开篇、追本溯源
随着企业产品业务不断扩大、用户量增加、功能需求复杂化,原有的系统架构逐渐无法满足高效运行、快速响应市场变化以及支持大规模并发访问等需求,在这种背景下,服务从单体应用架构,发展到资源隔离拆分多服务架构、负债均衡多集群架构,再到更细粒度的微服务容器编排架构,业务的增长不断促进架构的演进。本人有幸在刚进入互联网公司没几年就接触到相对大型的互联网产品的开发,从几十万、几百万到现在上千万 DAU,业务的增长不仅仅是对现有架构的挑战,更是推动技术创新和架构升级的动力。企业需要不断审视和调整其技术架构,以适应业务发展,保持竞争力,服务的部署架构以及开发者的技术认知,也跟随着高 QPS 场景不断的迭代升级。
这里将会对一些高性能的技术方案进行总结,带来一册武功秘籍【高性能 - 葵花宝典】,供大家品鉴,希望能给各位看官带来一点收获。
第一章、神兵利器:缓存
想要提高服务的性能,首当其冲大家都会想到神兵利器:缓存,缓存可以是:应用服务的缓存、独立的缓存服务。
应用服务的缓存一般就是存储一些使用频繁、但是存储空间占用不大,且基本不怎么变更的数据,或者作为多级缓存中的一级。
在分布式的场景在,应用服务缓存需要注意多节点缓存更新问题、一致性问题、LRU 缓存淘汰策略。
要解决分布式场景下的缓存问题,可以使用独立的缓存中间件,缓存不再存储在应用服务内存上,直接存储在缓存的中间中,这样多节点读取到的数据都是同一份,就没有上面的问题,并且缓存中间件提供的更多的功能、和高级特性的支持,可以应对更加复杂的场景。
这里主要对讲述 Redis 的一些应用场景,以及使用过程需要注意的地方。
1.1 Redis 缓存
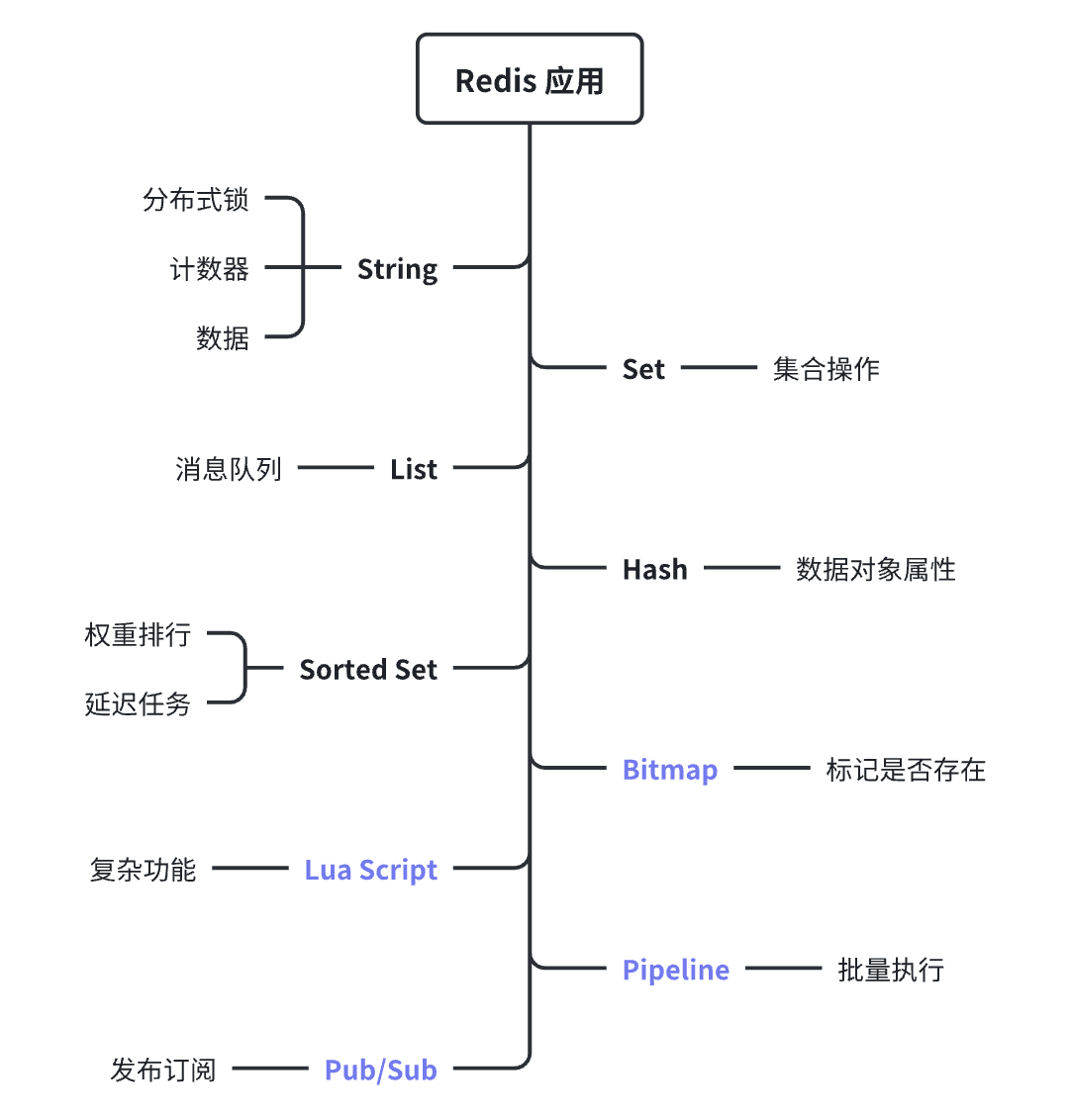
使用Redis缓存,常规的操作就是将原或者异构后的数据存储在缓存中,业务优先从缓存中拿数据,拿不到再从DB同步缓存,减少DB的查询。Redis的五种数据结构,以及其他的高级功能:bitmap、pub/sub、pipeline、lua script、Transactions,分别都有各自合适的应用场景,可以通过操作命令去学习了解,Redis的高可用部署架构、底层的数据结构原理、版本功能特性差异,以及一些面试八股文需要掌握的内容,大家有兴趣的可以谷歌搜索下,有很多相关的学习资料,这里就不细说。
