本文来源:支付宝体验科技公众号
前言
在OpenAI发布Sora这一突破性的“视频生成”大模型工具之时,全球科技界为之震撼。这个在“视频生成”领域开辟新天地的大模型工具,一跃成为社交媒体和科技界新的明星。Sora的登场,就像AI技术的长跑中突然出现的加速带跑,不仅令同类的Runway Pika等工具望尘莫及,更令60秒长的视频生成变得触手可及,仿佛为内容创作的天空插上了翅膀。
对我们而言,我们不仅想要追上Sora的步伐,更想超越它。在这一过程中,我们识别到视频重建的构建是实现这一理想的关键一环。这涉及如何在信息降维与Diffusion效率之间取得平衡,怎样处理时空信息的有效提取,如何处理复杂的长时间序列,以及如何维持视频中的物体跨时间帧的一致性。认识到这些技术挑战,我们对视频重建的领域投入了研究与热情,力图从中探寻解答,并在此基础上规划出一条我们自己的思路设计。我们发现通过精心设计的任务和损失函数,模型能够从视频序列中学习视频的时空属性和细粒度内容。这不仅能贡献在视频生成领域,对视频理解的领域也同样提供了新的思路和方法。本文将介绍我们紧随Sora之后对于视频重建的构建探索之路,汇报我们的调研成果,并分享将如何引导未来的设计路线图。让我们一起将探索变为日常,将远方变为前方,共创未来,诚邀同路人~
Sora对视频重建的要求
在视频生成领域,视频重建的作用关键在于将丰富且复杂的视频信息有效压缩到较低维度的隐空间中。这一过程为视频生成提供了基础设施,使在隐空间中进行视频生成变得更为高效和可控,同时也简化了视频内容的编辑和操纵过程。操纵隐空间的变量就等于间接控制了视频输出的各个面向,这对时间和空间上的精准建模尤为重要。Sora进一步提高了视频生成的时长和一致性,这对重建的质量和效率提出了更高要求,包括但不限于:
● 统一表征问题:
○ 如何为图片和视频创建一个统一的Latent空间表示?
● 时间一致性:
○ 如何保证视频生成中的对象的时间一致性?
● 处理长时序列:
○ 对于需要产生具有较长时间维度的序列(如60秒的视频)的生成任务,如何设计模型?
● 离散与连续Latent空间的选择:
○ 虽然离散Latent空间可以方便地与自回归语言模型结构相整合,但连续Latent空间因能够减少信息损失,且更容易跟diffusion模型整合,所以具有更高的概率被选择。
● 可变分辨率视频的支持:
○ 模型必须能够处理不同分辨率和长宽比的视频。考虑Patchify操作,对VAE压缩后的Latent表示进行进一步压缩以创建Patch矩阵,可在这个环节处理可变分辨率支持。但VAE模型训练中是否需要考虑?
视频重建相关工作调研
从问题出发,我们调研了目前的视频重建相关的技术,并对部分论文的核心代码进行了解读。
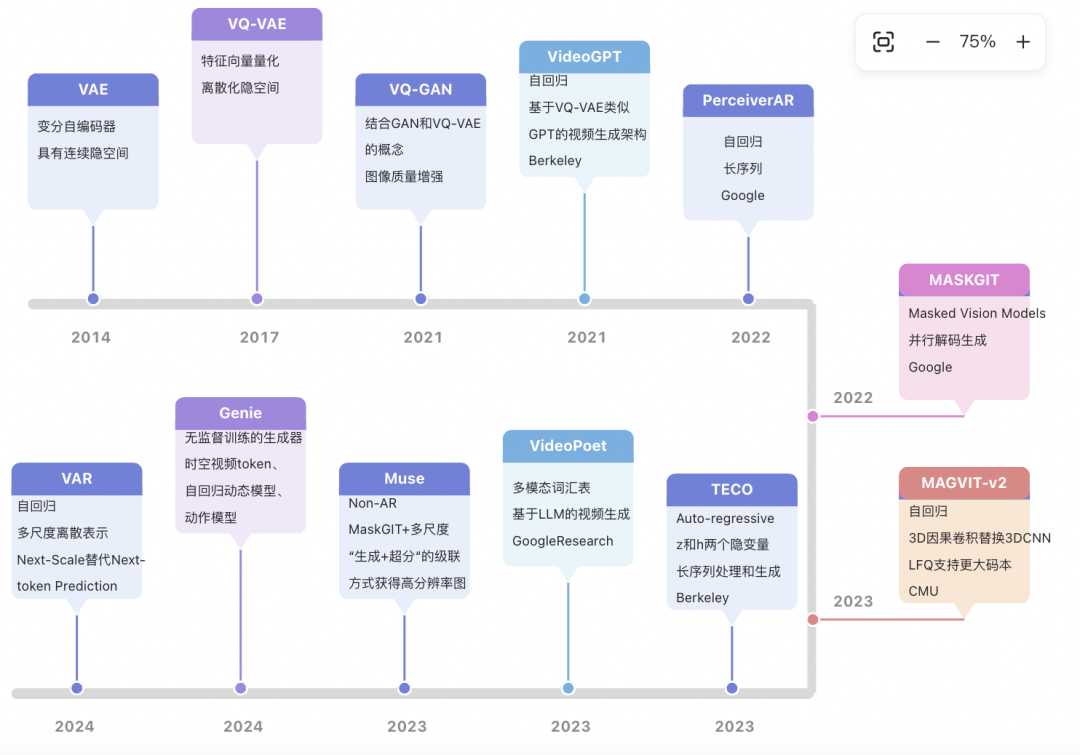
附调研详情链接 🔗 :https://www.yuque.com/antfe/featured/mg0k0k07d96stv7f?inner=iD4dJ
Video-GPT
VideoGPT是一种概念简单的架构,用于扩展基于似然的生成对自然视频进行建模。Video-GPT将通常用于图像生成的VQ-VAE和Transformer模型以最小的修改改编到视频生成领域。VideoGPT使用VQVAE,VQVAE通过采用3D卷积和轴向自注意力学习降采样的原始视频离散潜在表示。然后使用简单的类似GPT的架构进行自回归,使用时空建模离散潜在位置编码。VideoGPT结构如图7:
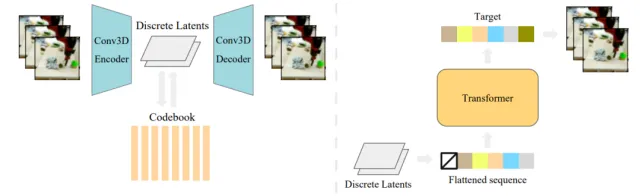
把训练管道分成两个连续的阶段:训练VQ-VAE(左)和训练潜在空间的自回归变换器(右)。第一阶段类似于原始的VQ-VAE训练程序。在第二阶段,VQ-VAE将视频数据编码为潜在序列作为先验模型的训练数据。对于推理阶段,首先从先验中抽取一个潜在序列,然后用VQ-VAE将潜在序列解码为视频样本
Learning Latent Codes
为了学习一组离散的潜在编码,首先在视频数据上训练一个VQ-VAE。编码器结构由一系列三维卷积组成,这些卷积在空间-时间上进行下采样,然后是注意力残差块。每个注意力残差块的设计如图8所示,使用LayerNorm和轴向注意力层。解码器的结构与编码器相反,注意力残差块之后是一系列的三维转置卷积,在空间-时间上进行上采样。位置编码是学习到的时空嵌入,在编码器和解码器的所有轴向注意力层之间共享。

VQVAE中注意力残差块的结构
Learning a Prior
第二阶段是对第一阶段的VQ-VAE潜在编码进行先验学习。遵循Image-GPT的先验网络结构,只是在前馈层和注意力块层之后增加了dropout层,用于正则化。尽管VQ-VAE是无条件训练的,但可以通过训练一个条件先验来生成条件样本。可以使用两种类型的条件。
交叉注意力(Cross Attention),对于video frame conditioning,首先将调整后的帧送入一个3D ResNet,然后在之前的网络训练中对ResNet的输出表示进行交叉注意力。
条件性范数(Conditional Norms),将transformer层归一化层中的增益和偏置参数化为条件向量的仿射函数。这种方法可以用于行动和类别调整模型。
Perceiver-ar:General-purpose, long-context autoregressive modeling with Perceiver AR https://github.com/google-research/perceiver-ar
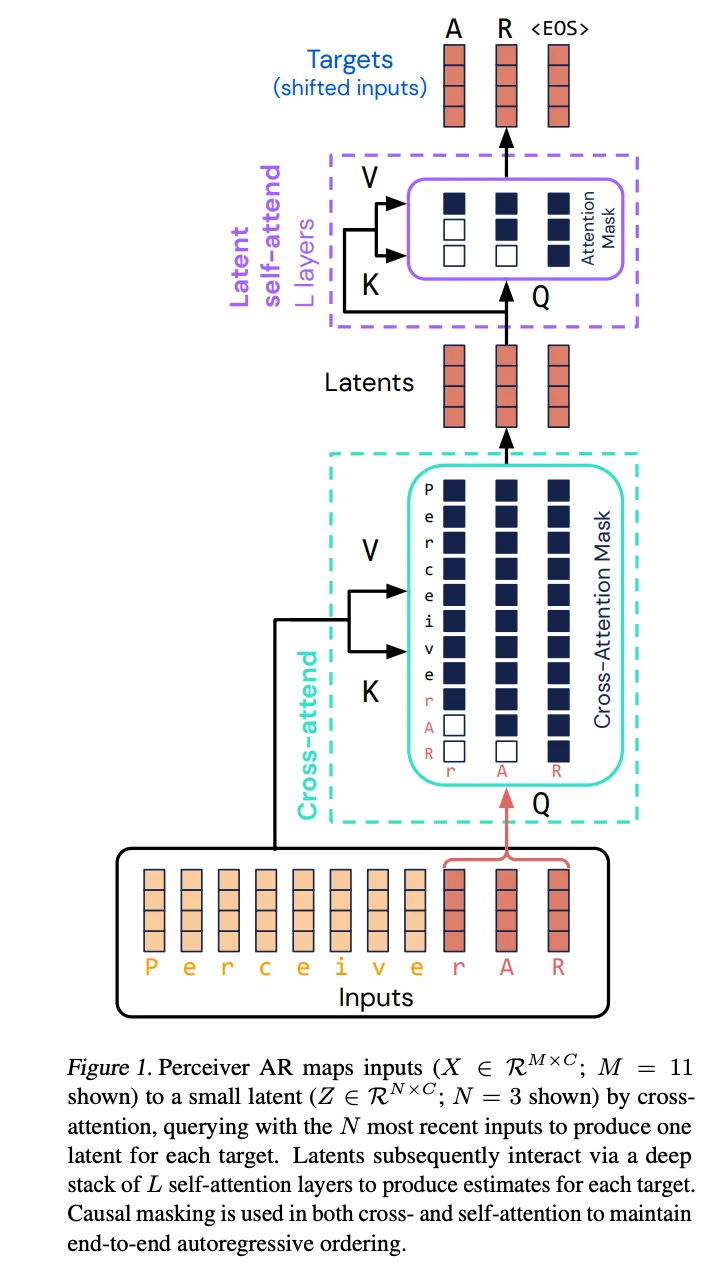
文章提出了一种名为Perceiver AR的模态无关的自回归生成架构,它通过交叉注意力机制将长范围的输入映射到一个较小的隐空间中,然后在随后的所有注意力操作中仅在生成的隐空间中进行处理。这种设计解耦了处理大型输入数组的计算需求与构建非常深的网络结构的需求,使得Perceiver AR可以处理大量的输入数据。然而,由于原始Perceiver模型的隐空间处理会关注所有输入数据而不考虑位置信息,因此它不能直接用于自回归生成——一个要求每个模型输出只依赖于序列中它之前的输入的任务。
Perceiver AR通过以下三种方式解决了这个问题,使其能够进行自回归生成:
- 引入隐空间处理顺序:Perceiver AR确保每个隐空间处理与单一输出元素对应,从而引入必要的顺序性。
- 使用因果掩码的交叉注意力:在交叉注意力机制中,Perceiver AR采用了因果掩码,确保每个隐变量处理仅与序列中排在其之前的输入元素有关。
- 隐空间堆栈中使用因果掩码自注意力:通过在隐空间堆栈中部署因果掩码自注意力,保证了自回归依赖结构可以从端到端被学习并保持。
由于这些改良,Perceiver AR的每个输出都依赖于之前所有的输入,因而对抓取长期依赖性大有裨益。文章展示了Perceiver AR在需要长期上下文的现实世界领域中的出色表现,这包括RGB级图像、标记化语言以及音频或符号音乐等任务,证明了它能够在知道真实结构的合成复制任务中完美识别长期上下文模式。
文章中着重指出了由于输入大小与计算需求解耦,模型在测试时可以改变隐空间(latent space)的大小以调整计算负载,这在训练时可以平衡模型容量与批量大小,而不影响测试时的性能。
文章的主要贡献如下:
● Perceiver AR架构的引入:一种高效、跨领域并能处理超过十万符号输入的自回归生成架构。
● 长上下文在自回归生成中的实用性验证:Perceiver AR在如ImageNet和Project Gutenberg的密度估计任务中取得了领先的成绩,以及在各种挑战性的生成任务中输出了高度一致且高保真度的样本。
● 输入大小与计算需求解耦:与当前流行的仅适用于解码器的Transformer和Transformer-XL架构相比,Perceiver AR提高了效率,并允许在测试时根据需要调整计算资源的使用。
总的来说,Perceiver AR为长序列自回归任务提供了一个高效和灵活的解决方案,其在处理长期上下文依赖性方面的能力使其成为自回归序列生成领域的一个方向。
1、Perceiver AR模型的几个核心组件:
位置编码(Position Encoding)
关键代码:
def generate_sinusoidal_features(size, max_len, min_scale, max_scale): """生成正弦位置编码""" @jax.vmap def make_positions_terminal_relative(pos_seq, input_seq): """将位置编码转换为相对当前位置的编码"""
位置编码是Perceiver模型的一个关键点,通过正弦位置编码和terminal-relative位置编码来捕捉序列的上下文信息。
- Attention模块
class SelfAttention(): """实现Self-Attention""" class CrossAttention(): """实现Cross-Attention"""
各种Attention模块是构建Transformer的基础,Perceiver使用Self-Attention和Cross-Attention来处理序列信息。
在Cross-Attention模块中,通过设置widening_factor参数来控制降维比例。widening_factor决定了Cross-Attention中Q,K,V的维度大小。例如:
self.cross_attn = CrossAttention( widening_factor=4, # 其他参数)
这里widening_factor=4,表示Cross-Attention的输入维度是输出维度的4倍。也就是说Cross-Attention实现了将输入降维到原来的1/4。
2、Perceiver AR model call的关键代码:
Masks:用于实现因果性的遮挡机制。make_block_causal_masks函数会根据inputs生成encoder mask和processor mask。
masks, latent_last_steps = make_block_causal_masks(
Position encodings:用于表示每个位置的信息。
○ absolute:位置编码直接融合在latent state中。
if self._position_encoding_type == 'absolute': # Position encodings not factored separately from the content/state. pass
rotary:使用旋转位置编码,latent_positions会索引出positions。
elif self._position_encoding_type == 'rotary': latent_positions = index_per_latent(positions, latent_last_steps)
Latents:用于表示每个位置的隐变量。initial_q_input表示初始的latent状态。
initial_q_input = self.z_linear(last_step_embeddings)
Cross-attention:用于实现长程依赖。initial_q_input作为query,经过自注意力层后和encoder输出进行交叉注意力。
initial_q_input = self.q_embed_z_linear(initial_q_input)
Causal autoregressive:只使用当前和历史latent状态进行预测,实现顺序生成。
masks, latent_last_steps = make_block_causal_masks()
多latent机制:每个位置可以对应多个latent,通过在axis=1上重复latent状态实现。
if self._num_latents_per_position > 1: # Replicate content encodings: initial_q_input = jnp.repeat( initial_q_input, self._num_latents_per_position, axis=1) # Build the latent index encodings. z_pos_enc = self.z_pos_enc(batch_size=batch_size) num_unique_positions = z_index_dim // self._num_latents_per_position z_pos_enc = jnp.tile(z_pos_enc, [1, num_unique_positions, 1]) initial_q_input += z_pos_enc
内存机制:通过memory和memory_type参数实现,用于重用过去的计算。
def __call__(self, ..., memory_type='none', memory=None, ...)
总体来说,Perceiver AR通过position encodings、latents、masks和cross-attention的组合,实现了一个通用的长程依赖和顺序生成的框架。
Magvit2
提出3D因果卷积同时支持图像和视频的token化,提出LFQ支持更大的码本
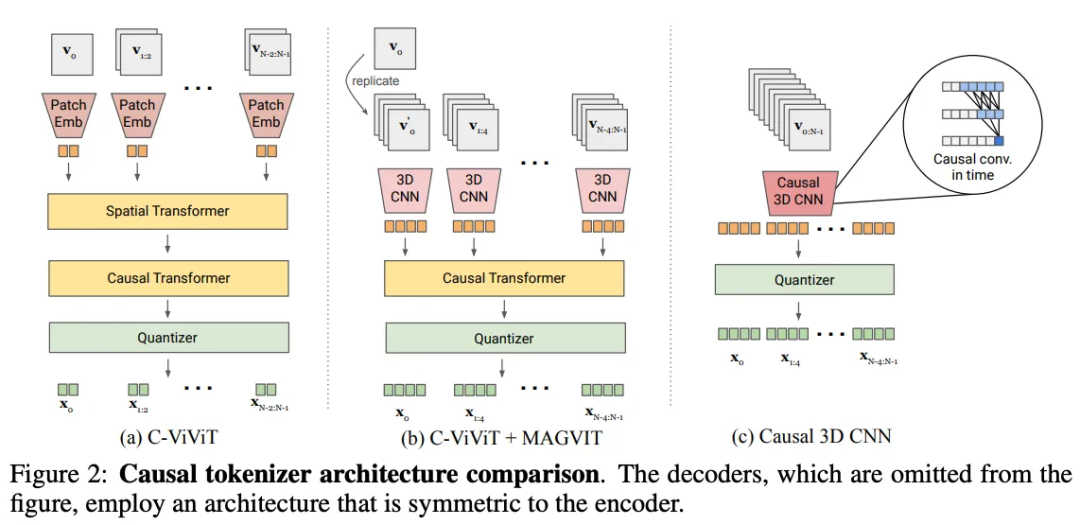
联合图像和视频 tokenizer
● 视觉 tokenizer 的一个理想特性是能够使用共享的码书对图像和视频进行 token 化。然而,利用 3D CNN 的 MAGVIT tokenizer 在 token 图像方面面临挑战,这是由于时间感受野的存在。
● 我们使用时间上因果的 3D 卷积(causalcnn)替换常规 3D CNN。具体而言,对于内核大小 kt,kh,kw 的常规 3D 卷积层,时间填充方案包括在输入帧之前填充 ⌊(kt−1)/2⌋ 帧,在输入帧之后填充 ⌊kt/2⌋ 帧。相反,因果 3D 卷积层在输入之前填充 kt−1 帧,之后不填充,因此每个帧的输出只取决于先前的帧。因此,第一帧始终独立于其他帧,允许模型对单个图像进行标记化。
● 通过padding方式实现时间轴上的因果卷积
LFQ
● 训练更大的码书的一个简单技巧是在增加词汇表大小时减少编码嵌入维度。基于以上观察,直接将 VQVAE 的 codebook embedding 维度降低为 0:原始 codebook 改为一个整数集,因为省去了之前的查表过程所以起名为 LFQ。LFQ 可以训练更大的 codebook 从而对后续生成更有利
● 本文引入了一种 LFQ 直接的变体,它假设码本维度独立和 latent 变量为二进制。具体而言,LFQ 的潜在空间被分解为单维变量的笛卡尔积
videopoet
VideoPoet 值得关注的一个原因在于,和绝大多数视频领域模型不同,VideoPoet 并没有走 diffusion 的路线,而是沿着 transformer 架构开发,将多个视频生成功能集成到单个 LLM 中,它的推出以及它所呈现出的效果,是 transformer 在视频生成任务上拥有极大潜力的有力证明。
多模态词汇表
该论文提出了一种多模态词汇表(multimodal vocabulary),用于表示视频和音频的离散标记。这个词汇表包含了大量的标记,可以涵盖各种不同的视觉和音频特征。
然后,该论文使用了一个预训练的大型语言模型,该模型是在这个多模态词汇表上进行训练的。这个语言模型可以生成与输入的文本或图像对应的标记序列,从而生成视频或音频。
此外,该论文还提出了一种控制生成任务的方法。通过在训练过程中构造不同的输入标记到输出标记的模式,可以控制模型生成的视频或音频的类型和质量。
创新点:
- 使用MAGVIT-v2 tokenizer进行视频编码:该论文采用了MAGVIT-v2 tokenizer,这种tokenizer能够独立地对视频的第一帧进行编码,而不需要考虑后续帧。这一创新点使得研究人员可以编码一张没有任何填充的图像作为视频的第一帧。
- 预测后续帧的剩余tokens:论文中,模型能够预测后续帧的剩余tokens,从而生成视频。这一创新点展示了模型能够产生在时间上连贯的物体生成,为动态、有意义的运动提供了可能。
- 预测未来帧:尽管模型只能查看视频的短期时间上下文(如第一帧或视频的第一秒),但该模型仍然能够预测未来的帧。这一创新点展示了模型在处理视频序列时的强大能力。
- 负责任的人工智能和公平性分析:该论文还对模型生成的输出进行了负责任的人工智能和公平性分析。研究人员评估了模型生成的输出是否公平,例如在年龄、性别和肤色等受保护属性上。
- 灵活的prompt模板:研究人员使用了灵活的prompt模板来生成视频。通过改变prompt模板中的“adverb”,可以显著改变输出的分布。这一创新点展示了模型在生成不同分布的视频输出上的灵活性。

MaskGit:Masked Generative Image Transformer

- Tokenization:自然语言都是离散值,而图像是连续值,想像NLP一样处理必须先离散化,iGPT里直接把图像变成一个个马赛克色块,ViT则是切成多块后分别进行线性映射,还有的方法专门学了一个自编码器,用encoder把图像映射成token,再用decoder还原
- Autoregressive Prediction:用单向Transformer一个个token地预测,最终生成图像
虽然这类方法的生成结果还可以,但是从直觉上却不那么顺溜。仔细想人是怎么画画的,大多数人肯定是先画个草稿,然后再逐步细化、填色,由整体到局部,而不是从上到下从左到右一个个像素去填充。
MaskGIT的核心思想,就是参考人的作画逻辑,先生成一部分token,再逐渐去完善。
在每个迭代中,模型同时并行地预测所有token,但只保留最自信的token。剩余的token被mask掉,并将在下一个迭代中重新预测。屏蔽比例逐步减少,直到通过几次迭代细化生成所有token。MaskGIT的解码速度比自回归解码快一个数量级,因为它只需要8个步骤(而不是256个步骤)生成一张图像,并且每个步骤内的预测可以并行化.
