问题一:使用maxcompute开发ODPS Spark任务,使用spark.sql 无法 rename分区
使用maxcompute开发ODPS Spark任务,使用spark.sql 执行rename分区 sql: alter table tableNamepartition(date=′tableName partition(date='dateFrom',source_id=sourceFrom)renametopartition(date=′sourceFrom) rename to partition(date='dateTo',source_id=$sourceTo), 任务报错退出。
报错信息如下:
org.apache.spark.sql.AnalysisException: ALTER TABLE RENAME PARTITION is only supported with v1 tables. at org.apache.spark.sql.catalyst.analysis.ResolveSessionCatalog.org$apache$spark$sql$catalyst$analysis$ResolveSessionCatalog$$parseV1Table(ResolveSessionCatalog.scala:588) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.analysis.ResolveSessionCatalog$$anonfun$apply$1.applyOrElse(ResolveSessionCatalog.scala:472) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.analysis.ResolveSessionCatalog$$anonfun$apply$1.applyOrElse(ResolveSessionCatalog.scala:48) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsUp$3(AnalysisHelper.scala:90) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:73) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsUp$1(AnalysisHelper.scala:90) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:221) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsUp(AnalysisHelper.scala:86) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsUp$(AnalysisHelper.scala:84) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsUp(LogicalPlan.scala:29) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.analysis.ResolveSessionCatalog.apply(ResolveSessionCatalog.scala:48) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.analysis.ResolveSessionCatalog.apply(ResolveSessionCatalog.scala:39) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$2(RuleExecutor.scala:216) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at scala.collection.LinearSeqOptimized.foldLeft(LinearSeqOptimized.scala:126) ~[scala-library-2.12.10.jar:?] at scala.collection.LinearSeqOptimized.foldLeft$(LinearSeqOptimized.scala:122) ~[scala-library-2.12.10.jar:?] at scala.collection.immutable.List.foldLeft(List.scala:89) ~[scala-library-2.12.10.jar:?] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1(RuleExecutor.scala:213) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1$adapted(RuleExecutor.scala:205) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at scala.collection.immutable.List.foreach(List.scala:392) ~[scala-library-2.12.10.jar:?] at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:205) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:196) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:190) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:155) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$executeAndTrack$1(RuleExecutor.scala:183) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:88) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.rules.RuleExecutor.executeAndTrack(RuleExecutor.scala:183) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.analysis.Analyzer.$anonfun$executeAndCheck$1(Analyzer.scala:174) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:228) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:173) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.execution.QueryExecution.$anonfun$analyzed$1(QueryExecution.scala:73) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111) ~[spark-catalyst_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:143) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:143) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:73) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:71) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:63) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:98) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:615) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) ~[spark-sql_2.12-3.1.1.jar:3.1.1] at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:610) ~[spark-sql_2.12-3.1.1.jar:3.1.1]
参考回答:
根据错误信息,ALTER TABLE RENAME PARTITION操作仅支持v1表。这意味着在MaxCompute中,Spark SQL目前可能不支持对分区表进行重命名操作。您需要考虑使用MaxCompute提供的原生命令或SDK来进行分区重命名操作。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/604644
问题二:大数据计算MaxCompute这里指定的是parquet,但是写入后不是parquet?
大数据计算MaxCompute这里指定的是parquet,但是写入后不是parquet? 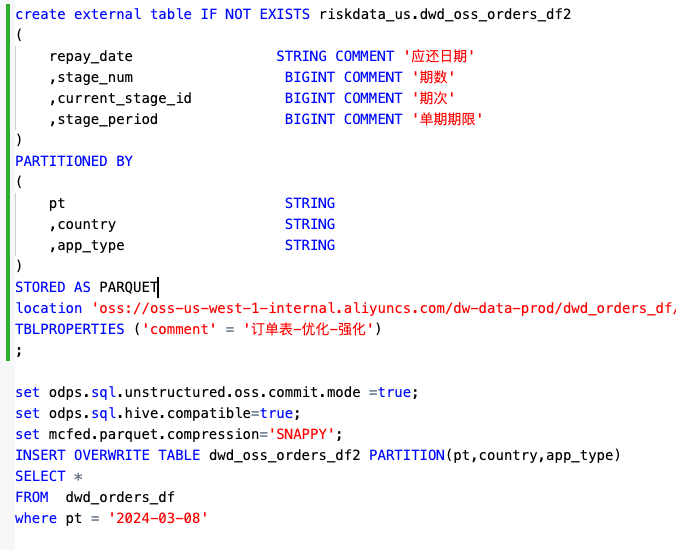
写入之后的数据如下 我期待的数据格式如下 

参考回答:
创建oss外部表时加上这个属性 serde_class 指定PARQUET参数,压缩用with serdeproperties属性,指定GZIP压缩。
https://help.aliyun.com/zh/maxcompute/user-guide/create-an-oss-external-table?spm=a2c4g.11186623.0.i15#section-f7w-sgc-jon
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/603376
问题三:大数据计算MaxCompute中dataworks 脚本模式下面,再查询这张表报错 怎么解决呢?
大数据计算MaxCompute中dataworks 脚本模式下面,更新完成一张数据表后,再查询这张表报错 怎么解决呢
insert into t(id1,id2) values(1,0);
update t set id2 = 1;
FAILED: ODPS-0130071:[64,51] Semantic analysis exception - cannot read table t after modification, please use variable instead: read table data into a variable before writing or access variables which represent new data
参考回答:
脚本模式会把所有SQL作为一个整体进行编译,执行。
如果你要顺序执行,得用odps SQL节点
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/603374
问题四:大数据计算MaxCompute这个函数的原理,帮忙看看这个问题?
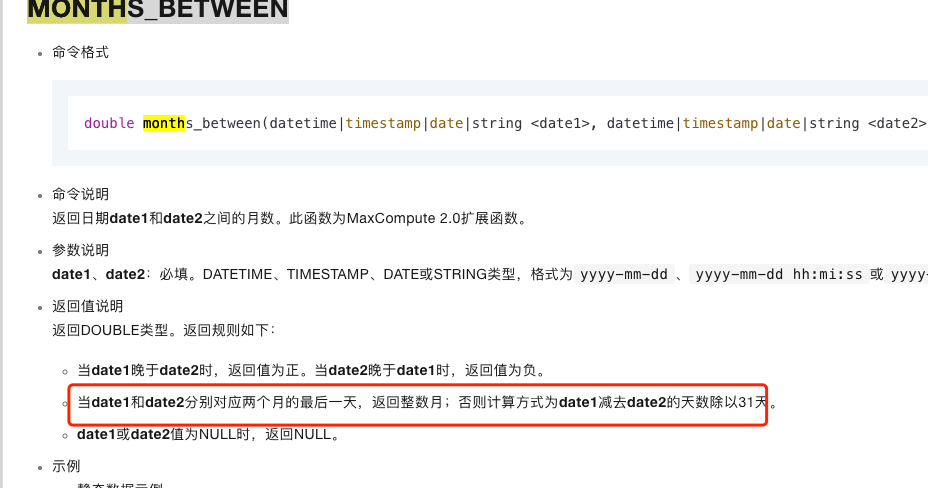
大数据计算MaxCompute这个函数的原理https://help.aliyun.com/zh/maxcompute/user-guide/date-functions?spm=a2c4g.11186623.0.i14#section-s2l-btt-mal?
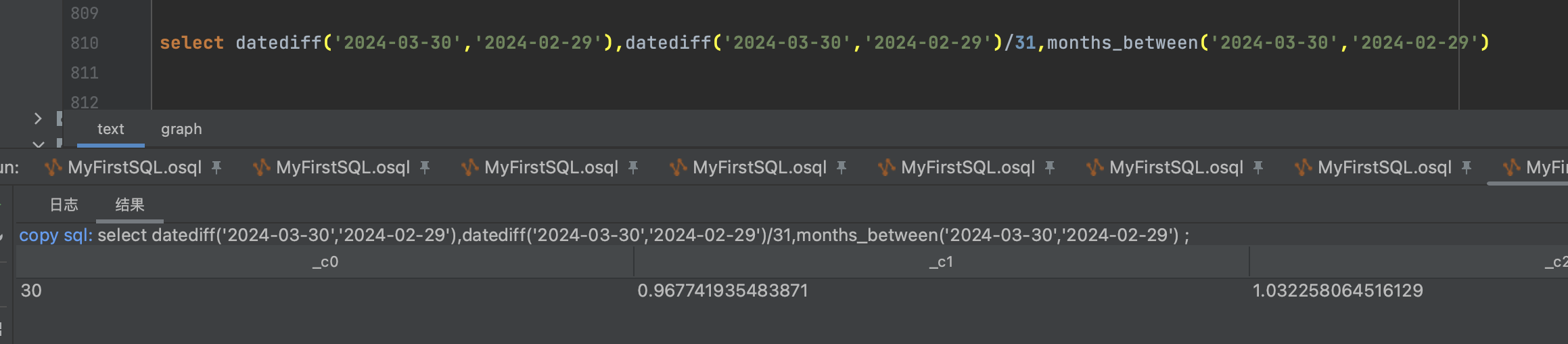
为什么我自己diff完 除以31,跟months_between的结果不一样 ,并且 20240229 到20240330 其实不满1个月,但是用months_between算出来的结果大于1,哪个大哥帮忙看看这个问题 ,是不是我哪里使用的有问题?select datediff('2024-03-30','2024-02-29'),
datediff('2024-03-30','2024-02-29')/31,
months_between('2024-03-30','2024-02-29'),
months_between('2024-03-31','2024-02-29')
参考回答:
我理解只这样的。
MONTHS_BETWEEN返回的是date1和date2之间的月数,datediff计算两个时间date1、date2的差值,不填写datepart参数,默认日期格式为天。
两个函数返回不同结果的原因在于它们计算差异的方式不同。datediff 返回一个整数的天数差,然后你手动除以 31 来得到一个近似的月份数。而 months_between 返回一个表示月数差的浮点数,它更准确地反映两个日期之间的时间跨度。MONTHS_BETWEEN函数尝试估算出从起始日期到结束日期经过了多少个完整月份,并加上剩余天数所占的月份比例。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/603363
问题五:大数据计算MaxCompute2月29号 到 3月30号 不足一个月为啥算出来1.几?
大数据计算MaxCompute2月29号 到 3月30号 不足一个月为啥算出来1.几? 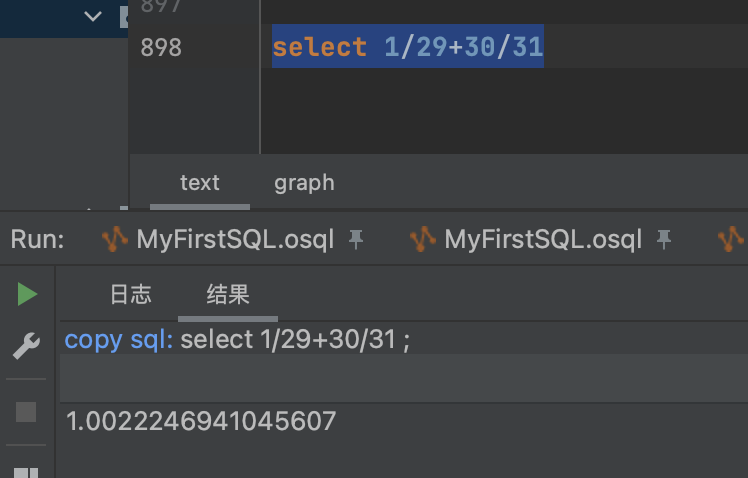
参考回答:
months_between 函数在计算月份差异时,不仅仅是简单地用天数除以 31。而是考虑到了月份中的具体日期。由于 3 月 30 日比 2 月 29 日晚一个月零一天,你实际上得到的是一个月零一天的月份数,然后那一天占据一个月的比例按 1/31 计算
1(月) + 1(天)/ 31(作为月的估算长度) = 1.032258064516129
也就是1 - (30 / 31) = 1.032258064516129
关于本问题的更多回答可点击原文查看:
