前言
在 3月23日 的时候,我去参加了 GDC(全球开发者先锋大会) 。在现场,听了几个大佬的前沿分享,感觉受益良多。同时也看到了一些很有意思的东西:
比如说这个机械狗

还有马斯克的“火星车”

以及最近火爆出圈的支持 200W token 上下文的大语言模型 kimi :

然后在主会场听了一个关于 魔搭社区 的一个分享



听完之后,我理解魔搭上有很多开源的 AI 模型以及数据集,以及它依托了阿里云平台的算力,可以让开发者快速的在魔搭平台去体验这些模型和微调这些模型。
后面我去另外一些分会场听讲座的时候,发现很多创业公司都是说他们依托于魔搭做了什么什么事情,我就想这魔搭是不是投了很多广告还是说这个活动是他赞助的哈哈哈。但这里只是猜测罢了,大家听听就算了。
听完回来之后,我就想自己试一下魔搭这个平台,看看上面有什么好玩的东西。
模型Demo体验

进入魔搭社区之后,发现上面已经有 3000 多个模型,我们就挑一些自己感兴趣的来玩一下。
我们先来尝试一下 百川2-13B-对话模型 这个大语言模型,它是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。
复制一下这里的示例代码。然后进入到 Notebook 中,就可以快速体验这个模型。

进入到 Notebook 之后,新建一个 baichuan.py 文件,填入如下代码。
from http import HTTPStatus from dashscope import Generation import dashscope # 可根据下方'开通DashScope并创建API-KEY'文档获取API-KEY进行填充 dashscope.api_key = 'API-KEY' def call_with_messages(): messages = [ {'role': 'user', 'content': '你是什么'}] gen = Generation() response = gen.call( 'baichuan2-13b-chat-v1', messages=messages, result_format='message', # set the result is message format. ) print(response) if __name__ == '__main__': call_with_messages()
然后先安装一下相关依赖, pip install dashscope ,然后控制台运行 python3 baichuan.py 可以看到,模型已经成功跑起来。

模型API体验
在魔搭平台上,有一些模型已经提供了 API 接口,我们可以直接拿到调用(套娃)。这里我选了三个,分别是:
- 通义-文本生成图像大模型-中英文-通用领域
- GPT-3诗词生成模型-中文-large
- GPT-3夸夸机器人-中文-large
以诗词生成模型为例,打开之后就可以看到自己的 token 以及调用的示例代码:

我们来做一个简单的前端页面,然后来调用一下诗词生成接口来试试效果:
import { Button, Form, Input } from "antd"; import React, { useState } from "react"; import { axios } from "../../api/index"; const API_URL = "/moda/api-inference/v1/models/iic/nlp_gpt3_poetry-generation_chinese-large"; const headers = { Authorization: "Bearer your-token", }; const Poem = () => { const [form] = Form.useForm(); const [loading, setLoading] = useState(false); const [result, setResult] = useState(""); const handleClick = async () => { const { text } = await form.validateFields(); setLoading(true); try { const res = await axios.post( API_URL, { input: text, }, { headers, } ); if (res.data.Data.text) { setResult(res.data.Data.text); } } finally { setLoading(false); } }; return ( <div> <Form form={form}> <Form.Item name="text" label="提示词" rules={[{ required: true, message: "提示词不可为空" }]} > <Input.TextArea maxLength={75} showCount /> </Form.Item> </Form> <Button loading={loading} onClick={handleClick} type="primary"> 生成 </Button> <h4>{result}</h4> </div> ); }; export default Poem;
这个页面很简单,点击之后拿到输入框的值去调用接口而已,没有特别需要交代的地方。唯一注意的是需要配置一下转发:
proxy: { "/moda": { target: "https://api-inference.modelscope.cn", changeOrigin: true, rewrite: (path) => path.replace(/^\/moda/, ""), }, }
下面来试试效果:

还有一个彩虹屁的模型:

不过我觉得这彩虹屁的效果也不咋地😓
但是当我调用文生图模型时,直接就报错了:

可能是部署API的机器太多人调用了,在官网成功调用过一次,至于效果如何大家自行评价吧

一种外部调用算法模型的方式
如果你已经在利用魔搭的机器资源跑起来一个模型,但是魔搭起的机器好像外面是访问不到的。也就是说,比如我起了一个文生图的模型,想给我的前端页面调用,这个时候应该怎么解决呢?下面介绍一种外部调用模型的方式。
这里以OFA图像描述-中文-电商领域-base这个模型为例,

这个模型用于输入一张图片,然后模型输出这张图片的描述。
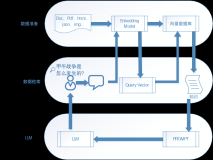
具体的实现流程先看一下这张图:

这里会有三个端:
- 前端:上传图片,以及展示图片的解析结果
node:就是后端,接收到图片之后,生成一条任务入库,其中任务表的DDL语句如下:
CREATE TABLE `missions` ( `id` int(11) NOT NULL AUTO_INCREMENT, `status` int(4) DEFAULT '0', `src` varchar(255) DEFAULT NULL, `content` mediumtext, `update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP, `create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4;
其中 status 字段是任务的状态,未执行是 0 ,执行完成是 1 ; content 是任务的执行结果,也就是模型的输出。
- 算法:轮训向
node端获取待执行的任务,然后进行模型推理,推理完成之后,更新任务的状态。
这里我为了方便,通信都是使用轮训来完成,如果想达到更好的效率,可以通过 WebSocket 。下面来看看各端的具体实现
前端
前端实现逻辑十分简单,就是普通的上传图片,然后轮训获取任务的状态:
// 上传图片 const handleFileChange = (e) => { const file = e.target.files[0]; const formData = new FormData(); formData.append("file", file); setLoading(true); axios.post(`${BASE_URL}/aigc/upload`, formData).then((res) => { setUrl(res.data.data); setId(res.data.id); }); }; // 获取任务执行结果 useEffect(() => { if (!id) { clearInterval(interval.current); return; } interval.current = setInterval(() => { axios.get(`${BASE_URL}/aigc/getResultById/${id}`).then((res) => { if (res.data.content) { clearInterval(interval.current); setResult(res.data.content); setLoading(false); } }); }, 1000); return () => { clearInterval(interval.current); }; }, [id]);
后端
后端这里提供几个接口:
第一个是上传图片接口,或者说是创建任务的接口,使用到的是 multer 这个库来接收上传的图片,把图片写入到静态资源目录中,并往数据库中添一条记录。
js
复制代码
const upload = multer(); router.post("/upload", upload.single("file"), async (req, res) => { const file = req.file; const timestamp = Date.now(); const ext = path.extname(file.originalname); const newName = `${timestamp}${ext}`; const filePath = path.join(UPLOAD_PATH, newName); fs.writeFile(filePath, file.buffer, (err) => { if (err) { console.error("写入文件时出错:", err); res.json({ data: false }); return; } const url = `http://your-ip:3000/upload/${newName}`; connection.query( "INSERT INTO missions (src) VALUES (?)", [url], (err, results) => { if (err) { console.error("上传失败:", err); res.status(500).send("插入失败"); return; } res.json({ data: url, id: results.insertId }); // 返回查询结果 } ); }); });
然后就是获取一条待执行的任务的接口,从数据库中查询一条 status 为 0 的记录出来,这个接口供算法端调用:
router.get("/getMission", async (req, res) => { const sql = "SELECT * FROM missions WHERE status = 0 LIMIT 1"; connection.query(sql, (err, result) => { if (err) { console.error("查询数据时出错:", err); res.json(false); return; } if (result.length === 0) { console.log("没有找到status为0的任务"); res.json(false); return; } console.log("找到status为0的任务:", result[0]); res.json(result[0]); }); });
再提供一个更新接口,算法模型推理完之后,把结果更新到数据库中:
router.post("/updateMission", (req, res) => { const { content, id } = req.body; const sql = "UPDATE missions SET status = ?, content = ? WHERE id = ?"; connection.query(sql, [1, content, id], (err, result) => { if (err) { console.error("更新数据时出错:", err); res.status(500).send("更新数据时出错"); return; } if (result.affectedRows === 0) { console.log(`没有找到ID为${id}的任务`); res.status(404).send(`没有找到ID为${id}的任务`); return; } console.log(`成功更新ID为${id}的任务`); res.send(`成功更新ID为${id}的任务`); }); });
最后提供一个查询任务的接口,供前端调用,获取任务的执行结果:
router.get("/getResultById/:id", async (req, res) => { const id = req.params.id; const sql = "SELECT * FROM missions WHERE id = ?"; connection.query(sql, [id], (err, result) => { if (err || result.length === 0) { console.log("没找到"); res.json(false); return; } res.json(result[0]); }); });
算法
算法这里就主要做三件事情:
- 获取任务
- 模型推理
- 更新任务结果
具体代码实现如下:
import time from modelscope.pipelines import pipeline from modelscope.utils.constant import Tasks from modelscope.outputs import OutputKeys import requests # 模型推理 def process_image_and_update_result(image_url,image_id): img_captioning = pipeline(Tasks.image_captioning, model='damo/ofa_image-caption_muge_base_zh', model_revision='v1.0.1') result = img_captioning(image_url) caption = result[OutputKeys.CAPTION] update_result_function(caption,image_id) # 更新任务结果 def update_result_function(caption, image_id): try: url = "http://your-ip:3000/aigc/updateMission" data = { "content": caption, "id": image_id } response = requests.post(url, json=data) if response.status_code == 200: print("结果更新成功") else: print(f"结果更新失败,状态码:{response.status_code}") except Exception as e: print(f"调用接口出错:{e}") # 获取任务 def get_image_url_function(): try: response = requests.get("http://your-ip:3000/aigc/getMission") if response.status_code == 200: data = response.json() print(data) if data == False: return None, None image_url = data.get("src") image_id = data.get("id") return image_url,image_id else: return None except Exception as e: print(f"接口请求出错:{e}") return None return None # 轮训获取 while True: image_url,image_id = get_image_url_function() if image_url: process_image_and_update_result(image_url,image_id) else: print("未获取到图片路径,1秒后重试...") time.sleep(1)
最后,来一起看一下整条链路运行的结果,整个调用的过程我就不录制 GIF 了,大概整个过程耗时 20S 左右。

最后
以上就是本文的全部内容,在如今这个 AIGC 爆火的时代,尝试一下各种模型还是挺有意思的。如果你觉得有意思的话,点点关注点点赞吧~