
模型介绍
模型地址:
https://modelscope.cn/models/OrionStarAI/OrionStar-Yi-34B-Chat
在线体验:
https://modelscope.cn/studios/OrionStarAI/OrionStar-Yi-34B-Chat/summary
11 月 20 日,由被称为「大模型应用开发创业者」傅盛创立的,全球领先的人工智能服务型解决方案提供商猎户星空公司,推出了一款基于零一万物开源的Yi-34B模型微调后的chat模型——OrionStar-Yi-34B-Chat。
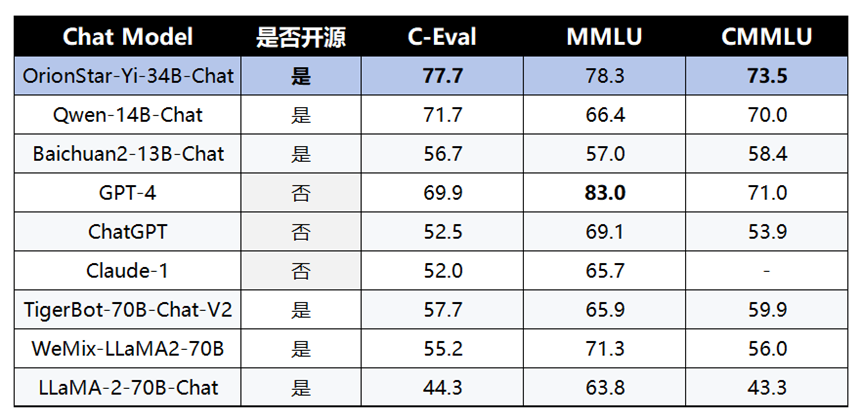
为了验证模型的各项能力,OrionStar-Yi-34B-Chat一经推出,在C-Eval和C-MMLU两个最具影响力的中文指标评估中,就以显著优势领先于Qwen-14B-Chat、Baichuan2-13B-Chat等国产大模型。
GPT-4固然能力强大,但闭源会要求企业访问公网以及难以定制化适配,使用场景受限。而开源能够使企业及超级个体轻松地借助专有数据进行微调和私有化部署,进而促进百行千业的良性发展生态。OrionStar-Yi-34B-Chat中英文大模型集高性能、完全开源、免费可商用等诸多优势于一身,可谓是ChatGPT最佳开源替代品之一。
OrionStar-Yi-34B-Chat多个评估基准表现最佳
作为国产优质大模型,OrionStar-Yi-34B-Chat更“懂”中文。为了验证模型的各项能力,OrionStar-Yi-34B-Chat在最具影响力的中文评估基准 C-Eval进行了综合评估,综合评分达到了77.7分,超过了同为国产大模型的 Qwen-14B-Chat、Baichuan2-13B-Chat,凸显中文世界的优异能力,可以更好的满足国内市场需求。
从更为全面的评估看,OrionStar-Yi-34B-Chat不仅在中文方面表现优异,在英文上表现同样亮眼。在全球大模型各项评测中最关键的 MMLU 英文权威评测榜单上,OrionStar-Yi-34B-Chat综合评分高达78.3,仅略逊色于 ChatGPT4 ,而比LLaMA-2-70B-Chat等某些参数规模更大的模型还要出色。
备注:
C-Eval 评测基准由上海交通大学、清华大学以及爱丁堡大学联合创建,是面向中文语言模型的综合考试评测集,覆盖了 52 个来自不同行业领域的学科。
MMLU 由加州大学伯克利分校等知名高校共同打造,集合了科学、工程、数学、人文、社会科学等领域的 57 个科目,主要目标是对模型的英文跨学科专业能力进行深入测试。其内容广泛,从初级水平一直涵盖到高级专业水平。
CMMLU是针对中国的语言和文化背景设计的评测集,用来评估LLM的知识蕴含和推理能力。该评测集跨多个学科,由67个主题组成。其中大多数任务的答案都是专门针对中国的文化背景设计,不适用于其它国家的语言。
更多细节维度的测评会持续更新在官方技术交流群。
为什么OrionStar-Yi-34B-Chat有如此亮眼的成绩呢?
1、Base模型基础好:作为大模型应用开发商,在Base大模型的选择上,猎户星空要对应用的质量负责,因此,对市面上广泛的开源模型做了测评,发现零一万物开源的Yi-34B模型表现确实优异。【聚言】是猎户星空自研的AI原生应用,我们用【聚言】进行实际的效果验证,Yi-34B模型在基于文本的理解能力、交互准确率及逻辑推理能力的效果最强。
2、15W+高质量中英文微调语料:我们知道微调数据是大模型训练的重要“燃料”,高质量、多样性的微调数据对大语言模型的对齐效果至关重要。我们在微调数据上花了大量时间和精力,使用了多种构建方案和人工精标及筛选,这些数据质量高、通用性强、覆盖面广、具备真实交互语料基础,对大型语言模型整个生命周期都有重要的影响,有助于大模型更好地适配实际的应用场景,实现人工智能赋能千行百业的愿景。
OrionStar-Yi-34B-Chat具体实践和经验分享
具体实践
我们知道高质量、多样性的微调数据是提高模型性能的关键因素,开源数据集质量普遍不高,多样性也较低,高质量数据需要人工精标!我们参考LLaMA-2以及intructGPT 定义了高质量、多样性的数据:
高质量:有帮助(helpful)、真实性(truthfulness)和无害性(harmlessness)详细见llama2论文。
多样性:任务多样、指令多样、覆盖领域多样, 再细点比如:指令长度及语种覆盖的多样。
数据具体构建思路如下
首先,我们基于数万条种子数据参考SELF-INSTRUCT、WizardLM、Orca、Backtranslation等基于大模型的方案去自动化构建一批初始数据,接着这些数据经过一个专门的数据质量模型进行评分和筛选,最终仅保留高质量数据。
紧接着参考 Platypus论文上方法做了数据去重、去污,保证数据严谨、有效。最后经过严格的人工精标,这些数据被进一步精炼,确保其无害性、真实性和实用性,最终形成了15W+高质量的微调语料。在数据筛选过程中,我们特别强调数据的安全性,加入了大量与安全相关的数据,以保证模型与人类价值观的一致性。关于数据的详细构建过程在猎户星空即将发布的自研大模型的技术报告里会详细说明,可以持续关注!
在具体微调的实践中,我们同时进行了两种微调方法:LORA和全参数量更新的微调,实际效果上基本也是全参数微调效果好于LORA。我们用DeepSpeed框架在4卡80G A100上使用ZERO3+Offload 策略,对这15W+数据进行了3个epoch的训练,分别在主观和客观测试集以及我们聚言业务的测试集上进行评测,给出了OrionStar-Yi-34B-Chat模型。这一过程不仅展示了猎户星空在技术上的创新和专业性,也体现了我们对质量和安全的不懈追求。
经验分享
•数据构建上前期可以利用大模型去快速构建一批数据,把模型迭代起来,积累经验,后面逐步构建高质量数据。微调模型的通用能力就是按这个思路优化的,随着人工精标的数据加入,模型效果也有提升(目前还在不断持续加入精标数据)。
•充分利用大模型能力,比如数据质量筛选、评测。
•微调数据的比例尽量均衡, 如:中英比例, 各种任务比例,我们经验 比例不要太离谱就行。
•在微调模型评测上,Ceval、MMLU一些开源评测集仅当做参考,不要只依赖它去挑模型,增加一些主观评测集,比如uoi、vicuna、belle等,或者构建自己评测集,另外重点关注模型在实际业务上的效果。
•在具体场景或具体任务上做微调,上千条左右的精标数据就有不错的效果。
OrionStar-Yi-34B-Chat示例案例效果展示
OrionStar-Yi-34B-Chat在交互对话、语义理解、知识问答、摘要生成和信息提取等多个方面都展现出卓越的性能。OrionStar-Yi-34B-Chat在语义理解任务中表现出色,能够准确把握文本的核心含义,为后续处理提供了可靠的基础,在交互中保障了流畅而自然的对话体验。
在线体验地址:
https://modelscope.cn/studios/OrionStarAI/OrionStar-Yi-34B-Chat/summary
对话交互
https://live.csdn.net/v/345816
知识问答
https://live.csdn.net/v/345814
语义理解
https://live.csdn.net/v/345815
猎户星空企业介绍
猎户星空(ORION STAR)成立于 2016 年9月,由傅盛创建,全球领先的人工智能服务型解决方案提供商,致力于“让人们从重复的体力劳动和简单的脑力劳动中解放出来,去从事更有温度、更具创造性的工作”。
猎户星空在行业内率先提出“AI+软件+硬件+服务=机器人”公式,具备自研全链条AI技术、机器人操作系统应用开发、标准化硬件研发制造、云端大脑服务能力,核心的AI机器人产品有:AI语音交互机器人、AI营销配送机器人、AI新零售机器人等。截至2023年6月底,猎户星空AI机器人累计总出货量已超过50,000台,总服务人次超5亿。
凭借7年AI经验积累,猎户星空推出大模型深度应用【聚言】,并已陆续面向行业客户开放并获得成果。猎户星空将继续凭借“机器人+大模型”的业务矩阵,秉持“助力合作伙伴成功”的价值主张,推动AI赋能实体经济和场景的数智化发展。
「聚言」是猎户星空自研基于大模型技术的深度应用,助力企业成为AI时代效率王者。为企业提供定制化AI大模型服务解决方案,真正帮助企业实现运营效率的提升、产品竞争力的增加、生意的快速增长,实现企业经营效率领先同行目标。

猎户星空具备全链条大模型应用能力的核心优势,包括拥有从海量数据处理、大模型预训练、二次预训练、微调(Fine-tune)、Prompt Engineering 、Agent开发的全链条能力和经验积累;拥有完整的端到端模型训练能力,包括系统化的数据处理流程和数百张GPU的并行模型训练能力,现已在大政务、云服务、出海电商、快消等多个行业场景落地。
同时,猎户星空具备顶级AI原生团队,Meta(Facebook)总部NLP和推荐算法科学家团队负责人领衔,来自百度、字节、微软等优秀算法工程师联合,人工智能领域磨合8年以上的团队,自然语言链路技术服务于小米、华为、美的、喜马拉雅音箱和手机。
接下来,猎户星空还将快节奏开源发布更多的大模型,邀请企业和开发者积极投入,共同促进语言模型开源社区的繁荣发展,打造属于自己场景中的大模型,引领下一代前沿创新和商业模型,探索走向通用人工智能的先进能力!
联系方式
邮箱:ai@orionstar.com
欢迎加入猎户技术交流微信群,群内可以提供模型最新信息,是一个畅所欲言的技术答疑平台。


