本文来源:支付宝体验科技公众号、
编者按:本文作者是支付宝算法工程师杰凡,介绍了视频生成主要玩家的对比,以及 Sora 视频生成原理和能力。欢迎查阅~
1. Sora 是什么
2. 视频生成主要玩家对比
3. Sora 视频生成原理简述
4. Sora 的能力
5. Sora 总结
6. 参考
1. Sora 是什么
Sora 是由 OpenAI 提出的视频生成模型,可以根据文本提示词,生成长达一分钟且质量极高的视频。OpenAI 提供了一份技术报告,展示了 Sora 的各项能力,但是对于技术细节透露较少。
2. 视频生成主要玩家对比
在 Sora 发布前,视频生成主要玩家包括 Runway、Pika、Stability AI,他们都有产品级视频生成应用公布。Sora 暂未完全开放使用,需要申请“红队测试”使用(这是一种通过模拟攻击者角色来发现潜在安全漏洞的方法,旨在评估并提升 OpenAI 的 AI 模型的安全性和可靠性)。另外,Google、Meta、字节等公司也积极研发视频生成相关技术,发布的论文都有不错的影响力,相应的技术应该是应用到了公司核心业务中。
| 公司 | Runway | Pika | Stability AI | OpenAI |
| 视频生成模型 | Gen2 | Pika 1.0 | SVD(Stable Video Diffusion) | Sora |
| 发布时间 | 2023.3 | 2023.11 | 2023.11 | 2024.2 |
| 是否开源 | 非开源(Gen1已发布论文) | 非开源 | 开源 | 非开源 |
| 视频时长 | 4s(后来提升至18s) | 3s | 4s | 60s |
2.1 Gen2 效果展示
输入图片和提示词进行视频生成:



运动笔刷功能:

2.2 Pika 效果展示
输入图片和提示词生成视频:

视频编辑:

宫崎骏电影生成,还是非常有感觉的:(不过可以看到,这不是直接生成长视频,而是由几个视频镜头拼接而成)

2.3 SVD 效果展示


2.4 效果对比
给 Sora、Pika、Runway、Stable Video 四个模型输入了相同的提示词。可以看到,四个模型都能很好的理解语义,而 Sora 在生成视频长度上基本是降维打击,且视频非常连贯。其他的几个技术基本都是 4s 左右的视频,非常的短。在实践中,很多人使用最后一帧的图片作为输入再次生成 4s 的视频,以此来生成多个 4s 的视频并进行拼接,最终产出长视频,但这种方式由于不在一次模型生成中,上下文的关联无法保证,得到的效果不连贯。

提示词:一窝金毛幼犬在雪地里玩耍,它们的头从雪中探出来,被雪覆盖。

可以看到,Sora 生成的视频动效非常明显。
提示词:几只巨大的毛茸茸的猛犸象踏着白雪皑皑的草地走来,长长的毛毛在风中轻轻飘动,远处覆盖着积雪的树木和雄伟的雪山,午后的阳光、缕缕云彩和远处高高的太阳营造出温暖的光芒,低相机视野令人惊叹地捕捉到了大型毛茸茸的哺乳动物与美丽的摄影,景深。

3. Sora 视频生成原理简述
这章节不会深入到太公式性的内容,希望通过容易理解的图文,把 Sora 能够生成高质量视频的原因表达出来。
3.1 整体结构
下图是 Sora 的整体框架,可拆成两个大块来看:
- 视觉编码器/解码器:编码器将原始视频映射到 patches,解码器把 patches 还原回视频
- 扩散模型(文本提示词为条件):以文本提示词为条件,生成 patches
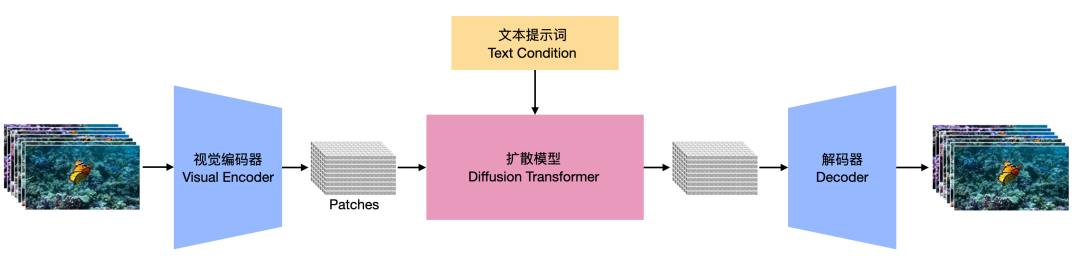
注:由于 Sora 并没有公布其论文,只发布了一个技术报告。技术报告中只是大概提到了一些技术概念,细节并不多,所以只能通过其引用的论文对其技术进行一个推测。
3.2 视觉编码器/解码器
将原始视频输入进编码器(Encoder),得到 Visual Patches,这个过程有点类似于“压缩”,然后再把 patches 送入后面的扩散模型,目的主要由两点:
- 将原始视频信息进行特征抽取,提取有效信息
- 将原始视频信息规模变小,降低后续网络计算成本

视觉编码器(Visual Encoder)
而解码器(Decoder)都是跟编码器成对出现的,作用是把扩散模型生成的patches还原为视频(可以理解为 encoder 的逆向过程),完成最终的视频输出。
Sora 技术报告中没有具体提得到 patch 的方式,下面是一种计算 patch 的方式,会在时间和空间两个维度同时对原始视频进行特征抽取,即将连续几帧的像素块“压缩”成一个 patch。
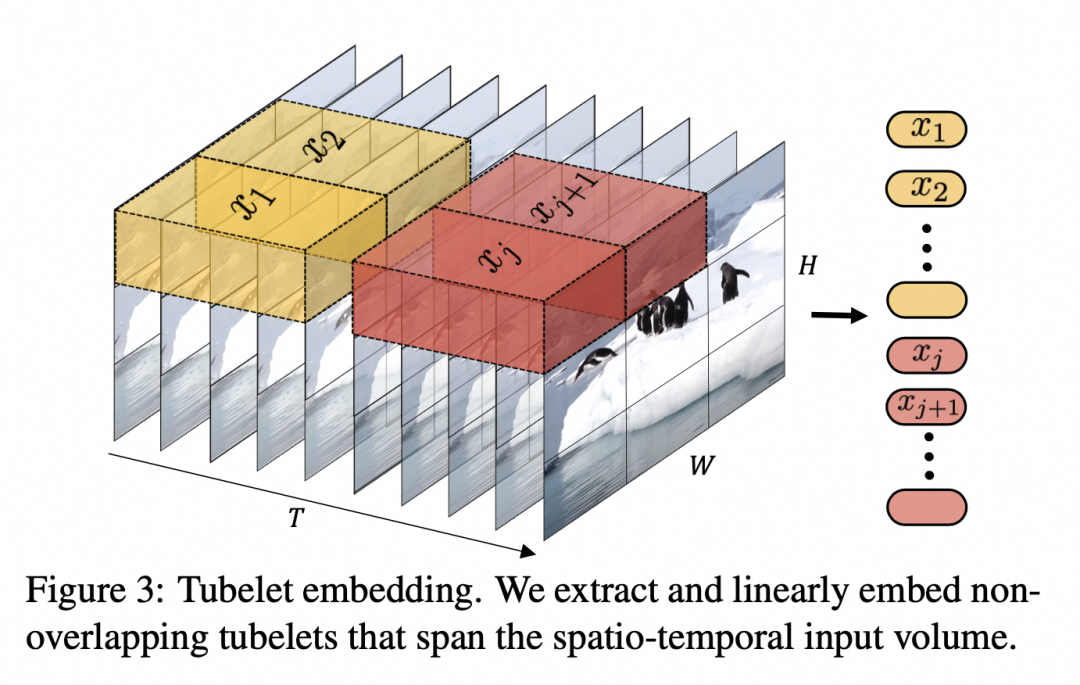
这个步骤将不同分辨率、不同视频长度的视频以及图片统一处理成 patches(图片可以认为是只有一帧的视频),最高分辨率可达 1920x1080 和 1080x1920,视频长度 1 分钟。
3.3 扩散模型
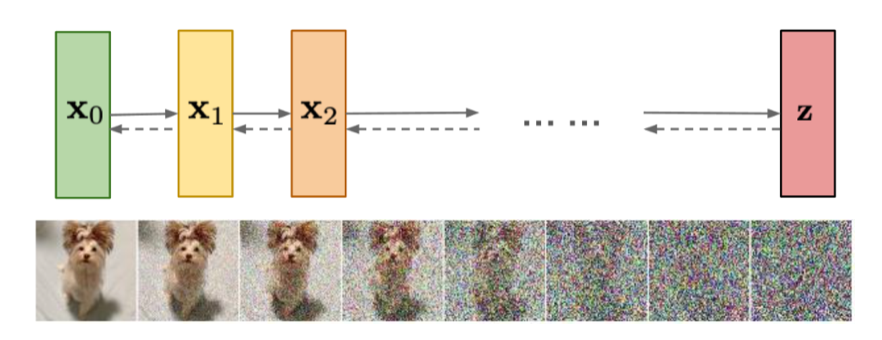
扩散模型(diffusion model)是当前图片生成、视频生成的主流技术,其原理是:
- 训练阶段
- 加噪:先将原始图片通过T步不断的加入噪声,最终得到完全噪声化的图片
- 去噪(denoise):将完全噪声化的图片进行去噪,通过T步逐渐还原为原始图片,这里会有一个噪声预测模型。另外,文本信息会在这时加入到模型中,使得在还原过程中,会考虑文本的语义。
- 预测阶段:随机生成一个噪声图片,且加入文本信息,执行训练阶段的去噪过程,即可得到生成的图片
注:实际送入扩散模型的是 patches,无法可视化为图片/视频,这里是为了方便理解,以原始图片送入扩散模型为例
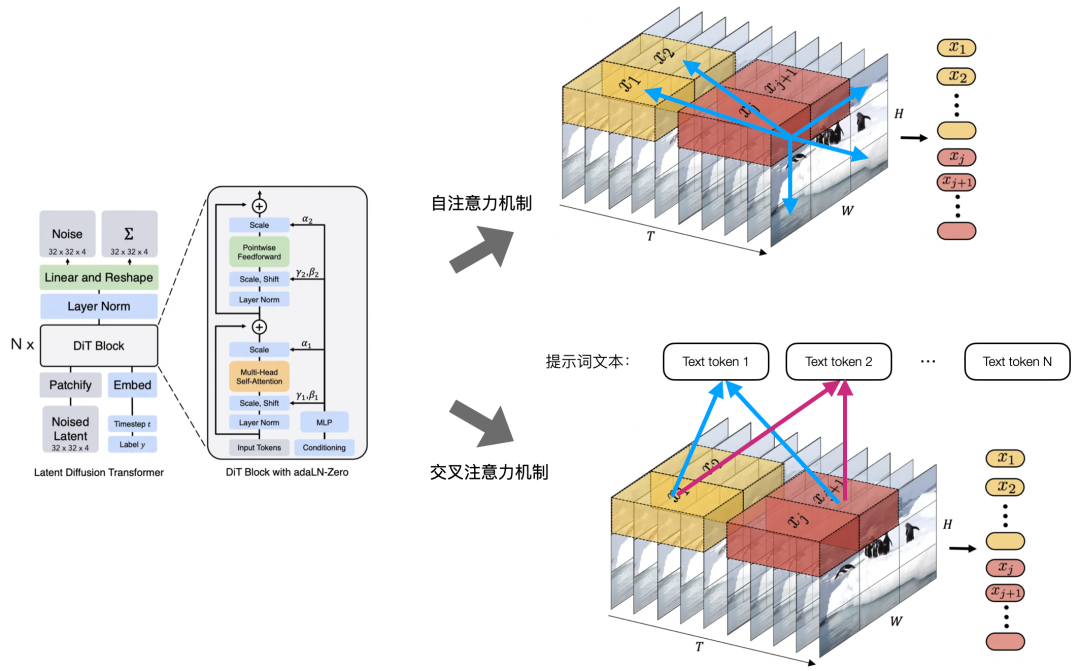
上面提到的噪声预测模型,Sora 使用的是 Transformer 结构,这个细节我们能从 DiT 论文上一探究竟。这其中有两个关键点,使 Sora 能够生成非常连贯且语义理解准确的长视频:
- 自注意力机制(self-attention):每一个视频 patch 都会去关注其他的所有 patch,使得模型在空间上,能够使不同像素块之间互相关注到,在时间上,即便跨过了较长时间,也能够使目标保持连贯性和持久性
- 交叉注意力机制(cross-attention):每一个视频 patch 都会去关注所有提示词文本 token(视频->patch,文本->token,是一个类似的意思),使得模型能够准确理解提示词语义意图,并让使用者通过提示词能更好的控制模型生成视频的内容
3.4 训练样本
OpenAI 的技术报告提到,大量带文本描述的视频对于训练这样一个模型非常重要。它使用了 DALL·E3(OpenAI提出的图像生成技术)为大量视频生成了高质量描述性文本,作为 Sora 的训练数据。使得 Sora 能够很好的理解提示词的语义,并进行视频的生成。
4. Sora 的能力
4.1 文生视频
Sora 可根据提示词生成视频。
提示词: 动画场景特写一个矮小的毛茸茸的怪兽跪在一支融化的红色蜡烛旁。艺术风格是 3D 和写实的,重点在于光线和质地。画作的氛围充满了惊奇和好奇,怪兽睁大眼睛,张开嘴巴凝视着火焰。它的姿势和表情传达出一种天真和俏皮的感觉,好像它是第一次探索周围的世界。温暖的色彩和戏剧性的照明进一步增强了图像温馨的氛围。
提示词: 超写实的特写视频,展现了两艘海盗船在一杯咖啡中航行时相互交战。
4.2 文生图
由于 Sora 将视频和图片进行了统一(图片就是只有一帧的视频),所以也可以根据提示词生成高清晰度的图片

4.3 文+图生成视频
Sora 可根据提供的图片和提示词文本生成视频。
如输入的图片:

提示词:在一座装饰华丽、历史悠久的大厅中,一道巨大的海浪正达到顶峰并开始破碎。两位冲浪者抓住时机,巧妙地在浪面上驾浪而行。
生成的视频:
4.4 视频扩展
可以给 Sora 指定开头的视频/图片,或结尾的视频/图片,使其生成视频。
如指定开头和结束是同一个骑车图片,就会生成一个无限循环在骑车的视频:
下面的视频由四个输入的视频首尾相接而成,Sora 会自动生成转场的动画,使得拼接效果更连贯:
4.5 视频风格转换
给定一个视频,可进行风格转换
输入视频:
根据提示词进行风格转换,提示词:将场景设置更改为在一个茂密的丛林中。
4.6 视频拼接
将两个视频直接进行合并
输入视频 1:
输入视频 2:
输出视频:
4.7 局限性
当前 Sora 也存在局限性,比如它可能会违反物理常识和直觉

5. Sora 总结
生成视频的特性:
- 三维一致性:Sora 能够生成具有动态相机运动的视频。随着相机的移动和旋转,人物和场景元素在三维空间中一致地移动。
- 长序列连贯性和目标持久性:即使在人物、动物和物体被遮挡或离开画面时,也能持续存在。同样,它可以在单个样本中生成同一角色的多个镜头,并在整个视频中保持其外观。
- 与世界互动:Sora 有时能够模拟以简单方式影响世界状态的行为。例如,画家可以在画布上留下随时间持久存在的新笔触,或者一个人可以吃一个汉堡并留下咬痕。
技术特性:
- 不同分辨率、不同视频长度的视频以及图片均可处理成 patches(图片可以认为是只有一帧的视频),统一由一个模型处理
- 通过 Diffusion Transformer 使其生成的视频具有更好的连贯性且能够准确理解提示词语义
从 OpenAI 透露的信息上来看,Sora 并没有提出原创性的全新模型结构,但提到了高质量数据源的重要性。由此我们可以看出,AIGC 的竞赛不仅仅是模型结构,还有大规模高质量训练数据、工程优化(更低的训练成本)、训练技巧和经验的竞争。
6. 参考
- Sora技术报告:Video generation models as world simulators:https://openai.com/research/video-generation-models-as-world-simulators
- What are Diffusion Models?:https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
- 真·降维打击,Sora与Runway、Pika的对比来了,震撼效果背后是物理引擎模拟现实世界:https://zhuanlan.zhihu.com/p/682551478
- Sora之前的视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0:https://blog.csdn.net/v_JULY_v/article/details/134655535
- 深入剖析Sora原理:细节解读与技术洞见:https://zhuanlan.zhihu.com/p/683169392