1.2 应用场景
具体业务中需要使用哪个数据结构或者高级功能,这个需要根据场景、数据结构、性能,等多方面去评估考量和最终选择。
这里例举自己在实践过程中对Redis使用场景列举:
1.3 效果对比
举栗一个使用redis提升性能的 Case,高并发业务接口实时的从 DB 中查询运营推荐的商品数据给到客户端展示,而且运营商品数据变更不频繁。
数据库集群能够支撑的 QPS 有限,在高峰期或者大促场景下容易把数据库打崩。这里通过引入 Redis 中间件降低数据库压力,提升接口性能。
使用 Redis 优化前后对比:
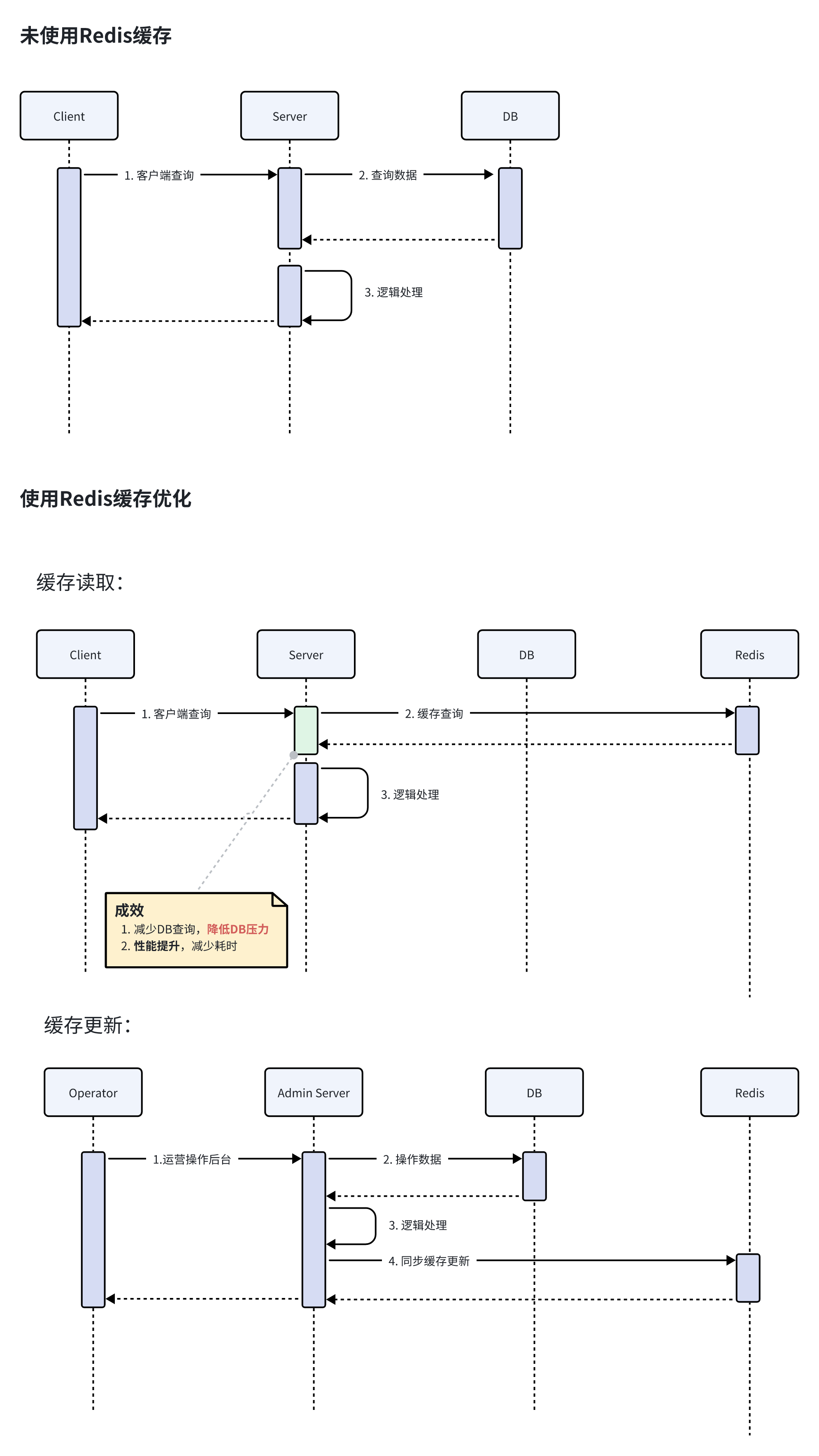
修炼心得:
- 提升性能: 由于 redis 存储在内存中,读写速度极快,减少数据库访问,从而提升了服务的性能、吞吐量,对于高并发和延迟敏感的场景尤其有效。
- 减轻DB压力: 请求优先走到 redis,降低了DB的访问,减轻了负载压力。
- 灵活数据结构:redis 支持的5种数据结构和多种高级功能,灵活搭配,可以解决目前业务中大部分场景需要。
- 高可用: redis 有多种部署架构方式,根据不同的业务架构需要选择,redis 的高性能设计以及分布式架构保障服务的高可用,通过资源监控预警,及时发现潜在的问题和异常,确保服务的稳定。
1.4 避坑指南
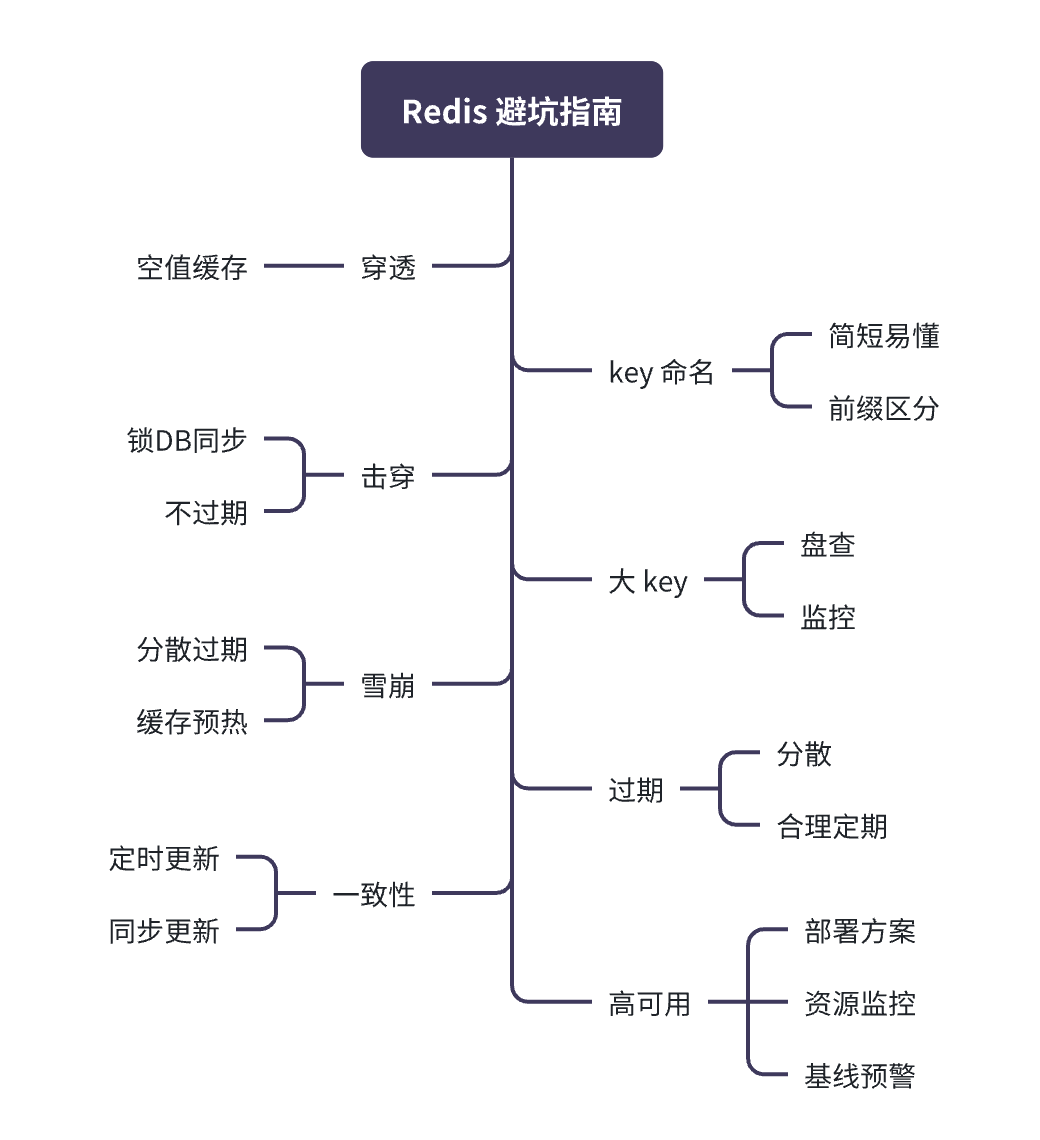
在使用缓存的过程中,需要考虑到一些相对极致的场景问题,比如:缓存的穿透、击穿、雪崩、等问题。
缓存穿透: 是指查询一个一定不存在的数据时,由于缓存中没有此数据,每次查询都会落到数据库层。恶意攻击或程序bug可能会不断尝试不存在的数据查询,使得数据库承受巨大压力。
缓存击穿: 特指对于那些热点key,在缓存失效的瞬间,大量并发请求同时到达,这些请求全部穿透缓存直达数据库,对数据库形成巨大压力。
缓存雪崩: 是指在一段时间内,大量缓存在同一时刻集体失效,后续请求均直接打到数据库,可能导致数据库瞬间压力过大,服务不可用。
大Key: 避免在redis中存储大量数据,导致内存大量使用,以及大key操作导致堵塞,分布式部署下节点内存使用不均,等问题。
Key命名: key长度不宜太长,尽可能简短且清晰表达用途,key需要能够根据业务领域、模块区分前缀,易于后续治理区分业务,尤其是对于redis集群共用的业务,后续做大key清理、redis拆分迁移。
过期时间: 一般使用redis做热数据存储,也存在一些做持久化的场景,但是大部分都是需要对key设置过期时间,避免冷缓存,长期占用内存空间,资源被浪费。
数据一致性: 数据DB更新,未能及时同步redis,导致数据不一致问题,对于一致性要求高的业务,需要重点考虑更新策略,保障一致性。
1.5 特殊巧用
批量操作: 需要高效执行批量操作,减少网络延迟,以及提高客户端与Redis服务器间交互效率的场景,可以使用 pipeline 进行批量执行,提高处理速度。
多命令 原子操作 : 对于有多个命令的操作,又需要保障原子性,可以考虑使用 lua 多命令原子操作,保障数据的一致性。通过lua脚本还可以实现各种个性化的需求,但是使用过程需要考虑性能问题、避免有过多耗时操作,堵塞了整个 redis 命令通道。
第二章、鬼斧神工:MQ
在过往的业务开发过程中,经常会有一些功能需求,它需要在核心接口中拓展,但是非接口主要流程内容,同时可以接受一定延迟处理,我们往往会引入鬼斧神工:MQ中间件,巧妙的使用,将达到奇效。
2.1 应用场景
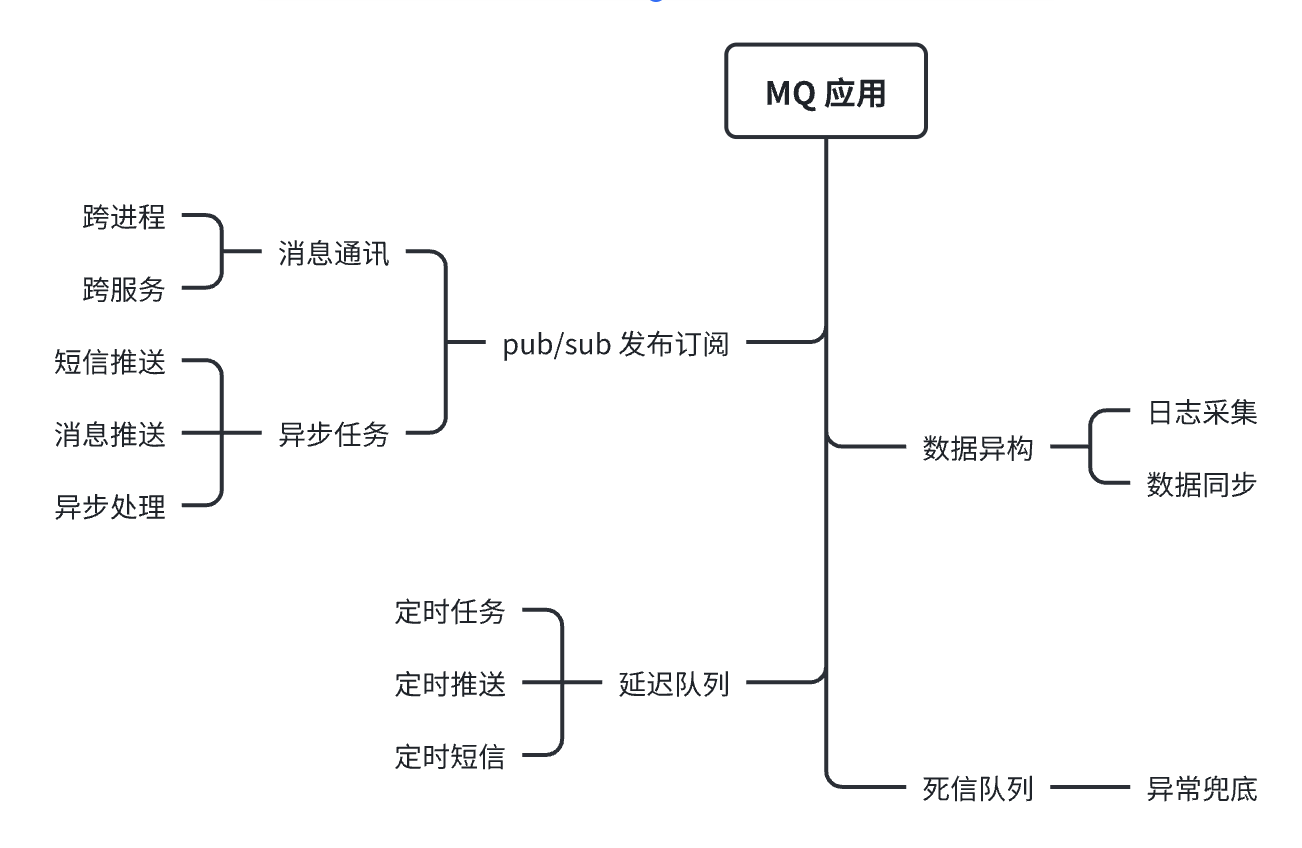
一般这些场景会用到MQ,如:高并发场景的削峰填谷、系统解耦、数据异构的业务场景、跨进程、服务的通讯、pus/sub、定时任务、等场景,需要有消息中间 MQ:kafka、rabitmq、rockmq、... 等,通过 MQ 中间件的使用,保障服务的稳定、提高性能和吞吐率。
MQ 的使用场景列举:
2.2 效果对比
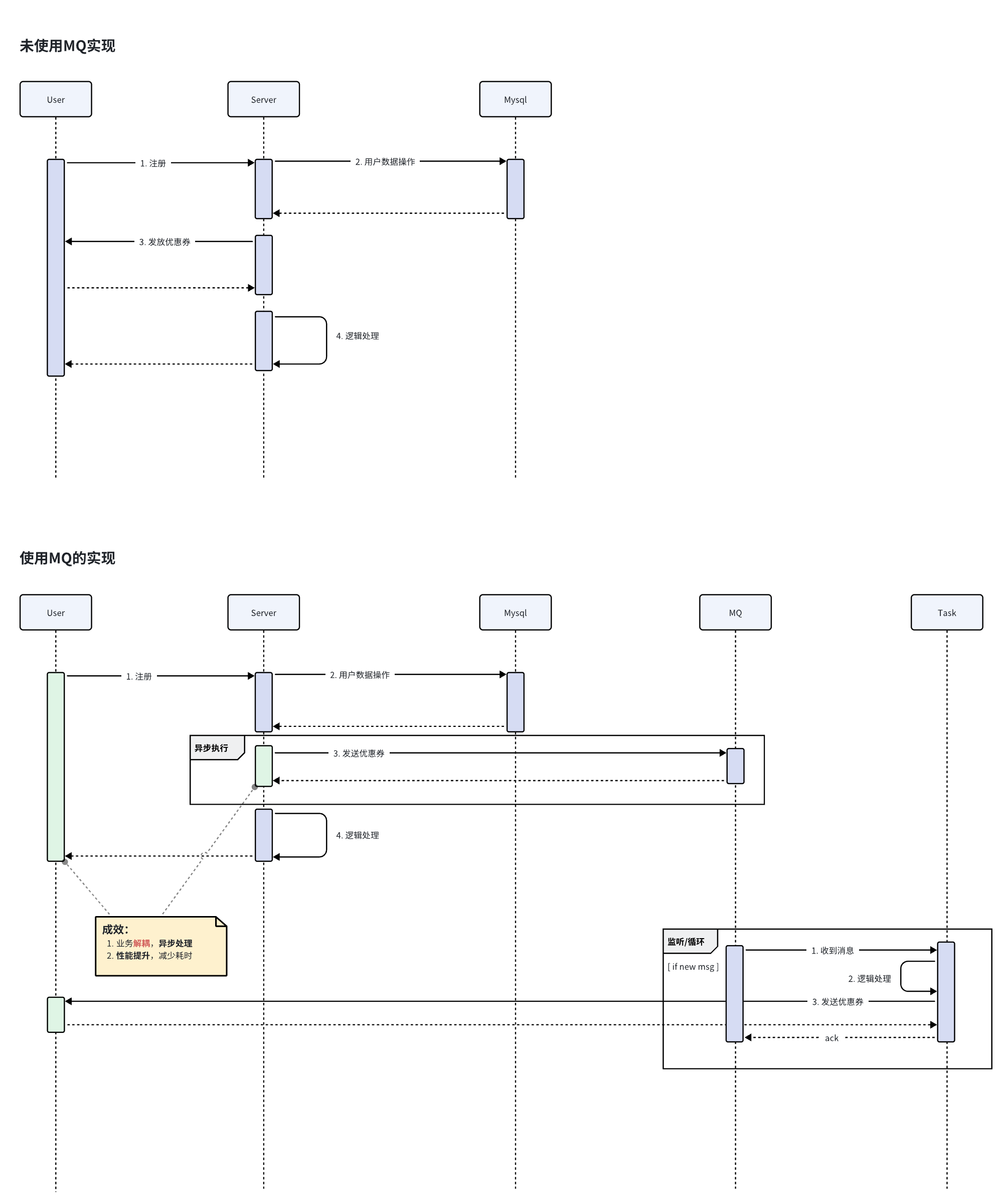
举栗一个使用发布订阅的简单 Case,用户注册成功后,给用户发放优惠券。
此流程中发放优惠券并非注册的主要流程,且能够接受注册成功后短暂延迟收到优惠券,基于这些前提条件下,可以将这个流程单独提取出来,使用 MQ 异步消费实现。
用户中心作为生产者,将注册成功后的用户信息组装上报到 MQ Topic,然后再起任务作为消费者监听 Topi c进行异步的消费。
后续如果有其他类似的需求,比如:注册成功后发送短信、推送消息、等,可以复用相同 Topic,实现业务解耦。
这里通过引入 MQ 对性能进行优化、业务解耦、提升注册流程的接口性能。
使用 MQ 优化前后对比:
修炼心得:
- 业务 解耦:生产者和消费者不需要直接知道对方的存在,降低了系统的耦合度。
- 削峰填谷:帮助平滑系统负载,处理请求峰值,防止系统过载。
- 异步处理:生产者无需等待消息处理完成即可继续工作,提高了系统响应速度和吞吐量。
- 可扩展性和灵活性:容易添加或更改消费者,适应系统变化。
2.3 避坑指南
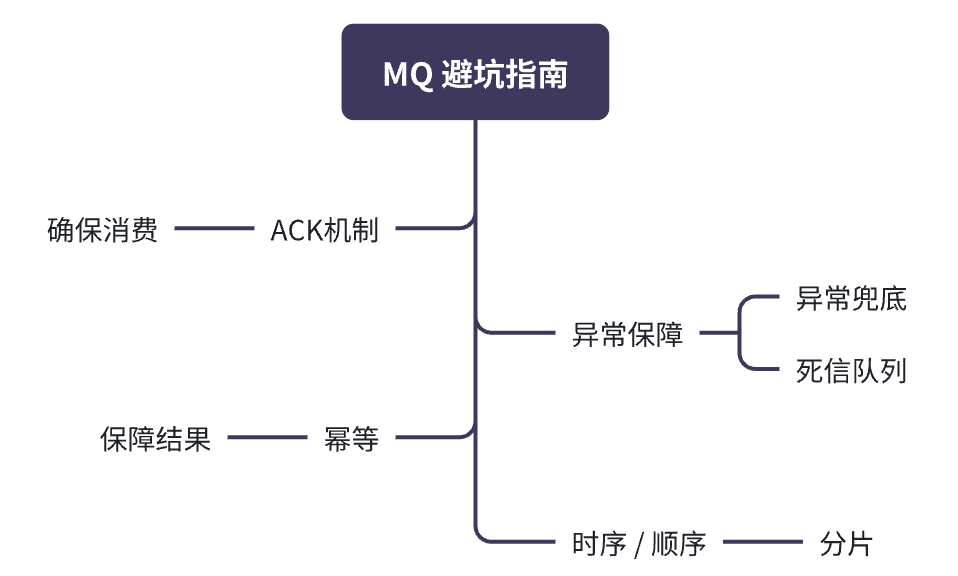
ACK 机制: 消息的执行需要确认被消费者成功消费后,才能从消息队列中移除。
容错机制: 需要保障消费结果最终成功,通过异常兜底,或者消息的死信队列,保障异常情况下消息也能够兜底处理。
结果幂等: 不能完全信任生产者的消息不重复,所以需要保障多次执行相同消息后结果幂等。
执行时序/顺序: 当存在多个消费者同时消费的时候,需要考虑消费时序问题,可能后进的会被先执行,需要保障逻辑不被影响,如果存在影响,就需要考虑将消息进行分片路由到不同队列中,进行多消费者消费,提高吞吐的同时,也能保障相同标识的消息执行时序是正确的。
第三章、分身之术:异步并行
在面对一些性能问题的时候,往往都是有一些耗时的操作(如I/O操作、网络请求、数据库访问等),除了将耗时的操作本身进行优化以外,我们还可以使用异步编程,这里使用分身之术:多线程、协程、等异步编程。
3.1 应用场景
3.1.1 异步并行
通过将多个 I/O 操作并行起来执行,等所有异步操作回来后,再进行后面的逻辑,减少了 I/O 在串行同步执行流程中步步等待,将部分上下文无直接关联的 I/O 操作并行执行,进而使整体的耗时缩短。
3.1.2 异步执行
将一些非核心流程的耗时的操作,通过异步编程,将其通过异步的方式执行,不阻塞主流程的执行。
3.2 效果对比
举栗一个业务场景,在业务逻辑处理之前,依赖三次的DB查询,且这三次的DB操作互相之间没有上下文依赖关系。
这里使用异步并行查询DB的方式,对性能进行优化。
使用异步并发执行前后的时序图对比: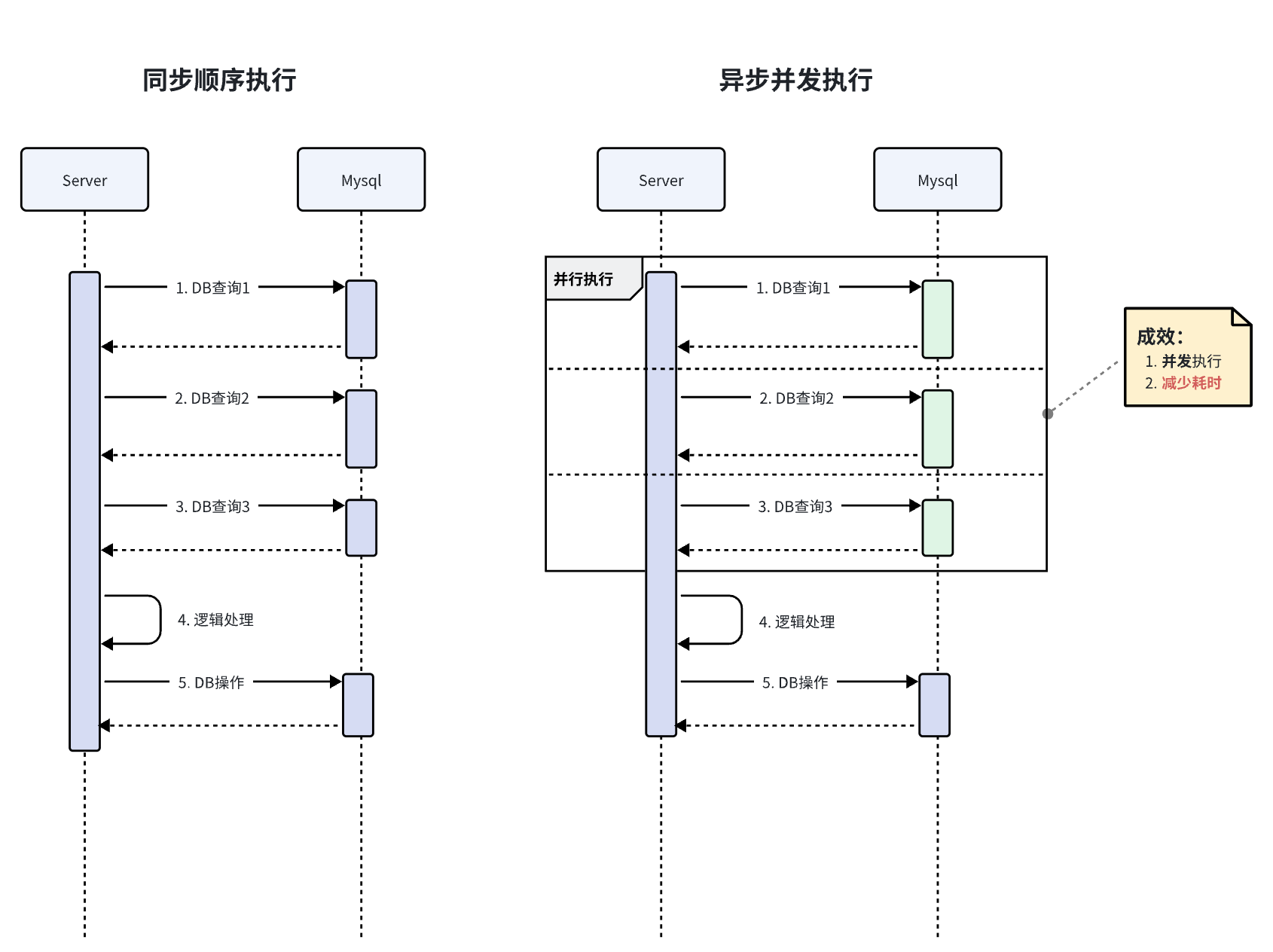
3.3 避坑指南
负载评估: 需要对并行操作的发起方和目标方服务器进行负载、服务器资源利用率的情况进行评估,在一些高并发、高峰期场景下,服务器本身负载就高,再对其并行改造,可能会事倍功半,可能会发展成压死骆驼的最后一根稻草,把服务搞崩溃了。
第四章、未卜先知:容量评估
想要保障服务的高性能,在设计阶段或者后续的治理阶段,都需要有未卜先知的能力。
根据应用的DAU、MAU,模块接口请求QPS、业务未来拓展方向、等信息,进行容量评估,作为设计的前置信息,衡量技术方案可行性。
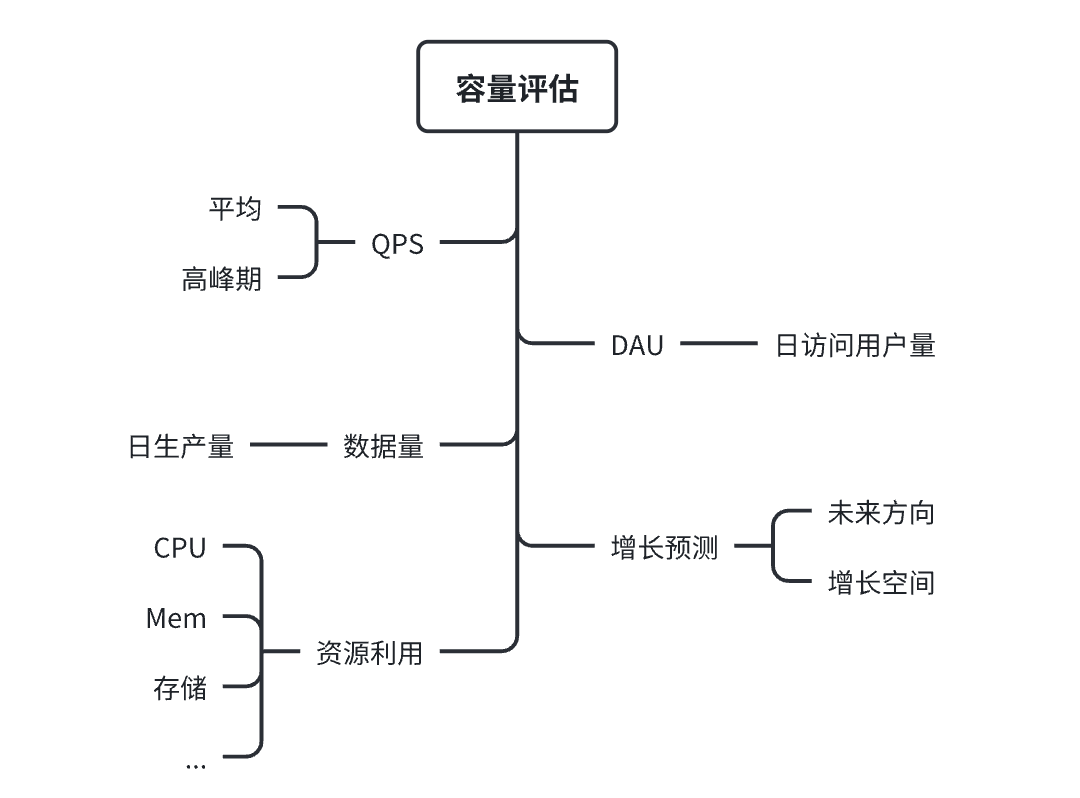
容量评估包含这些内容:
QPS : 评估每秒请求数量,平均值、最高值,用于方案设计,以及性能压测。
DAU: 评估功能日访问量。
数据量: 评估用户大概日生产数据量,用于用户表设计,如:是否纵向拆分列、横向分表、索引设计。
资源利用: 评估数据存储占用多少空间、应用服务占用多少资源(cpu、mem、i/o、load、...),用于评估部署机器配置、是否扩容 。
预测增长: 评估未来增长情况,用于方案设计考虑未来可拓展、可伸缩。
第五章、洞察:性能分析
5.1 程序的性能分析工具
不同编程语言有各自专门的或通用的性能分析工具,可以帮助开发者识别和优化代码中的性能瓶颈,提高程序运行效率。
比如 golang 程序的性能分析工具。
Pprof: 通过工具采集样本,然后通过性能剖析报告,分析性能瓶颈,常用于 CPU、内存、阻塞、goroutine 等多种类型的分析。
Benchmarking: 用于评估代码片段的执行速度,可以直接在代码中编写性能测试用例,也可以导出。
