问题一:大数据计算MaxCompute 为啥这条SQL无法执行呢?
大数据计算MaxCompute 中SELECT '123456' RLIKE '^(-|+)?\d+(.\d+)?′为啥这条SQL无法执行呢报错是FAILED:ODPS−0130071:[0,0]Semanticanalysisexception−physicalplangenerationfailed:java.lang.RuntimeException:SQLRuntimeUnretryableError:ODPS−0121011:Invalidregularexpressionpattern−infunctionRLIKE,regularexpressioncallfailed,errormessage:′nothingtorepeat′,erroroffsetinpatternis4,thepatternis(−|+)?d+(.d+)?' 为啥这条SQL无法执行呢 报错是FAILED: ODPS-0130071:[0,0] Semantic analysis exception - physical plan generation failed: java.lang.RuntimeException: SQL Runtime Unretryable Error: ODPS-0121011:Invalid regular expression pattern - in function RLIKE, regular expression call failed, error message:'nothing to repeat', error offset in pattern is 4, the pattern is ^(-|+)?d+(.d+)?, please check regular expression pattern 多次检查过正则表达式了,没问题呀,想匹配 +8 -8 +8.8 -8.8 也就是匹配正数、负数、和小数
参考回答:
在MaxCompute里正则表达式的模式中出现的 \ 都要进行二次转义。可以参考下文档:https://help.aliyun.com/zh/maxcompute/user-guide/maxcompute-regular-expressions?spm=a2c4g.11186623.0.i57#d4125f81cceth
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/603315
问题二:请教下大数据计算MaxCompute,我想在pyodps里执行SQL,应该是用什么办法?
请教下大数据计算MaxCompute,我想在pyodps里执行SQL,然后遍历SQL结果的每一行数据,进行操作,应该是用什么办法? 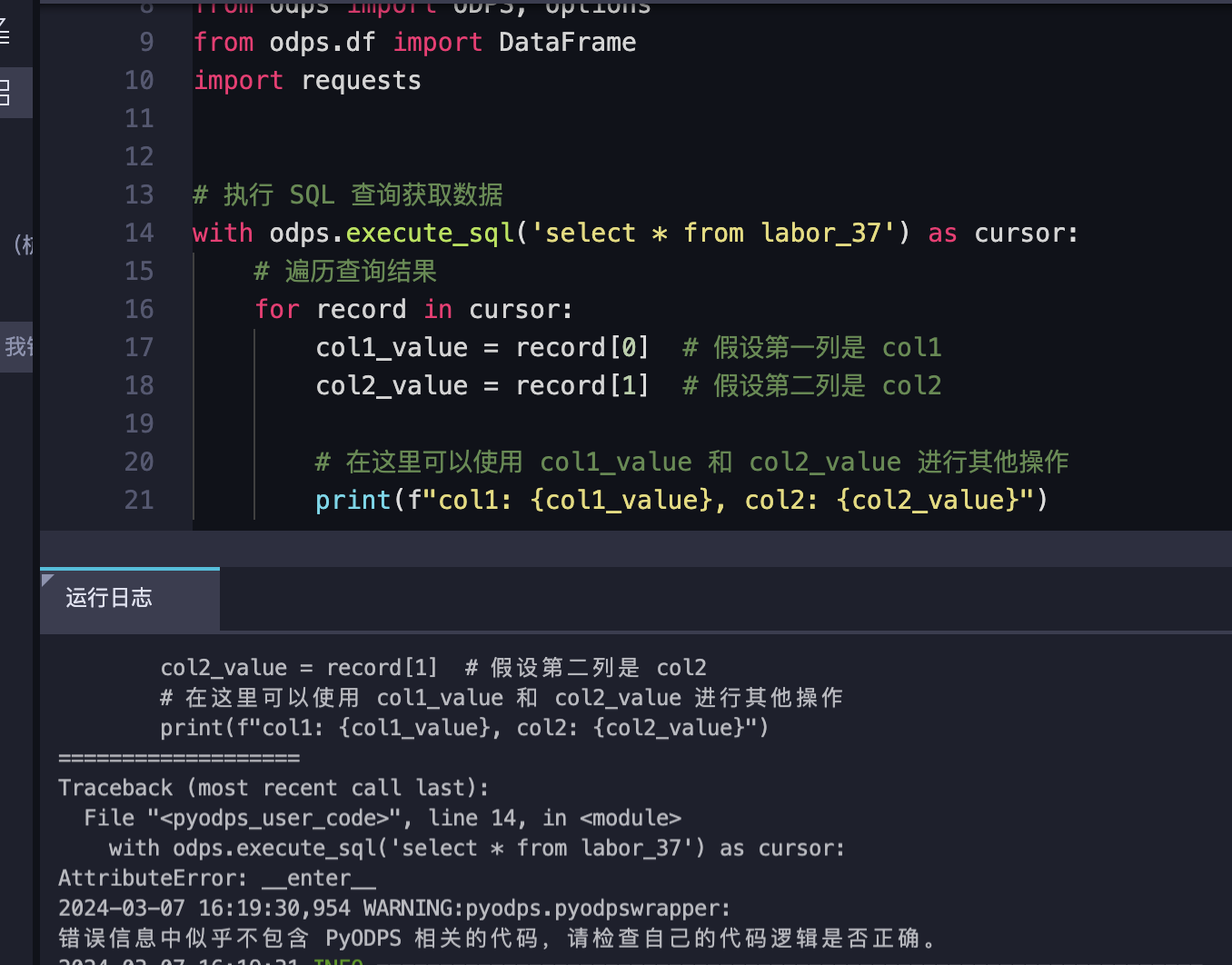
参考回答:
参考文档看下。 
https://pyodps.readthedocs.io/zh-cn/latest/base-sql.html
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/603258
问题三:DataWorks接上游一张表,每天增量更新存csv文件至oss,历史的列少就会报错,有方法解决么?
