深度学习之ResNet家族
1. ResNet
ResNet最早由KaiMing He(何恺明)在2016年提出,并获得当年ImageNet比赛的冠军; 当前引用量超过10W+,是深度学习具有里程碑意义的架构。
ResNet指出随意的增加网络的深度,测试误差和训练误差都会比更浅层的网络来的大,模型并不能如我们所愿有选择的学习:深层的网络即使不会更好,也不应该会比浅层的网络差。ResNet在此基础上人为的增加归纳偏至,提出了著名的残差结构,使得网络学习残差的部分,最差的情况下学习的到残差信息为0,而不使得网络变差,而实际上残差信息是可以学习到,使得深度学习可以训练更深的网络。
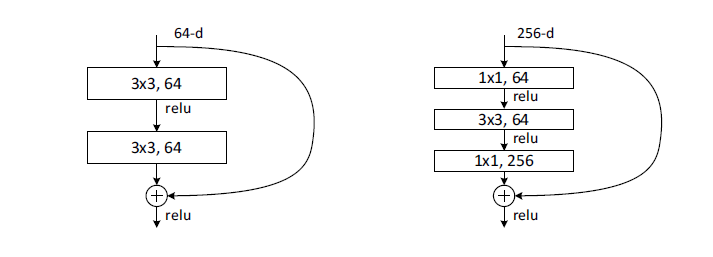
ResNet提出之后,有大量的科研工作者对其改进和调整,涌现出很多优秀的工作。本文整理分享了这些ResNet家族的成员,供大家参考。
ResNet的改进方向:
- 深度
- 宽度
- 因子
- 信息传递的方式
2. ResNetV2
同样是KaiMing He(何恺明),在分析了残差连接的方式之后提出ResnetV2,以此训练了1001层的resnet模型。
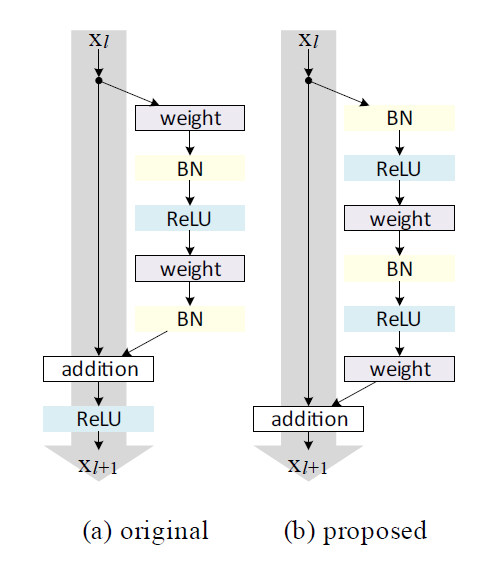
新旧对比可以看出有两个变化:
上一层的信息到下一层的进行直接的传递(没有relu激活层),使得信息传递更直接,可重复利用上一层的信息。文中作者做了很多不同的信息传递的尝试,效果都不佳。
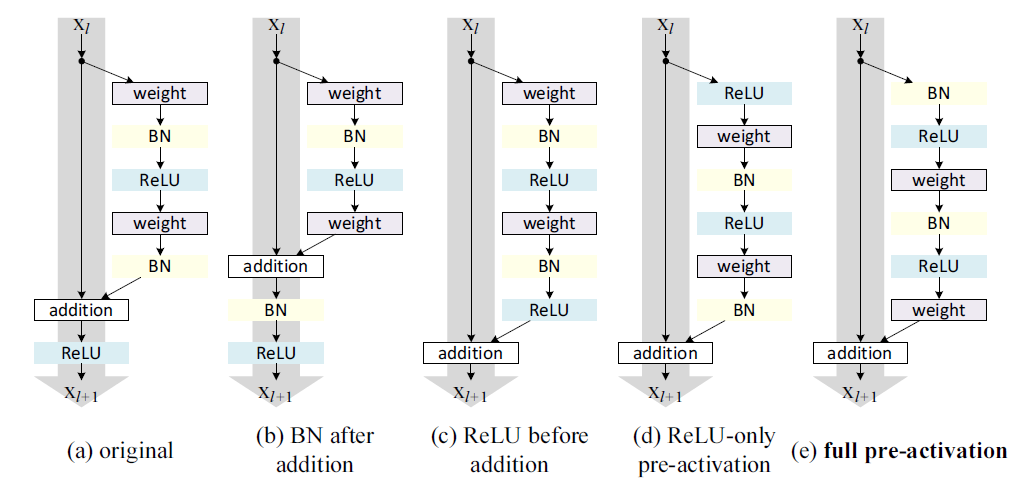
作者也尝试了不同的激活函数的组合方式,发现预激活(pre-Activation)效果是最好的。
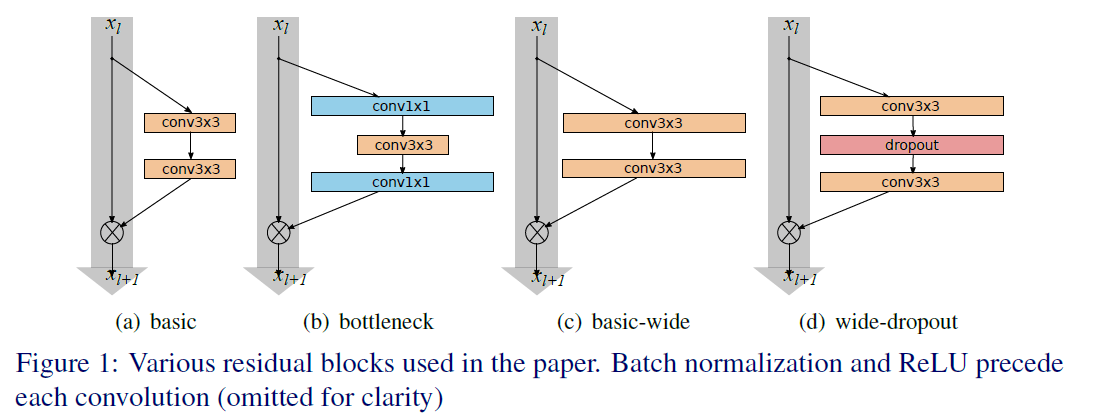
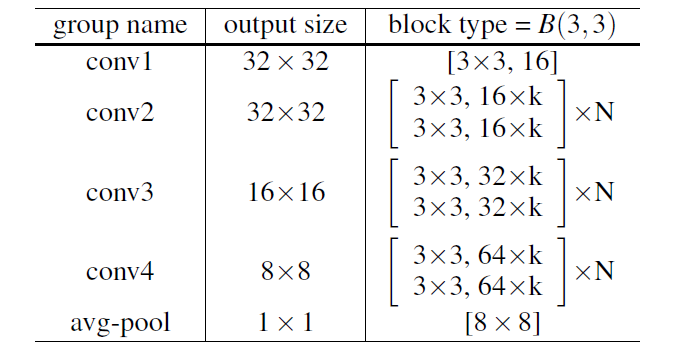
3. Wide Residual Networks
ResNetV2探索了在有效的信息传递的方式,可以训练更深的网络,效果也更好。而Wide Residual Networks指出网络可以训练的很深,但是往往精度的提升需要堆叠大量的层,使得训练时长加长;另一方面,ResNet天然的假设允许一个block可以不学习任何东西,某些网络层实际上是浪费的
在此基础上作者提出了WRN,减少深度,而增加宽度,使得每个block能学习到更加有效表示,文章指出即使16层的WRN也能达到更深网络的精度。
WRN在原始的特征channel上扩大K倍,同时也增加dropout层提高泛化。
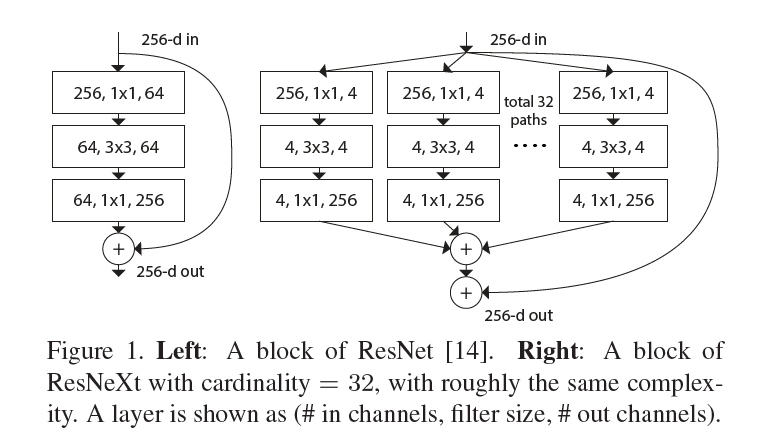
4. ResNeXt
ResNeXt在深度和宽度设计之外,从cardinality(基数)角度重新考虑模型的设计。ResNet是采用重复的策略(repetition strategy),ResNeXt采用的是分裂-转换-合并(split-transform-merge strategy),这个分裂的数量就是cardinality。每个分裂的转换结构结构是相同的,但是学习是独立的,增加了学习特征的多样性,也是文章标题Aggregated集成多个特征转换的含义所在。
5. Deep Networks with Stochastic Depth
在深度、宽度和三个维度探索ResNet架构的可能性的同时,Deep Networks with Stochastic Depth指出训练很深的网络存在耗时长和训练难的问题,论文提出一种通过设计随机深度降低训练难度,有在测试时可以利用深度网络的有点的训练策略。
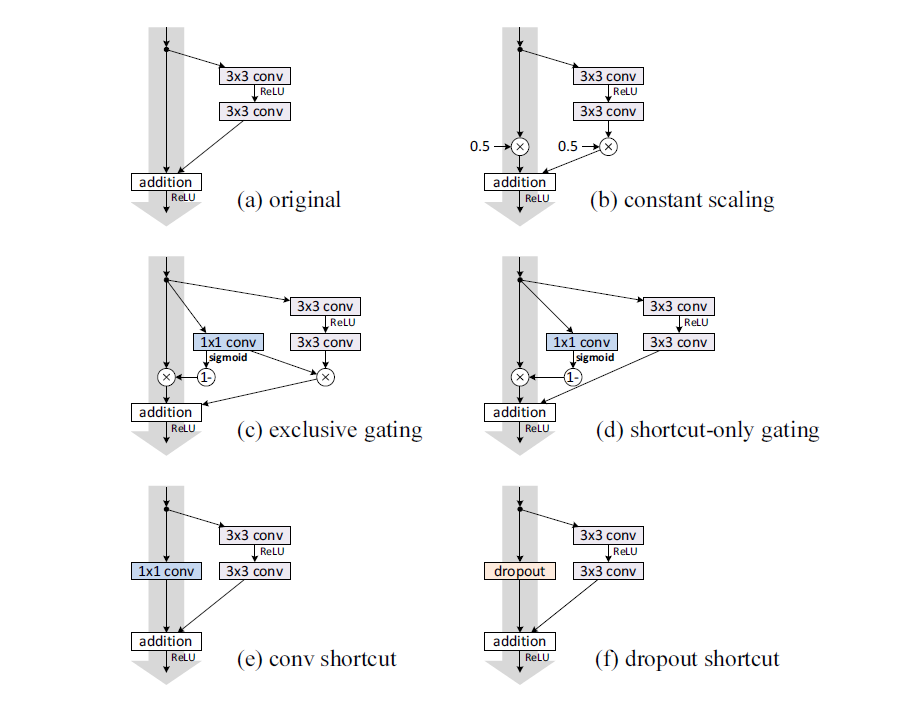
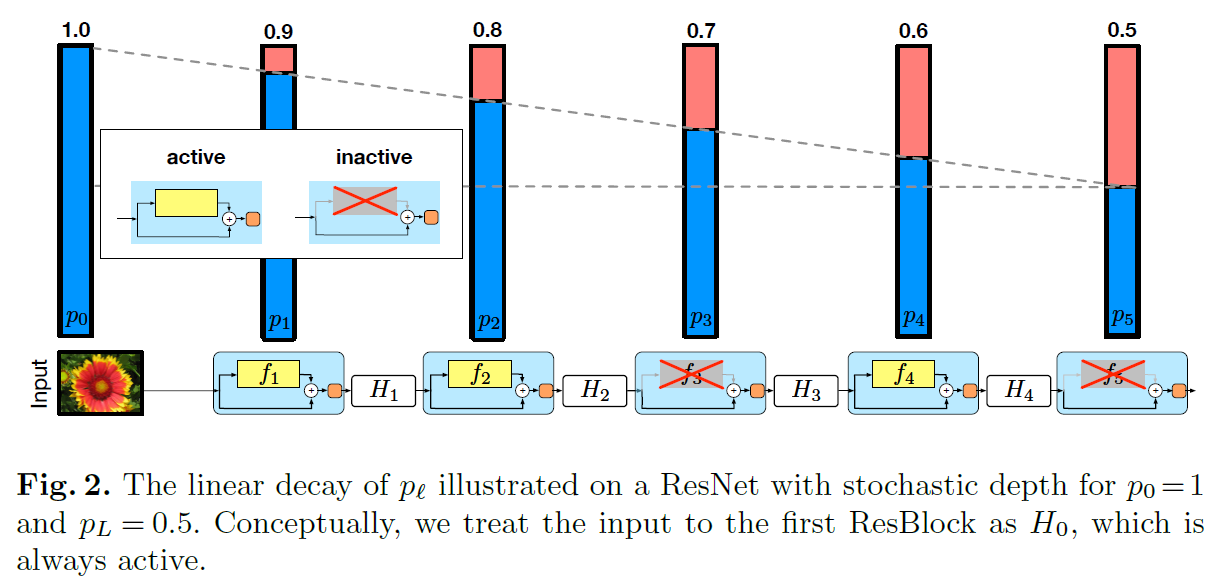
ResNet with stochastic depth分析了ResNet结构的特点:残差学习,残差部分(下图中黄色的部分)是允许不学习任何信息,而可以顺利传递信息。ResNet with stochastic depth于是尝试将残差部分以一定随机概率丢弃,从而训练过程降低训练的参数,加快训练过程(不需要前向计算和梯度更新);另一方面由于每次迭代都随机丢弃某些残差层,迭代与迭代之间丢弃层可能是不同,每次训练的是不同的模型,而且参数是下次迭代共享更新,等同于一次训练了多个模型,在测试时综合和所有的使用的层,一定程度是集成的模型(多模型融合的效果),实验表明泛化能力更好。
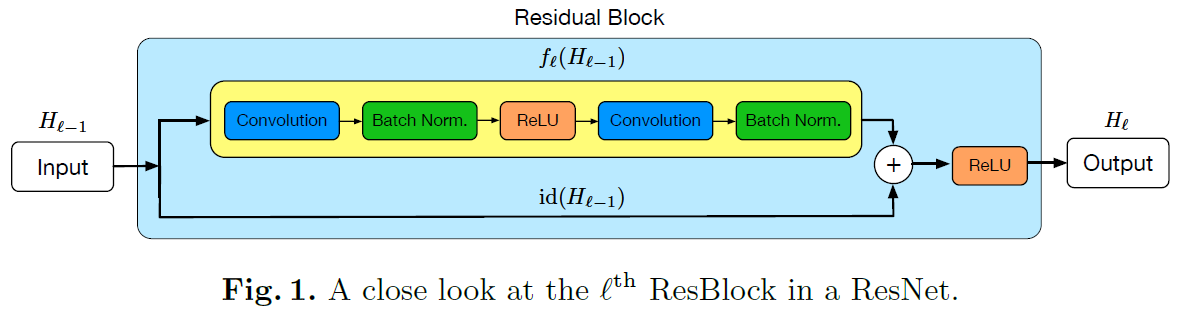
关于如何丢弃残差部分,如下图所示采用了随着深度加深逐层加大丢弃概率(pl)PL=0.5。
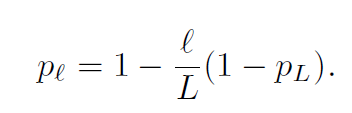
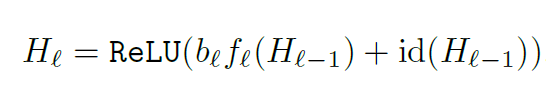
在测试时,ResNet with stochastic depth综合了所有使用的层,还原成完整的深度的网络结果,每一层按照丢弃的概率进行融合,达到模型集成的目的。集成方式如下: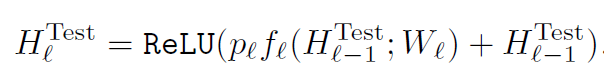
ResNet with stochastic depth和Dropout很类似(包括测试的概率还原),不同的是,Dropout是对神经元的丢弃而ResNet with stochastic depth是丢弃整个层,而其正式得意于Resnet的残差结果。
6. DenseNet
DenseNet在信息传递方式上拓展了Resnet。DenseNet的一个特点就是密集的连接,加大信息的共享和利用,另外DenseNet并没有采用残差的方式来合并信息,而是采用concat补充信息的方式来整合当前层和前面所有层的信息,这样的好处是可以增加更多的信息。DenseNet和ResNet with stochastic depth为同一作者。
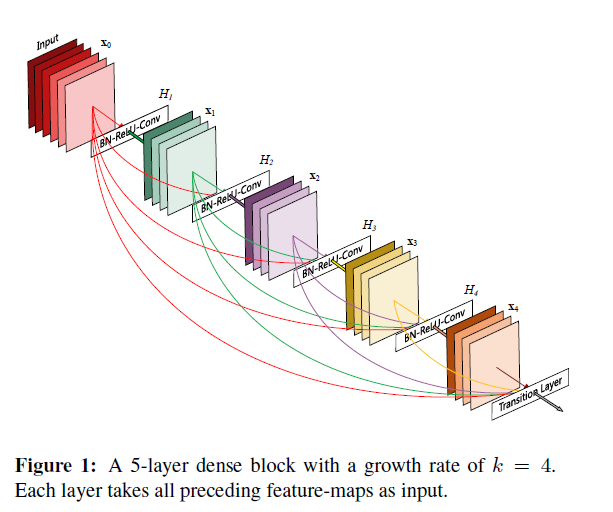
从上图可知,一个5层的dense block中,第2层的输入时来自第一层,而第三层的输入为第一层和第二层,以此类推,最后一层的输入为前面所有层的信息;从另一个角度看,第一层的信息传递到后面的每一层。DenseNet通过growth rate来决定多少信息传递到下一层。
- DenseNet的详细讲解可参见上一篇《深度学习之解构基础网络结构》
- https://github.com/liuzhuang13/DenseNet
7. DPN(Dual Path Network)
到现在为止,前面2到6是Resnet上演化,DenseNet是信息传递方式拓展了Resnet。还能其他的方式吗?
啊哈时刻来了,有的。DPN综合了ResNet和DenseNet两种信息传递方式,构建了两路信息传递网络。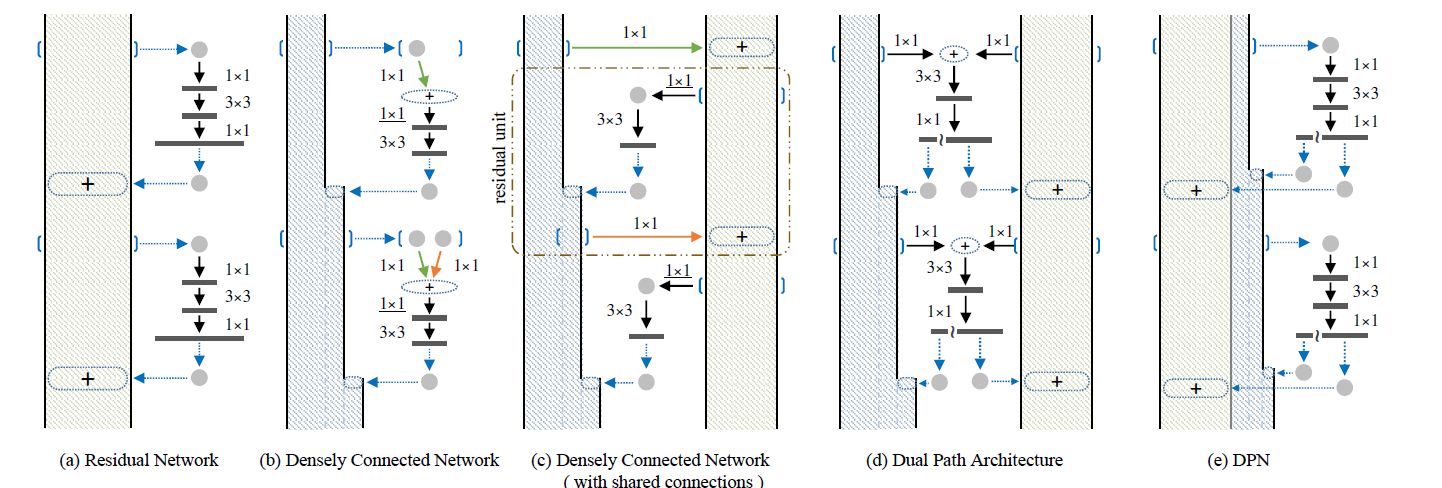
论文中的图看的有点费解(最右边为DPN),我们可以从论文中的出发点来理解就可以理解图中的含义:关键词为两路信息(残差部分和concat叠加部分)。从上图中为偏黄的一路为残差部分,灰色部分为concat叠加部分,也就是在block分支信息加工之后分成两部分,一部分学习残差的部分,另一部分作为新信息叠加到原始信息中。
DPN指出ResNet的残差方式没有增加更多信息的特征,而保留了特征和残差学习,而Densenet能通过密集连接并concat叠加的方式创造更多的特征,能给网络带来学习表征能力。
8. ResNest
ResNest是2020李沐团队和Facebook(meta)提出的一种结果特征注意力和多路表征学习的结构。ResNest可以说是之前技术的结合体:注意力机制 + 多路特征(基) + 残差学习。注意力机制会在后续和大家做详细分享。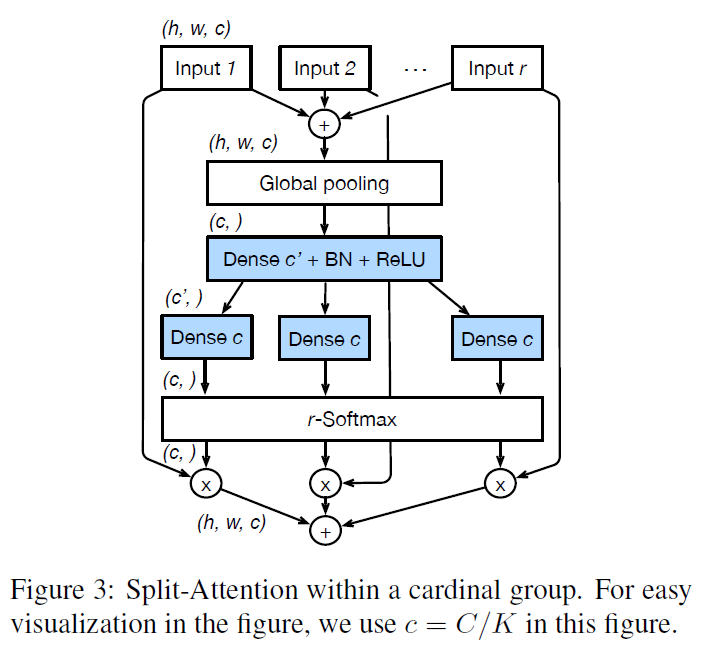
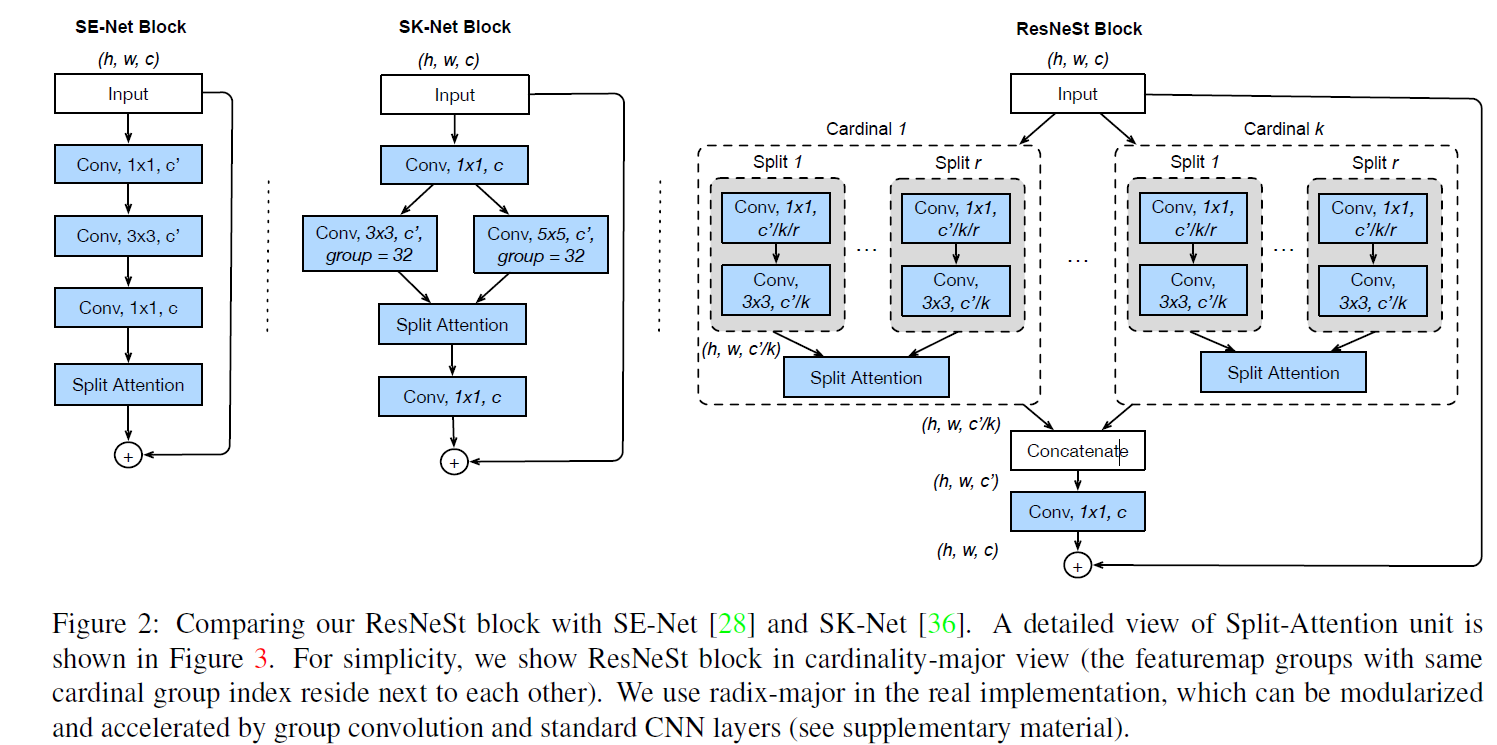
看起来很复杂,ResNest通过组合通道注意力和分解多路特征和残差学习来学习更好的特征。 其中
- 通道注意力(split attention):为每一个通道计算一个权重对输入通道进行加权来学习通道的重要性
- 多路特征:和ResNeXt类似,输入拆分成多路分别进行表征学习,只不过多路有进行进行多个小组(group),每个group进行通道注意力后,所有group信息进行合并最终和输入进行残差连接。
ResNest是站在巨人肩膀上的吧。
9. 总结
本文从深度 宽度 基数和信息传递方式和大家分享了ResNet的后继深度学习架构的演进,希望对你有帮助。总结如下:
- ResNetV2: 信息直接传递 + 预激活
- ResNext: 多路(基)学习能学到更好的表征
- Wide Residual Networks:可以试着加宽,更有效的进行残差学习,充分利用残差提取更多特征
- deep Networks with Stochastic Depth:随机深度降低训练耗时,又能融合多模型集成,提升泛化能力
- DenseNet:密集连接产生新特征,学习更好的特征
- DPN:融合ResNet和DenseNet的特点
- ResNeSt则是融合Attention + ResNext + group conv + Resnet,站在巨人肩膀上
搜索关注公众号:人工智能微客(AIweker)可批量下载所有论文(发送resnet)和讨论更详细的细节思路
10. 参考文献
- Deep residual learning for image Recognition
- Identity Mappings in Deep Residual Networks
- Wide Residual Networks
- Aggregated Residual Transformations for Deep Neural Networks
- Deep Networks with Stochastic Depth
- Densely Connected Convolutional Networks
- Dual Path Network
- ResNeSt: Split-Attention Networks



