
2017/12/20 北京云栖大会上阿里云MaxCompute发布了最新的功能Python UDF。

小编第一时间申请到了公测资格,下面就为大家做个简单演示,通过DataWorks注册MaxCompute Python UDF(字符串大小写转换),完成数据处理。
前提条件:
1、申请开通https://page.aliyun.com/form/odps_py/pc/index.htm
注意:公测阶段请使用测试Project,不要使用生产Project。
2、开通MaxCompute/Dataworks。
3、Python 脚本,test_udf.py。实现方法请参考Python实现MaxCompute UDF
# -*- coding:utf-8 -*-
from odps.udf import annotate #函数签名,SQL执行前所有函数的参数类型和返回值类型必须确定;
@annotate("string->string")#参数为string,返回值为string;
class Upper2Lower(object):
def evaluate(self, arg):#实现 evaluate 方法;
return arg.lower()操作演示:
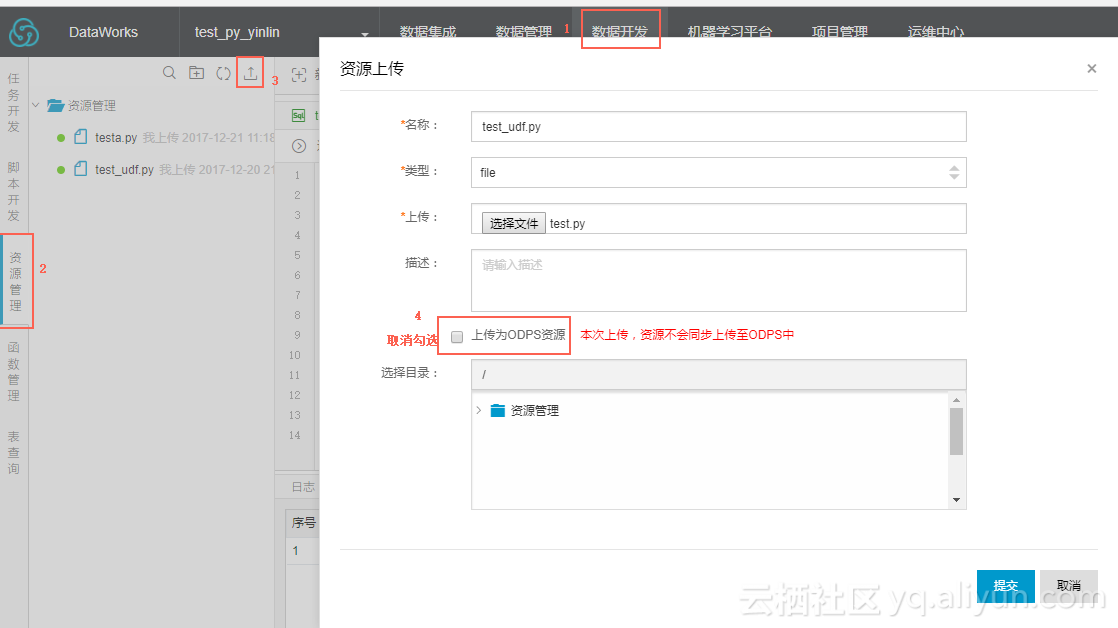
step1,通过Dataworks数据开发添加.py资源。操作如下,数据开发->资源管理->上传资源。
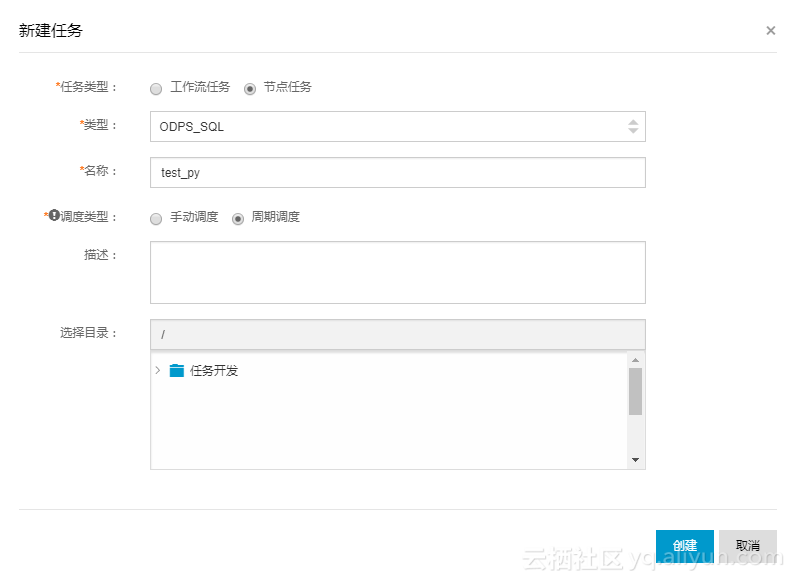
step2,通过Dataworks数据开发任务创建.py资源。
--@resource_reference{"test_udf.py"}
add py test_udf.py;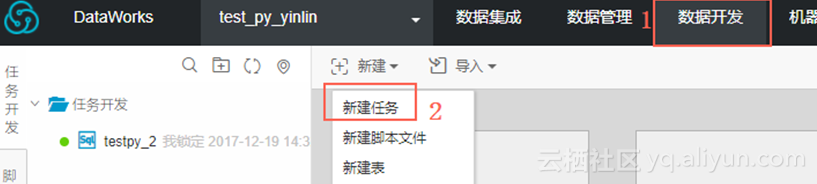
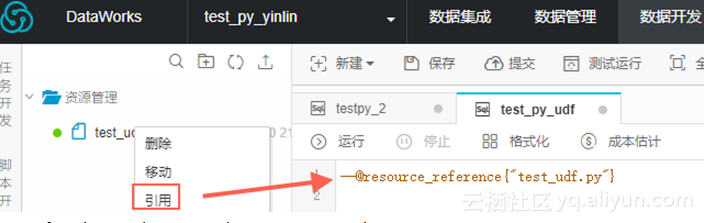
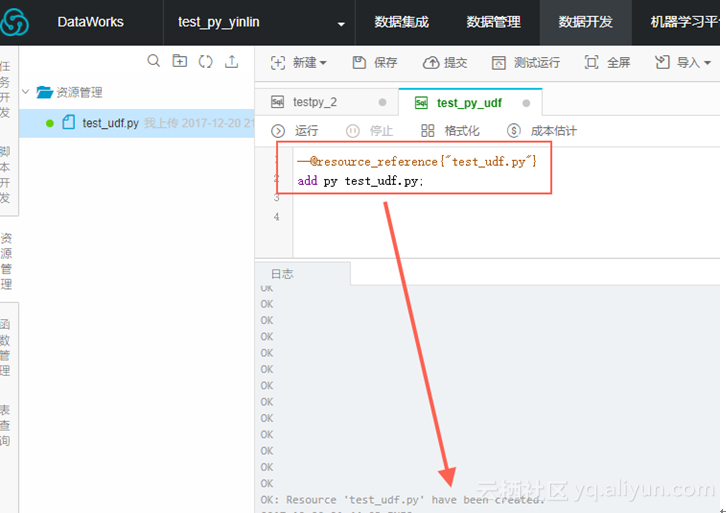
step3,数据开发任务注册函数。
create function upper2lower as 'test_udf.Upper2Lower'
using test_udf.py 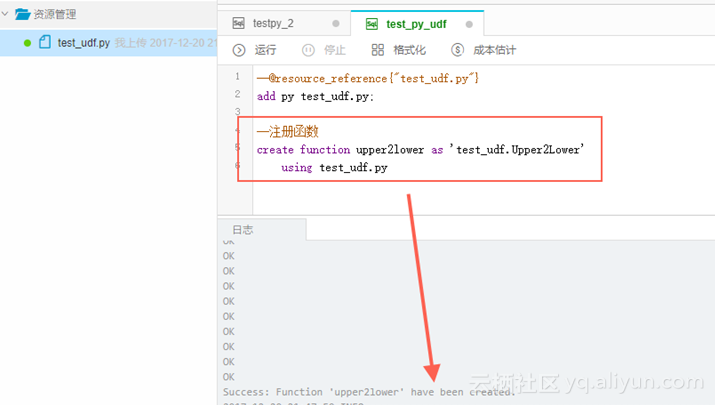
step4,通过list命令查看函数是否注册成功。
list functions ;
step5,完成udf测试。
select upper2lower('AA');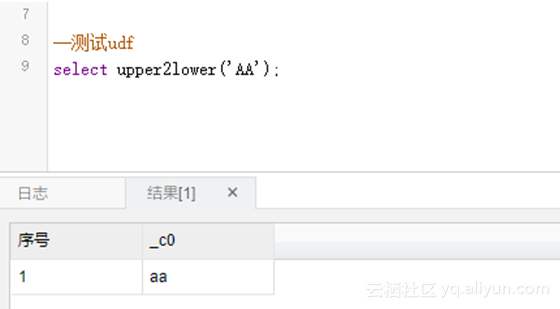
相关资料参考:
通过MaxCompute Console 运行Python UDF:https://yq.aliyun.com/articles/304494
通过MaxCompute Studio运行Python UDF:https://yq.aliyun.com/articles/304646
通过Pyodps 运行Python UDF :https://yq.aliyun.com/articles/307577
Python SDK :https://help.aliyun.com/document_detail/34615.html
欢迎加入“数加·MaxCompute购买咨询”钉钉群(群号: 11782920)进行咨询,群二维码如下:


阿里巴巴大数据-玩家社区 https://yq.aliyun.com/teams/6/
---阿里大数据博文,问答,社群,实践,有朋自远方来,不亦说乎……