DataWorks接上游一张表,每天增量更新存csv文件至oss,再通过外部表方式读数据进maxcompute,现在上游表增加字段,我离线同步节点也增加字段依然存文件至oss,这时候如果外部表也增加字段,读取历史及当前所有oss文件进来,历史的列少就会报错,有方法解决么?
还是历史oss文件都不能用了,只能按目前所有字段全量再抽一次进来?
参考回答:
有方法解决该问题,无需重新全量抽取数据。
当上游表增加字段后,相应的离线同步节点和外部表都需要进行更新以反映这些变更。对于已经存储在OSS的历史CSV文件,如果直接读取进MaxCompute而没有对外部表做相应的字段增加,的确会因为历史文件缺少新加字段而导致报错。为了解决这个问题,您可以采取以下步骤:
- 更新外部表定义:您需要在MaxCompute中更新对应外部表的定义,添加新的字段。这样新的字段会在读取CSV文件时被识别。
- 使用赋值节点处理历史数据:对于已有的历史OSS文件,可以通过DataWorks的赋值节点来为缺失的字段赋予默认值或标记。这样,即使历史数据中没有新字段的数据,也能保证数据类型一致,从而避免报错。
- 补数据功能:如果需要将历史增量数据同步至目标表对应时间分区,可以使用运维中心的补数据功能,这允许您针对特定的时间段补充数据。
- 配置重置位点:如果您需要修改同步任务的配置,可以在暂停任务时记下任务暂停的时间,然后重启任务时配置这个“重置位点”,使实时同步任务从重置位点向后同步数据,避免重复消费之前的数据。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/602635
问题四:大数据计算MaxCompute这个是什么错误吗?
大数据计算MaxCompute这个是什么错误吗?
FAILED: ODPS-0110061: Failed to run ddltask -
Modify DDL meta encounter exception : ODPS-0010000:System internal error -
Metastore processing exception - Batch modify failed. ots2.0 processing error because of
[Message]:batchWriteRow partially failed,
one of its errors:
Transaction size exceeds the limit.RowSize:2785.TotalSize:4195749.Limit:4194304.,
[RequestId]:00061274-7593-770d-aac4-ca0b87266e51, [TraceId]:null, [HttpStatus:]0 (
Inner exception: batchWriteRow partially failed, one of its errors:
Transaction size exceeds the limit.RowSize:2785.TotalSize:4195749.Limit:4194304.)
参考回答:
根据提供的错误信息,这是一个MaxCompute(阿里云大数据计算服务)的错误。错误代码为ODPS-0110061,表示在运行DDL任务时遇到了问题。具体的错误信息是"Transaction size exceeds the limit",即事务大小超过了限制。
根据错误信息中的详细信息,可以看出出现了一个批量写入行操作失败的情况。其中一个错误是事务大小超过了限制。RowSize表示单个行的大小为2785字节,TotalSize表示总大小为4195749字节,而Limit表示限制为4194304字节。
这个错误通常发生在进行大量数据写入操作时,超过了MaxCompute的事务大小限制。为了解决这个问题,你可以考虑以下几种方法:
- 减小每次写入的数据量:将大批量的数据拆分成更小的部分进行写入,以符合事务大小的限制。
- 增加事务大小限制:如果你有权限,可以尝试增加MaxCompute的事务大小限制,以满足你的数据写入需求。
- 优化数据结构:检查你的数据结构是否合理,是否存在冗余或不必要的字段,可以通过优化数据结构来减少每个行的大小。
请注意,具体的解决方法可能因实际情况而异,你需要根据你的具体情况和需求来选择适合的解决方案。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/601334
问题五:请教下大数据计算MaxCompute相关问题?
请教下大数据计算MaxCompute相关问题?想从A表的分区,往B表的分区克隆数据,A和B的结构一样我的写法是: clone table 项目生产环境.A表 partition (dt ='20240225') to 项目测试环境.B表 partition (dt ='20240226') if exists overwrite;

参考回答:
你的写法是正确的,可以按照以下方式从A表的分区克隆数据到B表的分区:
clone table 项目生产环境.A表 partition (dt ='20240225') to 项目测试环境.B表 partition (dt ='20240226') if exists overwrite;
这条语句将会将A表中日期为'20240225'的分区数据克隆到B表中日期为'20240226'的分区中。如果B表中已经存在相同分区,则会覆盖原有数据。
请确保在执行该语句之前,A表和B表的结构是相同的,并且你具有足够的权限来执行此操作。
关于本问题的更多回答可点击原文查看:
