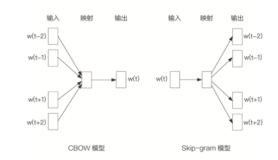
一、什么是BERT?
二、BERT安装
三、预训练模型
四、运行Fine-Tuning
五、数据读取源码阅读
(一) DataProcessor
(二) MrpcProcessor
六、分词源码阅读
(一)FullTokenizer
(二) WordpieceTokenizer
七、run_classifier.py的main函数
八、BertModel类
九、自己进行Pretraining
十、性能测试
(一)关于max_seq_len对速度的影响
(二)client_batch_size对速度的影响
(三)num_client 对并发性和速度的影响
————————————————
版权声明:本文为CSDN博主「废柴当自强」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jiaowoshouzi/article/details/89388794