Maskgit的主要优化
GumbelVQ
GumbelVQ 和传统的 Vector Quantizer (VQ) 在向量量化的过程中存在显著差异,尤其是在量化机制、训练目标和量化一致性三个方面。
量化机制的差异:
● GumbelVQ 采用的是 Gumbel-Softmax 方法,它通过添加 Gumbel 噪声和取 Softmax 实现软量化,产生一个连续的概率编码。
● VQ 采用的是硬量化机制,直接从 codebook 中选取最近的编码,产生离散的 one-hot 编码。
训练目标的差异:
● GumbelVQ 优化的是重构损失(即输入与量化后重构出的输出之间的差异),没有额外的损失项。
● VQ 同时优化重构损失和承诺损失,承诺损失确保编码表的更新能尽可能接近数据的实际分布。
量化一致性的差异:
● GumbelVQ 在训练和推理时采用相同的量化策略,没有区别。
● VQ 在训练时使用 soft assignment,在推理时需要取 argmax 得到离散编码。
代码示例:
量化方式:
# Gumbel-Softmax 软量化noise = jax.random.gumbel(key, shape)logits = jnp.log(softmax(-distances + noise))quantized = jnp.matmul(logits, codebook) # VQ 硬量化encoding_indices = jnp.argmin(distances, axis=1)encodings = jax.nn.one_hot(encoding_indices, num_embeddings)quantized = jnp.matmul(encodings, codebook)
训练目标:
# Gumbel-Softmax 重构损失loss = jnp.mean((x - quantized)**2) # VQ 重构损失与承诺损失commit_loss = jnp.mean((quantized - x)**2)embed_loss = jnp.mean((quantized.stop_gradient() - x)**2)loss = commit_loss + embed_loss
推理策略:
# Gumbel-Softmax 训练和推理保持一致# (使用相同的 logits 和 quantized 计算) # VQ 推理时的量化_, encoding_indices = jnp.argmin(jnp.linalg.norm(x[:, None] - codebook, axis=-1), axis=-1)encodings = jax.nn.one_hot(encoding_indices, num_embeddings)
在实践中,GumbelVQ 的软量化方法提供了平滑的量化和更简单的训练流程,因为它消除了训练和推理之间的差异,并允许模型进行端到端的优化。而传统的 VQ 方法在特定的情况下可能更有效,比如当资源有限或者明确需要硬量化结果时。选择哪一种方法取决于具体任务的要求和可用资源。
mask_transformer
Mask并行解码是一种处理带遮挡图像输入的有效方法,它模拟了人类进行绘画时的过程——首先确定整体轮廓,然后逐步填充细节。以下是如何通过这种机制实现并行解码以及效率提升的总结:
- 全链路中的Mask处理:
- 生成Mask标记:对输入序列随机应用Mask,模拟数据缺失的场景,为学习过程带来挑战。
- 利用Mask的Embedding:将Masked位置的Token替换为专用的Mask Token,然后将其传送进Embedding层。
- 自注意力中的Mask应用:在Transformer内部,使用Mask标记来控制注意力权重,从而在计算时排除Masked Token的干扰。
- 预测Masked Token:仅针对被Mask的Token计算损失,从而关注模型在预测缺失数据上的表现。
- 并行解码能力:
- 支持并行计算:Transformer允许整个序列同时进入模型,不需要逐个Token处理,自注意力机制自然地支持并行操作。
- 聚焦Masked区域:通过计算损失时只关注Masked Token,可以在一次计算中更新多个Token的预测,而非逐个更新。
- 效率提升的背后原理:
- 节省计算资源:由于不需要逐步产生预测,推理速度得以显著提升。
- 避免重复计算:在推理过程中避免了对非Mask位置的冗余计算,专注于补全缺失的信息。
- 模拟人类绘画过程的能力:
- 确定大致轮廓:类似于初步勾画草图,模型学会先捕获整体结构和重要特征。
- 逐步填充细节:在后续步骤中细化预测,类似于在素描中增加细节和深度。
以下是对应的核心代码示例,展示了如何实现Mask并行解码:
# 1. 生成Mask标记masked_indices = np.random.choice(seq_len, mask_ratio * seq_len)mask = np.ones(seq_len)mask[masked_indices] = 0 # 2. 生成Mask Embeddingmasked_input_ids = input_ids.copy()masked_input_ids[masked_indices] = mask_token_idmask_emb = embedding_layer(masked_input_ids) # 3. 自注意力中使用Maskattn_weights = attn_weights.masked_fill(mask == 0, -1e9)attn_output = softmax(attn_weights) @ v # 4. 预测Masked Tokenmlm_logits = MlmLayer(transformer_output, embedding_matrix)mlm_loss = cross_entropy(mlm_logits, input_ids, masked_indices)
Mask并行解码结合了Transformer强大的表示能力和处理遮挡数据的灵活性,在实际任务中,如Masked Language Modeling、图像生成等场景下表现出优越的性能。通过内部并行处理和对Mask区域专注的特点,实现了快速、高效且具有一定模拟人类行为特性的深度学习模型。
Muse: Text-To-Image Generation via Masked Generative Transformers
https://github.com/lucidrains/muse-maskgit-pytorch/
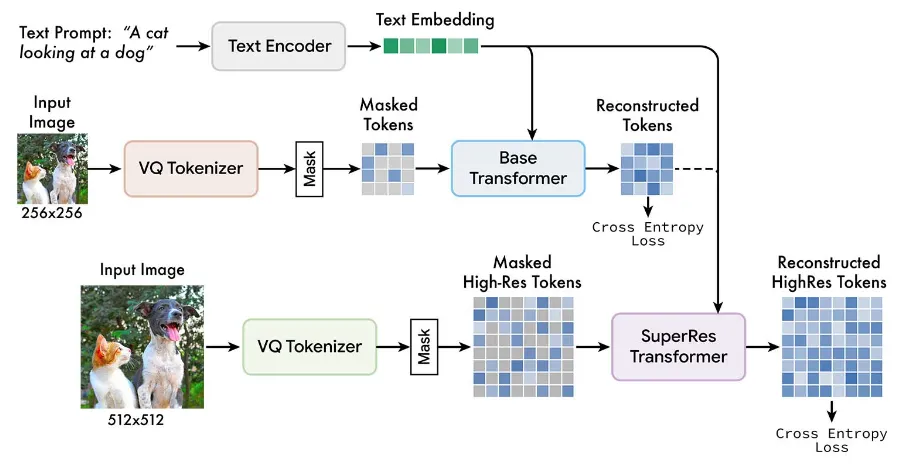
上图展示了Muse的整体框架。与DALL·E 2和IMAGEN等Text2Image大模型类似,Muse采用”生成+超分“的级联方式获得高分辨率图。具体地,Muse基于预训练语言大模型T5-XXL提取的text embedding, 先生成一个低分辨率的图,然后用一个超分模型扩大生成图像的分辨率并修饰局部细节。
我们把负责生成低分辨率图的网络叫做Base Transformer,Base Transformer通过训练实现:输入被Mask掉的image tokens(mask的比率可以是从0到1),基于text embedding预测被mask掉的token。在inference的时候,Base Transformer使用MaskGIT中的并行加速方法,仅需24次迭代就可以生成 16×16 个image tokens。
我们把负责做超分的网络叫做SuperRes Transformer,SuperRes Transformer通过训练实现:输入被Mask掉的image tokens(mask的比率可以是从0到1),基于text embedding和生成阶段的结果预测被mask掉的token。在inference的时候,SuperRes Transformer也使用MaskGIT中的并行加速方法,仅需8次迭代就可以生成 64×64 个image tokens。
TECO:Temporally Consistent Transformers for Video Generation https://github.com/wilson1yan/teco
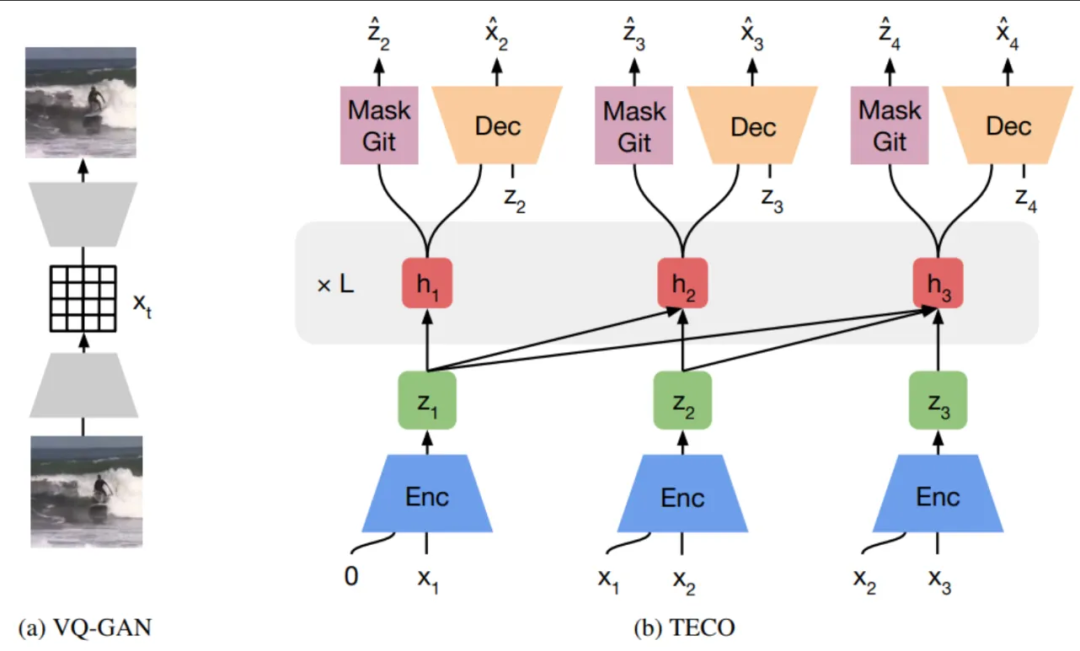
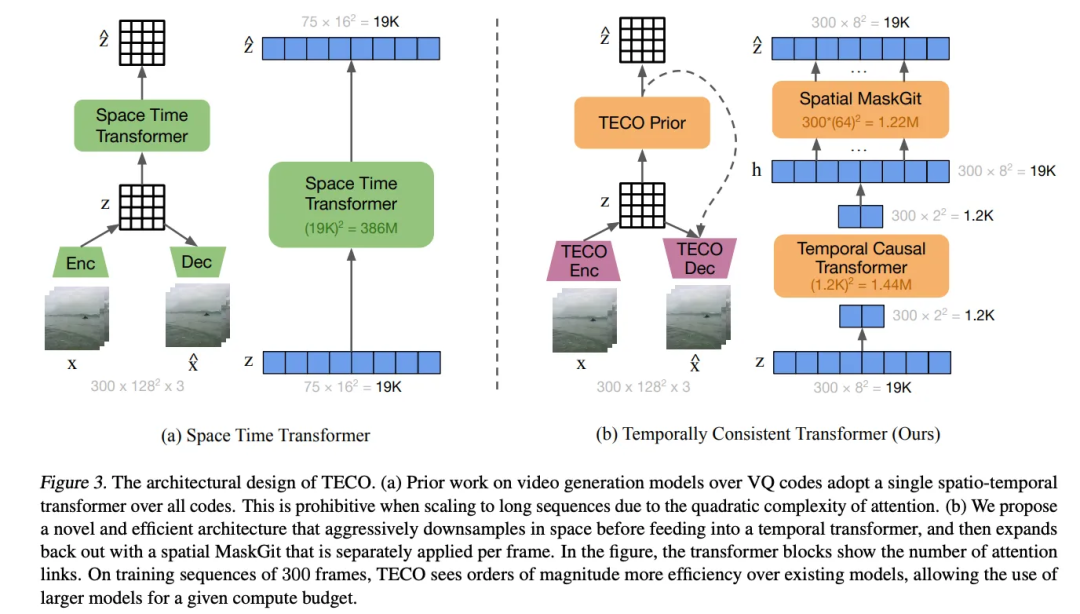
Encoder
TECO代码中的具体实现,对编码流程再进行详细解释:
- 查询码本embeddings
embeddings = self.vq_fns['lookup'](encodings)
直接调用了VQ-VAE的lookup方法,将输入的编码indices转换为embeddings。
- 添加sos token
sos = jnp.tile(self.sos_post[None, None], (embeddings.shape[0], 1, 1, 1, 1))sos = jnp.asarray(sos, self.dtype)
构建一个全0的sos embedding,并tile到batch维度上,加入到序列最前面。
- t和t+1帧concat
embeddings = jnp.concatenate([sos, embeddings], axis=1) inp = jnp.concatenate([embeddings[:, :-1], embeddings[:, 1:]], axis=-1)
在时间轴上,将t和t+1的embedding concat到特征维度上。
- 传入ResnetEncoder编码器
out = jax.vmap(self.encoder, 1, 1)(inp)
输入concat后的序列到ResNetEncoder中。
- 量化主体部分,得到量化embedding,量化索引等
vq_output = self.codebook(out)
encode函数是对输入的编码进行处理,输出条件部分和编码部分。
- 返回: 如果self.config.n_cond=4
- 条件部分编码:out[:, :4],即前4帧编码
- 量化结果:包含29帧量化embedding,量化索引等
这个函数将输入的编码分为条件部分和主体部分,条件部分直接返回,主体部分进行量化等处理
vq_output = { 'embeddings': vq_embeddings[:, self.config.n_cond:], 'encodings': vq_encodings[:, self.config.n_cond:], 'commitment_loss': vq_output['commitment_loss'], 'codebook_loss': vq_output['codebook_loss'], 'perplexity': vq_output['perplexity'], } return out[:, :self.config.n_cond], vq_output
vq_embeddings和vq_encodings表示向量量化(Vector Quantization)的结果,两者有以下区别:
- vq_embeddings: 这是量化后的embedding向量,表示输入被量化到离它最近的embedding向量。
- vq_encodings: 这是量化的索引,表示输入被量化到代码簿(codebook)中的哪个索引位置。
向量量化过程包括:
- 输入通过编码器输出特征表示
- 特征表示被量化到离它最近的代码簿向量(vq_embeddings)
- 记录量化后的索引(vq_encodings)
所以vq_embeddings是量化后的向量表示,vq_encodings是对应的索引。两者共同表示了向量量化的结果。
量化后的向量表示vq_embeddings保留了更多信息,可以用于后续生成。而索引vq_encodings是离散的,可以用于计算量化损失,指导量化表示学习更好的连续表示。
cond, vq_output = self.encode(encodings) z_embeddings, z_codes = vq_output['embeddings'], vq_output['encodings'] deter = self.temporal_transformer( z_embeddings, actions, cond, deterministic=deterministic )
Temporal Transformer
实现了对输入z_embeddings的下采样,多头自注意力,以及上采样的过程

将条件编码cond和主体编码z_embeddings在时间轴上拼接,将action重复拼接到每个时间步的通道维度上,将上一时间步的编码和action拼接作为自注意力的输入(t-1的z embedding和当前t的action拼接)
通过z_proj进行下采样,减少时间分辨率
传入自注意力模块z_tfm,进行自注意力计算
通过z_unproj上采样,恢复原始时间分辨率
输出deter,
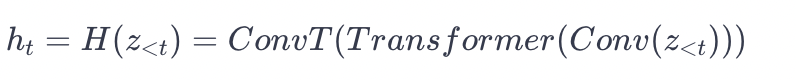
def temporal_transformer(self, z_embeddings, actions, cond, deterministic=False): #将条件编码cond和主体编码z_embeddings在时间轴上拼接 #将action重复拼接到每个时间步的通道维度上 #将上一时间步的编码和action拼接作为自注意力的输入 inp = jnp.concatenate([cond, z_embeddings], axis=1) actions = jnp.tile(actions[:, :, None, None], (1, 1, *inp.shape[2:4], 1)) inp = jnp.concatenate([inp[:, :-1], actions[:, 1:]], axis=-1) #通过z_proj进行下采样,减少时间分辨率 inp = jax.vmap(self.z_proj, 1, 1)(inp) #加入起始符sos #传入自注意力模块z_tfm,进行自注意力计算 #去掉起始符sos,取后面的时间步 sos = jnp.tile(self.sos[None, None], (z_embeddings.shape[0], 1, 1, 1, 1)) sos = jnp.asarray(sos, self.dtype) inp = jnp.concatenate([sos, inp], axis=1) deter = self.z_tfm(inp, mask=self._init_mask(), deterministic=deterministic) deter = deter[:, self.config.n_cond:] #通过z_unproj上采样,恢复原始时间分辨率 deter = jax.vmap(self.z_unproj, 1, 1)(deter) return deter
之所以要进行下采样再上采样,是为了通过自注意力模块建模更长时间范围内的依赖关系,同时又不会导致计算量成倍增加。
下采样可以大大减少需要建模的时间步数,降低计算量。而上采样再恢复原始分辨率,从而保证输出与输入时间步数一致。
所以这种下采样-自注意力-上采样的结构既考虑了计算效率,也保证了建模长时间依赖的能力。
Genie: Generative Interactive Environments
Genie的生成式交互环境,它是首个从未标记的互联网视频中以无监督方式训练出来的环境。该模型可以根据提示生成无数种可通过文本、合成图像、照片甚至草图来描述的动作可控的虚拟世界。拥有110亿参数的Genie可以被看作是一个基础世界模型。它由一个时空视频标记器、一个自回归动态模型和一个非常简单且可扩展的潜在动作模型组成。尽管在没有任何地面真实动作标签或其他在领域模型文献中常见的特定领域要求的情况下进行训练,Genie仍然能够使用户能够以逐帧的方式在其生成的环境中进行操作。此外,所学习的潜在动作空间还促进了训练代理模仿从未见过的视频中的行为,为未来训练通用代理开辟了道路。

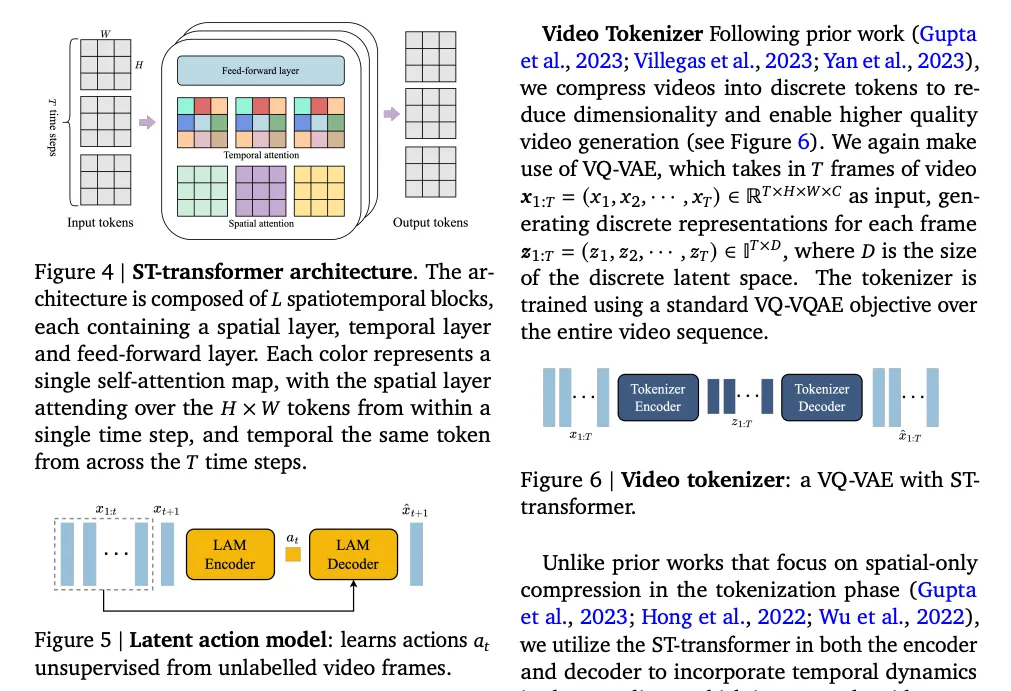
VAR :Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
这篇文章介绍了一种全新的生成模型框架——视觉自回归建模(Visual Autoregressive, VAR)。VAR提出了对图像自回归学习方式的重定义,将传统的逐像素或逐标记(token)的预测过渡到从低分辨率到高分辨率的多尺度预测过程。这种方法与经典的自回归模型相比,更符合人类的视觉感知习惯,即先识别大致轮廓,再注重细节部分。
VAR框架的关键思路源自人类创建或感知图像的层次化方式。研究者们受到多尺度设计的启发,创新性地提出了图像自回归学习的“下一尺度预测”范式。具体来说,VAR首先将图像编码成多个不同分辨率(尺度)的标记图,然后从最低分辨率的标记图开始其自回归过程,逐步预测出更高分辨率的标记图,其中每一步的预测都基于之前所有尺度的标记图。
在技术实现上,VAR直接采用了类似于GPT-2的变压器(Transformer)架构进行视觉自回归学习。这一设计使得VAR可以充分利用Transformer模型的长距离依赖能力和有效的序列建模能力。
文章中提出的VAR在ImageNet 256x256这一主要基准测试中表现出色。它在自回归模型领域中达到了新的里程碑,超越了扩散变压器模型(Diffusion Transformer, DiT)。更具体地说,VAR在弗雷歇特席普森距离(FID)和改进得分(IS)的指标上均取得了显著提升,并且在推理速度上比先进模型快约20倍。
作者进一步强调,VAR在随着模型规模增大时,表现出与大型语言模型(Large Language Models, LLMs)相似的清晰幂律规模法则。这一点表明VAR的性能提升与模型规模之间存在稳定的线性关系,为模型的可扩展性和未来的进一步发展提供了强有力的证据。
在下游任务中,VAR也表现出了零样本泛化的能力,能够无需特定训练即在诸如图像修复、图像生成和编辑等任务上取得良好表现。这证明了VAR不仅在一般的图像生成过程中有效,也能广泛应用于其他相关领域。
文章的这些贡献表明,VAR作为一种新颖的自回归视觉生成框架,可能会对未来的视觉生成任务和统一的模型学习框架产生重要影响。为了推动该领域的研究,作者已经公开了所有模型和代码,这无疑将促进社区对自回归和视觉自回归模型在视觉生成方面的进一步探索和应用,主要创新点和启发如下:
- 层次化图像感知的模拟:人类对图像的感知和创作往往是层次化的,先把握整体结构,然后关注细节。基于这种自然的多尺度、从粗到细的视觉处理方式,VAR方法在图像建模中引入了新的“排序”概念。这种排序方式模仿了人类视觉系统的处理流程,不再是按照固定次序逐像素预测,而是根据视觉信息的重要性和逻辑顺序进行。
- "下一个尺度预测"范式:受到多尺度理论的启发,VAR框架定义了一种新的图像自回归学习方式,即“下一个尺度预测”,与传统的逐个标记或像素预测明显不同。这种策略允许模型首先在较低分辨率上把握图像的粗略内容,然后逐步预测出更加细节化的信息,从而逐步提升图像的清晰度。
- 多尺度编码与逐步精细化:VAR开始于将原始图像编码为一系列不同分辨率的标记图,这构成了自回归模型的输入序列。从最低分辨率的1×1起始,模型逐步自回归地提高分辨率,每一步都是基于前一步的所有标记图进行预测,使模型不仅仅记忆先前的内容但也在每一步进一步增加细节。
- 采用变换器架构进行模型学习:VAR模型利用与GPT-2相似的变换器(Transformer)架构,充分利用了变换器在处理序列数据、建模长期依赖关系方面的优势。这种架构使VAR能够有效地实现多尺度视觉自回归学习,并且有望在图像生成领域取得突破性的进展。

视频重建相关的工作总结
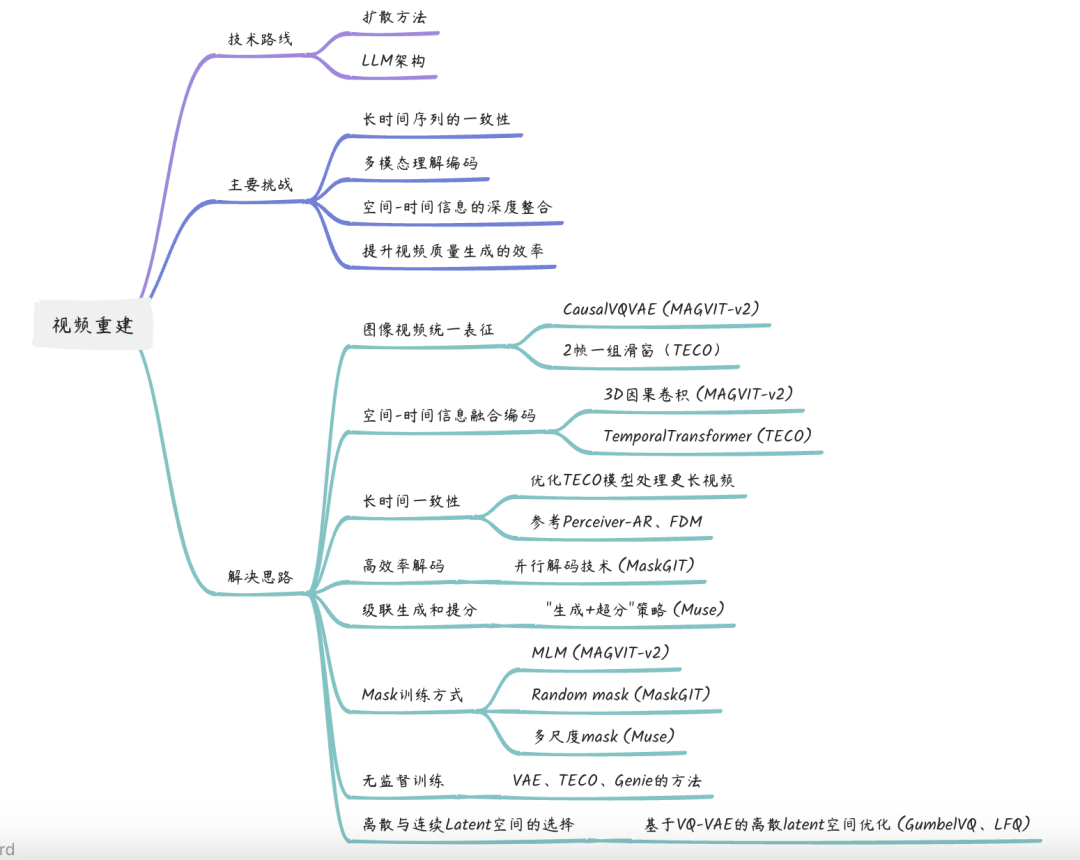
总结上面的工作,目前视频生成领域有两个主流的技术路线,一个是走diffusion 的路线,二个是沿着 transformer 架构开发,将多个模态包括视频生成功能集成到单个 LLM 中。上面工作体现的视频生成中的主要关键挑战,包括长时间序列的一致性、多模态理解编码、空间-时间信息的深度整合,以及提升视频质量生成的效率。
问题的解决思路:
- 图像视频统一表征:如MAGVIT-v2所提出的CausalVQVAE,采用3D因果卷积,利用padding技术实现因果;如TECO使用的TemporalTransformer,利用CausalMask实现attention的因果;采用因果的好处是,第t帧依赖0~t-1帧,所以第0帧依赖的只有自己,图像就可以认为是第0帧,从而统一表达了图像和视频的表达。一些其他实现上的差异有,MAGVIG-v2因为会把4帧最后压缩成一帧的Latent表示,所以它不仅在空间维度,同时也在时间维度上对输入进行了压缩,而这可能在输入层面带来进一步的信息损失,另外latent编码从4帧压缩成1帧的latent表示,对于短时一致性有帮助,但是靠CNN很难融入太长历史信息。Teco则是两帧一组,比如对于第t帧,则把前一帧第 (t-1) 帧也和第t帧放在一组。这里要注意,尽管也是2帧一组,但是这和MAGVIT 思路是不一样的,TECO这个2帧一组类似一个滑动窗口,窗口间是有重叠的,所以不存在多帧压缩成一帧带来的信息损失问题,相反增加了信息。
- 空间-时间信息融合编码:结合MAGVIT-v2提出的3D因果卷积和TECO的长序列处理方法,实现对视频在空间和时间上更精细的编码。Gene提出的时空编码、TECO的多级latent编码等。
- 长时间一致性:优化TECO模型的长序列处理机制,使其能够处理更长的视频内容,并确保生成视频在时间轴上的一致性与连贯性。类似Perceiver-AR、Flexible Diffusion Modeling of Long Videos-FDM(同时参考最近生成视频帧,以及更长时间之前固定的若干帧,增加参考视频的时间跨度)
- 高效率解码:借鉴MaskGIT的并行解码技术,提高视频内容生成的速度,同时保持高质量的视频输出。
- 级联生成和提分:仿效Muse中的"生成+超分"策略,可能将为实现更高解析度的视频输出提供一种策略,即先生成较低解析度的视频然后逐步提升分辨率。
- Mask训练方式:masked language model (MLM) for Magvit2、random mask for Maskgit、多尺度mask for Muse,多级多轮多尺度掩码恢复生成的训练方式基本在多篇论文验证可行。
- 无监督训练:追随类似于VAE、TECO、Genie中所采用的技术,探索无监督学习方法,从单个隐空间编码到时间、空间两个维度的隐空间,到时间、空间、运动的多级隐空间编码,以减少对有标签数据的依赖,从大量未标记的视频中学习生成模型。
- 离散与连续Latent空间的选择:大部分都是基于VQ-VAE的离散latent空间的优化,比如GumbelVQ、LFQ相关技术
视频重建技术发展创新路线图
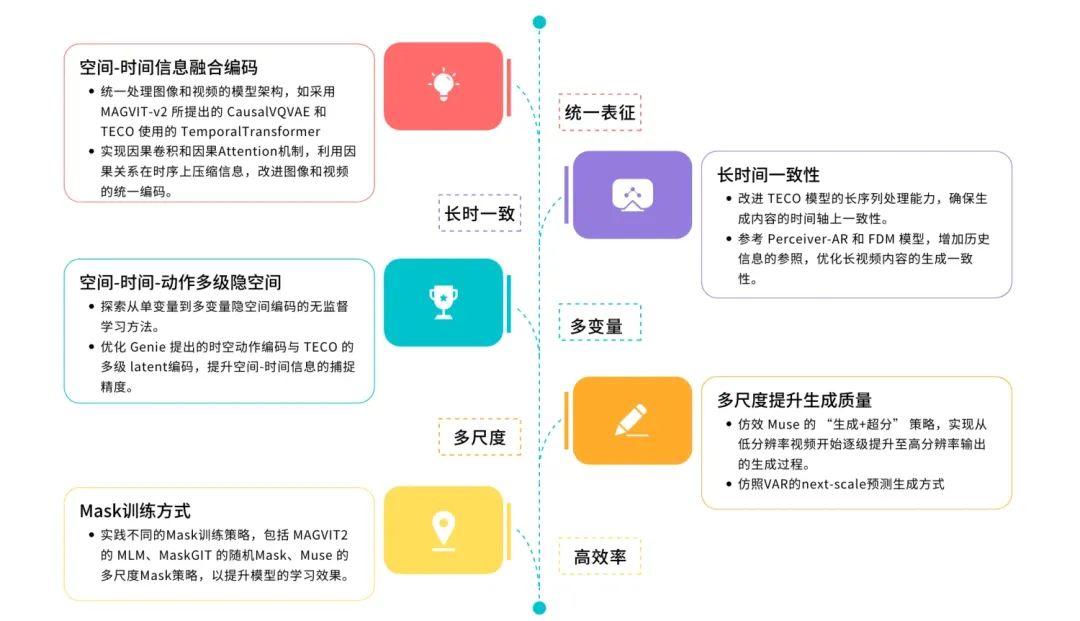
统一表征:空间-时间信息融合编码
- 统一处理图像和视频的模型架构,如采用 MAGVIT-v2 所提出的 CausalVQVAE 和 TECO 使用的 TemporalTransformer
- 实现因果卷积和因果Attention机制,利用因果关系在时序上压缩信息,改进图像和视频的统一编码。
长时一致:长序列处理能力
- 改进 TECO 模型的长序列处理能力,确保生成内容的时间轴上一致性。
- 参考 Perceiver-AR 和 FDM 模型,增加历史信息的参照,优化长视频内容的生成一致性。
多变量:空间-时间-动作多级隐空间
- 探索从单变量到多变量隐空间编码的无监督学习方法。
- 优化Genie 提出的时空动作编码与 TECO 的多级 latent编码,提升空间-时间信息的捕捉精度。
多尺度:多尺度提升生成质量
- 仿效 Muse 的 “生成+超分” 策略,实现从低分辨率视频开始逐级提升至高分辨率输出的生成过程。
- 仿照VAR的next-scale预测生成方式
高效率:Mask训练方式
- 实践不同的Mask训练策略,包括 MAGVIT2 的 MLM、MaskGIT 的随机Mask、Muse 的多尺度Mask策略,以提升模型的学习效果。
- 借鉴 MaskGIT 的并行解码技术,加快视频内容的生成速度,同时确保输出质量。
- 探索用于视频生成任务的并行和分布式编解码策略,以提高效率。
通过上述路线图,可以看出未来视频重建方向可能会集中在提高时空信息编码的精度、维持长时间内容一致性、提升解码效率与生成质量,以及强化无监督学习策略等方面。此外,新的模型架构和训练方法也将持续探索和优化,以便更好地处理和生成高质量视频内容。
我们的工作目标
- 短期目标:服务Sora和原生多模态相关工作,提升模型的整体性能,空间上压缩16-64倍,时序上压缩4-8倍
- 长期目标:保证质量不降的情况下,提升视频编码的压缩比,进一步提升视频理解和生成的模型推理效率
引用
- https://github.com/google-research/perceiver-ar
- https://github.com/lucidrains/muse-maskgit-pytorch
- https://arxiv.org/pdf/2202.04200.pdf
- https://github.com/lucidrains/muse-maskgit-pytorch
- https://magvit.cs.cmu.edu/v2/
- https://wilson1yan.github.io/teco/
- https://github.com/wilson1yan/teco
- https://github.com/FoundationVision/VAR
- https://var.vision/demo
- https://arxiv.org/abs/2404.02905
- https://sites.google.com/view/genie-2024/home
- https://sites.research.google/videopoet/
- https://muse-model.github.io/