概述
我们都知道,yarn版本的hadoop无论是从架构上面还是软件设计的层面上面都比原始的hadoop版本有较大的改进。在架构方面,我们认为yarn模式是新一代的框架,这个在官方等丛多的资料中说明得很详细了。在软件设计方面,我认为主要有以下的一些大的方面的改进:服务生命周期管理模式、事件驱动模式、状态驱动模式。这几个模式都写在hadoop-yarn-common中,接下来,我将详细说明这些模式。
服务生命周期管理模式
一个对象肯定有生与死,那在我们设计中如何表示这一点呢?在业务系统中,我们一般是用spring,spring就负责管理对象的生命。在hadoop,我们没有必要引进spring这么厚重的容器。我们可以自行设计一套代码来管理我们服务的生命周期。那需要满足那些条件呢?
- 一个服务的生命大概有4个状态:NOTINITED、INITED、STARTED、STOPPED。对应一些基本的操作,如:init start stop等。
- 服务的状态变化会触发一些变化。可以用观察者模式。
- 有组合服务的概念,因为我需要一个循环同时启动多个服。可以使用Composite模式。
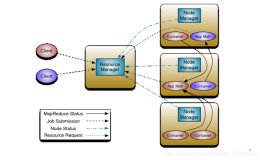
那yarn的设计方面如下:

从中我们看出service这个设计正好满足我们的三个基本的要求。从图中,我看得很清楚,这个是一个典型的设计方案。一个接口,下面有一个抽象类,再有一个组合类。AbstractService其实实现了register()、unrgister()及状态变化后,调用Listener基本的功能。CompositeService实现了组合服务的需求,如:ResourceManager可以组合几个服务。在yarn中,Listener并没有实现异步。个人感觉主要有两个理由:第一,如图中,NodeManager既是Service又是Listener,如果异步有死锁的风险。第二,因为都是服务,其启动,停止调用次数都相对非常少,状态也不会经常发生变化,没有必要引入异步。
事件驱动模式
事件驱动模式最核心的部分就是一个异步dispatcher,以此来达到解耦的目的。我们看下yarn中怎么实现的,如下图:
这个也是一个典型的设计方案,我在以前的系统中经常这么设计事件的。其实这个也是监听者模式。在消息中间件中,我们往往引入中间的存储层——存储转发。其实这个在路由器中也是这样的。用到最后,其实都差不多,关键在于你能否看破。
需要注意的是,AsyncDispatcher也是一个service,这样ResourceManager等组合服务可以add AsyncDispatcher获得AsyncDispatcher事件转发的功能。
状态驱动模式
在设计模式中,有一个状态模式,其实我这里讲的理论就是有穷状态机。状态模式我们可以认为是摩尔型有限状态机 ,我们这里讲的主要是米利型有限状态机, yarn中实现的还是比较复杂的,可以看出他就是非确定型的自动机。在框架中还是比较少看见状态机的,这个可以仔细研究下,我们可以先看下RMNode状态机的状态图(这个图是根据RMNode状态机自动生成的)。
我们看到 任意两个状态之间的变化可以是任意的事件,并且可以是多个事件;同一个事件可以使一个状态迁移到多个不同的状态。我们可以认为这里的状态机是非确定性米利型有限状态机。这些知识在大学的编译原理上面讲过,我也是翻书的。我们看下yarn中的实现,如下图所示:
我认为其中最重要就是构建这个Map>> stateMachineTable对象,这里面存了状态机的元信息。后续调用完全是根据这个Map来运行的。重点讲下这个map的组成,从from到to端,第一个STATE是from端的状态。从一个状态转移可以有多个事件触发,其中的每一个事件可以有一个Transition,每个Transition就是有一个OPERAND操作。
一个Transition可以转移到多个to端的状态。可以从类图中看到Transition的两个实现类SingleInternalArc、MultipleInternalArc。MultipleInternalArc还带了一个默认的状态。
这个数据构建的时候用了builder模式,实现了FluentInterface。客户端是直接使用StateMachine的接口调用的,当然这个StateMachine也是由StateMachineFactory构建的(make)。我们看下状态的执行流程:

在yarn中,我们看下事件驱动模式与状态驱动模式是怎么结合的,从中可以看出,状态机其实和事件是密不可分的。状态机的Transition也会产生一些Event再输出到AsynDispatcher中。

总结
在yarn中的应用了很多新的设计思想,以上3个只是在整个框架中比较突出的几个。我们在阅读框架时,要时刻牢记,设计软件的第一原则是软件设计的理论及架构模式。由于作者个人知识面有限,如果描述有错误或者遗留之处敬请谅解,再欢迎指出,我们共同进步。