问题一:大数据计算MaxCompu使用pyodps 和 odpssql对mc表数据进行清洗处理 哪个效率高?
"1大数据计算MaxCompute使用pyodps 和 odpssql对mc表数据进行清洗处理 哪个效率会高一些呢?
- 大数据计算MaxCompute的cte 产生的临时结果集 的生命周期有多长呢 可以在odps sql 节点 里面使用么?"
参考答案:
首先,关于第一个问题,pyodps和odpssql在MaxCompute中的效率,这个取决于你的数据量和数据处理复杂性。
- pyodps:这是阿里云MaxCompute的Python SDK,它提供了丰富的API以支持MaxCompute的各类操作。由于它是Python写的,所以在处理复杂的数据清洗任务时可能会更灵活,更方便。然而,由于Python在处理大数据时的性能限制,对于超大规模数据,可能会比使用odpssql稍慢一些。
- odpssql:这是MaxCompute的SQL接口,可以直接在ODPS中运行SQL语句进行数据操作。对于简单的数据清洗任务,odpssql可能会更快一些,因为它直接在MaxCompute的分布式环境中运行,而不需要通过Python进行中转。然而,对于复杂的数据清洗任务,odpssql可能不如pyodps那么灵活。
至于第二个问题,关于大数据计算MaxCompute的cte产生的临时结果集的生命周期,这个主要取决于你的代码逻辑和系统配置。在大多数情况下,临时结果集的生命周期应该与你的整个MaxCompute作业的生命周期相同。也就是说,只要你的作业还在运行,临时结果集就应该存在。
至于在odps sql节点里面是否可以使用cte(Common Table Expression),根据我的知识库,odpssql确实支持cte。你可以在SQL语句中使用cte来创建和管理临时结果集。
总的来说,如果你需要处理的数据量非常大,并且数据清洗任务相对简单,那么odpssql可能会更高效一些。如果你需要处理的数据量适中,并且需要进行复杂的 数据清洗任务,那么pyodps可能会更合适。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/567867
问题二:大数据计算MaxCompu使用pyodps 和 odpssql对mc表数据进行清洗处理 哪个效率高?
"1.请问大数据计算MaxCompute使用pyodps 和 odpssql对mc表数据进行清洗处理 哪个效率会高一些呢?
- 大数据计算MaxCompute的cte 产生的临时结果集 的生命周期有多长呢 可以在odps sql 节点 里面使用么?"
参考答案:
这取决于具体的应用场景。一般来说,在数据清洗方面,ODPS SQL更容易理解和使用,但是对于复杂的需求,可以考虑使用PyODPS。
具体的区别包括:
- PyODPS更加强大,可以进行更复杂的逻辑处理;
- ODPS SQL较为简单,适合一般的筛选、排序等操作;
- 在性能方面,PyODPS能够更好地利用GPU加速等功能,但是有一定的学习成本。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/567835
问题三:DataWorks如何增加maxcompute的自定义资源?
DataWorks如何增加maxcompute的自定义资源?
参考答案:
添加资源下载用于IP地转换的自定义函数Java包getaddr.jar以及地址库ip.dat。关于IP地址转换的自定义函数,详情请参见MaxCompute中实现IP地址归属地转换。右键单击WorkShop业务流程下的MaxCompute,选择新建 > 资源。需要分别新建File和JAR类型的资源。 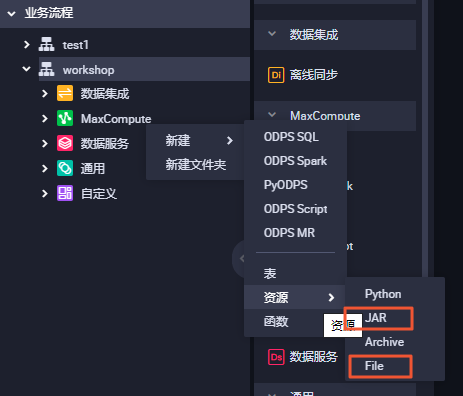
File类型上传地址库ip.dat。输入资源名称,选中大文件(内容超过500KB)及上传为ODPS资源,然后单击点击上传。  单击提交。
单击提交。
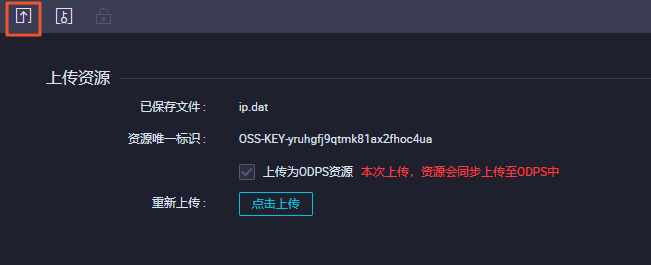
JAR类型对应Java包getaddr.jar。您需要勾选上传为ODPS资源,然后单击点击上传。上传完成后,单击 
提交。说明 提交时,请忽略血缘不一致信息。注册函数在业务流程下右键单击MaxCompute,选择新建 > 函数,将函数命名为getregion。在注册函数页面,依次填写类名为odps.test.GetAddr,资源列表为getaddr.jar,ip.dat,命令格式为getregion(ip string),保存后单击提交函数注册。 
https://help.aliyun.com/document_detail/122859.html
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/567757
问题四:DataWorks中maxcompute自定义函数jar包创建?
DataWorks中maxcompute自定义函数jar包创建?
参考答案:
点击以下链接下载依赖JAR包:alisa-wrapper-face-1.0.0.jar。
https://help.aliyun.com/document_detail/198585.html
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/567755
问题五:DataWorks中MaxCompute里面有类似于least的函数嘛?
DataWorks中MaxCompute里面有类似于least的函数嘛?我记得直接就有least
参考答案:
很高兴告诉您,在MaxCompute中,您可以使用LEAST()函数进行最小值的选择。LEAST()函数可以从一组数字表达式中返回最小的一个,如:
SELECT LEAST(a, b, c);
其中,“a”、“b”和“c”代表数值表达式。此函数将返回三个表达式中最小的那个值。
请注意,您可以在MaxCompute官方文档中查看关于LEAST()函数的详细说明以及它的应用示例。
关于本问题的更多回答可点击进行查看:
