之前笔者参加了公司内部举办的一个 Big Data Workshop,接触了一些 Spark 的皮毛,后来在工作中陆陆续续又学习了一些 Spark 的实战知识。
本文笔者从小白的视角出发,给大家普及 Spark 的应用知识。
什么是 Spark
Spark 集群是基于 Apache Spark 的分布式计算环境,用于处理大规模数据集的计算任务。Apache Spark 是一个开源的、快速而通用的集群计算系统,提供了高级的数据处理接口,包括 Spark SQL、Spark Streaming、MLlib(机器学习库)和GraphX(图计算库)。Spark 的一个主要特点是能够在内存中进行数据处理,从而大大加速计算速度。
Scala 编程语言是 Spark 的首选编程语言之一。Spark 最初是用 Scala 编写的,而且 Scala 具有强大的静态类型系统和函数式编程特性,使其成为 Spark 的理想选择。Spark 支持多种编程语言,包括 Java、Python 和 R,但 Scala 在 Spark 社区中仍然占据重要地位。
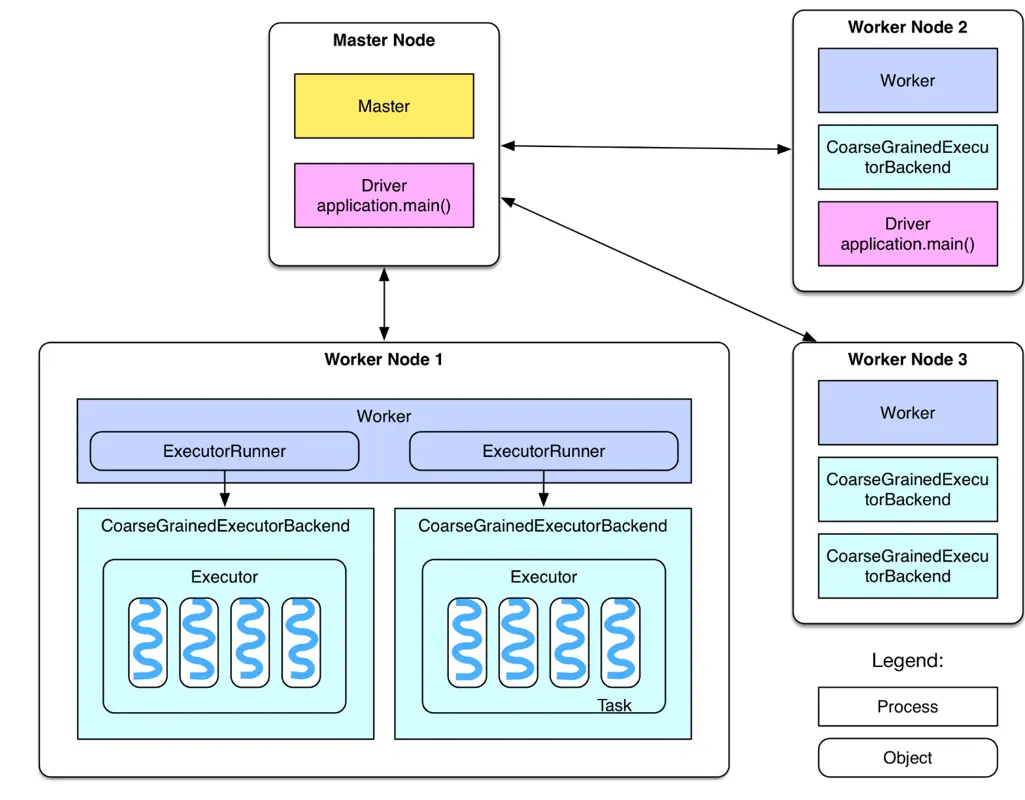
什么是 RDD?它在 Spark 架构中扮演着怎样的角色?
提到 Spark 就不能不提到 RDD.
Spark 架构中的RDD(Resilient Distributed Dataset,弹性分布式数据集)是一种基本的数据结构,它在 Spark 分布式计算中扮演着关键的角色。RDD 是 Spark 的核心抽象,它提供了一种容错的、可并行处理的数据结构,用于在集群中存储和操作数据。
RDD 将数据划分为多个分区,这些分区可以并行地在集群中进行处理。RDD 提供了一种高度抽象的数据处理接口,使得开发者可以方便地执行并行计算任务。

RDD 顾名思义,具有下面这些特性:
- 弹性(Resilient):RDD 具有容错性,即使在节点故障时也能够自动从先前的转换中恢复。这通过 RDD 的依赖信息和转换操作日志实现,使得 Spark 能够在节点失败时重新计算丢失的数据。
- 分布式(Distributed):RDD 将数据划分为多个分区,并在集群中分布存储这些分区。这样,计算可以在分布式环境中并行执行,提高了处理速度。
- 不可变(Immutable):RDD 是不可变的数据结构,一旦创建就不能被修改。这确保了数据的一致性,并简化了并行计算的实现。
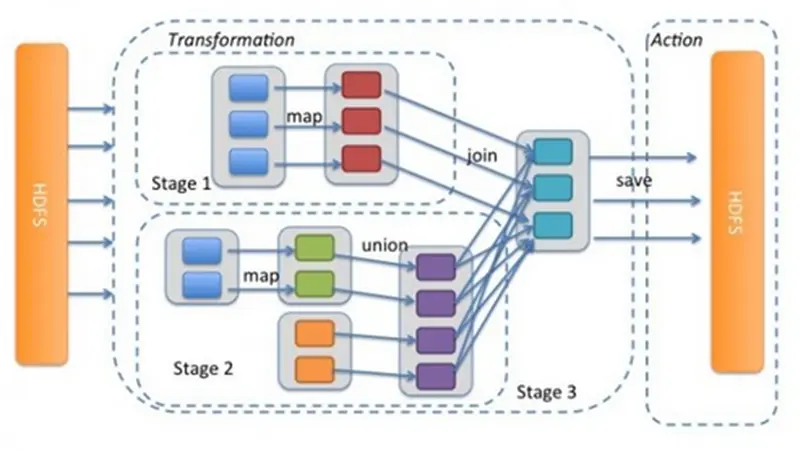
RDD 实战(一):平方和的计算
我们通过一个计算整数集合平方和的简单例子,来学习 RDD 的实战。
首先,我们创建一个RDD:
`data = [1, 2, 3, 4, 5]` `rdd = sparkContext.parallelize(data)`
接下来,我们可以使用转换操作对 RDD 执行平方操作:
`squared_rdd = rdd.map(lambda x: x ** 2)`
现在,我们得到了一个新的 RDD squared_rdd,它包含了原始 RDD 中每个元素的平方。最后,我们可以使用行动操作计算平方和:
`result = squared_rdd.reduce(lambda x, y: x + y)`
在这个例子中,RDD 允许我们以并行的方式对数据执行转换和计算操作,而不需要显式的循环或迭代。同时,RDD 的容错性确保了在计算过程中节点失败时的可靠性。
RDD 实战(二):统计 text 文件中每个单词的出现次数
有了前面的基础,我们再来完成一个稍微复杂一些的大数据分析任务。
我用 Java 编写了一个应用程序,这个 Java 应用接收一个输入参数,该参数代表一个 text 文件的绝对路径,这个 text 文件的内容是一本英文小说。
这个 Java 应用,可以使用 Spark RDD 的 API,来高效统计 text 文件里,每个单词的出现频次。
完整的可运行的 Java 代码如下:
package org.apache.spark.examples; import scala.Tuple2; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import java.util.Arrays; import java.util.List; import java.util.regex.Pattern; // Maven source public final class JavaWordCount { private static final Pattern SPACE = Pattern.compile(" "); @SuppressWarnings({ "resource", "serial" }) public static void main(String[] args) throws Exception { if (args.length < 1) { System.err.println("Usage: JavaWordCount <file>"); System.exit(1); } SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount"); JavaSparkContext ctx = new JavaSparkContext(sparkConf); JavaRDD<String> lines = ctx.textFile(args[0], 1); JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { @Override public Iterable<String> call(String s) { return Arrays.asList(SPACE.split(s)); } }); JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String s) { return new Tuple2<String, Integer>(s, 1); } }); JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer i1, Integer i2) { return i1 + i2; } }); List<Tuple2<String, Integer>> output = counts.collect(); for (Tuple2<?, ?> tuple : output) { System.out.println(tuple._1() + ": " + tuple._2()); } ctx.stop(); } }
package org.apache.spark.examples; import scala.Tuple2; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import java.util.Arrays; import java.util.List; import java.util.regex.Pattern; // Maven source public final class JavaWordCount { private static final Pattern SPACE = Pattern.compile(" "); @SuppressWarnings({ "resource", "serial" }) public static void main(String[] args) throws Exception { if (args.length < 1) { System.err.println("Usage: JavaWordCount <file>"); System.exit(1); } SparkConf sparkConf = new SparkConf().setAppName(`JavaWordCount`); JavaSparkContext ctx = new JavaSparkContext(sparkConf); JavaRDD<String> lines = ctx.textFile(args[0], 1); JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { @Override public Iterable<String> call(String s) { return Arrays.asList(SPACE.split(s)); } }); JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String s) { return new Tuple2<String, Integer>(s, 1); } }); JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer i1, Integer i2) { return i1 + i2; } }); List<Tuple2<String, Integer>> output = counts.collect(); for (Tuple2<?, ?> tuple : output) { System.out.println(tuple._1() + `: ` + tuple._2()); } ctx.stop(); } }
这段 Java 程序从 Apache Spark 中导入 RDD API:org.apache.spark.api.java.JavaRDD, 然后进行下面的逻辑:
- 定义一个正则表达式模式 SPACE,用于按空格分隔单词。
- 创建一个JavaSparkContext对象 ctx,它是Spark的入口点,用于连接到集群。
- 通过命令行参数获取输入文件路径,如果参数数量小于1,则打印用法说明并退出程序。
- 创建一个SparkConf对象 sparkConf,设置应用程序名称为 “JavaWordCount”。
- 使用 ctx.textFile 读取输入文件,将每一行作为一个元素组成的RDD(Resilient Distributed Dataset)。
- 使用 flatMap 操作将每行文本拆分为单词,并生成一个包含所有单词的新RDD words。
- 使用 mapToPair 操作将每个单词映射为键值对(单词, 1),生成新的Pair RDD ones。
- 使用 reduceByKey 操作对相同键的值进行累加,得到最终的单词计数结果,生成新的Pair RDD counts。
- 使用 collect 操作将结果收集到Driver程序中,得到一个包含单词和计数的列表 output。
- 遍历输出列表,将结果打印到控制台。
- 停止SparkContext,释放资源。
将这个 Java 程序编译成 .class 文件后,使用下面的命令行,将该 class 文件包含的 RDD 计算逻辑,以 Job 的形式,提交到 spark 集群上:
./spark-submit --class "org.apache.spark.examples.JavawordCount" --master spark://NKGV50849583FV1:7077 /root/devExpert/spark-1.4.l 1/bin/test.txt

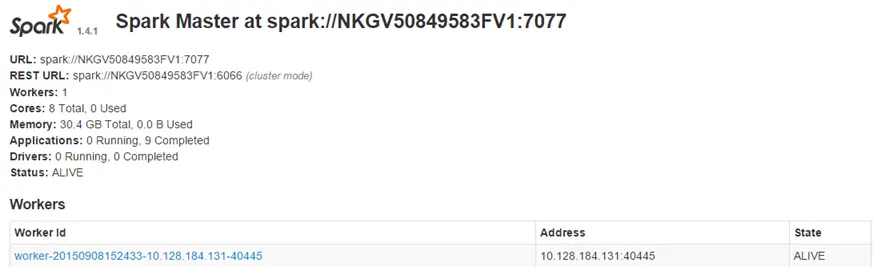
命令行里的 spark://NKGV50849583FV1:7077 是我在一台 Linux 服务器上安装的 Spark 集群,如下图所示:
至此,我们完成了通过 Spark RDD 进行大数据处理分析的一个实际需求。
