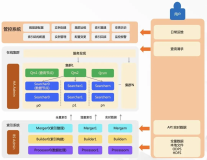
一、架构模式
在介绍具体问题之前,先回顾前面的知识。Havenask主要有两种架构模式,即读写分离模式和读写统一模式。读写分离与读写统一相比,主要在于多了独立的索引。


二、Hape运维脚本问题
构建服务叫build service,Havenask主要由下面几个部分组成:
- Hape运行脚本
- 在线系统
- 索引构建系统Build Service
- Swift消息中间件
- 还有其他依赖的一些基础的组件,比如zk、hdfs等。
Havenask的所有操作都是通过Hape脚本来实现的,它在脚本执行过程中可能会出现命令执行失败的情况。在解决这类问题时,我们首先通过Hape脚本提供的validate的命令验证配置是否,如果正确,再在执行的命令后面加-v的参数(hape start havenask –v),打印命令执行过程中的详细的信息。另外,Hape脚本是使用Python编写的,我们可以直接修改这个脚本,进行pdb的跟踪。
三、集群相关问题
集群相关的问题较为复杂,它主要包括在线集群的问题、BS集群的问题、Swift集群的问题和一些依赖的基础组件的问题。
- 在线集群的问题主要表现为在线集群节点启动异常、查询异常(主要包括查询耗时变大或查询报错)、表加载异常等。
- BS集群的问题主要包括BS结集群节点启动异常、数据处理延迟、索引构建异常等。
- Swift集群的问题主要包括Swift进群节点启动异常、Swift数据处理延迟等。
- 基础组件的问题主要包括ZK的问题和hdfs的问题,ZK的问题主要包括上面各个集群的节点启动异常,Hdfs的问题可能会导致索引数据、实时数据的读写异常等。
在排查这些问题时,我们首先要确定出现问题的部分,找到对齐的部分后,主要通过排查对应的日志确定具体问题的原因。如在线集群出现问题后,可查看在线Master的日志,在在Master日志中查看是否有异常的节点。另外,如果已经确定了异常节点,就可以查看对应异常节点上的日志。
三、表相关问题
表相关的问题主要包括表创建失败,或是表创建成功但未生效,或是表全量失败,或时表索引构建过慢等方面。
- 表创建失败,是指在通过HAPE脚本创建表时报错,我们就可以直接在Hape执行命令过程中加一个-v参数,排查具体报错的原因。
- 表创建成功但未生效,我们可以到对应的在线集群的Master节点中查看对应的日志。
- 表全量失败和表索引构建过慢主要是由索引构建服务异常(如配置不合理等)导致的,我们主要排查build Service日志数据写入的问题,主要包括数据写入后一直未生效,无法在线查询,或是查询得到的结果与写入的原数据不一致。
四、数据写入与查询问题
- 排查这类问题,首先要确保写入的数据无误,其格式是Havenask支持的正确格式。其次,要确定表是全量表或是直写表,因为全量表和直写表对应的整体数据生效链路不同。
- 若是全量表,在数据写入时应先将数据写入Swift,然后处理BS process节点,重新发送到一个Swift中转,在线的search节点直接从Swift上面去获取处理后的数据,然后直接在内存中构建。若是直写表,数据直接发到search,直接构建成索引,然后search把数据写入Swift,继而其他的数据节点同步这个数据,构建成索引。
- 总之,全量表和直写表的数据生效链路不同。在确定属于何种表之后,根据首次推送到的节点开始逐步排查。对于一个全量表,数据推送后一直未生效,可以排查是否所有消息中间件都有数据延迟,是否数据处理节点有延迟,是否由于设置节点内存已满导致索引构建失败。这样,我们基本可以确定数据未生效的原因。
- 查询耗时过大或是查询报错主要是由于在线集群异常或某些配置不合理或扫描的数据节点数据量过多导致的。如查询耗时过大,可以首先确定query,即是否是由于扫描数据量大导致的,如果扫描数据合理,则要检查在线集群的资源是否有瓶颈,这里的资源主要是指CPU资源和内存资源。如果第一次查询较慢,再次查询可能会相对较快,之后,原因是内存资源可能存在瓶颈,或是待查询的数据刚开始不在内存中,我们需要将它提前加到内存中,这样查询耗时就会变短。
- 另外一个资源是CPU资源,只要查看CPU水位即可,CPU过高会导致查询耗时变大。查询报错,主要排查查询的query是否正确,报错时,我们可以通过查询错误的日志或通过在查询语句中添加一些trace,进而查看具体的原因。
除了以上问题外,数据写入与查询问题比较复杂,我们还需要根据具体的case具体分析。
四、结尾
具体Havenask问题排查的视频可以通过链接查看,欢迎各位开发者使用。
视频链接:https://developer.aliyun.com/live/253856?spm=a2c6h.13262185.profile.5.563bee42LdD7By
关注我们:
Havenask 开源官网:https://havenask.net/
Havenask-Github 开源项目地址:https://github.com/alibaba/havenask
阿里云 OpenSearch 官网:https://www.aliyun.com/product/opensearch
钉钉扫码加入 Havenask 开源官方技术交流群: