时间序列数据处理
时间序列数据处理是数据科学和分析中的重要任务之一。Pandas 提供了丰富的功能来处理日期和时间数据、创建时间索引以及执行时间重采样。
- 创建时间序列数据:使用 Pandas 创建时间序列数据,通常需要包含日期时间列,并使用
pd.to_datetime()将日期时间字符串转换为 Pandas 的日期时间对象。 - 时间索引:将日期时间列设置为数据框的索引,以便根据时间访问、分析和操作数据。
- 访问时间索引数据:使用
.loc[]或切片语法来按年、月、日等级别访问数据,也可以使用属性(例如.year、.month、.day)来访问索引的年、月、日等属性。 - 时间索引的切片:使用切片操作来选择特定时间范围内的数据,包括起始日期和结束日期。
- 时间索引的重采样:使用
resample()方法将时间序列数据从一个频率转换为另一个频率,可以选择不同的频率,并应用不同的聚合函数(如mean()、sum()、max()、min()等)来计算新频率下的值。
1. 解析日期和时间数据
在 Pandas 中,你可以使用 pd.to_datetime() 函数将包含日期和时间的字符串解析为 Pandas 的日期时间对象。这允许你在数据中有效地处理日期和时间信息。
import pandas as pd # 示例数据包含日期时间字符串 data = {'date': ['2023-09-01 08:00:00', '2023-09-02 09:30:00', '2023-09-03 10:45:00'], 'value': [10, 15, 20]} # 创建 DataFrame df = pd.DataFrame(data) # 解析日期列为日期时间对象 df['date'] = pd.to_datetime(df['date']) # 查看结果 print(df)
输出结果:

2 创建时间索引
要在 Pandas 中创建时间索引,通常需要满足以下两个条件:
- 数据框中必须包含日期时间列。
- 使用
pd.to_datetime()将日期时间列转换为 Pandas 的日期时间对象。
以下是一个示例,演示如何创建一个带有时间索引的数据框:
import pandas as pd # 示例数据包含日期时间字符串 data = {'date': ['2023-09-01', '2023-09-02', '2023-09-03'], 'value': [10, 15, 20]} # 创建 DataFrame df = pd.DataFrame(data) # 解析日期列为日期时间对象 df['date'] = pd.to_datetime(df['date']) # 将日期列设置为索引 df.set_index('date', inplace=True) # 查看结果 print(df)
输出:

在上述示例中,我们首先将日期字符串解析为 Pandas 的日期时间对象,然后使用 set_index() 方法将日期时间列设置为索引。
3. 访问时间索引数据
一旦创建了时间索引,你可以使用索引来访问数据,例如按日期、按月、按年等。
3.1 按年、月、日等级别访问数据 (.loc[])
假设你有一个时间索引的数据框 df,你可以使用 .loc[] 来按照不同级别访问数据。
import pandas as pd import numpy as np # 创建一个示例时间序列数据 date_rng = pd.date_range(start='2023-01-01', end='2023-12-31', freq='D') data = {'value': np.random.randint(1, 100, len(date_rng))} df = pd.DataFrame(data, index=date_rng) # 访问特定年份的数据 print(df.loc['2023']) # 访问特定月份的数据 print(df.loc['2023-03']) # 访问特定日期的数据 print(df.loc['2023-06-15']) # 访问某个时间范围内的数据 print(df.loc['2023-04-01':'2023-04-15'])
上述示例演示了如何按年、月、日等级别使用 .loc[] 访问数据。
3.2 使用部分日期作为索引 (.loc[ ], .loc[ : ])
如果你只关心时间索引的一部分,你可以使用部分日期来选择数据。
# 选择 2023 年 4 月的数据 print(df.loc['2023-04']) # 选择 2023 年 5 月到 2023 年 8 月的数据 print(df.loc['2023-05':'2023-08'])
3.3 使用时间索引的属性 ( .index )
Pandas 还提供了 .index 属性,允许你访问时间索引的年、月、日等属性。
# 访问索引的年份 print(df.index.year) # 访问索引的月份 print(df.index.month) # 访问索引的日期 print(df.index.day)
输出如下:
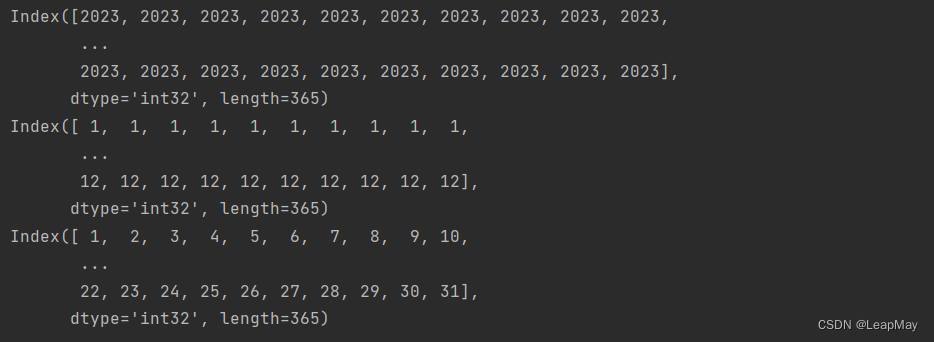
这些示例演示了如何按照不同的时间级别访问时间索引数据。时间索引的灵活性使你能够根据具体的需求轻松地选择和分析时间序列数据。
4 时间索引的切片
时间索引的切片是一种非常有用的操作,它允许你选择时间序列数据中的特定时间范围。你可以使用 Pandas 中的 .loc[] 或直接使用时间索引的切片语法来执行时间索引的切片操作。以下是时间索引的切片示例:
import pandas as pd import numpy as np # 创建一个示例时间序列数据 date_rng = pd.date_range(start='2023-01-01', end='2023-12-31', freq='D') data = {'value': np.random.randint(1, 100, len(date_rng))} df = pd.DataFrame(data, index=date_rng) # 使用 .loc[] 进行时间索引的切片 # 选择 2023 年 2 月到 2023 年 5 月的数据 subset1 = df.loc['2023-02-01':'2023-05-31'] # 选择 2023 年 8 月到 2023 年 10 月的数据 subset2 = df.loc['2023-08-01':'2023-10-31'] # 使用切片语法进行时间索引的切片 # 选择 2023 年 3 月到 2023 年 7 月的数据 subset3 = df['2023-03-01':'2023-07-31'] # 选择 2023 年 11 月到 2023 年 12 月的数据 subset4 = df['2023-11-01':] # 查看结果 print(subset1,"subset1") print(subset2,"subset2") print(subset3,"subset3") print(subset4,"subset4")
在上述示例中,我们演示了两种不同的时间索引切片方法:一种使用 .loc[] 方法,另一种使用切片语法。无论使用哪种方法,都可以方便地选择特定的时间范围,以便进一步分析或可视化时间序列数据。
请注意,时间索引的切片是包含起始日期和结束日期的。如果你想选择特定月份或年份的数据,也可以使用相应的索引,如 df['2023-02'] 或 df['2023']。
5 时间索引的重采样
时间索引的重采样是一种将时间序列数据从一个频率转换为另一个频率的操作,例如将每小时数据转换为每天数据。
Pandas 提供了 resample() 方法来执行时间索引的重采样操作。以下是时间索引的重采样示例:
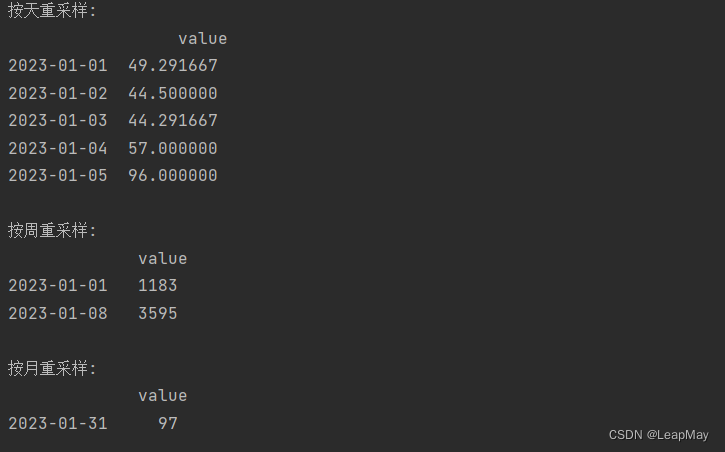
import pandas as pd import numpy as np # 创建一个示例时间序列数据,每小时一个数据点 date_rng = pd.date_range(start='2023-01-01', end='2023-01-05', freq='H') data = {'value': np.random.randint(1, 100, len(date_rng))} df = pd.DataFrame(data, index=date_rng) # 按天重采样并计算每天的平均值 daily_mean = df.resample('D').mean() # 按周重采样并计算每周的总和 weekly_sum = df.resample('W').sum() # 按月重采样并计算每月的最大值 monthly_max = df.resample('M').max() # 查看重采样结果 print("按天重采样:\n", daily_mean) print("\n按周重采样:\n", weekly_sum) print("\n按月重采样:\n", monthly_max)
输出如下: