问题一:大数据计算MaxCompute有办法使查询不存在分区的sql报错吗?
大数据计算MaxCompute有办法使查询不存在分区的sql报错吗? 我们有的连表,其中一个表可能没有对应日期的分区,但是这种查询不报错,只是数据不对。比较不容易排查。
参考回答:
在大数据计算MaxCompute中,如果查询不存在的分区,系统会执行失败并返回报错。
当您在MaxCompute中执行SQL查询时,如果涉及到的表分区不存在,而且没有使用if exists条件,那么查询将无法成功执行,并会返回一个错误,提示分区不存在。这一机制可以帮助用户及时发现数据问题,避免因查询不存在的分区而得到错误的数据结果。
此外,自2018年1月10日起,MaxCompute对于新创建的项目,默认情况下不允许对分区表进行全表扫描操作。这是为了减少不必要的I/O源的浪费,同时降低按量计费模式下的费用。因此,在查询分区表数据时,必须明确指定分区。
为了确保数据的准确性和便于排查问题,建议在编写涉及分区表的查询语句时,总是显式指定分区键。这样,如果某个表缺少对应日期的分区,查询将因为找不到相应的分区而报错,从而避免了返回不正确的数据。同时这也有助于提高查询效率和减少不必要的计算成本。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/606772
问题二:请问我在阿里云上创建了一个用户RAM,然后在大数据计算MaxCompute里面添加了该用户(租户)?
请问我在阿里云上创建了一个用户RAM,然后在 大数据计算MaxCompute里面添加了该用户(租户),然后 又在项目里面 创建了一个角色,同时授权此角色可访问 整个项目,最后 把用户 加入此角色,现在的情况是 客户端 远程 连接 maxcompute (使用刚才创建的ram用户) 显示 没有权限查询项目下面的表,报错信息如下:
failed: ODPS-0130013:Authorization exception - Authorization Failed [4019], You have NO privilege 'odps:Select' on {acs:odps:*:projects/seal/schemas/logdb/tables/test}
参考回答:
根据您提供的信息,您在阿里云上创建了一个RA用户,并在MaxCompute中添加了该用户(租户)。然后,您在项目中创建了一个角色,并授权该角色可以访问整个项目。最后,您将用户添加到该角色中。
然而,您在客户端远程连接MaxCompute时遇到了权限问题,无法查询项目。报错信息显示您有'odps:Select'权限。
要解决这个问题,您可以尝试以下步骤:
- 确保您的RAM用户具有足够的权限来访问MaxCompute。您可以登录阿里云控制台,检查RAM用户的权限设置,确保它具有访Mampute中为该用户分配的角色是否具有正确的权限。您可以登录Maxompute控制台,查看角色的权限设置确保它具有执行查询操作的权限。
- 检查您的查询语句是否正确。请确保您使用的是正确的项目名称、模式和表名,并且查询语句符合MaxCompute的语法规则。
- 如果问题仍然存在,您可以尝试联系阿里云技术支持寻求帮助。他们可以帮助您进一步排查问题并提供解决方案。
请注意,以上步骤仅提供了一般性的建议,具体解决方法可能因您的环境和配置而异。建议您参考阿里云官方文档或与阿里云技术支持团队联系以获取更准确的帮助。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/606771
问题三:请问一下大数据计算MaxCompute,ODPS在查询时报CTE子查询过于复杂?
请问一下大数据计算MaxCompute,ODPS在查询时报CTE子查询过于复杂,除了修改查询语句外还有其他的解决办法吗? 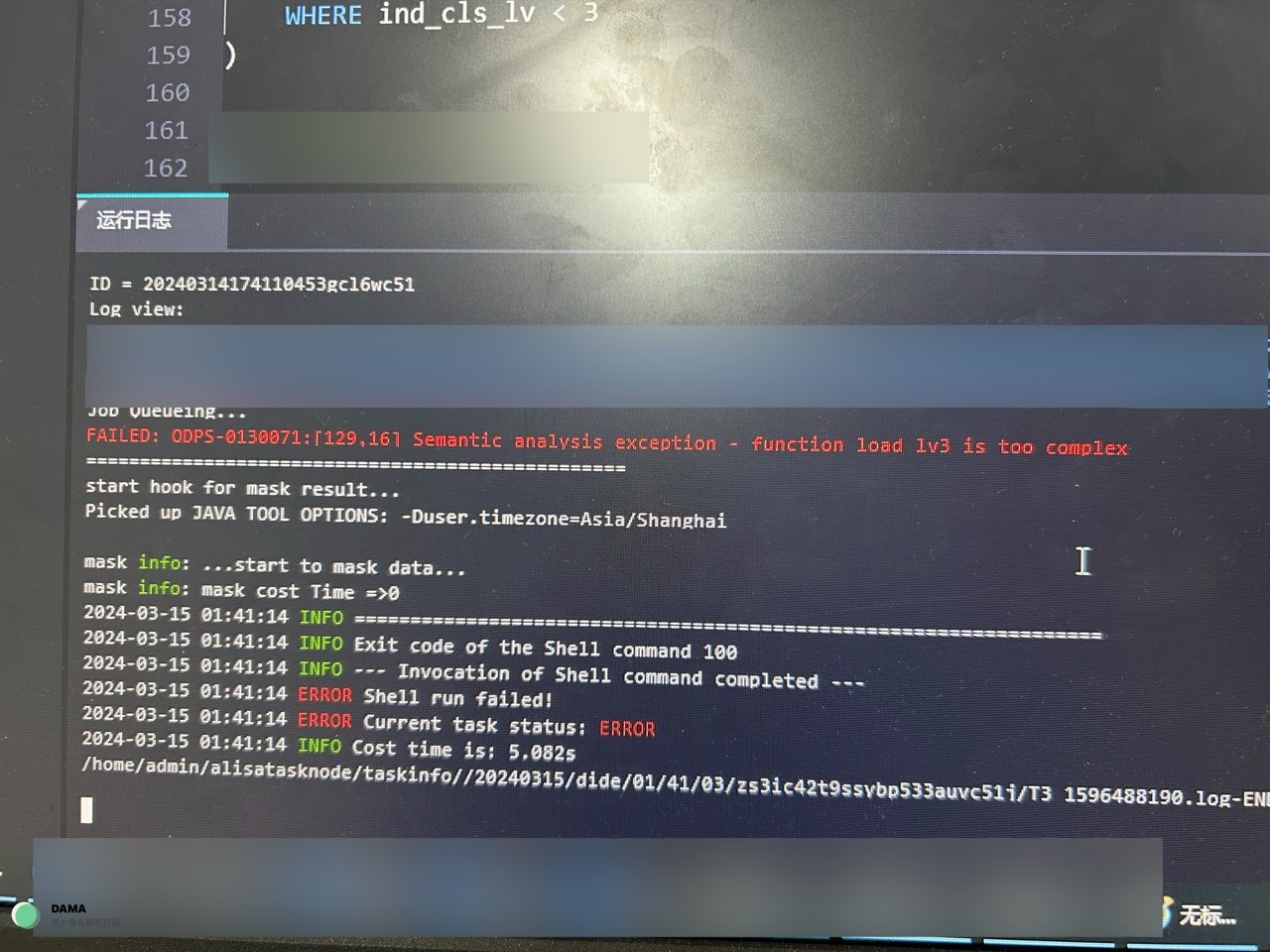
参考回答:
在大数据计算中,CTE(Common Table Expression)子查询是一种常用的技术,用于将复杂的查询分解为更简单、易于理解的子查询。然而,在某些情况下,CTE子查询可能会变得过于复杂,导致查询性能下降或执行失败。
除了修改查询语句以简化CTE子查询外,您还可以考虑以下几种方法来解决这个问题:
- 优化查询逻辑:重新审视您的查询逻辑,看是否有可能通过调整查询顺序、使用不同的连接方式或过滤条件来减少CTE子查询的复杂度。
- 数据预处理:如果可能的话,在查询之前对数据进行预处理,例如创建临时表或视图,以便在CTE子查询中使用更简单的表达式。
- 使用索引:如果您的数据存储在支持索引的数据库中,可以考虑为相关列创建索引以提高查询性能。
- 分布式计算:对于特别复杂的查询,可以考虑使用分布式计算框架(如MapReduce或Spark)来处理数据,并将结果存储在MaxCompute或ODPS中供后续查询使用。
- 分批查询:如果查询涉及大量数据,可以考虑将数据分成较小的批次进行处理,以避免一次性加载过多数据导致的内存不足问题。
- 增加资源:根据需要,可以增加MaxCompute或ODPS的资源(如内存、CPU等),以提高查询性能和处理能力。
需要注意的是,具体的解决方案取决于您的查询需求和数据规模。在进行任何更改之前,建议先备份原始数据和查询语句,并在测试环境中验证更改的效果。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/606762
问题四:大数据计算MaxCompute pip安装命令是什么原因?
大数据计算MaxCompute pip安装命令pip install -U imbalanced-learn报错:DEPRECATION: Python 2.7 reached the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 is no longer maintained. pip 21.0 will drop support for Python 2.7 in January 2021. More details about Python 2 support in pip can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support pip 21.0 will remove support for this functionality.
WARNING: The directory '/root/.cache/pip' or its parent directory is not owned or is not writable by the current user. The cache has been disabled. Check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag.
Defaulting to user installation because normal site-packages is not writeable
Collecting imbalanced-learn
Downloading imbalanced-learn-0.12.0.tar.gz (29.7 MB)
ERROR: Exception:
Traceback (most recent call last):
File "/usr/lib/python2.7/site-packages/pip/_internal/cli/base_command.py", line 223, in _main
status = self.run(options, args)
File "/usr/lib/python2.7/site-packages/pip/_internal/cli/req_command.py", line 180, in wrapper
return func(self, options, args)
File "/usr/lib/python2.7/site-packages/pip/_internal/commands/install.py", line 321, in run
reqs, check_supported_wheels=not options.target_dir
File "/usr/lib/python2.7/site-packages/pip/_internal/resolution/legacy/resolver.py", line 180, in resolve
discovered_reqs.extend(self._resolve_one(requirement_set, req))
File "/usr/lib/python2.7/site-packages/pip/_internal/resolution/legacy/resolver.py", line 385, in _resolve_one
dist = self._get_dist_for(req_to_install)
File "/usr/lib/python2.7/site-packages/pip/_internal/resolution/legacy/resolver.py", line 337, in _get_dist_for
dist = self.preparer.prepare_linked_requirement(req)
File "/usr/lib/python2.7/site-packages/pip/_internal/operations/prepare.py", line 480, in prepare_linked_requirement
return self._prepare_linked_requirement(req, parallel_builds)
File "/usr/lib/python2.7/site-packages/pip/_internal/operations/prepare.py", line 505, in _prepare_linked_requirement
self.download_dir, hashes,
File "/usr/lib/python2.7/site-packages/pip/_internal/operations/prepare.py", line 257, in unpack_url
hashes=hashes,
File "/usr/lib/python2.7/site-packages/pip/_internal/operations/prepare.py", line 130, in get_http_url
from_path, content_type = download(link, temp_dir.path)
File "/usr/lib/python2.7/site-packages/pip/_internal/network/download.py", line 163, in call
for chunk in chunks:
File "/usr/lib/python2.7/site-packages/pip/_internal/cli/progress_bars.py", line 168, in iter
for x in it:
File "/usr/lib/python2.7/site-packages/pip/_internal/network/utils.py", line 88, in response_chunks
decode_content=False,
File "/usr/lib/python2.7/site-packages/pip/_vendor/urllib3/response.py", line 576, in stream
data = self.read(amt=amt, decode_content=decode_content)
File "/usr/lib/python2.7/site-packages/pip/_vendor/urllib3/response.py", line 541, in read
raise IncompleteRead(self._fp_bytes_read, self.length_remaining)
File "/usr/lib64/python2.7/contextlib.py", line 35, in exit
self.gen.throw(type, value, traceback)
File "/usr/lib/python2.7/site-packages/pip/_vendor/urllib3/response.py", line 451, in _error_catcher
raise ReadTimeoutError(self._pool, None, "Read timed out.")
ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out. 是什么原因?
参考回答:
这个错误是因为在安装imbalanced-learn时,Python 2.7已经到达了生命周期的尽头,不再维护。同时,pip 21.0将放弃对Python 2.7的支持。此外,还出现了读取超时的错误。建议升级Python版本并使用支持ython 3的pip版本。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/606758
问题五:大数据计算MaxCompute我查询后发现这个用户其实在这个project中?
大数据计算MaxCompute我查询后发现这个用户其实在这个project中,他现在的问题是,他在老的sql窗口下可以跑,在新的sql窗口下会出现这个报错? 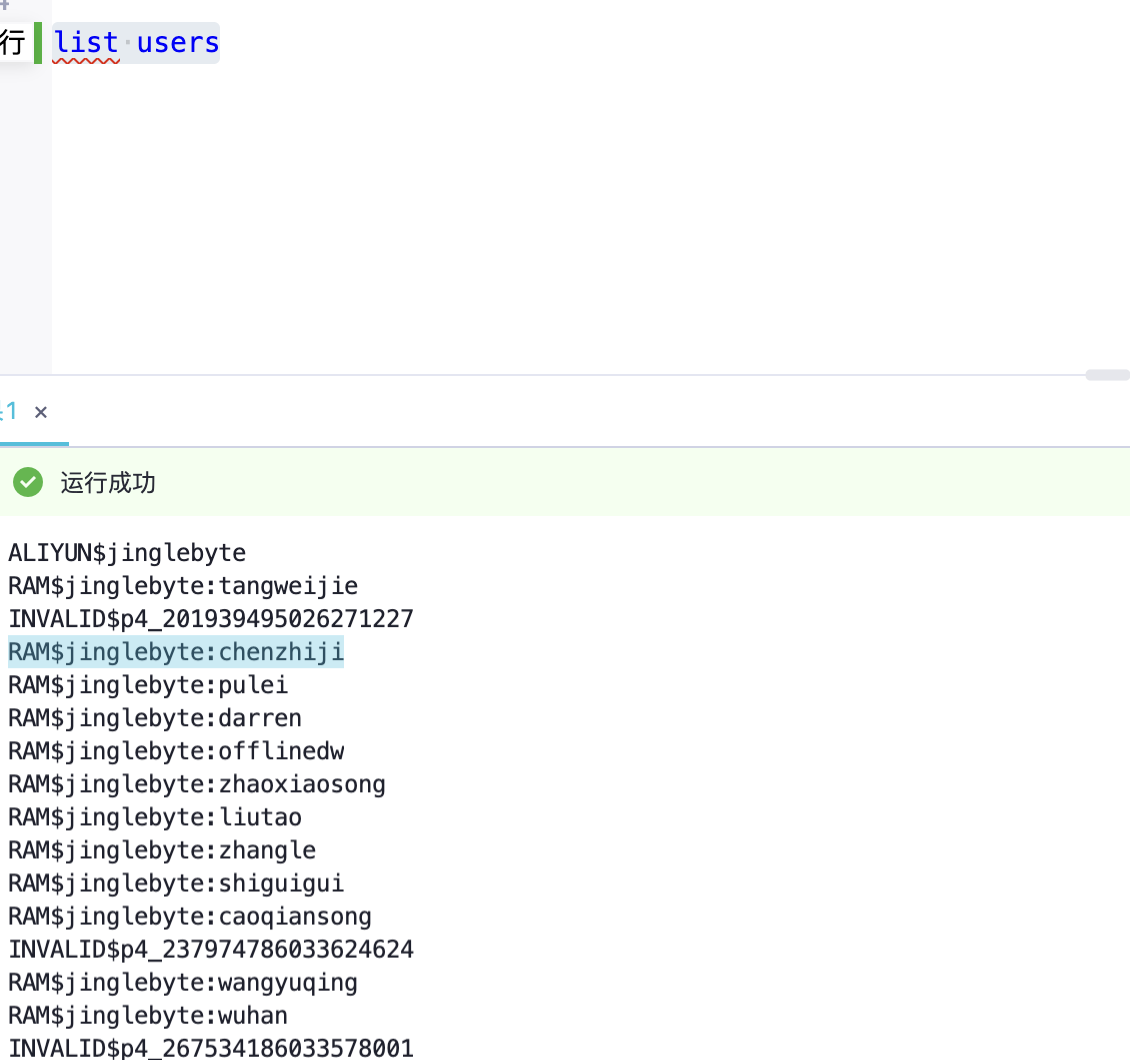
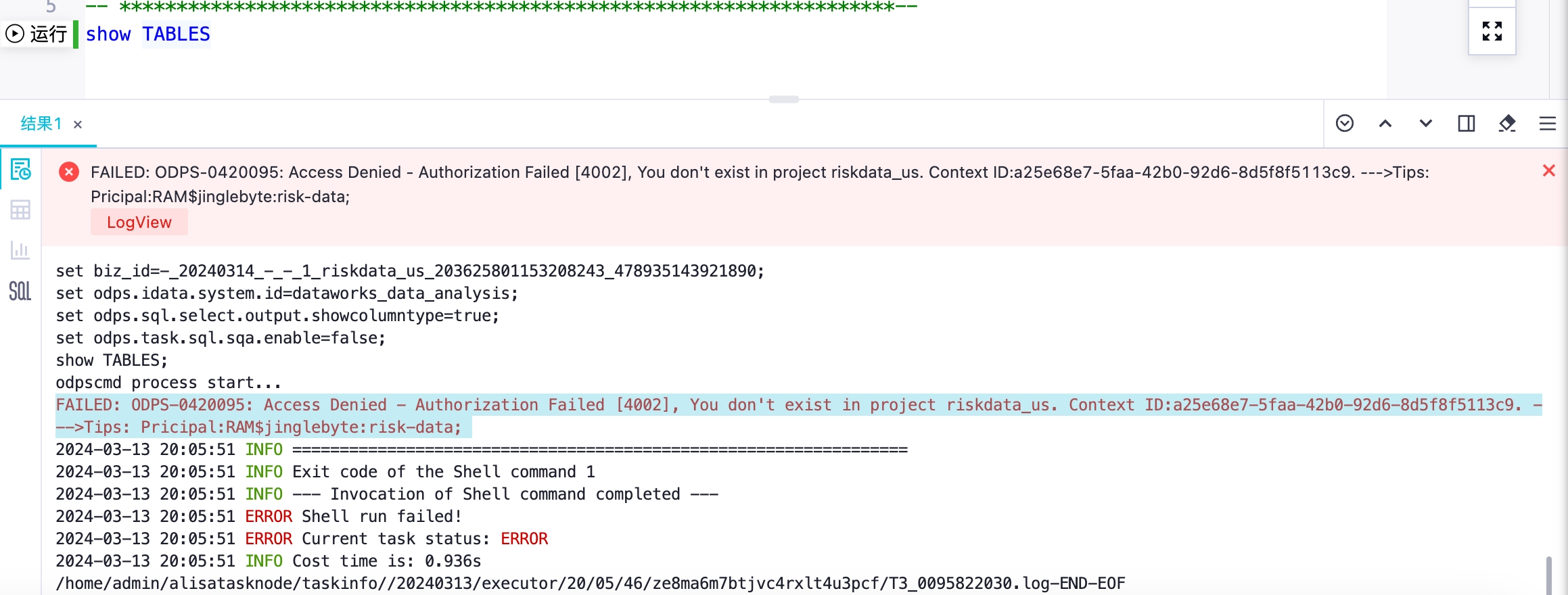
参考回答:
如果在MaxCompute中查询后发现某个用户实际上存在于该project中,但该用户在新的SQL窗口下出现报错,可能是由于以下原因之一:
- 权限问题:该用户可能没有足够的权限来执行某些操作或访问某些资源。请确保该用户具有正确的权限,并且已经正确配置了其角色和权限。
- 会话问题:如果该用户在新的SQL窗口下无法执行操作,可能是因为该用户的会话没有正确建立或已过期。请尝试重新登录或刷新页面以重新建立会话。
- 网络问题:有时网络连接问题可能会导致查询失败或出现错误。请检查您的网络连接并确保它稳定可靠。
- 代码问题:如果该用户在新的SQL窗口下无法执行操作,可能是因为代码存在问题。请仔细检查代码并确保它符合MaxCompute的语法和规范。
如果您仍然无法解决问题,建议您联系阿里云的技术支持团队,他们可以提供更详细的帮助和支持。如果在MaxCompute中查询后发现某个用户实际上存在于该project中,但该用户在新的SQL窗口下出现报错,可能是由于以下原因之一:
- 权限问题:该用户可能没有足够的权限来执行某些操作或访问某些资源。请确保该用户具有正确的权限,并且已经正确配置了其角色和权限。
- 会话问题:如果该用户在新的SQL窗口下无法执行操作,可能是因为该用户的会话没有正确建立或已过期。请尝试重新登录或刷新页面以重新建立会话。
- 网络问题:有时网络连接问题可能会导致查询失败或出现错误。请检查您的网络连接并确保它稳定可靠。
- 代码问题:如果该用户在新的SQL窗口下无法执行操作,可能是因为代码存在问题。请仔细检查代码并确保它符合MaxCompute的语法和规范。
如果您仍然无法解决问题,建议您联系阿里云的技术支持团队,他们可以提供更详细的帮助和支持。
关于本问题的更多回答可点击原文查看:
