分布式系统详解--架构(Hadoop-克隆服务器)
分布式系统上一个呢,写了一下分布式系统的单机版安装教程,并且对于hadoop来说进行了一个单机版的应用测试。我们这篇文章主要讲解一下利用hadoop来进行分布式搭建。当然在搭建分布式集群之前也要仔细的了解一下hadoop的一些原理,比如说:HDFS原理和YARN原理。
一、克隆服务器(基于虚拟机VMware)
右键服务器--> 管理-->克隆 (下一步)录制小视频~~
二、克隆后配置(修改新创建的服务器信息)
2.1 修改主机名
A. 临时修改 hostname centos01 这个重启之后就会失效。
B. 保存修改 /etc/sysconfig/network。添加HOSTNAME=centos01

2.2 修改网卡信息
vi /etc/udev/rules.d/70-persistent-net.rules
看到两个几乎相似的信息,删掉上面的,留着下面的。将NAME="eth1"改为NAME="eth0"。

2.3 修改ip信息
vi /etc/sysconfig/network-scripts/ifcfg-eth0
1,修改UUID将其设置为另外一个十六进制的数
2,HWADDR数值为该服务器中网络适配器里面高级设置中的MAC地址。
3,IPADDR的值是IP 地址,我的虚拟机中服务器为233,将233设置为了234。自己可以自行修改

2.4 修改映射
vi /etc/hosts
根据上面的MyLinux 添加centos01的映射。

2.5 重启网卡
service network restart

倘若重启失败,最后一个出现了失败,那就重启一下服务器,再重新测试一下。
这样我们就克隆一个服务器完成。
2.6 重新克隆一个服务器,叫做centos02 ip地址是192.168.71.235

2.7 互相ping命令,看是否能进行ping通
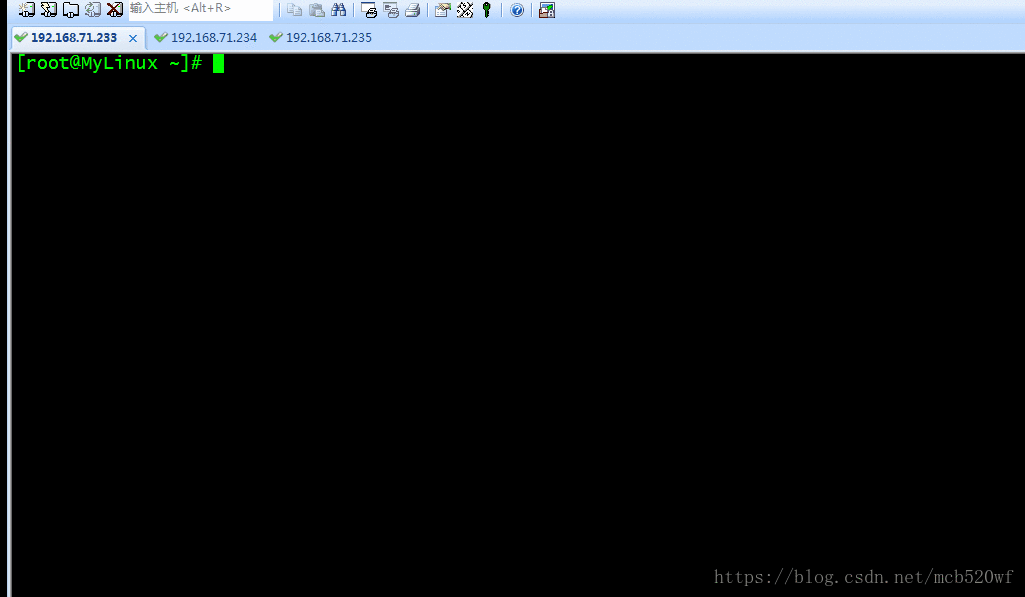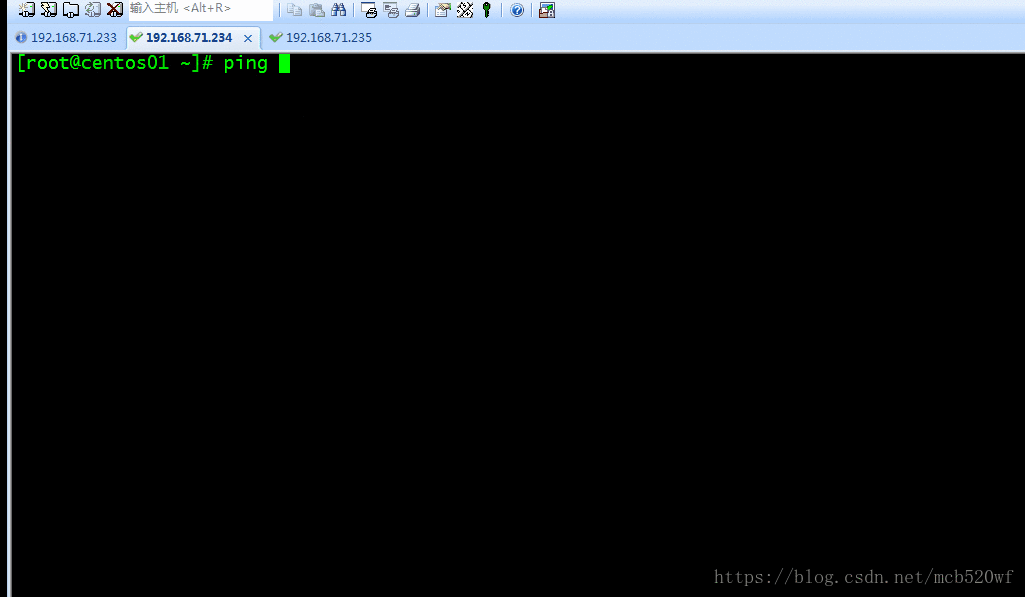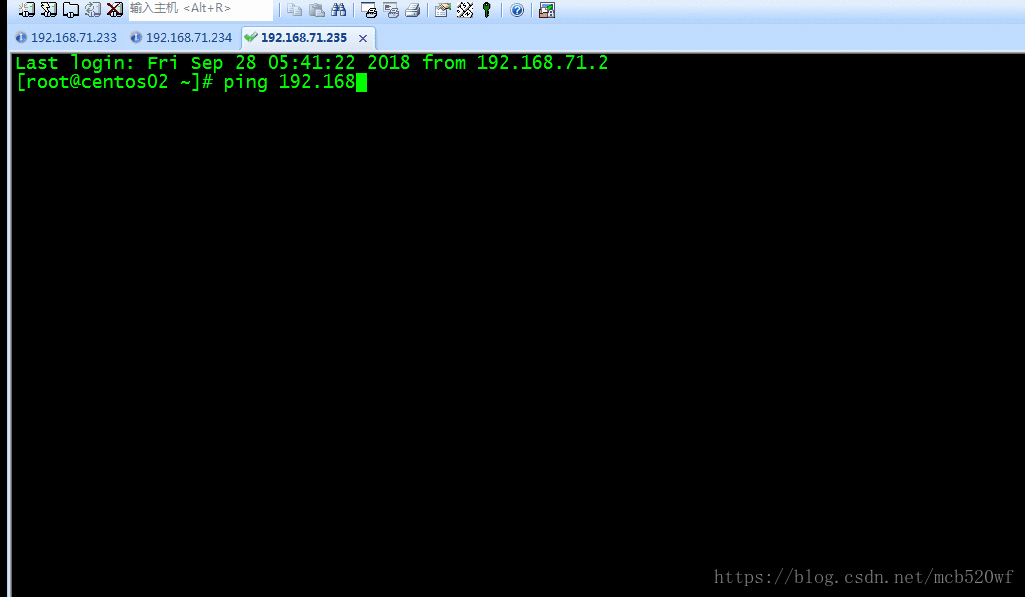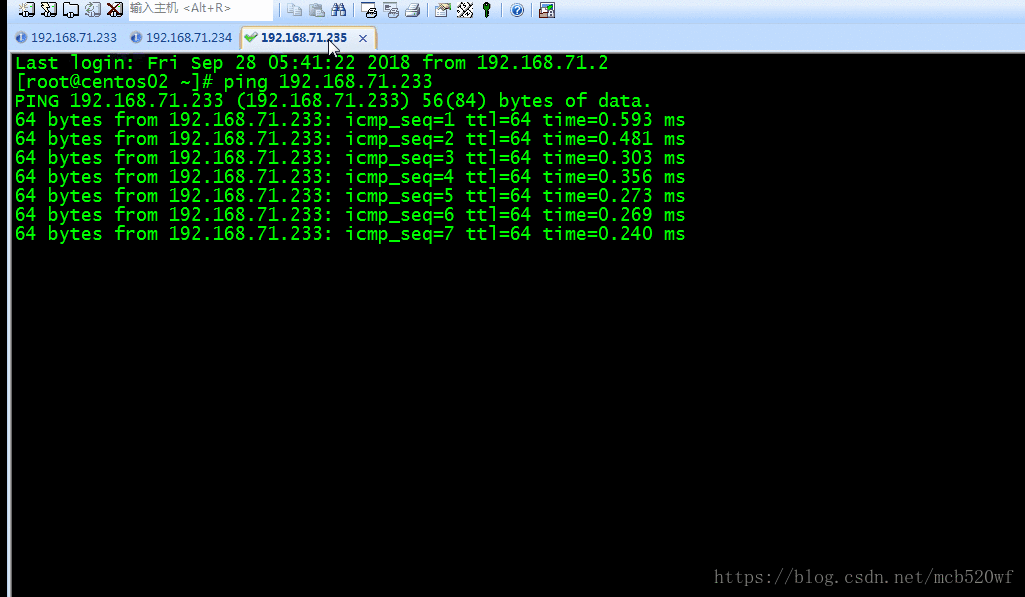
OK。进行到这儿我们就可以进行下一步配置了,就是hadoop的集群配置,这个放在下一个来说~~