Trace: 主要用于记录和分析单个 Go 程序的内部运行时事件,如 goroutine 的生命周期、调度、同步操作(如锁的争用)、系统调用等。Go Trace 主要关注的是程序的内部行为和执行流程,帮助开发者理解程序的执行效率和资源消耗。
5.2 分布式的性能分析
企业在微服务架构的环境下,服务依赖多基础设施、除了存储系统,还有各种中间件、以及多个内部服务调用,从请求发起到最终响应,整个调用链路错综复杂,需要对分布式服务进行链路追踪,这样才能定位到在链路中的哪个环节出现了问题。
分布式 追踪 用于跟踪一个请求从进入系统到响应返回的完整路径,包括它所经过的所有服务、服务间的调用关系、调用存储、中间件、每个环节的耗时等。这对于诊断延迟问题、监控服务依赖关系、优化系统性能至关重要。
比如 golang 的分布式链路追踪 Jeager trace 需要一定的代码入侵,或者使用无代码入侵的 DeepFlow,基于 eBPF/cBPF,自动采集应用、网络、系统全栈性能指标。
第六章、千锤百炼:性能压测
开发人员通过编码实现了业务需求,功能性测试也通过了,但是并不代表它就没问题。要保障接口的高性能,QA还需要对接口进行性能压测,基于容量评估和性能测试的要求,衡量是否能够达到上线的标准。
6.1 压测标准
压测需要制定一套标准,如:什么接口需要性能测试?性能测试需要关注哪些指标?以及指标的基线要求。
以下是梳理我们 QA 的一些压测标准,仅供参考
是否 压测 : P0、P1核心业务接口、高 QPS 接口、无依赖第三方 / 内部耗时服务(算法/搜索..) 接口 。
压测 配置: 最低48线程数,支持按倍数增长、压测时间、压测倍数、等。
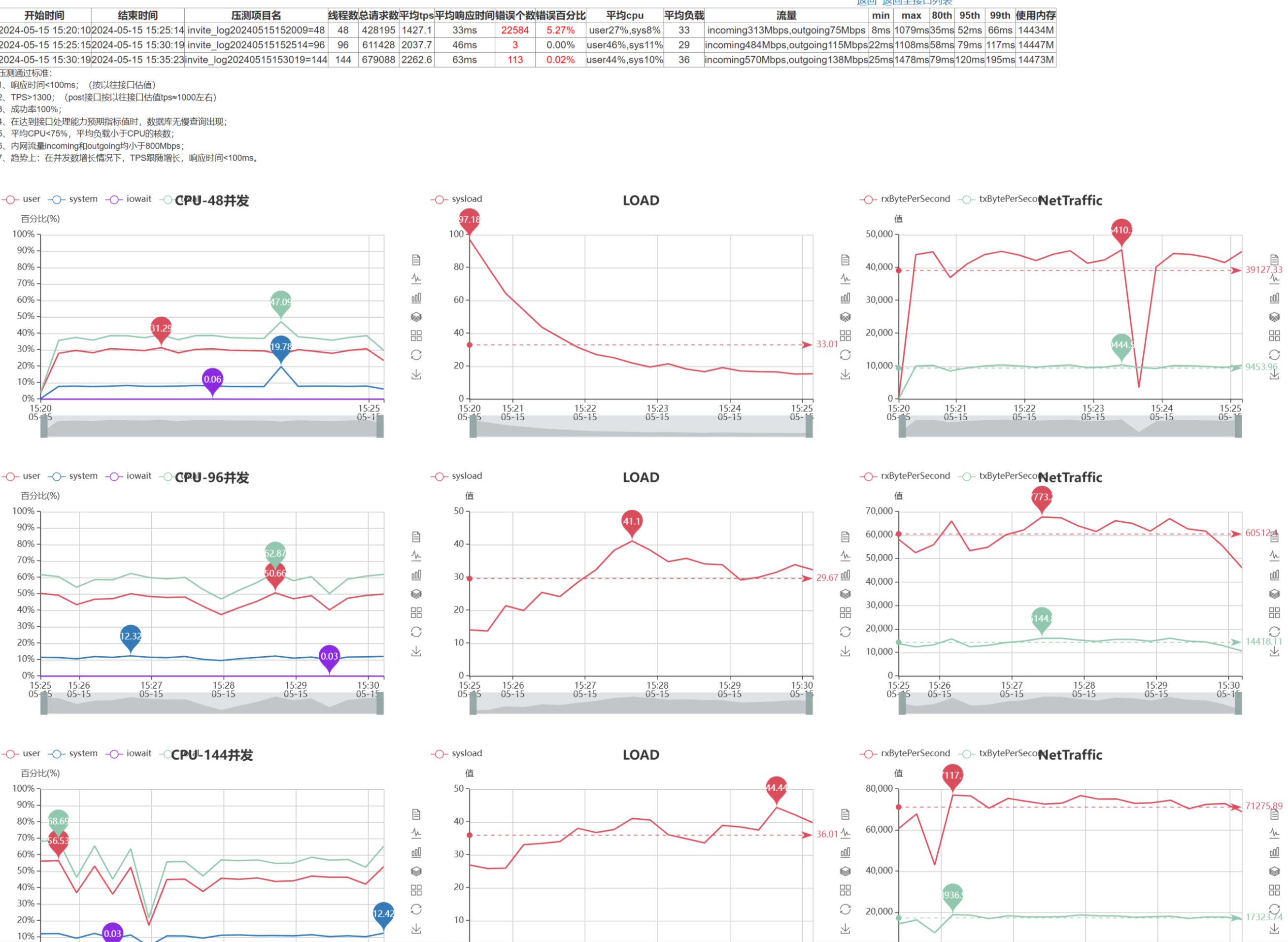
关注指标:请求数、QPS、TPS、CPU、MEM、I/O、Load、响应时间、错误数、错误率。
判断依据: 性能测试基线 + 容量评估。
压测 通过基线:
- 响应时间 < 100ms (按以往接口估值)
- TPS > 1300(post 接口按以往接口估值 tps ≈ 1000左右)
- 成功率 100%;
- 在达到接口处理能力预期指标值时,数据库无慢查询出现;
- 平均 CPU < 75%,平均负载小于 CPU 的核数;
- 内网流量 incoming 和 outgoing 均小于 800 Mbps;
- 趋势上在并发数增长情况下,TPS 跟随增长,响应时间 < 100ms。
压测 报告:
压测结束后会输出压测报告,通过报告分析判断是否达到要求。
6.2 压测工具
推荐压测工具 Jmeter 一个由Apache组织开发的基于Java的压力测试工具,能够模拟大量用户并发访问,提供丰富的图形界面和报告功能。
企业内部是基于 Jmeter 开发的压测平台,通过web页面访问和操作接口压测,查看压测结果报表。
第七章、未雨绸缪:监控预警
高性能的系统通常需要实时、准确的性能监控。通过监控关键性能指标(如CPU使用率、内存占用、磁盘I/O、网络带宽、响应时间等),可以及时发现系统瓶颈和异常状况。这些数据是衡量系统是否运行在高性能状态的重要依据,也是调优的出发点。
监控系统不仅要收集数据,还需要具备预警功能。当监控到的性能指标超过预设阈值时,预警系统会自动触发警告,通过邮件、短信、电话或集成的消息系统通知运维人员。这样可以在问题影响用户体验或造成系统故障之前,及时采取行动进行干预,保障系统的高性能运行。
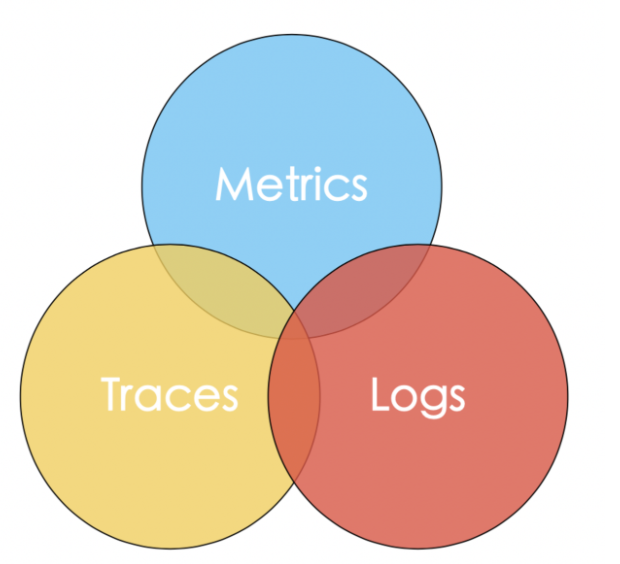
在可观测性的内容中,可以抽象出三大元素:日志(Logs) 、跟踪(Traces) 、指标(Metrics) ,这三大元素就是可观测性的三大支柱。
我的另外有一篇文章对观测性能的一些心得:如何保障服务的高可用 - 提升可观测性,有兴趣的朋友可以移步了解。
第八章、开天辟地:架构演进
8.1 架构演进
随着业务的迭代运营,DAU、MAU 增长,QPS 增多,为了应对大流量带来的三高挑战:高可用、高并发、高性能,为了保障用户体验,为了保障服务稳定性、鲁棒性,为了支撑未来3-5年的增长,基于以上的诉求点,服务架构也随之升级,从单体架构、拆分隔离部署、负载均衡多服务节点部署、再到更细粒度的分布式微服务部署。
架构设计与演进并不是一蹴而就的过程,不追求过度设计,遵循架构设计三大原则:简单优于复杂、演进优于一步到位,合适优于业界领先。
暂时无法在飞书文档外展示此内容
通过服务部署保障高性能的中心思想主要围绕以下几个方面:负载均衡、资源隔离、冗余备份、过载保护(限流、熔断、降级)、弹性扩容。
暂时无法在飞书文档外展示此内容
8.2 架构图
作为服务端开发人员,需要对应用服务的部署架构足够熟悉,尤其是分布式的微服务部署,整体链路关系网错综复杂,当线上出现请求idletimeout网络问题、服务不可用的级联效应、雪崩效应、 等问题的时候,如果你对部署架构没有足够的了解,就很难排查出问题,包括在做分布式系统设计的时候,也需要对当前架构有足够熟悉。
这里有个建议,服务端可以去找运维了解部署架构、部署细节,然后自己去画架构图,通过作图的过程加强架构理解,同时图可以可以更好的表达和呈现架构层级关系、流量走向、基础设施、组件结构细节,架构图还可以存储归档,分享新童鞋,帮助其他人了解和自己回忆。
下面是本人在基于对企业服务部署架构的了解,以及在问题排查过程,逐步了解部署细节后绘制的架构图。
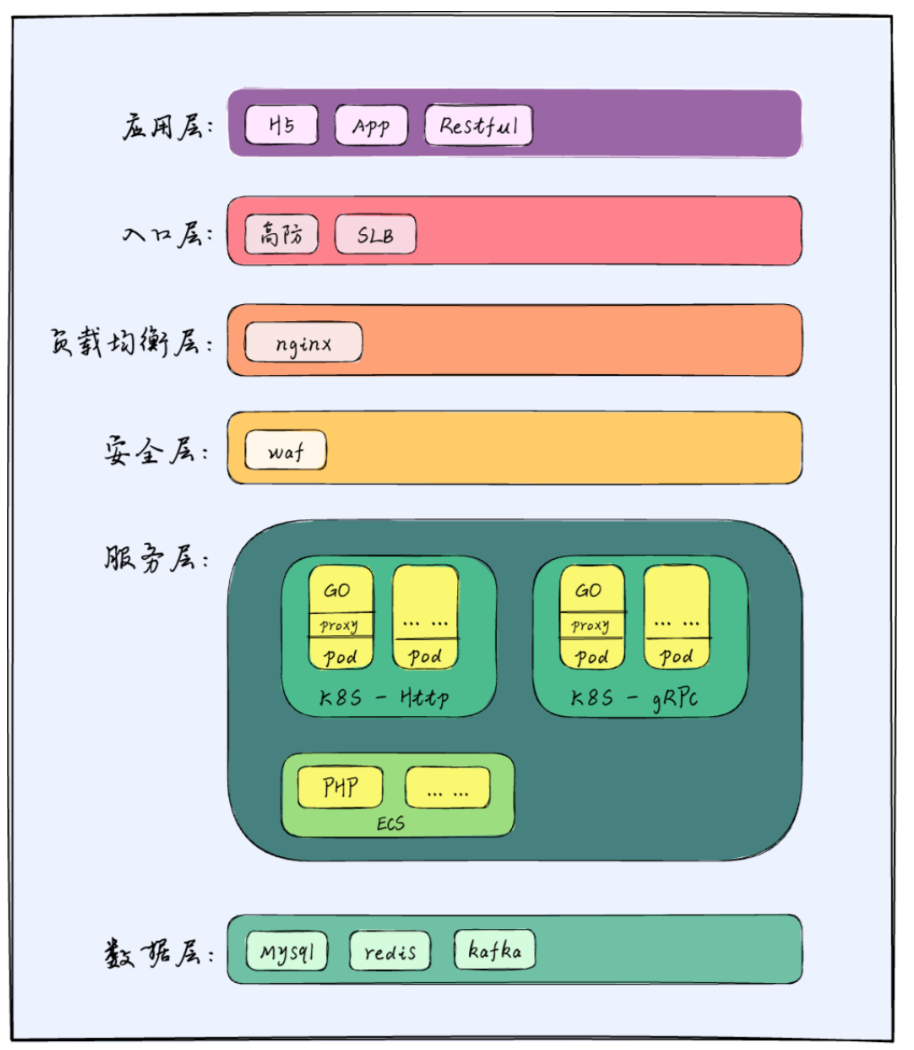
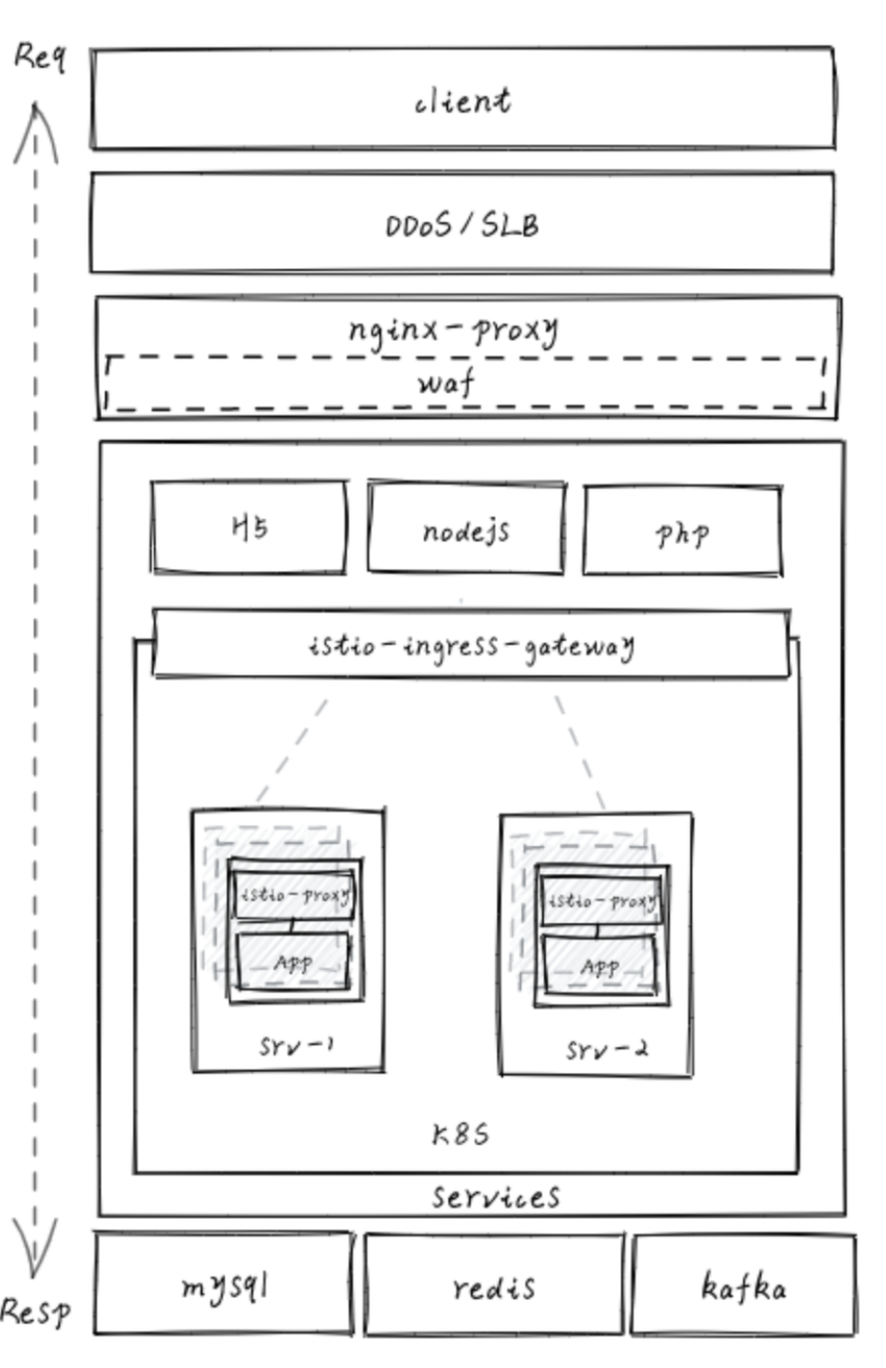
8.2.1 分层架构图
将部署服务架构分解为多个逻辑层次,以组织和分离系统的不同功能组件。
8.2.2 流量走向图
请求南北流量走向
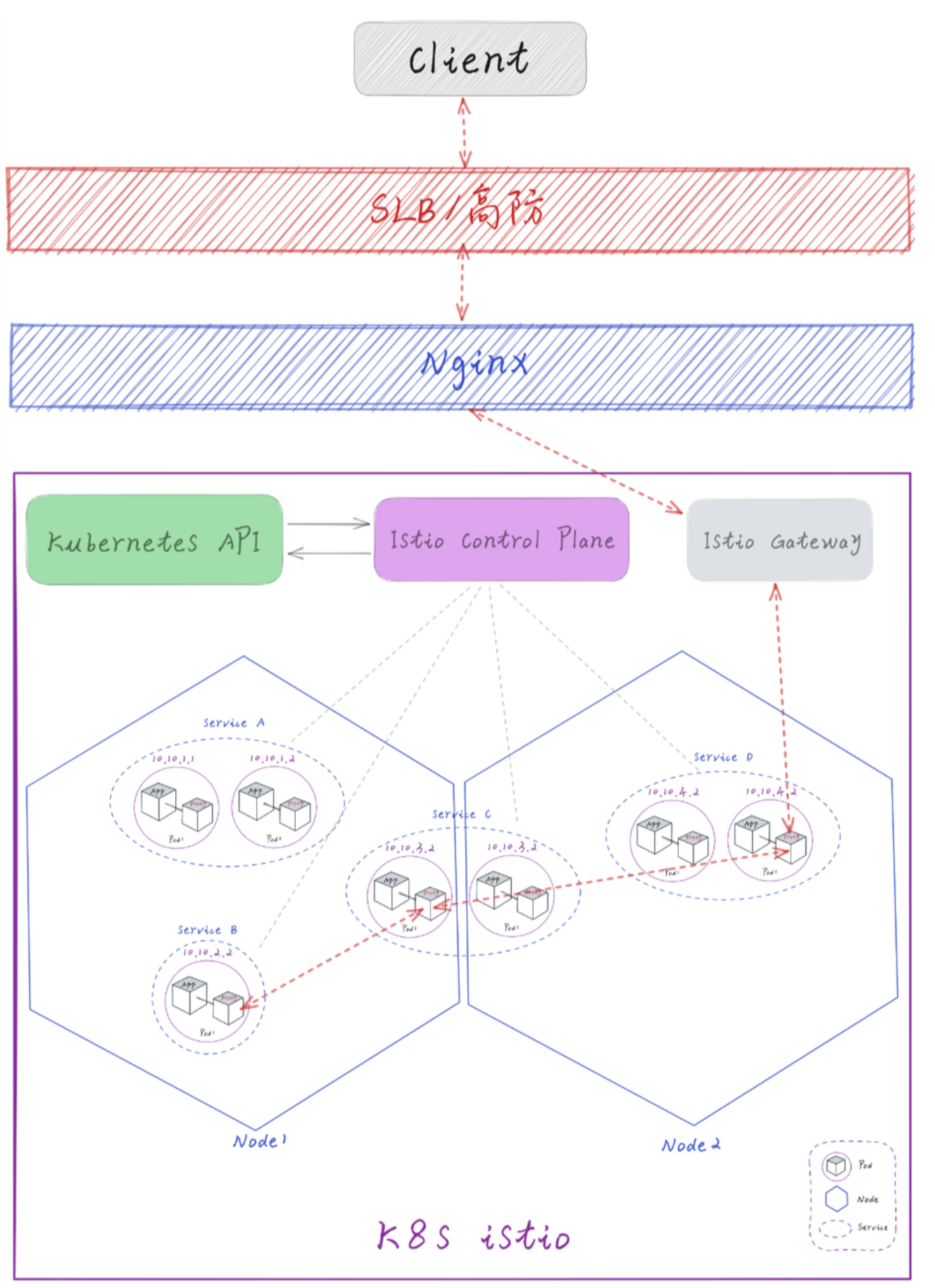
8.2.3 微服务架构图
k8s 容器编排 + istio 服务网格
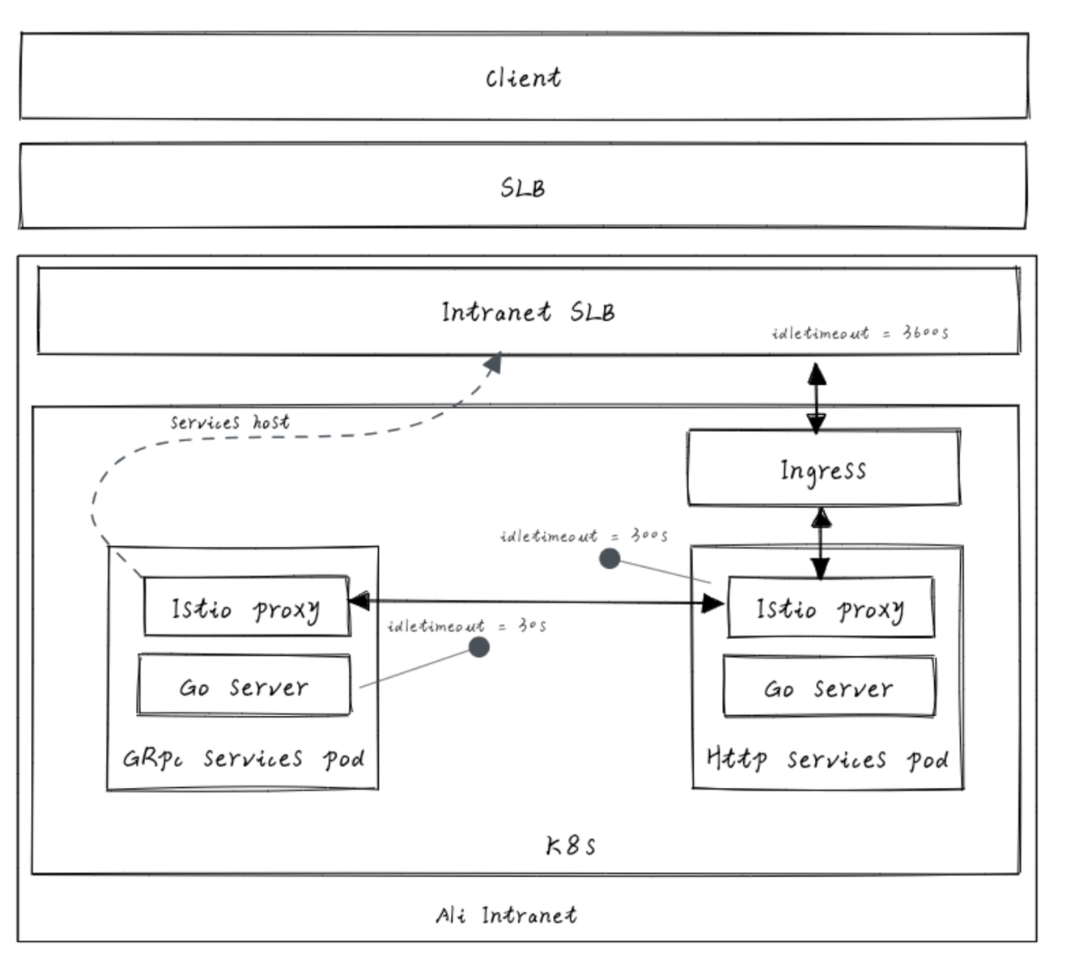
8.2.4 架构细节图
列举几个架构组件的细节图,通过图更直观了解架构组件的细节,帮助分布式方案设计、问题排查定位。
各组件 idletimeout 配置情况
终篇、结束语
生命的活力寓于不息的运动之中,技术的精髓则蕴藏于不懈的探索与实践。以上便是近期在追求高性能之路上积累的心得体会,感谢您的耐心阅读直至最后,若您认可这份分享,请不妨慷慨地点赞,让这份知识的芬芳在我们之间轻轻传递,留一抹余香于指尖。
文章收录在 Github《大话 WEB 开发》,欢迎关注。
