脑子不好使啊!复习过的东西过几天就忘记了!
参考教程:
论文地址:[pdf]End-to-End Object Detection with Transformer
源码地址:https://github.com/facebookresearch/detr
概述
在之前的章节中我们介绍过transformer的原理和transformer在图像分类任务的代表作,DETR作为在目标检测领域使用Transformer的开山之作,给出了一个高效的端到端的目标检测框架。
使用DETR时,可以省去繁琐的非极大值抑制和 生成anchor的步骤,它直接输出的就是目标框的预测结果。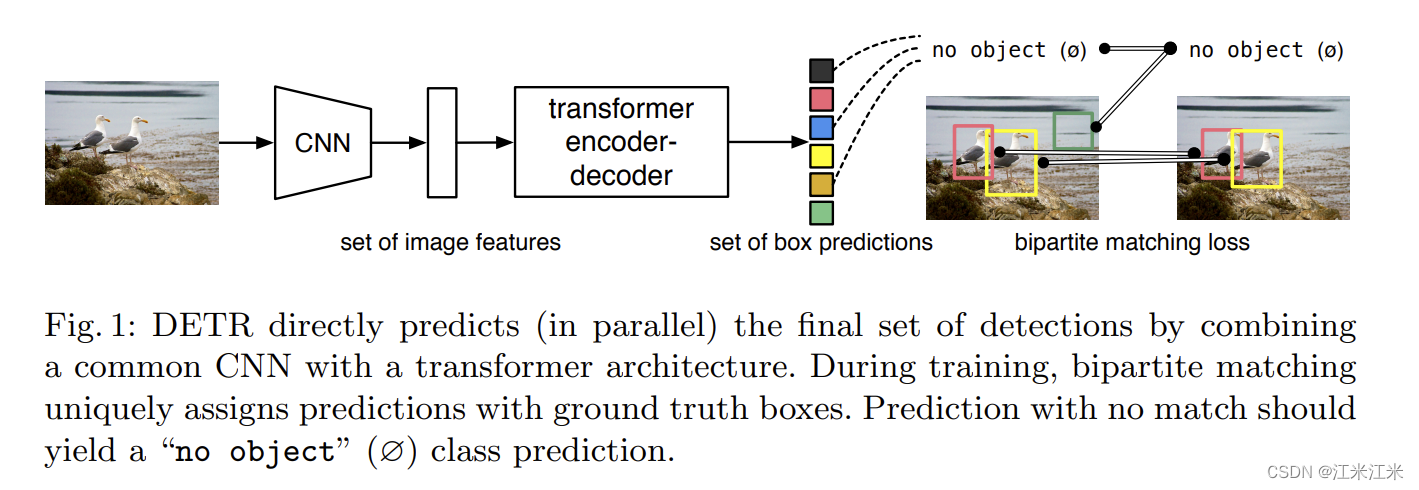
DETR把目标检测变成了一个集合预测问题。它采用基于transformer的encoder-decoder结构。transformer中的自注意力机制可以把元素之间的交互建模成一个序列的形式,这种结构很适合做集合预测,而DETR就可以看作起到了把一个图像序列转换成集合序列的作用。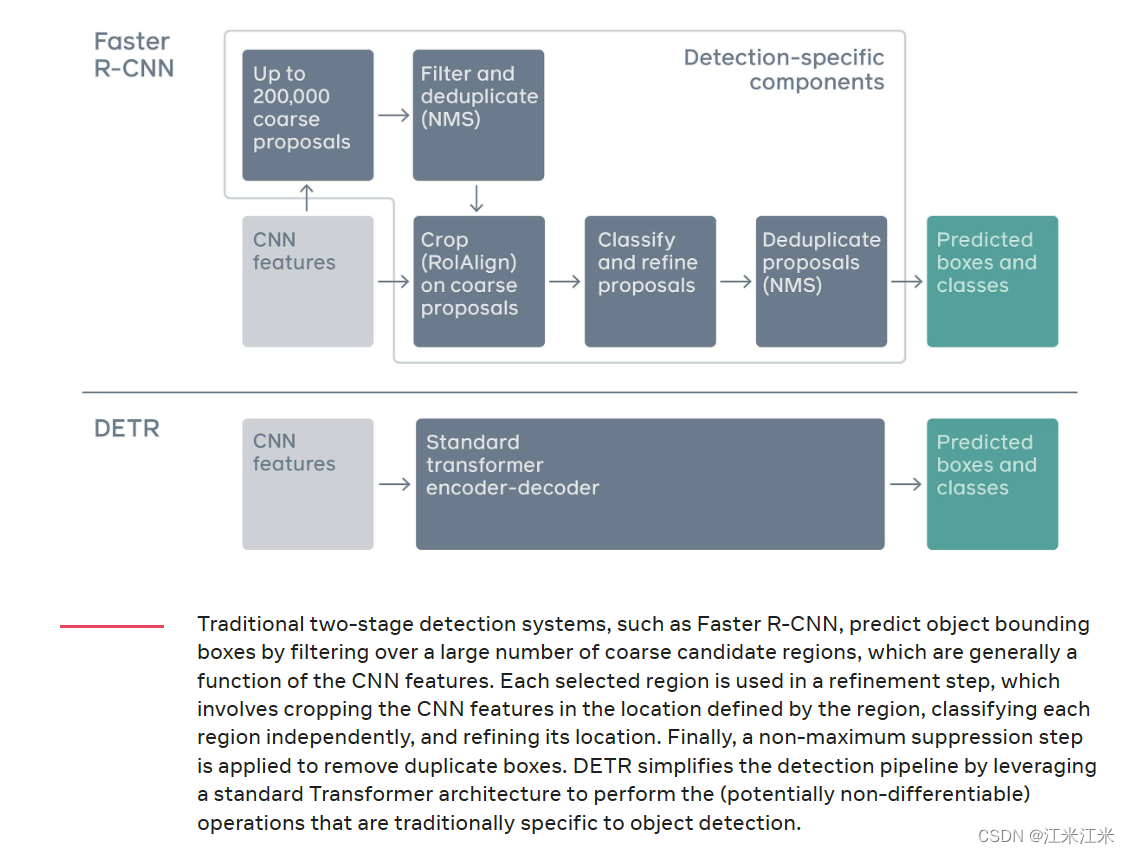
在上图中可以看到,和传统的two-stage目标检测模型相比,DETR的流程有多简单,只需要一个encoder-decoder就可以直接得到预测框和类别。而一个two-stage的模型则要先选出proposal-》过滤-》分类和修正-》再过滤才能得到最终的结果。
DETR的优势不只在于高效便捷,它的目标检测的performance也相当不错,在大物体检测的效果上比faster r-cnn更胜一筹。
the DETR model
集合预测有两个核心的组成:1. 一个集合预测的损失函数,用来完成预测结果和ground truth的匹配;2. 一个能够得到一个目标检测结果的集合的模型结构。
我们先来看一下这个结构。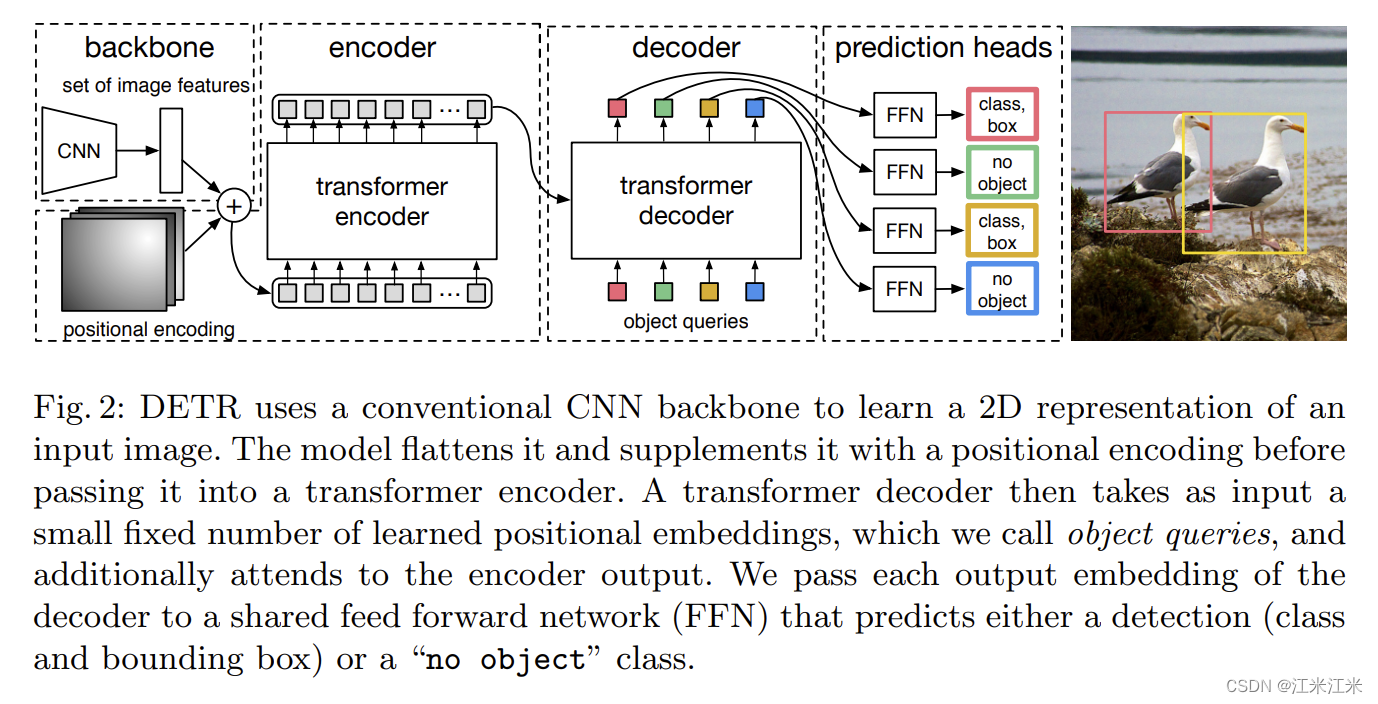
DETR architecture
上图给出了比较简洁明了的DETR的模型结构,它由三个主要部分构成。
- CNN backbone: 得到一系列的图像的特征,作为transformer部分的输入。
- Encoder-Decoder transformer:
- Encoder: Encoder部分以图像特征作为输入,并加入了位置编码。
- Decoder: Decoder部分引入了名为object queries的输入,它与我们最终的目标检测结果有关。
- FFN: feed forward network部分用于进行class和bounding box的预测。
CNN backbone
对CNN backbone没有明确的要求,常用的那些backbone都可以在这里使用。对于一个输入$x_{img} \in R^{3\times H_0\times W_0}$,希望在经过backbone后,得到的输出$f\in R^{C\times H\times W}$,我们希望$C=2048,H,W=\frac{H_0}{32},\frac{W_0}{32}$。
Transformer encoder
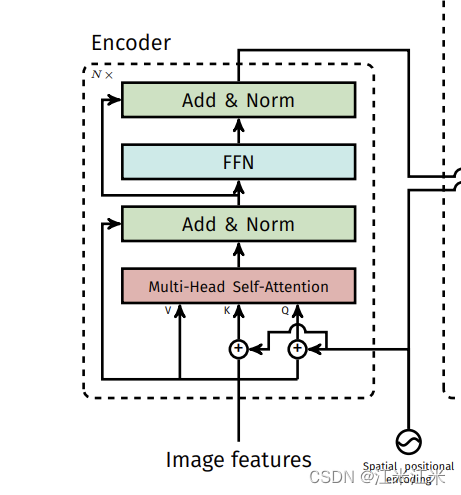
在不考虑batch的情况下,我们的图像是一个三维的输入,但是transformer要求我们的输入是二维的N*D,N代表序列的个数,D代表序列的维度。
所以我们CNN backbone的输出,在进入transformer前要先经过转换,从$f\in R^{C\times H\times W}$变成$f\in R^{d\times H W}$。d是使用1*1卷积降维后得到的新维度。
因为transformer的特征之间没有空间位置信息,所以这里还需要增加一个position embedding。在DETR中position embedding不是直接加载image的patch embedding上的(在DETR中就是我们backbone得到的feature,这里我叫他patch embedding是为了好理解),从图中可以看出,这个position embedding是加在了每个encoder block的Q和K上。
Transformer decoder
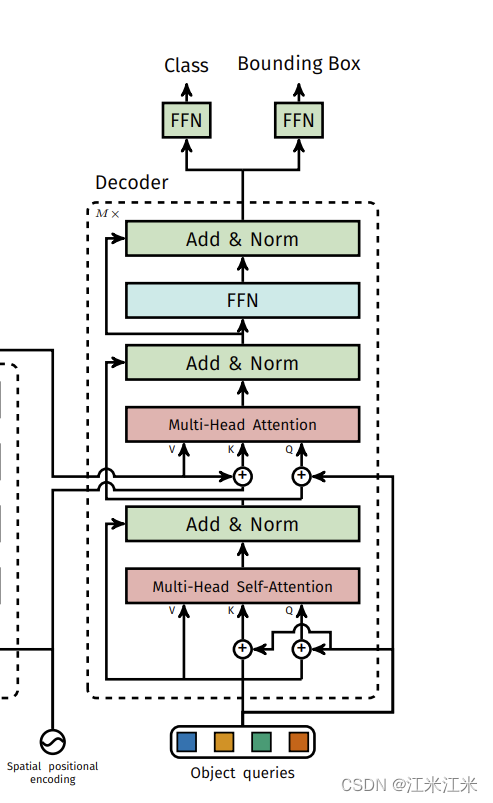
在decoder的部分,也遵循了标准的transformer中的decoder结构。输入同样是二维的N*D。在decoder中,不仅使用self-attention,还有encoder-decoder attention,即使用来自encoder的V、K和来自decoder的Q进行attention。
这里的N也代表了预测结果的个数。N是多少就代表你每个图片会预测多少个框。
decoder的输入又被称为object query,希望这个object query能体现出位置信息,所以它其实也是一个position embedding。同样地,它也被加到self-attention的Q和K上。而在encoder-decoder attention的部分,decoder的position embedding也被加到了来自decoder的Q上,来自encoder的K则加上来了encoder的position embedding。
FFN
FFN的预测结果包括box的中心坐标、宽和高,线性层也会完成物体类别的预测。
因为预测结果的N通常是比图片中实际的框的数量要多的,所以在这里使用了一个额外的class label表示没有物体 “no object”。
DETR loss
因为decoder的部分输入是n个object queries,所以DETR只能预测N个结果。N的数量是固定的,和groundtruth会存在数量上的不一致。所以会引发一个问题:怎么衡量预测结果的准确性。
DETR把它当作一个二分图匹配的问题来解决。假设ground truth是$y$,预测结果是$\hat{y} = \{\hat{y_i}\}^N_{i=1}$。一般情况下N是比图片中实际的框的数量要大的,我们把$y$也当作一个大小为N的集合(用“no object”补全)。
匹配结果的损失函数可以表示为
$$ \hat{\sigma} = arg min \sum_i^NL_{match}(y_i,\hat{y}_{\sigma(i)}) $$
最优匹配通过匈牙利算法来计算,这个loss的目的就是让最优匹配的结果的差距最小化。这个匹配结果的损失不仅考虑分类,也考虑bounding box,所以它可以被看作$y_i = (c_i, b_i)$。c是class,b是代表了中心坐标和宽高的向量。
$$ L_{match}(y_i,\hat{y}_{\sigma(i)}) = -1_{\{c_i\neq\oslash\}}\hat{p}_{\sigma(i)}(c_i) + 1_{\{c_i\neq\oslash\}}L_{box}(b_i,\hat{b}_{\sigma(i)}) $$
上面这个公式是一个pair的损失,下一步就是计算所有pair的总的损失。
$$ L_{Hungarian}(y,\hat{y}) = \sum^N_{i=1}[-log\hat{p}_{\hat{\sigma}(i)}(c_i)+ 1_{\{c_i\neq\oslash\}}L_{box}(b_i,\hat{b}_{\hat\sigma(i)})] $$
在实际使用中,作者对“no object”的类别会做一个down-weight的处理,为了缓解类别不均衡的问题。
公式中的$L_{box}()$,作者使用的是l1loss和iouloss的组合。
$$ L_{box}(b_i,\hat{b}_{\sigma(i)}) = \lambda_{iou}L_{iou}(b_i,\hat{b}_{\sigma(i)}) + \lambda_{L1}||b_i - \hat{b}_{\sigma(i)}||_1 $$
此外,作者还是用了名为auxiliary losses的方法,对于每一个decoder block的输出都计算一次loss,并且这样也确实带来了效果的提升。
代码实现
代码部分主要参考源码:https://github.com/facebookresearch/detr。
首先回顾一下DETR的流程。
- 使用backbone提取图像特征:这里用的是最深层的featuremap。
- 创建position embedding。这个embedding主要在encoder相关的部分使用。
- transformer encoder结构,主要用于进行一个全局特征的提取。
- 创建object query。这个也可以看作一个position embedding,主要在decoder相关的部分使用。
- transformer decoder结构,寻找图像中的物体。
- FFN 预测目标检测的结果。
DETR
首先我们来看一下源码中DETR这个class。
它的init()函数中的传入参数包括:
- backbone:你打算使用的backbone
- transformer:构造好的transformer
- num_classes:数据集中物体种类的数量。
- num_queries:object queries的数量,也就代表了每张图中能预测的物体的最大数量。
- aux_loss:是否要使用aux_loss。
我们只看构造函数的部分,各个module已经很清晰明了啦。配合着我们说过的DETR的流程。class DETR(nn.Module): """ This is the DETR module that performs object detection """ def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False): super().__init__() self.num_queries = num_queries self.transformer = transformer hidden_dim = transformer.d_model self.class_embed = nn.Linear(hidden_dim, num_classes + 1) # 增加了一个“on object”的类别 self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3) self.query_embed = nn.Embedding(num_queries, hidden_dim) # 你的object query self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1) self.backbone = backbone self.aux_loss = aux_loss - self.backbone 用于获得featuremap的backbone
- self.input_proj 用于将backbone获得的featuremap降维,得到的featuremap维度一般是2048,这个有点太大了。
- self.transformer 你的transformer 包含了encoder和decoder。
- self.query_embed 你的object query。
- self.class_embed 和 self.bbox_embed用于预测类别和bbox。
然后我们再看一下forward的部分。
if isinstance(samples, (list, torch.Tensor)):
samples = nested_tensor_from_tensor_list(samples)
features, pos = self.backbone(samples)
src, mask = features[-1].decompose()
assert mask is not None
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
outputs_class = self.class_embed(hs)
outputs_coord = self.bbox_embed(hs).sigmoid()
out = {
'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out
这里的self.backbone(samples)的返回结果有两个,一个是features一个是pos,因为在源码中position_embed的部分和backbone结合在一起做了。
将输入们一股脑地放到transformer里面,得到输出hs。
并用hs来进行bbox和class的预测。
backbone and position
在论文给出的代码中,position embedding和backbone的实现还是比较简单的。
在下面这段代码中,self.backbone使用的是resenet50去掉池化和全连接的部分,用于提取特征图,x = self.backbone(inputs)的结果是维度=2048的32倍下采样featuremap。
然后使用self.conv这个1*1卷积进行降维。并在flatten后和pos_embedding组合在一起作为输入。
当然这段代码实际上和原论文中描述的原理是不一致的,因为论文里的position embedding是加在Q和K上的,并不是直接和输入组合在一起的。
下面这段代码只是说明了DETR在实现上是多么简单,不需要依赖别的package。
# 首先是init的部分
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2]) # 忽略了最后的池化和全连接的resnet50
self.conv = nn.Conv2d(2048, hidden_dim,1)
self.row_embed = nn.Parameter(torch.rand(50,hidden_dim//2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim//2))
# 下面是forward的部分
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([self.col_embed[:W].unsqueeze(0).repeat(H,1,1),
self.row_embed[:H].unsqueeze(1).repeat(1,W,1),
],dim=-1).flatten(0,1).unsqueeze(1)
现在我们继续来看github上官方源码是怎么做的。
在官方源码中,position_embedding和backbone被组合到了一起。
IntermediateLayerGetter
DETR的backbone中用到了这个class。
https://github.com/pytorch/vision/blob/main/torchvision/models/_utils.py#L8
class IntermediateLayerGetter(nn.ModuleDict):
def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:
这个class的作用是,给定model和想要返回的层。在forward阶段,返回的结果是一个OrderedDict,它的key是你指定的返回层对应的名字,它的val是当前层的输出结果。
def forward(self, x):
out = OrderedDict()
for name, module in self.items():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out
在backbone的实现中是这样定义 return_interm_layers的
if return_interm_layers:
return_layers = {
"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
else:
return_layers = {
'layer4': "0"}
也就是说你想要中间层的结果,IntermediateLayerGetter的forward阶段会以名字“0,1,2,3”返回四个层的输出,如果你不需要中间层的结果,那么只会返回名为“0”的layer4的输出。
下面为backbone的forward阶段。这里的self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
假设我们没有使用interm_layer,那么self.body(tensor_list.tensors)的返回结果是layer4的输出的featuremap。
那么最终得到的这个out就是{'0': nestedtensor}。
def forward(self, tensor_list: NestedTensor):
xs = self.body(tensor_list.tensors)
out: Dict[str, NestedTensor] = {
}
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
out[name] = NestedTensor(x, mask)
return out
Joiner
在源码中,backbone和position encoding被一个名为Joiner的类组合在一起,我们先看一下这个类做了什么。
在Joiner是一个nn.Sequential(),我们之前学过,nn.Sequential()会把传入的module顺序组合在一起,并在forward阶段顺序调用。在Joiner中,它重写了forward()的部分。
class Joiner(nn.Sequential):
def __init__(self, backbone, position_embedding):
super().__init__(backbone, position_embedding)
def forward(self, tensor_list: NestedTensor):
xs = self[0](tensor_list)
out: List[NestedTensor] = []
pos = []
for name, x in xs.items():
out.append(x)
# position encoding
pos.append(self[1](x).to(x.tensors.dtype))
return out, pos
这个forward里的self[0]就是我们的backbone,self[1]就是position_embedding这个module。
已知self[0](tensor_list)返回的结果是一个OrderedDict。假设我们没有使用中间层,那么这里返回的xs是{"0": nestedtensor}。
这里返回的out就是nestedtensor的list,pos就是使用每一个nestedtensor做输入得到的position embedding的list。
position encoding
https://github.com/facebookresearch/detr/blob/main/models/position_encoding.py
源码中提供了两个position encoding的方式。
这个具体直接看源码吧。
在Joiner中,假如你使用了interm_layer,那么backbone就会有多层的输出,每个输出都会用position encoding生成一个位置编码。
位置编码的大小是$B, 1, H, W$。这里的位置编码和VIT以及SWIN中的还是有些差别的。
VIT和SWIN中在最开始都把一整个图片分成了多个patch,它的位置编码还包括了这个patch在整个图片中的位置。但是在DETR中它其实输入就是一个patch,而不是多个patch。在swin和transformer,它的position embedding是一个和token大小一致的编码,你的输入是N*D,那么你的position embedding也是N*D。
在DETR中,position embedding不是很在乎你的N的大小,它只看了你的D的位置,也就是$H,W$。所以position encoding才可以和backbone直接join在一起做,它不需要考虑backbone下一步用卷积降维的结果。
transformer
源码链接: https://github.com/facebookresearch/detr/blob/main/models/transformer.py
源码中transformer的部分用的也是自定义的模型,因为这里相对pytorch中的版本是有修改的,比如说它要求每个block的Q和K都需要加上position embedding。
直观来看,一个transformer由encoder和decoder两部分组成。它的init()部分主要是定义了一个encoder和一个decoder,所以我们直接来看一下forward部分的代码。
对于一个大小为$bs, c, h, w$的输入,首先要把它转成一个token的格式,在这里转为了$h*w, bs, c$。它的位置编码因为要与token直接相加,所以也需要改,变成了$h*w, bs, 1$
object query 也做了一些格式上的变化。原本的object query大小是$n, d$,被变成了$n,bs,d$。
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
这里要解释一下,这种写法是因为nn.MultiheadAttention中的batch_first默认是False。
Query embeddings of shape :math:
(L, E_q)for unbatched input, :math:(L, N, E_q)whenbatch_first=False
or :math:(N, L, E_q)whenbatch_first=True, where :math:Lis the target sequence length,
然后输入和编码们一起被送进 encoder和decoder中,分别得到encoder的输出memory和decoder的输出hs,并最终返回这两个结果。
encoder的输出memory和输入src大小是一致的,都是$h*w, bs, c$,所以最后先permute成$bs, c, h*w$后又展开为$bs, c, h, w$。
decoder的输出原本应该和输入tgt的大小是一致的(也就是object query的大小),都是$n,bs,d$,在实际上它在最终输出前增加了一个额外的维度,变成了$1,n,bs,d$,然后transpose后最终得到的是$1, bs, n, d$
事实上在decoder的过程中是可能会返回多层结果的,假如需要多层结果,这里得到的decoder的输出就是$k,n,bs,d$,k表示层数。所以单个结果的时候用unsqueeze也是为了保证返回结果的shape的一致性。
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
mask = mask.flatten(1)
tgt = torch.zeros_like(query_embed)
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
Encoder
我们先来看一下encoder的部分。一个encoder由多个encoder block/layer组成。在每一个layer中,都需要完成 MSA + MLP,此外还搭配上Norm+add残差。和标准的encoder的结构是一样的。
来看一下源码的layer的init部分。该有的组件都有:
- MSA + 残差和 + 归一化
- MLP + 残差和 + 归一化
这里的MSA就是self.self_attn。
MLP由两个全连接self.linear1,self.linear2加激活函数组合完成。
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
我们来看一下forward的部分。源码中实现了两个forward,一个是forward_pre,一个是forward_post。两个实现的区别在于normalize的位置。本质上还是一样的。我们以forward_post为例子进行介绍。
forward_post更符合我们对整个流程的认知。
- 得到QKV,进行self attention
- norm + 残差和
- 经过MLP
- norm + 残差和
```python
def forward_post(self,src, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None): q = k = self.with_pos_embed(src, pos) # 加上位置编码 src2 = self.self_attn(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0] # self attn src = src + self.dropout1(src2) # 残差和 src = self.norm1(src) # norm src2 = self.linear2(self.dropout(self.activation(self.linear1(src)))) # MLP src = src + self.dropout2(src2) # 残差和 src = self.norm2(src) # norm return src
src就是我们的输入,我们的K和Q要加上位置信息,所以这里使用了self.with_pos_embed进行一个加法的计算。
经过self attention得到结果src2,和输入src进行残差和+norm的计算。
然后再经过MLP层,再次残差和+nrom的计算,得到最终的输出。
这个layer和我们之前写过的encoderlayer除了加位置编码这个处理外,没有任何的区别。
在Encoder中会连续使用n次这个layer,每次都要使用这个位置编码对K和Q进行处理。
### Decoder
decoder 部分和 encoder有一点区别,因为decoder部分除了self_attn外还要和encoder联动做一个cross_attn。
decoderlayer的__init__()部分相对于encoderlayer,增加了一个self.multihead_attn用于做cross_attn,然后增加了对应的norm和dropout,别的没有改变。
所以我们直接来看forward的部分,还是用forward_post做例子。
首先看一下输入参数包括哪些。
```python
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt就是你的decoder的输入,memory是你的encoder的输出。pos是你的encoder的position embedding。query_pos就是你的object query。
这里的tgt在初始化时是一个和object query大小一致的全0向量,每一个decoder layer的输出都会成为下一层的输入的tgt。
一个decoder layer的流程是这样的:
- 输入进行self attention
- 上一步的结果作为q 和来自encoder的k和v做cross-attention
- 正常的MLP
来看一下代码中是如何完成的。
第一步是self attention。在这一步中是encoder中一样,Q和K上要加上位置编码。然后输出结果还要进行残差和+norm。
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
我们现在得到的tgt,将作为Q用于下一步的cross attention的计算。memory作为来自encoder的输出,会给我们提供K和V。
在这个self.multihead_attn中,输入的Q是加上decoder的位置编码的tgt,输入的K是加上了encoder的位置编码的encoder的输出memory,V是不加位置编码的memory。然后再进行残差和+norm的计算。
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),key=self.with_pos_embed(memory, pos),value=memory, attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
现在这个tgt,在最后接上MLP就可以输出了。
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
整个流程和一般的decoder也没有什么区别,主要是不管是selfattention和crossattention的部分,Q和K都要注意加上位置编码。
FFN
这一部分还是要回到DETR这个大class里面。
我们对DETR整体进行回顾,这里会将init()中的代码和foward()的放在一起,直观地看每一部分的作用。。
在backbone的部分我们得到了featuremap和position embedding。
self.backbone = backbone # __init__直接传进来一个backbone的module
features, pos = self.backbone(samples) # forward的部分,backbone的输出结果是两个list,第一个list里的元素是nestedtensor,第二个list的元素是position embedding
然后我们的feature map是要使用一个1*1卷积进行降维的。然后作为transformer的输入。
self.transformer = transformer # __init__直接传进来一个transformer的module
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1) # 用于降维的1*1卷积
self.query_embed = nn.Embedding(num_queries, hidden_dim) # object query
src, mask = features[-1].decompose() # 这里只使用了list的最后一项,所以不是很明白假如返回了中间层的话会起到什么作用。
assert mask is not None
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0] # 这里的输入的src要经过降维的,输入的pos也是最后一个featuremap得到的pos embedding,都没用到别的层的。
我们可以看到这里只用的了transformer的第一个输出。之前我们说过它会返回两个结果,第一个是decoder的结果,第二个是encoder的结果,所以这里只看decoder的结果。
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
outputs_class = self.class_embed(hs)
outputs_coord = self.bbox_embed(hs).sigmoid()
这两个比较简单,感觉也没有什么要说的。
Loss
源码链接: https://github.com/facebookresearch/detr/blob/main/models/detr.py
源码中的loss也是自定义了一个名为SetCriterion的类,其中也实现了多种类型的loss,我们重点看一下分类loss和位置loss。
在进行损失计算前,首先要完成输出的100个cls+bbox和ground truth的匹配,这里是使用匈牙利算法完成的,源码就不看了,链接放在这里。
aux loss
在DETR的forward阶段,直接返回的结果是:
out = {
'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
假如你打算使用aux_loss,那么就会增加decoder的中间层的输出结果,用于计算。
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
@torch.jit.unused
def _set_aux_loss(self, outputs_class, outputs_coord):
return [{
'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
loss_labels
在计算label的损失时,要用的是预测结果是pred_logits,它的大小应该是$bs, n, cls+1$,bs是batchsize,n是object query的数量,也就是我们要预测的框的数量,cls+1是包含了'no object'类后的物体类别总数。
首先要构建一个分类的target。
target_classes = torch.full(src_logits.shape[:2], self.num_classes,dtype=torch.int64, device=src_logits.device)
这个可以理解成构建一个大小为(bs,n)的target,并用self.num_classes这个数进行填充。因为实际上的类别是0到self.num_classes-1,所以这个self.num_classes 在这里代表的其实是“no object”这一类。
别的有真实类别的target是
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)])
这个会被直接拼到target_classes上去。
target_classes[idx] = target_classes_o
这样就得到了一个和输出logits数量/class都保持一致的target。
然后再使用cross_entropy计算结果。
loss_ce = F.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)
loss_boxes
loss_boxes的流程和loss_label差不多。
一个区别是,class也会计算“no object”的损失,但是boxes直接算对应的boxes的损失。
所以可以看到在loss_labels中使用的logits是全部的cls_logits,而loss_boxes中则挑出了匹配成功的部分。
src_boxes = outputs['pred_boxes'][idx]
loss_bbox使用的是L1loss和iou loss组合的结果。
还是一样先找出target。
target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0)
然后计算L1损失。
loss_bbox = F.l1_loss(src_boxes, target_boxes, reduction='none')
再计算iou损失。
loss_giou = 1 - torch.diag(box_ops.generalized_box_iou(
box_ops.box_cxcywh_to_xyxy(src_boxes),
box_ops.box_cxcywh_to_xyxy(target_boxes)))
