问题一:大数据计算MaxCompute授权服务后报错变了,还是不行,如何解决?
参考回答:
当前账号还是没有访问ddl里的bucket权限,麻烦再按照文档核查下权限步骤 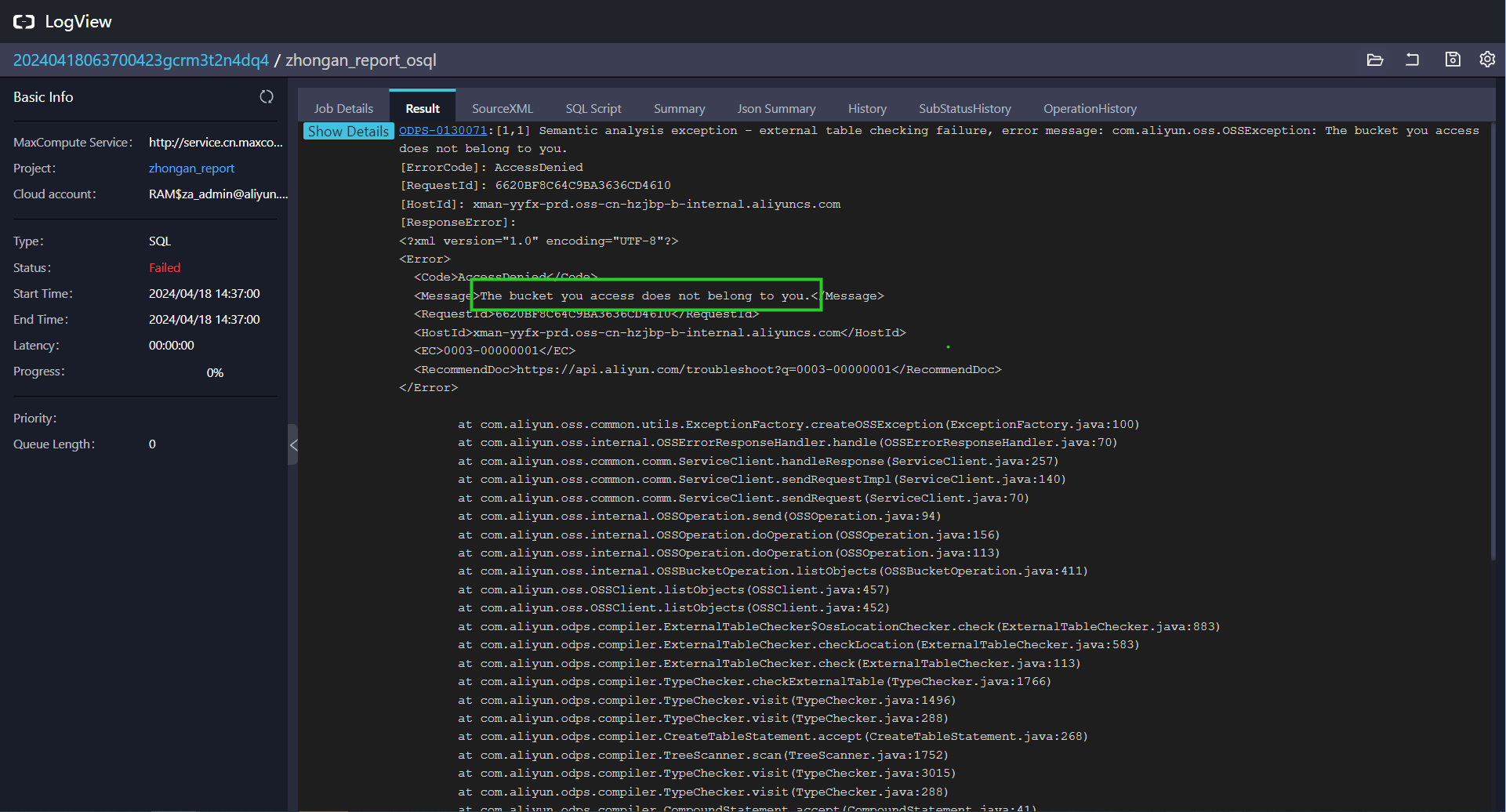
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/616164
问题二:大数据计算MaxCompute这个是什么问题?
大数据计算MaxCompute这个是什么问题?
[{field:c_customer_sk, type:bigint, comment:}, {field:c_customer_id, type:char(16), comment:}, {field:c_current_cdemo_sk, type:bigint, comment:}, {field:c_current_hdemo_sk, type:bigint, comment:}, {field:c_current_addr_sk, type:bigint, comment:}, {field:c_first_shipto_date_sk, type:bigint, comment:}, {field:c_first_sales_date_sk, type:bigint, comment:}, {field:c_salutation, type:char(10), comment:}, {field:c_first_name, type:char(20), comment:}, {field:c_last_name, type:char(30), comment:}, {field:c_preferred_cust_flag, type:char(1), comment:}, {field:c_birth_day, type:bigint, comment:}, {field:c_birth_month, type:bigint, comment:}, {field:c_birth_year, type:bigint, comment:}, {field:c_birth_country, type:varchar(20), comment:}, {field:c_login, type:char(13), comment:}, {field:c_email_address, type:char(50), comment:}, {field:c_last_review_date_sk, type:char(10), comment:}] 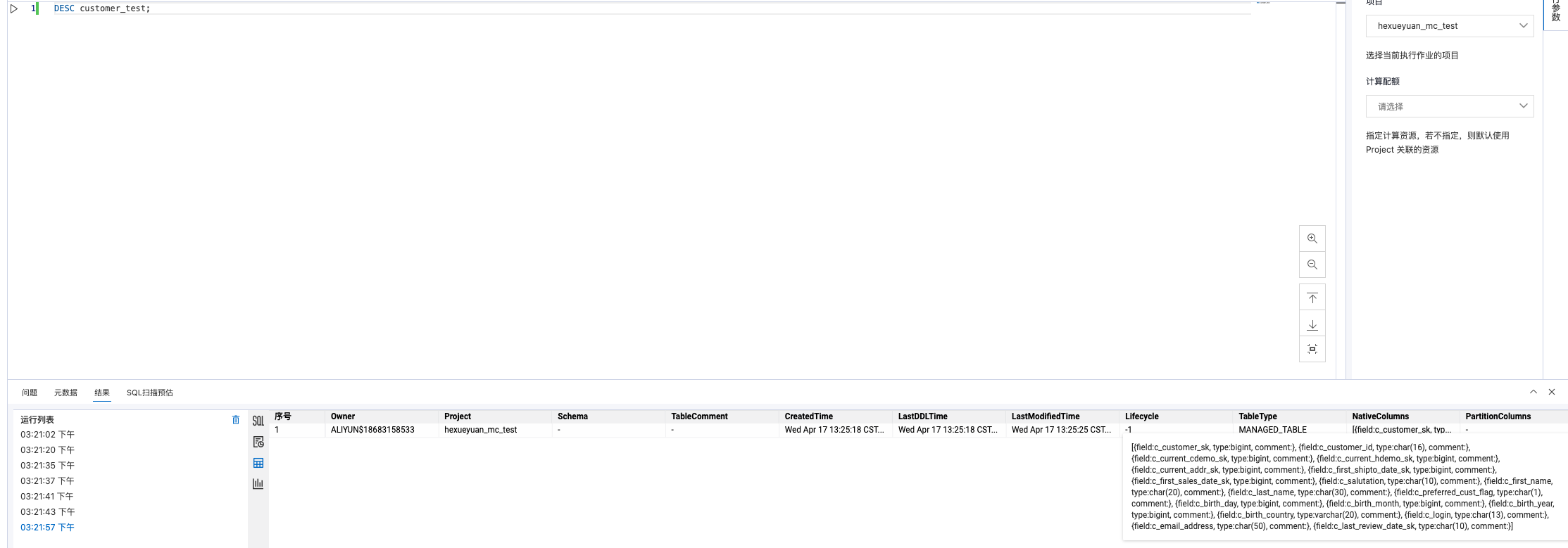
参考回答:
 这个去掉
这个去掉
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/616161
问题三:大数据计算MaxCompute注释掉之后执行还是有这个报错呢?
大数据计算MaxCompute注释掉之后执行还是有这个报错呢? 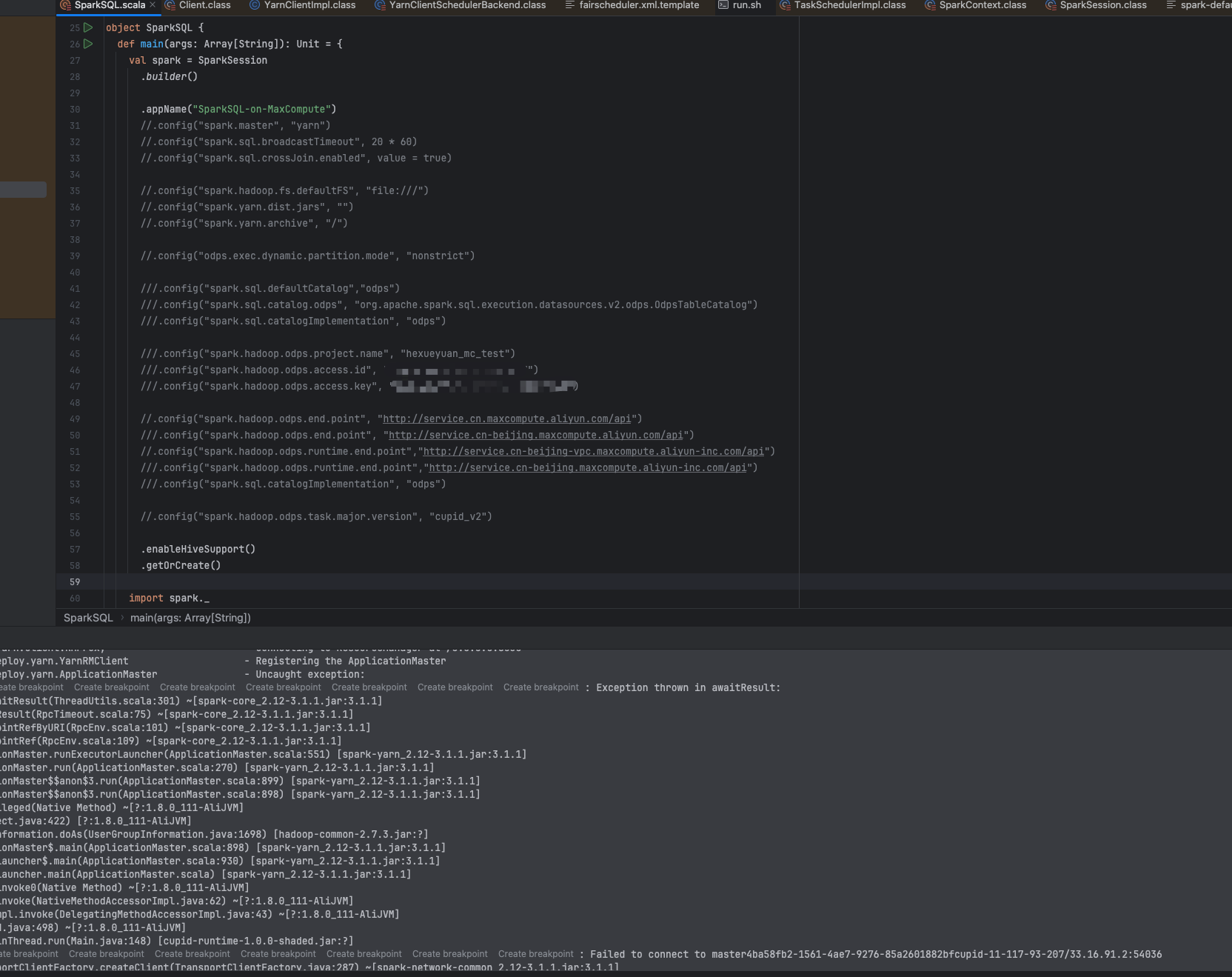
参考回答:
加spark.master = yarn、spark.submit.deployMode = cluster再试下。
spark3的改了,提交方式不太一样了 ,
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/616149
问题四:大数据计算MaxCompute这个报错辛苦帮忙看看是什么原因呢?
大数据计算MaxCompute这个报错辛苦帮忙看看是什么原因呢,rm连不上am吗?看起来是哪里没配置对 
参考回答:
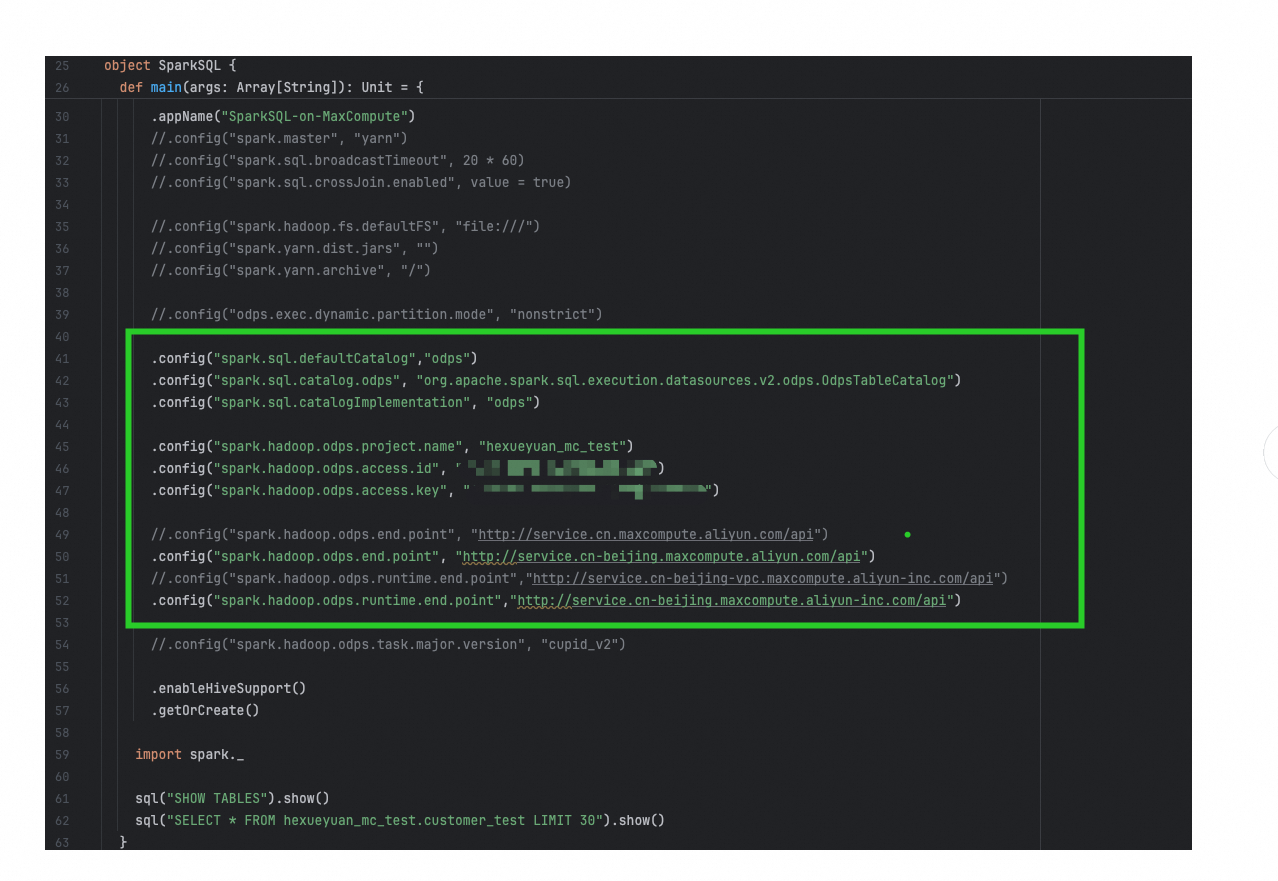
spark客户端执行,得去掉这些配置,加到客户端的conf里就行。执行的话参考:https://help.aliyun.com/zh/maxcompute/user-guide/running-modes?spm=a2c4g.11186623.0.0.f2a52658o92BZB#section-1tq-j9h-c6m ,
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/616146
问题五:大数据计算MaxCompute写了一个python udf,执行的时候只有mapper,是啥情况呀?
大数据计算MaxCompute写了一个python udf,执行的时候只有mapper,速度很慢,是啥情况呀? 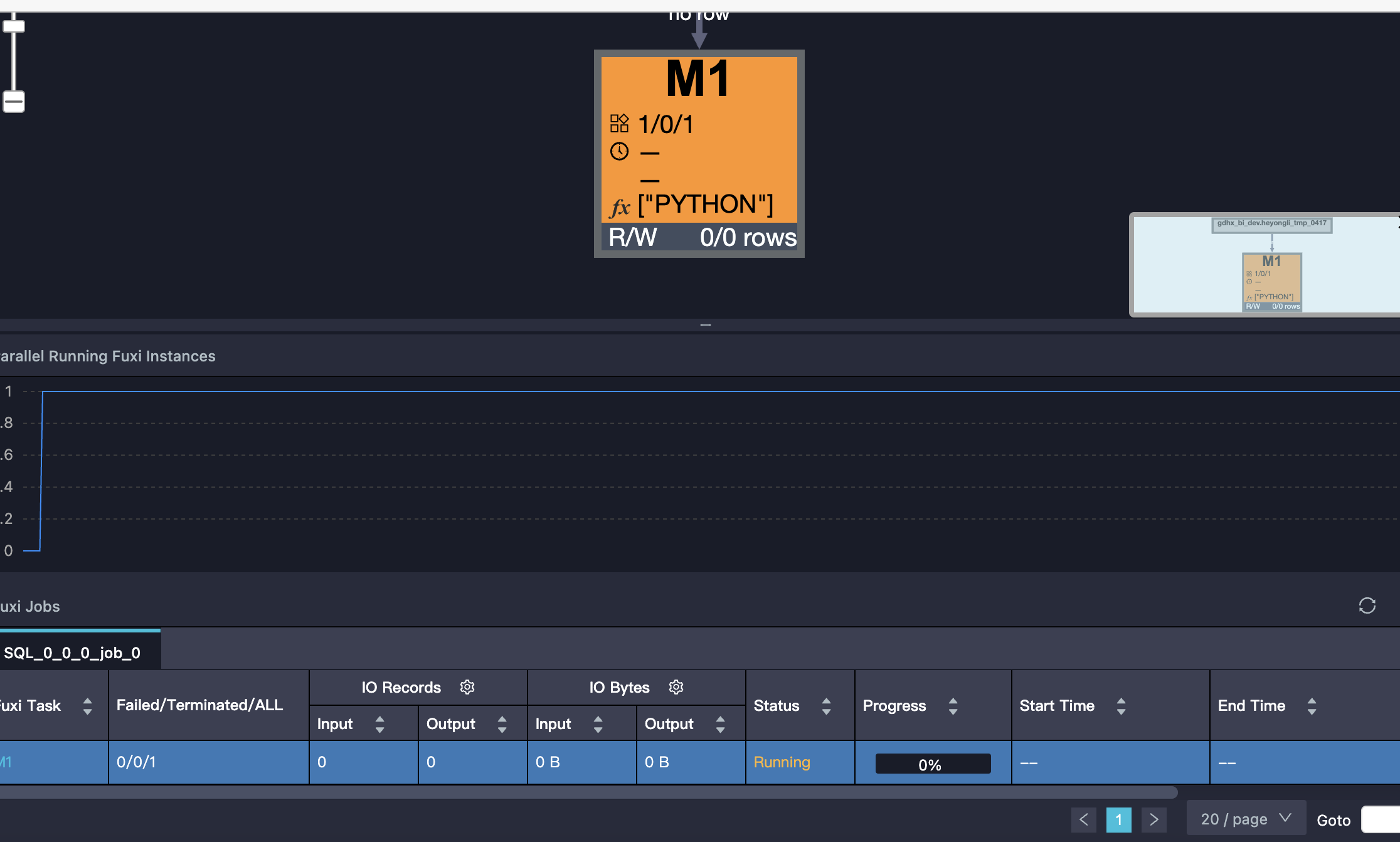
设置 odps.stage.reducer.num这种也没什么用
参考回答:
这个数据量太少 目前没办法切 后面我们会加一个flag来切 ,
关于本问题的更多回答可点击原文查看:
