调研,新方案必须满足我们以下的基本需求:
(1)支持大量IoT数据的不间断写入,至少能存放百T以内的数据,随着数据规模的增长,能够方便的进行垂直和水平扩展。
(2)支持基于时间戳的历史数据查询,响应时间至少达到秒级,后期根据业务需要,支持对一些关键字段进行索引,以满足某些查询场景
(3)与目前的大数据生态产品(MapReduce,Spark,Hive)能友好兼容,支持离线和准实时OLAP
(4)优先选择有雄厚实力的商业公司支持的云平台,最大限度减少运维成本。
最终我们技术团队选择的是阿里云平台,阿里是国内大数据领域技术最雄厚的公司,比如HBase,阿里拥有2 HBase PMC、3 Committer、数十位内核贡献者,贡献200+ Patch,同时阿里云平台提供了多种方便易上手的数据产品工具。
3. 车纷享数据中心
车纷享的数据来自于车载终端上传的数据报文,首先经过系统平台的网关,然后借助规则引擎对数据报文进行解析拆分成有意义的数据项,以数据记录的方式放入消息队列,消息队列采用了阿里的MQ,消息队列的消费程序,会将消费到的数据分别存入Redis以及HBase,其中Redis是用来提供车辆实时状态的查询,HBase提供车辆历史数据的查询,为了对历史数据进行灾备处理,使用了阿里云的OSS存储,将备份数据日志文件按照时间分区存储至OSS。
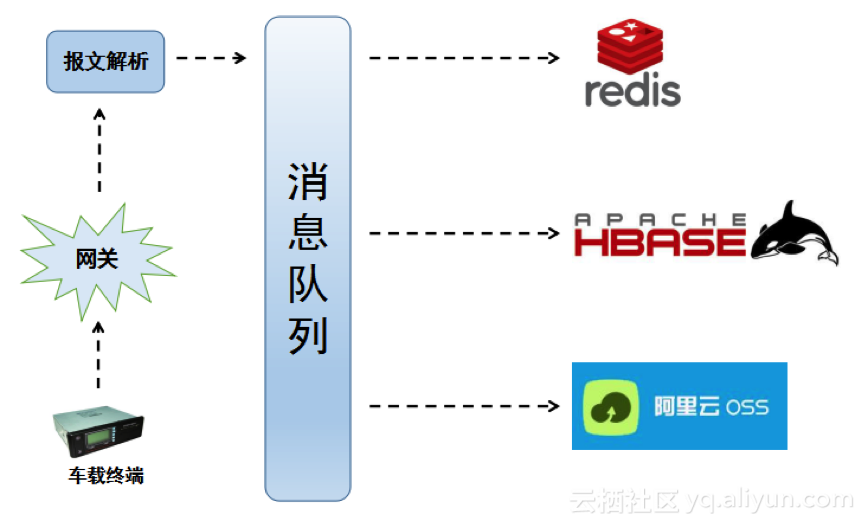
3.1 项目背景
车联网符合并发量大,数据上传频率高,写多读少的高吞吐型业务场景,对查询要求也接近准实时;原有的关系数据库已经不能满足我们的业务需要,尤其数亿量级下的分页查询和车辆历史轨迹查询的场景下,关系数据库的读取相应延迟已经达到了数分钟级,完全不能满足客户的需要。阿里云HBase为我们提供了HBase+Phoenix的组合方案。
HBase是基于磁盘的NoSql数据库,因为采用了LSM的数据结构,随机写效率较高,特别适合车联网的数据上传特点,在基于Rowkey方面的查询延时接近准实时。但是因为原生HBase的查询方式比较底层,没有SQL查询接口,对于使用者要求较高,而且没有二级索引,如果不是基于Rowkey查询,查询效率会急剧下降,为了减少客户的使用难度,阿里云HBase团队在HBase集群里集成了Phoenix的交互引擎,简单的嵌入架构如下:
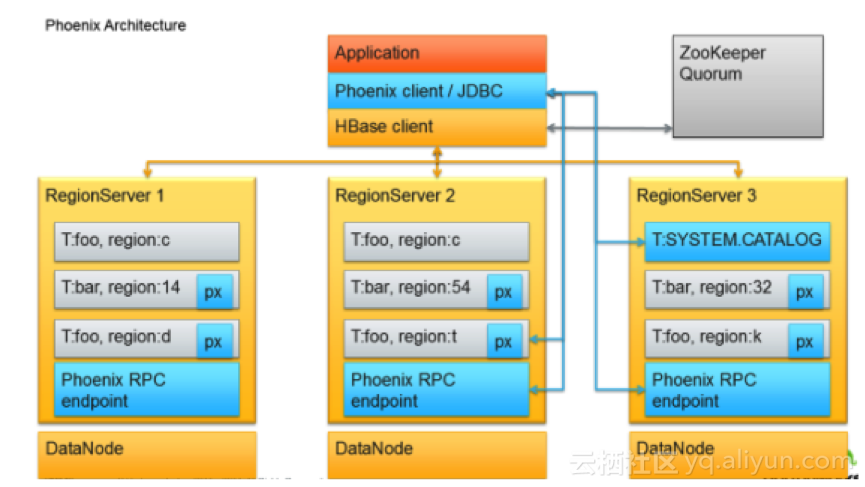
Phoenix的架构
Phoenix主要给HBase增加了SQL查询以及二级索引支持,大大降低了我们的二次开发难度,也进一步丰富了我们对多种查询场景的支持。
3.2 性能指标
1、系统情况
目前测试集群上有6台服务器,都是16Core 32G的配置
2、查询测试
历史数据表(保密需要,字段适当裁剪):
| create table if not exists 车辆历史数据表 ( |
3、建立索引表
| create index 车辆历史状态索引表 on 车辆历史状态表(车辆标识,上传时间,行驶里程,车速,电量) include (发动机温度,发送机转速,油耗,卫星数量,卫星信号强度,......) |
车辆状态历史表中目前有记录12亿条左右,Region有52个
基于rowkey查询
| 查询场景 |
平均响应时间 |
tps |
| 单用户单日数据查询,基于rowkey |
80ms |
1250 |
| 单用户多日数据查询,基于rowkey |
130ms |
769 |
| 50用户单日数据查询,基于rowkey |
210ms |
23800 |
| 50用户多日数据查询,基于rowkey |
320ms |
15600 |
基于索引字段查询
| 查询场景 |
平均响应时间 |
tps |
| 单用户单日数据查询,基于索引字段 |
650ms |
153 |
| 单用户多日数据查询,基于索引字段 |
860ms |
116 |
| 50用户单日数据查询,基于索引字段 |
720ms |
6900 |
| 50用户多日数据查询,基于索引字段 |
1210ms |
4400 |
通过HBase+Phoenix,丰富了我们的历史查询手段,原先的车辆1个月轨迹历史数据回放查询需要5-10分钟,现在2秒内就能返回所需数据。上面的数据都是我们实际的业务场景数据测试的结果,提升了150倍,大大超出我们的期望。
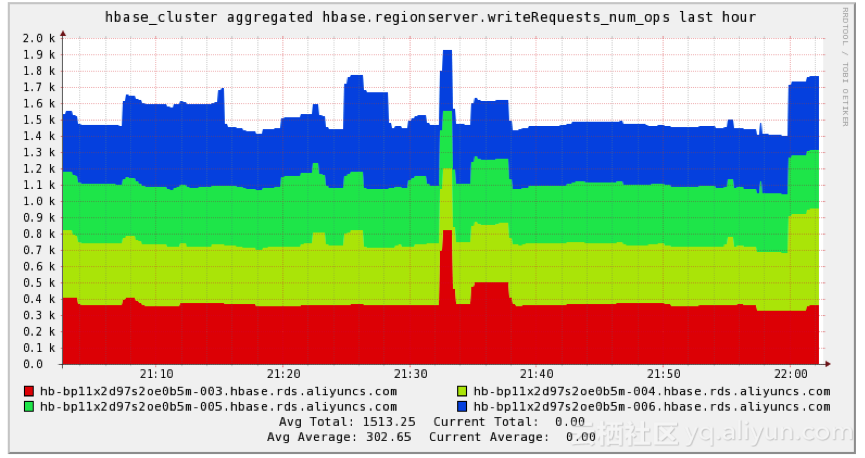
4、集群状况
目前接入的车辆大约为3万辆,其中比较重要的考察指标就是OPS(operation per second 每秒操作次数),主要针对车辆数据的实时不间断写入,目前HBase集群中,平均在1.5K OPS,峰值可以到达2K OPS,目前的集群配置可以支撑最大约400K的OPS,至少可以满足未来2年左右的业务增长需要。阿里云HBase同时支持资源节点水平,垂直扩展和滚动重启,基本可以做到用户无感知下完成升级,这种能力对适应业务的敏捷变化非常有帮助。
3.3 数据处理
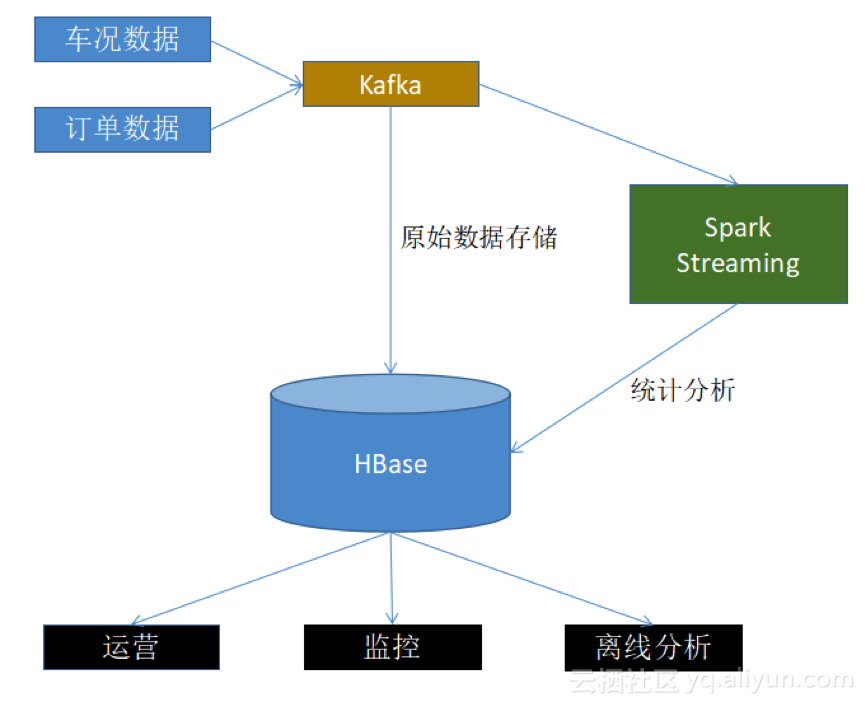
场景实例
以网约车管理平台为例,主要数据来源为车况数据和订单数据,进入Kafka后,拉出两个分支,分别存储进HBase数据库和进入Spark Streaming流式计算引擎,主要用来为运营部门优化网点,车辆分流,监控部门的风控管理和商业BI相关的离线分析提供数据支撑。
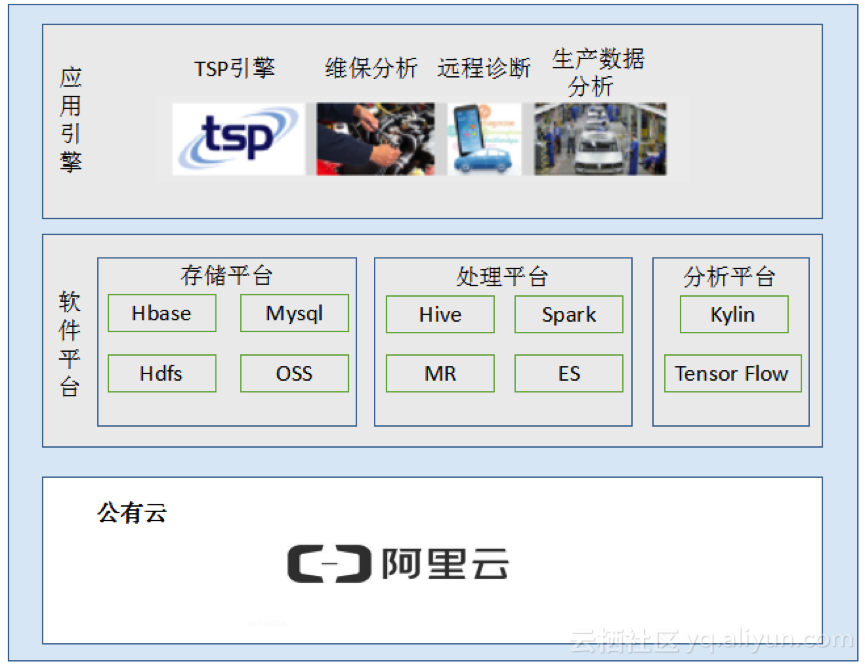
3.4 使用感受
现在车纷享的车联网数据平台已迁入阿里云HBase团队已经半年多了,平均日写入数据几十G,到现在还没出现数据服务器的严重故障问题,总体比较稳定,大大降低了我司的运营管理成本。阿里云HBase团队也给我们的开发团队提供了有力的技术支撑,碰到技术问题,我们可以非常及时得到响应,帮助我们排除了业务开发中的许多问题。再次证明我们的当初选择是正确的。
同时也希望阿里云HBase团队未来可以在产品易用性上更上一层楼。展望未来,随着业务的扩展,我们的数据会有一个指数级的增长。
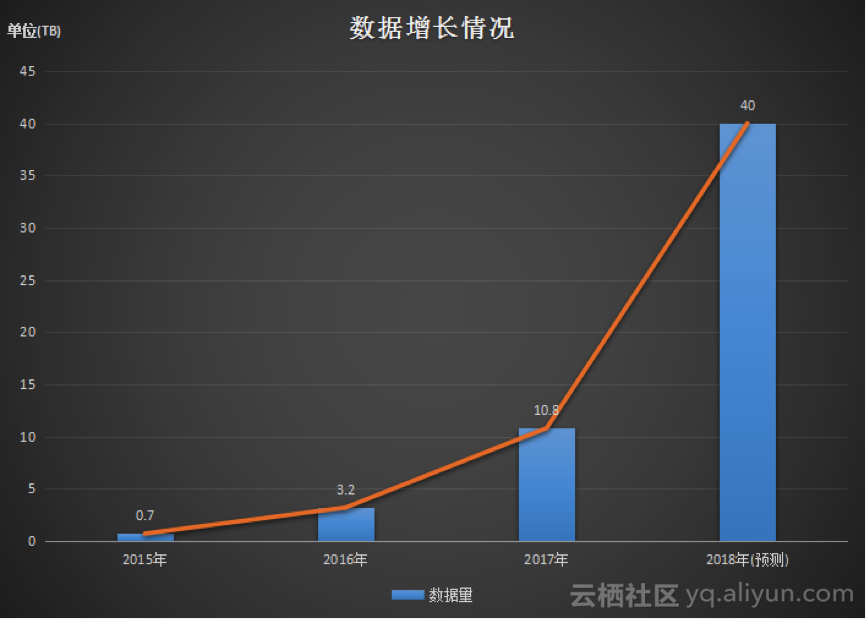
希望新的一年继续和阿里云加大合作,同时将运营中的问题反馈到阿里云技术社区,协助阿里云技术团队将数据产品做得越来越好。
