1. 现有架构
现有Flink写Hudi架构如下
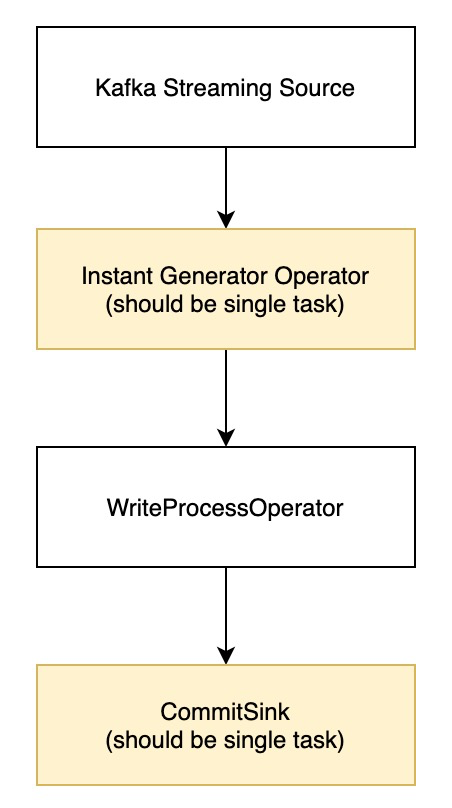
现有的架构存在如下瓶颈
•InstantGeneratorOperator并发度为1,将限制高吞吐的消费,因为所有的split都将会打到一个线程内,网络IO会有很大压力;•WriteProcessOperator算子根据分区处理输入数据,在单个分区处理,BUCKET逐一写入,磁盘IO也会有很大压力;•通过checkpoint缓存数据,但checkpoint应该比较轻量级并且不应该有一些IO操作;•FlinkHoodieIndex对per-job模式有效,不适用于其他Flink作业;
2. 改进方案
2.1 步骤1:移除并发度为1的算子
解决第一个瓶颈。
可以通过为写入算子实现一个算子协调器WriteOperatorCoordinator来避免使用并行度为1的算子InstantGeneratorOperator,协调器会基于checkpoint开始新的提交。

2.1.1 工作流
写方法首先会将数据缓存为一批HoodieRecord
当Flink checkpoint开始时,开始写一批数据,当一批数据写成功后,方法会通知StreamWriteOperaorCoordinator成功写入;
2.1.2 Exactly-once语义
通过缓存checkpoint之间的数据来实现exactly-once语义,算子协调器在触发checkpoint时会在Hoodie的timeline上创建一个新的instant,协调器总是会在其算子之前开始checkpoint,所以当方法开始checkpoint时,已经存在了REQUESTED HoodieInstant。
方法处理线程开始阻塞数据缓存,然后checkpoint线程开始刷出之前缓存的数据,当刷出成功后,线程不再阻塞并且开始为新一轮的checkpoint缓存数据。
因为checkpoint失败会触发写回滚,实现了exactly-once语义。
2.1.3 容错
算子协调器在生成新的instant时会检查上一个instant的合法性,如果写入失败会进行回滚处理,算子协调器在提交写入状态时会进行多次重试以减少提交状态的失败概率。
注意:需要按照分区字段对输入数据进行分区以避免不同的线程写入相同的FileGroup,一般场景下时间字段为分区字段,所以sink task非常可能会有IO瓶颈,更灵活的方式是根据FileGroupId进行数据shuffle(步骤2解决)。
2.2 步骤2:更灵活的写入线程
解决第二个瓶颈。
对于每一个分区,WriteProcessOperator处理所有的逻辑,包括index/bucket/数据写入:
•索引INSERT/UPDATE记录;•使用PARTITIONER确定每条记录的Bucket(FileID)•逐一写Bucket
第三步的单线程处理是瓶颈所在。为解决这个瓶颈,将WriteProcessOperator划分为FileIdAssigner和BucketWriter

2.2.1 FileIdAssigner
FileIdAssigner对每条记录处理如下
•BucketAssigner为每条记录创建一个分区写入Profile,其是分配BucketID(Partition Path+FileID)的关键;•查找索引以确定记录是否为UPDATE,如果记录是UPDATE,那么关联已有的fileID,如果是INSERT,根据配置的文件大小确定fileID;•向下游发送带有fileID的记录;
FileIdAssigner的输出记录可以通过fileID进一步shuffle到BucketWriter。
2.2.2 BucketWriter
BucketWriter的输入为HoodieRecord,然后逐一写Bucket;
第二步需要重构已有的Flink客户端(HoodieFlinkWriteClient),当前代码中HoodieFlinkWriteClient将处理步骤二中的所有的任务,这种模式适用于Spark,但对Flink不太合适,对于Flink而言,需要做一些重构(移除index/bucket)以便让client更轻量级,专注于数据写入。
2.3 步骤3:Mini-batch模式写
解决第三个瓶颈。
•在BucketWriterCoordinator开始时会开始一个新的instant(不同于步骤1和步骤2中从新的checkpoint开始)•新的checkpoint开始时,BucketWriter会阻塞并且刷出缓存数据,有异步线程消费缓存数据(在第一个版本中是在#processElement方法中刷出数据)并刷出。•对于BucketWriteCoordinator,如果checkpoint的数据写入成功(获取一个checkpoint成功通知),检查并提交INFLIGHT状态的instant,同时还是新的instant。

2.3.1 Exactly-once语义
为提高吞吐,当checkpoint线程开始刷出缓存数据时,处理线程不再阻塞数据的缓存。当checkpoint失败触发回滚操作时,会有一些重复的数据,但是在UPSERT操作下语义依然正确。
当支持一条条记录写入而非一批记录时,可以支持Exactly-Once语义。
2.3.2 容错
在进行checkpoint时,不再阻塞数据缓存,因此很可能有一个mini-batch缓存刷出,当checkpoint失败时,会重新消费之前的缓存数据,会重复写入该缓存数据。
当checkpoint完成时,协调器检查并提交上一次instant,同时开始新的instant。当发生错误时,将会回滚写入的数据,这意味着一个Hoodie Instant可能会跨不同的checkpoint。如果一个checkpoint超时,那么下一次checkpoint将会刷出剩余的缓存数据。
2.4 步骤四:新的索引
解决第四个瓶颈。
新的索引基于BloomFilter索引,其步骤如下
•从state中查找一条记录是否为UPDATE,如果为INSERT,不做任何处理;•如果记录是UPDATE,使用BloomFilter索引查找候选文件,查找这些文件并且将所有的index信息放入状态;
当所有文件都被加载后,则可标识为纯状态模式,后面可以仅仅只查询状态即可。

新的索引可适用于不同的Flink作业写入;
3. 兼容性
算子协调器在Flink 1.11引入,为兼容低于1.11版本,需要添加一个不使用算子协调器的pipeline
input operator => the instant generator => fileID assigner => bucket writer => commit sink
其中使用了instant generator替换协调器。
注意该pipeline无法使用mini-batch模式,因为没有组件协调mini-batch,也无法控制算子checkpoint的通知顺序,所以无法在checkpoint完成后开始新的instant。



