在上一篇博文中,重点介绍的是Neo4j的读操作,在本文中则将聚焦于Neo4j的写操作,主要包括:创建节点和联系、转移节点和联系以及Cypher查询优化三大问题。
一、创建节点和联系
节点和联系是构成Neo4j图数据库的主要元素,熟悉和掌握基本的节点和联系创建操作非常重要。
(一)操作节点
Node乃Neo4j数据库中最核心的元素,其他元素或者连接于此或者对其进行补充定义或描述。首先,使用下列命令删除当前数据库中的全部已有内容,然后从无到有,一点一滴地学习:
- match (n)-[r]-(n1)
- delete n,r,n1;
- match (n)
- delete n;
(1)单节点
可以使用create (n); 或者create ();或者 create (n) return n;三种方式中的任意一种来创建一个节点。如果仅仅是为了创建一个节点而没有对该节点更进一步的操作,那么就可以省略自定义变量n而使用空括号()。同样,如果不需要返回结果,那么连return从句也是不必要的。
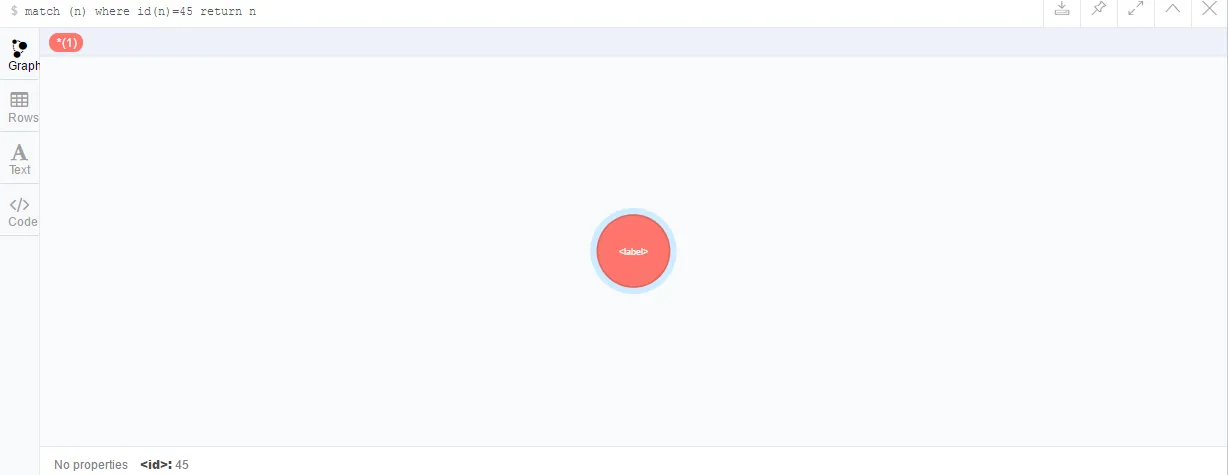
重要的是,Neo4j为每一个节点都分配了一个唯一的ID用作标识。然而,这些ID实际上是Neo4j内部的,而且可以随Neo4j安装或版本的不同而变化,因此强烈建议不要在构建用户定义逻辑中使用节点ID,通俗而言就是用户的代码实现尽量不要使用ID。但是,话又说回来了,并不是根本不能用,比如:
- match (n)
- return ID(n)
(2)多节点
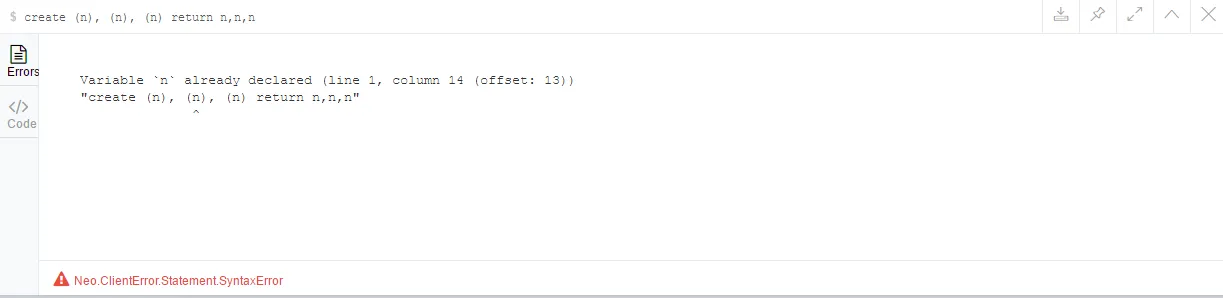
多节点的创建,就是多个元素的并列,如:create (n), (n1)或者create (), ()等。那么,有意思的是,如果create (n), (n)连续两个相同的n,会发生什么样的结果呢?答:结果会报错,系统提示因为已经创建了第一个节点n了,不能重复创建。如图所示:
(3)带标签的节点
Neo4j使用标签实现对相似节点的分组和分类,而且标签还可以用来创建索引(index)从而有助于优化对节点的查询。创建有标签的节点,就是将冒号开始的标签写入即可。学以致用,一口气新建两个带标签而且是多标签的Nodes:
- create (n:MAEL:BOY:STUDENT), (n1:FEMAEL:TEACHER)
- return n, n1
(4)带属性的节点
正如本系列入门点滴的第一篇博文所言,使用属性的实现方式是键值对(key-value pairs),如:
- create (n:MALE{name:"haha", age:20})
- return n
那么,试试创建一个带有字符串数组的属性:
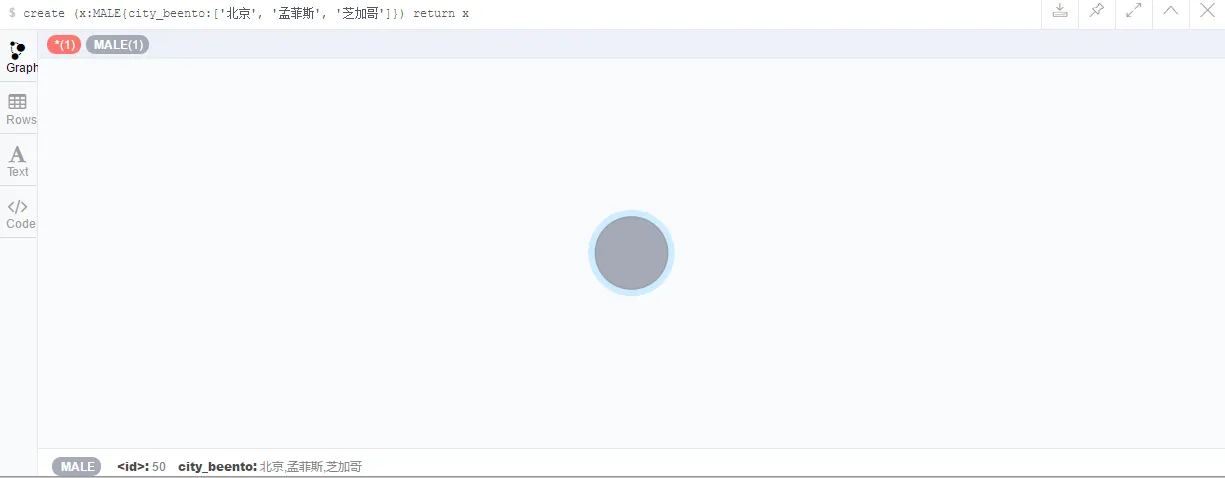
然后,我又创建了一个:create (x:MALE{city_beento:['北京', '孟菲斯']}) return x。这下有意思了,试着搜索一下:
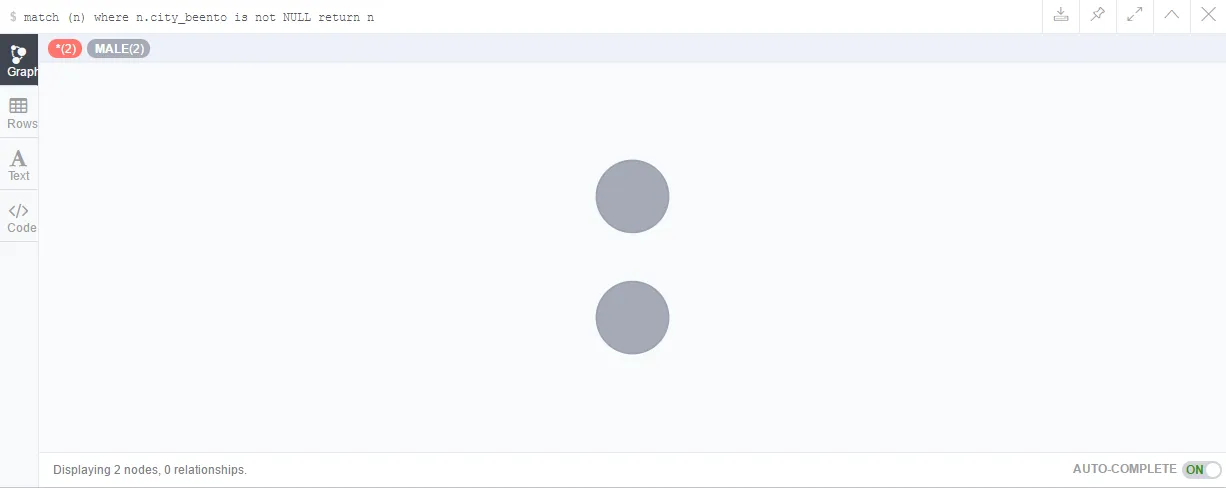
结果是这样:
match (n{city_beento:['北京']}) return n, 命中零个
match (n{city_beento:['北京','孟菲斯']}) return n, 命中一个
match (n{city_beento:['北京','孟菲斯','芝加哥']}) return n, 命中一个
match (n{city_beento:['北京',*]}) return n, 语句报错
match (n{city_beento:[]}) return n, 命中零个
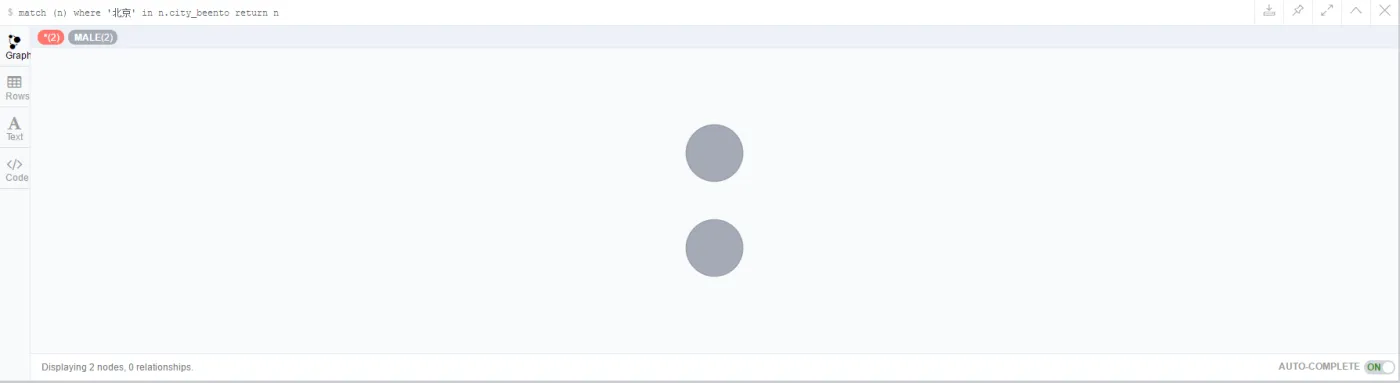
所以,方括号中的属性值实际上是作为一个整体出现的,直接匹配属性只能精确命中。当然,如果需要模糊匹配,那么就可以在where从句中使用in来灵活实现:
- match (n)
- where '北京' in n.city_beento
- return n
(二)操作联系
联系是Neo4j图中另一个核心的元素,对于任何节点或属性而言,只有与其他节点相连时方能体现其重要性。
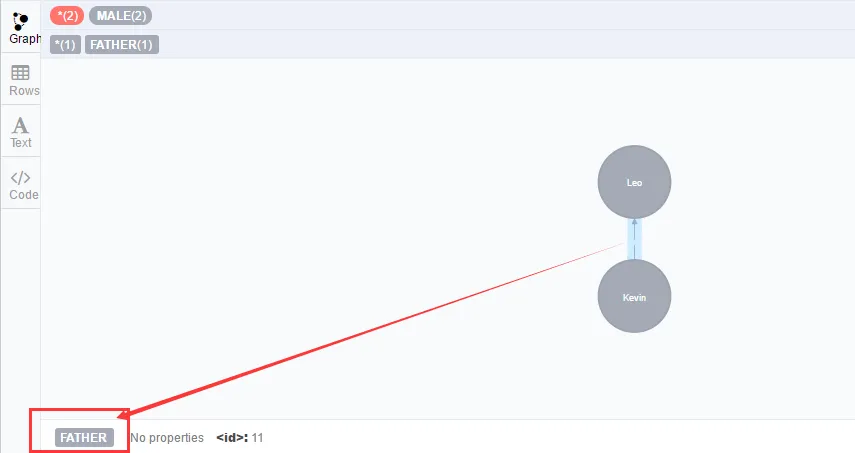
(1)单联系
单向联系使用有向箭头->或
- create (n:MALE{name:'Kevin'})-[r:FATHER]->(n:MALE{name:'Leo'})
- or
- create (n:MALE{name:'Kevin'})-[r:FATHER]->(n1:MALE{name:'Leo'}) return n,r,n1
(2)多联系
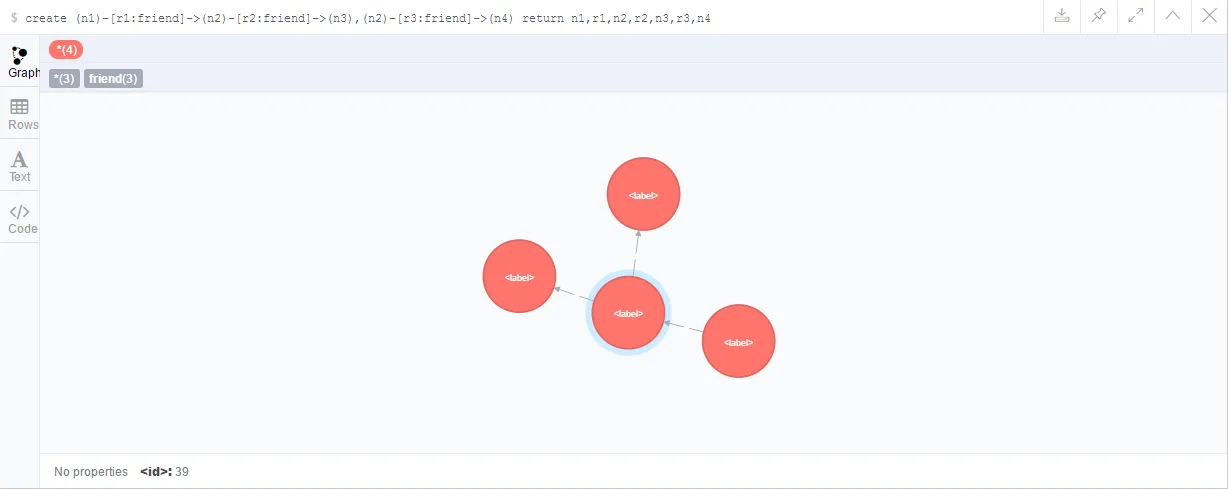
多联系 就是一口气多写点:
- create (n1)-[r1:friend]->(n2)-[r2:friend]->(n3),(n2)-[r3:friend]->(n4) return n1,r1,n2,r2,n3,r3,n4
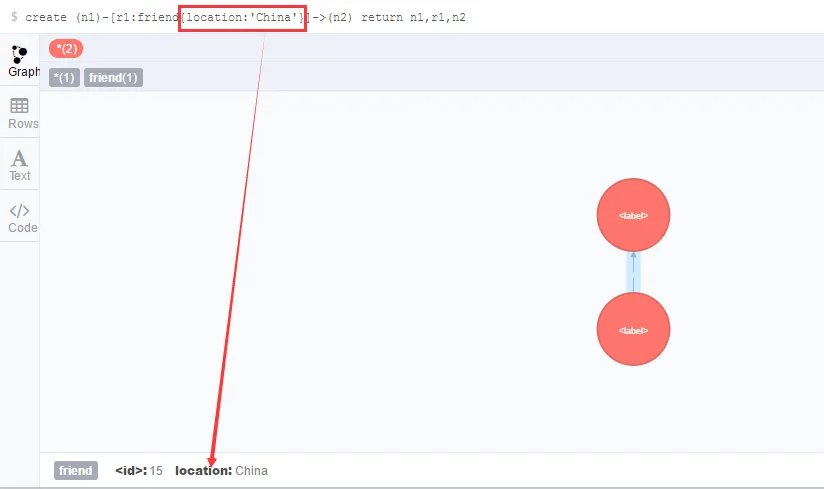
(3)带有属性的联系
没什么特别的 ,只是在联系中添加属性而已,和节点一样,如下图 :
(三) 具有节点和联系的全路径
也没什么特别的 ,全路径就是把create语句全部保存到一个变量中,上例可以重写为:
- create k = (n1)-[r1:friend{location:'China'}]->(n2) return k
(四)创建唯一的节点和联系
刚才创建的节点和联系或多或少有些盲目,有可能引起和给定图中已存在的节点或其属性相重复。 所幸Neo4j提供了create unique语句,这个语句放在 m a t c h 和 c r e a t e这里 , 对于match上的东东会新建缺省元素。这个语句使得我们可以没有重复地实现对给定进行 原 图 最 小程度 的 改 变 。
- match (n)
- where id(n) = 52
- create unique (n)
- return n,r,n1,n2
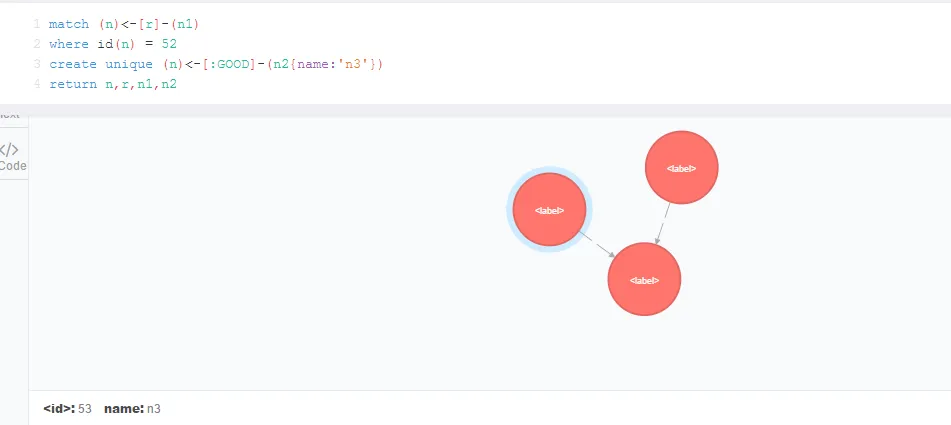
在这个例子中,我同时对n节点的属性也进行 了更新,代码: create unique (n{name:' n1'})创建就是创建,更新已有的就需要另一个语句了:set!
(五)Create Unique和Merge
尽管之前的博文已经提到了merge从句,但现如今还是要再来个quick recap。Merge语句出现在Match和Create的组合中,用于搜寻目标节点、属性、标签或联系。如果目标已经存在,那么直接PASS,否则就直接创建目标对象。与Create Unique类似,Match+Merge+Create也避免出现元素重复,然而二者并不是一样的,差别就在于:Create Unique部分匹配就可以,而Merge则只有整个pattern都匹配才创建,否则什么也不做。
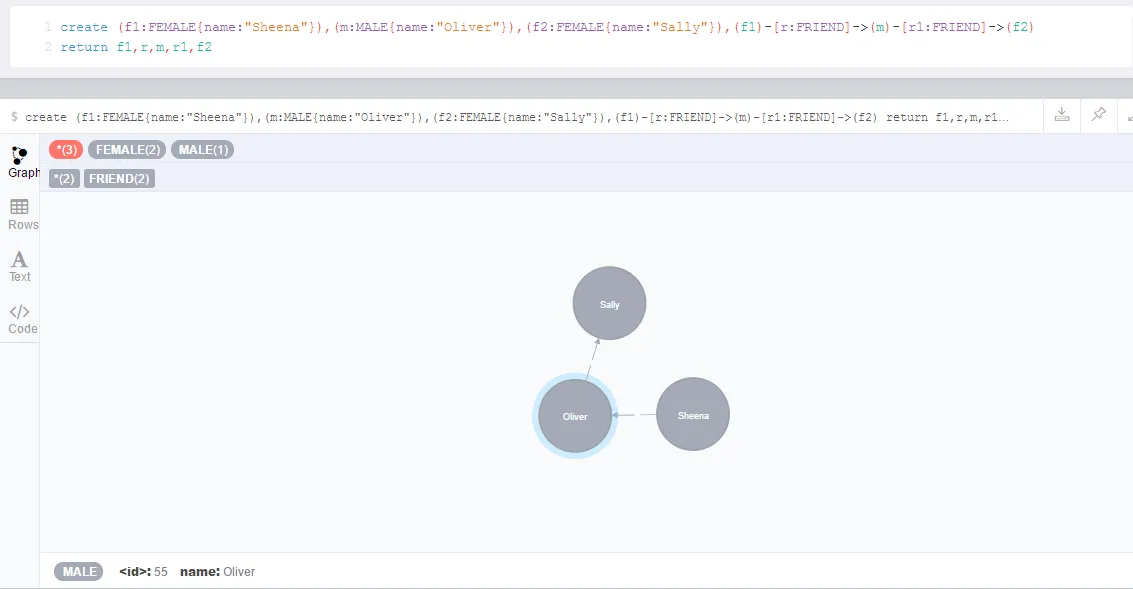
Merge语句实际上后跟on match和on create两个子句,pattern匹配则走on match,不匹配则走on create分支。与Create Unique不同,Merge能够创建索引和标签,甚至被用于创建单节点。上例子,先创建三个节点及其联系:
- create (f1:FEMALE{name:"Sheena"}),(m:MALE{name:"Oliver"}),(f2:FEMALE{name:"Sally"}),(f1)-[r:FRIEND]->(m)-[r1:FRIEND]->(f2)
- return f1,r,m,r1,f2
接下来,使用Merge匹配已存在的元素并新建其他元素:
- match (f1:FEMALE{name:"Sheena"}),(m:MALE{name:"Oliver"}),(f2:FEMALE{name:"Sally"})
- merge (f1)-[r:FRIEND]->(m)-[r1:FRIEND]->(f2)-[r2:FRIEND]->(f1)
- return f1,r,m,r1,f2,r2
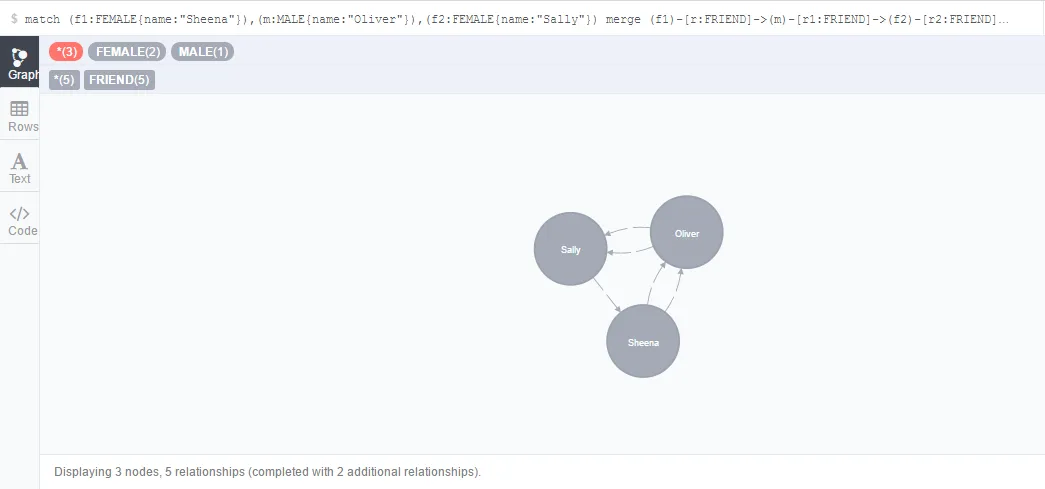
看来,merge本身并不能直接避免重复,起码在当前这个版本下!使用的时候一定要注意。
(六)使用限定条件
Neo4j在version2后引入了对标签进行限定的概念。截止目前为止,Unique限定能用,但将来会有更多的。
通过如下方式可以对MALE标签生成一个Unique限定:
- create constraint on (n:MALE) assert n.name is unique
- match (n:MALE{name:'Oliver'})
- create (n1:MALE{name:'Oliver'})-[r:FREIND]->(n)
- return n1,r,n
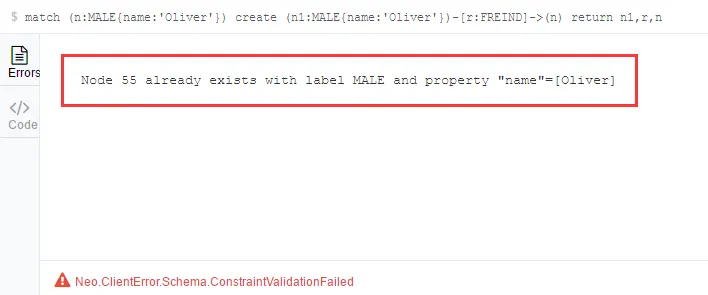
这个安全功能,很实用!若想删除之前加上的限定条件,则需要使用drop:
- drop constraint on (n:MALE) assert n.name is unique
二、修改节点和联系
主要讨论如何更新标签、属性和联系。
(一)更改节点属性
具体方式就是借助Match匹配节点,然后通过Set更改值。如:
- match (n:FEMALE {name:"Sheena"})
