问题一:DataWorks如何在MaxCompute客户端添加python第三方包?
DataWorks如何在MaxCompute客户端添加python第三方包?
参考答案:
如何在pyodps调用第三方包?
需要使用独享调度资源组进行操作,详情请参考文档:在PyODPS节点中调用第三方包https://help.aliyun.com/zh/dataworks/use-cases/use-a-pyodps-node-to-reference-a-third-party-package#task-1954895
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/571123
问题二:在大数据计算MaxCompute中,这是什么情况?

参考答案:
project name我看你上午提交的是prod_kerry_dw,重新提交下吧。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/571032
问题三:在大数据计算MaxCompute中,有什么方案可以让别人自动触发我的maxcompute任务吗?
有什么方案可以让别人自动触发我的maxcompute任务吗?或者 有没有方法 让mc中的表跟rds中的表 始终保持一致?我也想做的是 在maxcompute中更改后 也能实时同步到mysql
参考答案:
如果你想让 MaxCompute 中的任务能够自动触发,或者希望 MaxCompute 中的数据能够实时地更新 MySQL 数据库,你可以考虑以下几种方案:
- 使用 DataHub 来实现两个数据库之间的实时同步。DataHub 是阿里云的一种消息中间件产品,它提供了一种高效、可靠的双向数据流解决方案。您可以通过使用 DataHub 的订阅功能,将 MaxCompute 中的数据实时地推送到 MySQL 数据库中。
- 使用 DataWorks 来实现任务自动化。DataWorks 是一种企业级的大数据分析平台,它可以帮助您管理和调度各种数据处理任务。您可以将 MaxCompute 中的任务添加到 DataWorks 中,并设置触发条件和调度策略,从而实现自动触发任务的功能。
- 使用 Lambda 函数来实现任务自动化。Lambda 函数是一种轻量级的服务,它可以根据预定义的条件触发代码执行。您可以使用 Lambda 函数来监视 MaxCompute 中的数据变化,一旦发现数据发生变化,就触发相应的任务。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/571030
问题四:在大数据计算MaxCompute中,我这边启动都是失败的,是目前还没有资源吗?

我这边启动都是失败的,是目前还没有资源吗?
参考答案:
对于您的MaxCompute启动失败的问题,可能有多种原因。其中一种可能是计算资源不足。在MaxCompute中,配额组(Quota)是MaxCompute的计算资源池,为MaxCompute中的计算作业提供所需计算资源(CPU及内存)。如果您的作业对计算资源的需求超过了您的配额组的资源,可能会导致任务启动失败。
另一种可能是环境配置问题。例如,如果调度配置有多个网关资源组,一般有一个默认的资源组,需要JDK为1.8及以上版本,如果环境中的JDK版本不满足要求,也可能导致任务启动失败。
此外,如果您想使用MaxCompute的自定义函数(UDF)或MapReduce功能,需要依赖资源来完成。例如,您编写UDF后,需要将编译好的JAR包以资源的形式上传到MaxCompute。运行此UDF时,MaxCompute会自动下载这个JAR包,获取您的函数。如果这些步骤未正确执行,也可能引发启动失败的问题。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/571029
问题五:在大数据计算MaxCompute中,数据集成时 能update吗?
数据集成时 能update吗?第二第三条 怎么看起来是一样的,一个update,一个先delete再insert而已 结果不是一样吗 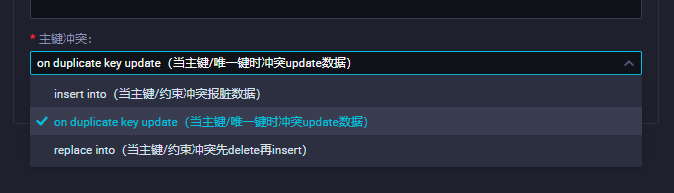
参考答案:
对于MySQL来说,是存在差别的。选择导入模式,可以支持insert into、on duplicate key update和replace into三种方式:
insert into:当主键/唯一性索引冲突时会写不进去冲突的行,以脏数据的形式体现。
如果您通过脚本模式配置任务,请设置writeMode为insert。
on duplicate key update:没有遇到主键/唯一性索引冲突时,与insert into行为一致。冲突时会用新行替换已经指定的字段的语句,写入数据至MySQL。
如果您通过脚本模式配置任务,请设置writeMode为update。
replace into:没有遇到主键/唯一性索引冲突时,与insert into行为一致。冲突时会先删除原有行,再插入新行。即新行会替换原有行的所有字段。
如果您通过脚本模式配置任务,请设置writeMode为replace。
关于本问题的更多回答可点击进行查看:


