问题一:我尝试使用魔塔社区的方法训练rwkv模型,但是报错:object 没有'model属性'
我使用的是本地的模型,是在导入模型的时候报错, 具体的报错是:AttributeError: 'ConfigDict' object has no attribute 'model'
以下是代码和configuration文件的代码:
from modelscope.models import Model from modelscope.trainers import build_trainer from modelscope.msdatasets import MsDataset from modelscope.utils.hub import read_config from modelscope.pipelines import pipeline # 导入数据集 my_json = './data/osa.json' ds = MsDataset.load('json',data_files=[my_json]) print(next(iter(ds))) #导入模型 model_id = Model.from_pretrained('./model') #p = pipeline('task-oriented-conversation', 'Blink_DL/rwkv-4-pile-1b5') config=read_config(model_id) print(config.pretty_text) #配置参数 def cfg_modify_fn(cfg): cfg.task='task-oriented-conversation' cfg.num_labels=2 cfg.train.max_epochs = 5 cfg.train.work_dir='./new' cfg.train.dataloader.batch_size_per_gpu = 32 cfg.evaluation.dataloader.batch_size_per_gpu = 32 cfg.train.optimizer.lr = 2e-5 cfg.train.lr_scheduler.total_iters = int(len(train_dataset) / cfg.train.dataloader.batch_size_per_gpu) * cfg.train.max_epochs return cfg #训练 kwargs=dict( model=model_id, train_dataset=ds, cfg_modify_fn=cfg_modify_fn ) trainer = build_trainer(default_args=kwargs) trainer.train()
{ "framework":"pytorch", "task":"task-oriented-conversation", "modle":{ "type":"rwkv-4-pile-1b5", "max_length":128 }, "train":{ "work_dir":"./new" } }
使用的模型名称是: RWKV-4-Pile-1B5-20220822-5809.pth
参考回答:
根据您提供的信息,如果在使用ModelScope训练rwkv模型时出现"object没有'model属性'"的错误,这可能是因为在您的代码中尝试访问一个对象的'model'属性,但该对象并没有定义此属性。
请确保您的代码正确设置了ModelScope相关的对象和属性,并且按照正确的顺序进行调用。以下是一个示例,展示如何使用ModelScope训练rwkv模型:
import modelscope_sdk # 设置API密钥 modelscope_sdk.set_api_key("YOUR_API_KEY") # 创建ModelScope实例 ms = modelscope_sdk.ModelScope() # 加载rwkv模型 model = ms.get_model("rwkv", "latest") # 训练模型 training_data = ... labels = ... model.train(training_data, labels) # 保存模型 model.save("my_trained_rwkv_model")
请注意,上述示例仅展示了一个基本的训练过程,并假设您已经准备好了训练数据和标签。在您的实际代码中,请确保正确处理各种参数、数据加载和预处理等步骤。
如果问题仍然存在,建议检查您的代码中是否有其他地方可能导致该错误的原因。另外,请参考ModelScope SDK的文档和示例代码,以确保正确使用ModelScope的功能和属性。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/526290?spm=a2c6h.14164896.0.0.292a508eFf9XKU
问题二:我用本地ModelScope模型再进行训练的时候报错了。用model_id仓库的模型训练成功的本地?
我用本地ModelScope模型再进行训练的时候报错了。。用model_id仓库的模型训练成功的本地模型再训练 提示num_labels不匹配  是读取本地模型不对吗? 是读取路径 还是读取bin文件。Response details: {'Code': 10010205001, 'Message': '获取模型信息失败,信息:record not found', 'RequestId': 'd50bd4e6-7ca6-4d6f-a169-aa6d1f9d2460', 'Success': False}
是读取本地模型不对吗? 是读取路径 还是读取bin文件。Response details: {'Code': 10010205001, 'Message': '获取模型信息失败,信息:record not found', 'RequestId': 'd50bd4e6-7ca6-4d6f-a169-aa6d1f9d2460', 'Success': False}
参考回答:
您遇到报错的原因应该是第一次训练和第二次训练数据使用的 labels 不完全一致,而第一次训练的 id2label,label2id,labels 在训练结束时保存到 configuration.json 中了。解决方法是删除 output/configuration.json 文件中的 model.id2label,model.label2id,model.num_labels,preprocessor.label2id,dataset.train.labels 等相关字段,或是使用 labels 相同的数据集进行继续训练
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/516765?spm=a2c6h.14164896.0.0.292a508eFf9XKU
问题三:使用SambertHifigan个性化语音合成-中文-预训练-16k报错,完全按照模型介绍中的操作
报错信息如下: 2023-06-08:11:43:32 INFO [se_processor.py:50] [SpeakerEmbeddingProcessor] try load it as se.model Traceback (most recent call last): File "/home/ducheng/anaconda3/envs/modelscope-sambert-py37/lib/python3.7/site-packages/kantts/preprocess/se_processor/se_processor.py", line 41, in process '[SpeakerEmbeddingProcessor] se model loading error!!!') Exception: [SpeakerEmbeddingProcessor] se model loading error!!!
During handling of the above exception, another exception occurred:
Traceback (most recent call last): File "PTTS-basemodel.py", line 33, in trainer.train() File "/home/ducheng/anaconda3/envs/modelscope-sambert-py37/lib/python3.7/site-packages/modelscope/trainers/audio/tts_trainer.py", line 229, in train self.prepare_data() File "/home/ducheng/anaconda3/envs/modelscope-sambert-py37/lib/python3.7/site-packages/modelscope/trainers/audio/tts_trainer.py", line 208, in prepare_data se_model) File "/home/ducheng/anaconda3/envs/modelscope-sambert-py37/lib/python3.7/site-packages/modelscope/preprocessors/tts.py", line 37, in call speaker_name, target_lang, skip_script, se_model) File "/home/ducheng/anaconda3/envs/modelscope-sambert-py37/lib/python3.7/site-packages/modelscope/preprocessors/tts.py", line 57, in do_data_process targetLang, skip_script, se_model) File "/home/ducheng/anaconda3/envs/modelscope-sambert-py37/lib/python3.7/site-packages/kantts/preprocess/data_process.py", line 205, in process_data se_model, File "/home/ducheng/anaconda3/envs/modelscope-sambert-py37/lib/python3.7/site-packages/kantts/preprocess/se_processor/se_processor.py", line 52, in process map_location=device)) File "/home/ducheng/anaconda3/envs/modelscope-sambert-py37/lib/python3.7/site-packages/torch/serialization.py", line 795, in load return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args) File "/home/ducheng/anaconda3/envs/modelscope-sambert-py37/lib/python3.7/site-packages/torch/serialization.py", line 1002, in _legacy_load magic_number = pickle_module.load(f, **pickle_load_args) _pickle.UnpicklingError: invalid load key, '\x08'.
参考回答:
[SpeakerEmbeddingProcessor] se model loading error!!!”,这表明在加载说话者嵌入模型时出现了错误。
建议您检查一下您的模型文件路径是否正确,并确保您已经下载了正确的模型文件。您可以尝试使用以下代码加载说话者嵌入模型:
python
Copy
from kantts.preprocess.se_processor.se_processor import SpeakerEmbeddingProcessor
se_processor = SpeakerEmbeddingProcessor(model_path="path/to/se/model")
在这个示例中,我们使用 SpeakerEmbeddingProcessor 类加载说话者嵌入模型,并将模型文件路径传递给 model_path 参数。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/519057?spm=a2c6h.14164896.0.0.292a508eFf9XKU
问题四:请问按照ModelScope文档部署到阿里云EAS 调用模型报错 不知道是哪一层的问题?
问题1:请问按照ModelScope文档部署 damo/mplug_image-captioning_coco_base_zh到阿里云EAS 调用模型报错 400 OSError(36, 'File name too long') 不知道是哪一层的问题? 问题2:这个日志是EAS上服务日志截取的 是请求返回了400 应该是服务端读入报错的 
参考回答:
回答1:这个看起来已经返回了图片内容,data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAA7QAAAIVCA,前面data:image/png;base64,去掉,后面的内容写到一个文件,应该就是输出图片 回答2:这个问题是由于这个task类型的输入输出数据没做好适配,我刚刚临时修改了一版,麻烦您把服务配置里的image改成这个: registry-vpc.cn-beijing.aliyuncs.com/modelscope-repo/modelscope:model_deploy-1.3.0_image_captioning
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/512649?spm=a2c6h.14164896.0.0.6338508ePQwQ9m
问题五:ModelScope不联网的的状态下,按这种方式加载的模型,但是还是报错。是啥原因?
ModelScope不联网的的状态下,按这种方式加载的模型,但是还是报错。是啥原因?
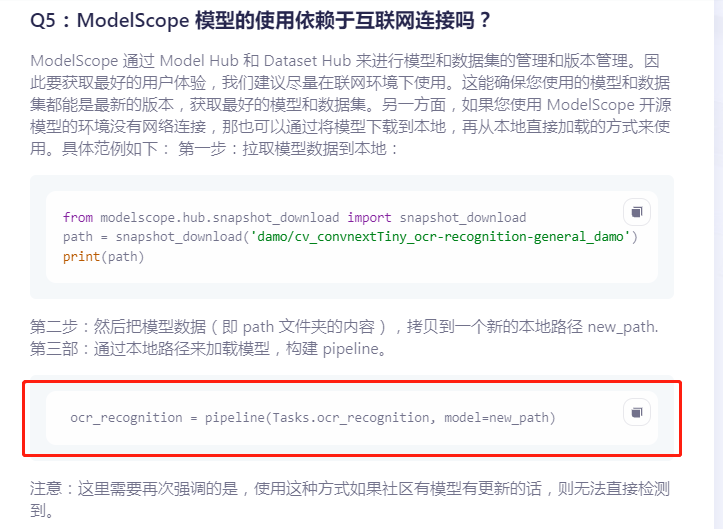
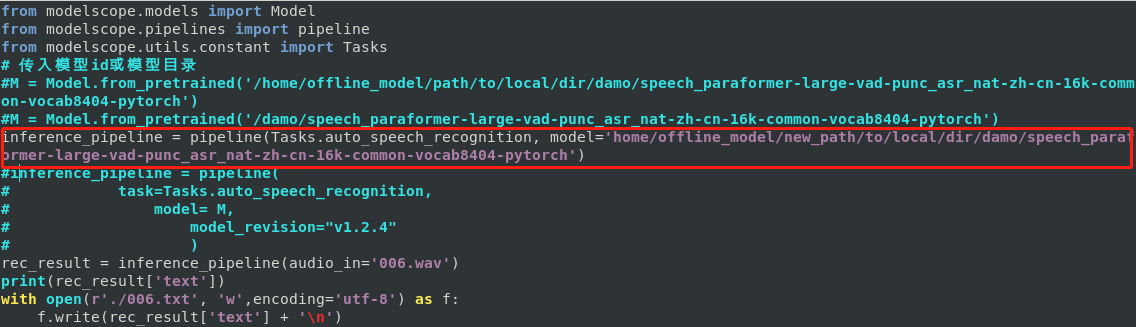
请问 必须联网,才能加载模型吗?
参考回答:
单个独立的模型应该是不需要联网的。如果是复合模型(一个模型pipeline调用了另外一个模型),那有可能本地加载支持的就不是那么完整了。麻烦ls下对应的目录,看下目录的内容
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/522077?spm=a2c6h.14164896.0.0.6338508ePQwQ9m