- set n.surname = "Foster"
- return f
- match (n{name:'Sheena'}) set n.middlename = NULL return n
- match (n{name:'Sheena'})
- remove n.surname
- return n
(二)更改标签
和之前更改属性相似,也是使用set和remove进行操作,但是不同的是没有set :XXX = NULL的写法。看例子就好:
- match (n{name:'Sheena'})
- set n:GOODMAN:BADMAN
- return n
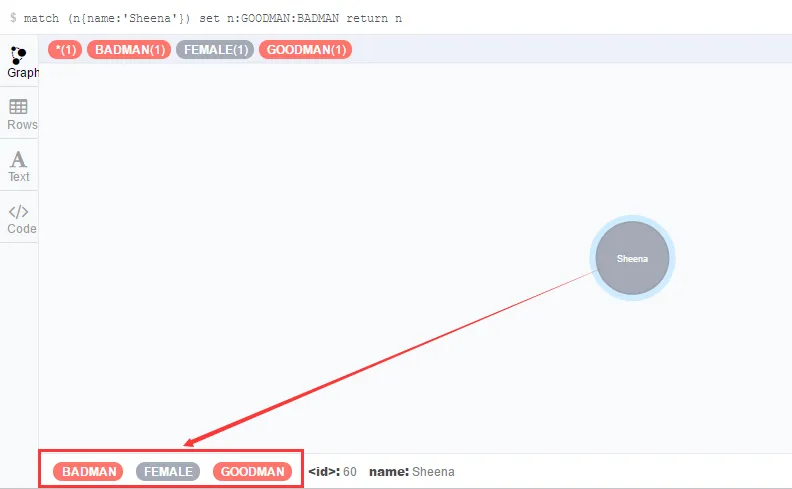
然后把BADMAN标签去掉,然后再加入一个新的标签:
- match (n{name:'Sheena'})
- remove n:BADMAN
- set n:GOODGOODMAN
- return n
(三)更改联系
与属性和标签不同,并没有更改联系的语法词。唯一的方法就是首先移除这些联系,然后创建新联系。比如:如果Sheena和Oliver不再是朋友关系,那么匹配二者的联系并且删除这个联系即可。
- match (n{name:'Sheena'})-[r:FRIEND]-(n1{name:"Oliver"})
- delete r
- return n,n1
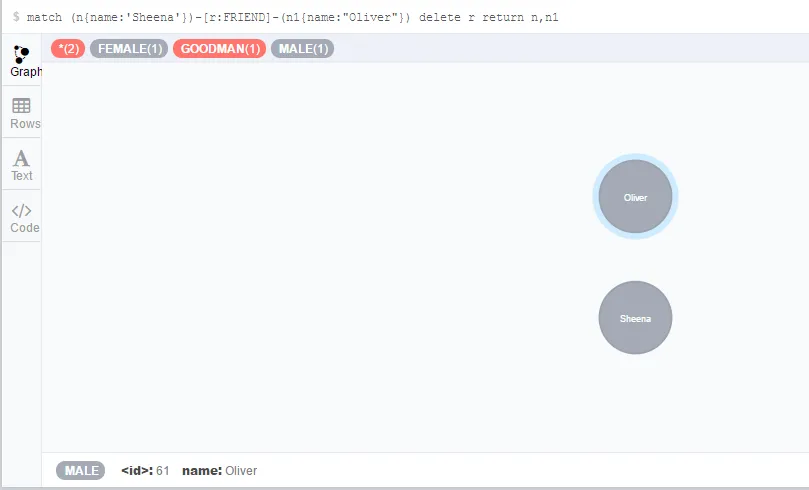
五岳之巅
2017年5月25日(孟菲斯时间)
18:05
终稿于Dorsey