参考教程:
swin-transformer/model.py
SWIN-Transformer: Hierarchical Vision Transformer using Shifted Windows
概述
在前面介绍了vision transformer的原理,加入transformer的结构后,这种网络在多种图像任务中都取得了不错的结果。但是它也存在一些问题。
第一个问题就是上一章提过的粗粒度问题,patch的大小比较大时,一个patch内可能有多个相似特征。
第二个问题就是当你想获得更多的特征时,就必须使用很长的序列。这里的序列长度指的是N*D中的N。想要获得更多的N,patch的大小就需要变小,也就是更加细粒度。但是这种情况下,在计算内积的时候就效率很低,尤其考虑到encoder的block要反复做很多次,速度就更慢了。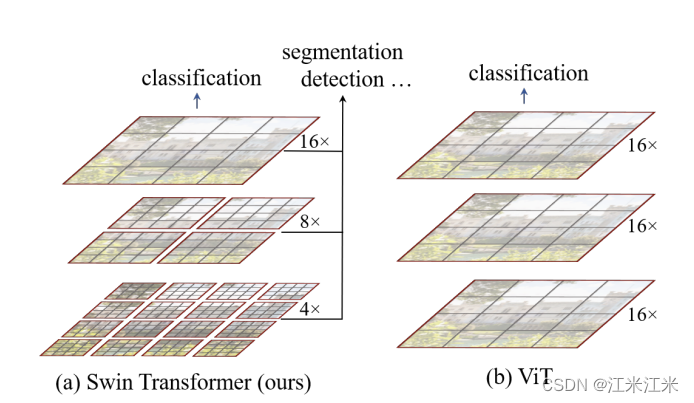
上图可以看出swin-transformer和vit有着比较明显的区别。首先siwn有着层次化的结构,随着层数加深,特征图的大小是在变化的。在VIT中,假如你将原始图片分割成16x16的patch,那么从始至终你的patch的大小都是固定的,而在swin中你能看出你的patch的大小有一个4*4->8*8->16*16的变化。其次是swing的特征图中有很多的划分好的名为窗口的区域,这也是它的方法的核心,VIT中所有的patch之间都要进行self-attention的计算,而swin中只在窗口内进行计算,这样计算量也会大大减小。
swin-transformer使用窗口和分层的方式。为了把结果做的比较好,第一层用很细粒度的token,在后面的层里为了提高效率,开始进行token的合并。经过每一层合并,token的数量会越来越少,计算量也会相对的减少。
token数量逐渐降低,就像卷积网络中feature map逐渐减小的过程。swin-transformer其实就是模拟了CNN的过程,随着层次的加深,token的数量降低,但是embedding_dim按层翻倍。
看整个流程,本质上还是一样的。首先对输入的图像进行编码。这里使用的是patch partition, 获得H/4*W/4个embedding,embedding_dim = 4*4*3 = 48。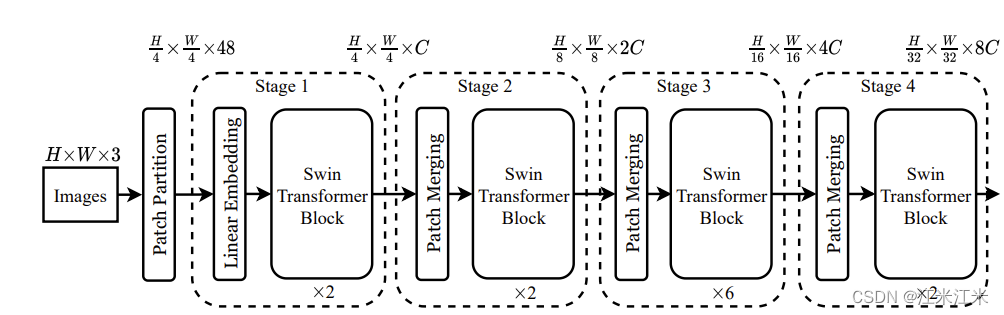
之后开始在网络中进行一层一层的forward。并且隔几个block进行一次patch merging。patch merging的作用就是将patch合并在一起,减少patch的数量。
在这个网络中,使用的block就是swin-transformer block,也就是shifted windows transformer,基于滑动窗口的方法。作者提出了滑动窗口这个机制,它不仅限制了没有重叠的窗口的自注意力计算,也允许跨窗口的连接。这样窗口内部和窗口之间都会存在信息传递。
综合来说,它的整体架构还是可以分成两部分:
- 得到pacth。
- 分层计算attention
transformer blocks
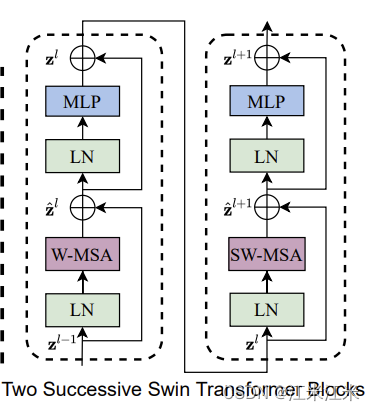
swin transformer block 和VIT中transformer block的主要区别就是用一个基于shifted window计算的多头自注意力模块取代了标准的MSA。
那么基于窗口的MSA做了哪些工作呢?
swin使用窗口,把一个图像分成一块一块不重叠的区域。假设每一个窗口包含M*M的patch。那么对于一个拥有h*w个patch的图像,MSA和W-MSA的计算量会有很大的差别。
$$ \begin{aligned} \Omega (MSA) = 4hwC^2 + 2(hw)^2C\\ \Omega (W-MSA) = 4hwC^2 + 2M^2hwC \end{aligned} $$
在h和w很大的时候,global的自注意力的计算量是难以负担的,但是基于窗口的自注意力下,计算量就比较容易接受。
计算量
来看一下这个计算量是如何计算得到的。
- 对于MSA:
- C代表着我们的token的维度,假设我们的输入大小为$A^{h*w, C}$,在进行Q\K\V的计算时维度没有发生变化,那么我们计算$A^{h*w, C} * W^{C,C}$的矩阵乘法的过程中,每次计算的计算量是$hwC^2$
- 因为Q\K\V计算了三次,所以三次的计算量为$3hwC^2$。
- 下一步是计算$Q^{h*w, C}$和$K^{h*w, C}$的内积,计算结果为$X^{h*w,h*w}$,内积计算需要点对点进行计算,所以计算量为$h^2w^2C$。
- 再下一步计算$X^{h*w,h*w}*V^{h*w, C}$,计算量为$h^2w^2C$。
- 因为这里是多头的自注意力机制,所以还需要增加一步$B^{h*w,C}* W^{C,C}$,计算量为$hwC$
- 所以对h*w个patch做MSA,总的计算量加起来为$4hwC^2 + 2h^2w^2C$
- 对于W-MSA:
假如窗口大小为M*M,那么在W-MSA中窗口数量为$\frac{h}{M}*\frac{w}{M}$- 对M*M个patch做MSA,总的计算量是$4M^2C^2 + 2M^4C$
- 一共要进行$\frac{h}{M}*\frac{w}{M}$ 次这样的计算,那么总的计算量是:
$$ \begin{aligned} &\frac{h}{M}*\frac{w}{M} * (4M^2C^2 + 2M^4C)\\ =&\frac{hw}{M^2}*(4M^2C^2 + 2M^4C)\\ =&\frac{hw}{M^2}*4M^2C^2 + \frac{hw}{M^2}*2M^4C\\ =&4hwC^2 + 2M^2hwC \end{aligned} $$
swin-transformer block
在swin-transformer中,有两种block,两个block要连在一起使用。
第一个block是W-MSA + MLP。
第二个block是SW-MSA + MLP。
两个block连在一起才是完整的结构。
从源码上看在进入和离开窗口时,embedding都会有形状的改变,分别为window_partition,作用是把大小为B*N*D的输入转成窗口的格式。在经过attention计算后,再使用window_reverse转回去。
整个block的计算公式可以写为:
window-partion
比如说我们的输入是一个224*224*3的图像,在经过patch embedding后得到56*56*96的结果。也就是说我们的图像被分成了56*56个4x4的小patch,每个4*4的小patch在处理后得到长度为96的embedding,到这一步,我们的数据就变成了56*56*96。
那么为了使用window-MSA,我们需要将这个patch_embedding再次变成一个窗口一个窗口的形状。假设我们的窗口大小为7。那么我们就可以得到8*8*7*7*96大小的embedding。前面的8*8代表你的window的个数,7*7是你的window的大小,96是每个位置的embedding的长度。
W-MSA
window-MAS就是在window范围内进行的自注意力计算。一个窗口的大小是7*7,也就是说每个窗口内有49个元素,我们要求这49个元素互相的关注度。
因为只在窗口内进行计算,所以可以理解成 8*8 = 64是你的batch_size, batch中的每个特征是不会互相影响的。7*7 = 64是你的word_number,96是你的word的embedding。这其实是和普通的MSA计算过程是一样的。
现在我们使用多头MSA对我们的64*49*96的输入进行计算。我们可以得到:
$$ SizeOf(Q/K/V) = 64 \times 3\times 49\times (96/3) $$
Q和K进行内积,得到的自注意力map的大小为64*3*49*49。
然后再和V加权求和,得到最终输出的token大小为64*3*49*(96/3)。
window-reverse
我们的token在进入block时进行了partion,再出去时我们希望得到的结果能保持和输入的token一样的大小。
对上面的结果直接进行reshape,就可以从64*49*96变回56*56*96。
shifted-window MSA
window-based 自注意力就像我们上面说的,只在窗口内进行计算,窗口间互不影响。但这种情况下,我们得到的就不是全局的特征了,所以shifted-window MSA就在这里起到了窗口间通信的作用。它通过滑动窗口的方式,更改窗口的位置,实现不同区域的交互。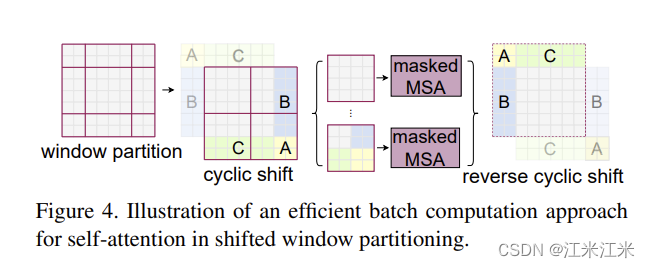
shifted window会带来更多的窗口数量,原本的窗口数是$\frac{h}{M}*\frac{w}{M}$,窗口经过平移后,新的窗口数会变成$(\frac{h}{M}+1)*(\frac{w}{M}+1)$,并且窗口的大小也变得不一样。
论文中采用的方法是将右/下方的window移动到左/上放,使用带mask机制的自注意力计算,并在计算出结果后将结果恢复至原来的窗口。
(这一块解释起来好复杂,论文中也也很含糊啊)
Patch Merging
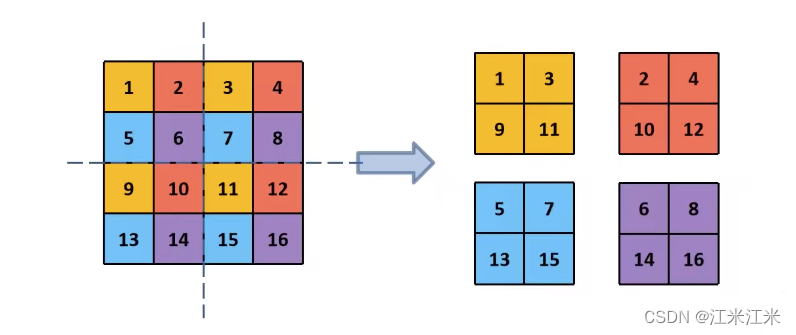
从百度里偷了一张图。
patch merging在这里就相当于一个下采样操作。
并且它采用的方法在之前也很常见,具体可以参考yolov2的passthrough,yolov5的FOCUS模块。本质上就是从一个feature map上间隔挑选,挑出4个大小为 h/2, w/2的新feature,并concat到一起,那么它的通道数其实是变成了4倍。
所以在后面又添加一个卷积层,进行降维操作。从而达成一次下采样,维度翻一倍的经典类卷积网络结构。
源码中都是用的全连接进行降维的。
relative position bias
【这里我需要抽空再看看】
在进行自注意力的计算时,增加一个relative position bias。
$$ Attention(Q,K,V) = SortMax(QK^T/\sqrt d+B)V $$
假设patch的数量是$M^2$,那么相对位置的范围就是[ -M+1, M-1]。所以论文作者使用了一个大小为[2M-1, 2M-1]的大bias matrix,实际使用的B就是从这里选出的。
代码实现
我们先来看一下整个流程,确认一下模型中都需要哪些结构。
- 对于一个输入图片,把它处理成token的形式。
- 对于每一个block,我们需要有
- window_partion
- window_reverse
- W-MSA (W-MSA和SW-MSA共用一个)
- MLP
- LN
- 输出头。
我们一步一步来完成整个流程。
代码主要参考:
https://github.com/microsoft/Swin-Transformer/blob/main/models/swin_transformer.py
input embedding
在swin的设置中,最初的patch_size大小是4, embed_dim大小是96,也就是说对于一个大小为$(h, w, c)$的输入,我们得到的embedding大小应该是$(h/4,w/4,96)$。
这一部分我们仍像之前一样使用卷积来完成。
去掉我写的无关紧要的注释的部分,这个代码和VIT最开始的patch embedding没有什么区别。核心都是conv+norm。
class PatchEmbed(nn.Module):
def __init__(self, patch_size=4, in_c=3, embed_dim=96, norm_layer=None):
super().__init__()
patch_size = (patch_size, patch_size)
self.patch_size = patch_size
self.in_chans = in_c
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
# 官方还限制了输入输出图像大小的要求,应该是从窗口数量考虑的,这里默认图像大小都符合要求,就不额外写了。
# 另一个参考代码中,还考虑了对不符合大小的图像进行padding。
# 我个人看法是假如你的图像大小真的和规定差距很大的时候,你除了padding成patch_size的倍数外,你还需要考虑你的
# 窗口数量是否符合要求,比如223*224的输出,窗口大小7*7,最初你的数量是8*8,随着两两合并的过程
# 这个数量是会按2倍下采样缩小的。
# pad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)
# if pad_input:
# to pad the last 3 dimensions,
# (W_left, W_right, H_top,H_bottom, C_front, C_back)
# x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],
# 0, self.patch_size[0] - H % self.patch_size[0],
# 0, 0))
x = self.proj(x).flatten(2).transpose(1,2)
x = self.norm(x)
return x
在对输入图像做了patch_embedding后,还要对它加上position_embedding。
在之前的position_embedding中我们还考虑了cls头,在这里不需要考虑。
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
sub-module
将一个swin-transformer block拆开来看,介绍一下每一部分是如何实现的。
window-partion
window-partion的过程其实就是个reshape的过程。比如我们第一步得到的patch_embedding大小是56*56*96。在这一步就会reshape成$(\frac{56}{window\_size}*\frac{56}{window\_size}*window\_size*window\_size*96)$。我们只计算window内部的self-attention。前面的个数全都可以看作batch_size。也就是说输出结果可以当作$(n, window\_size, window\_size, 96)$,那么每个窗口内会有$window\_size^2$个元素来进行自注意力的计算。
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
在进入attention模块之前,我们得到的window_partition的结果还会在reshape一下。我们输入attention的数据的格式要求是$(batch, number, embd_dim)$,partition结果与之对应的就是$(batch*number\_window, window\_size^2, embd\_dim)$
x_windows = x_windows.view(-1, self.window_size * self.window_size, C)
window_reverse
window_reverse的过程和window_partition的过程正好相反,它会把带窗口的embedding变回最初的大小。也就是从$(batch*number\_window, window\_size^2, embd\_dim)$变回56*56*96(在我们设定的情况下的大小)。
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
# 真正的B等于输入的第一个维度/window的个数。
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
W-MSA
处理成按window分的patch后,下一步就是正常的做MSA就可以了。
我们先不考虑shifted-window的平移,只看一下window-MSA的代码是怎么实现的。
在下方的代码上我都给出了注释,其实可以看出来,除了增加了 relative_position_bias的部分和mask,这段代码和上一章节里面VIT的MSA的部分是完全一样的。没有任何差别。
这里的mask在不用shift的时候就是None,所以在W-MSA里其实没有用到它,它只在shifted-window MSA起作用。
class WindowAttention(nn.Module):
def __init__(self, emd_size, window_size, num_head, qkv_bias = True, attn_drop = 0., proj_drop = 0.):
self.emb_size = emb_size
self.num_heads = num_head
head_im = dim//num_head
self.scale = qk_scale or head_dim**-0.5
self.qkv = nn.Linear(emb_size, emb_size *3, bias = qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(emb_size, emb_size)
self.proj_drop = nn.Dropout(proj_drop)
# 上面这部分就是普通的MSA一样的部分。没有任何修改。
# 下面的部分加了relative position bias。这部分我其实也不是很明白。
self.window_size = window_size
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1)*(2*window_size[1] - 1), num_heads))
# 这个地方就是上面说过的[2*M-1, 2*M-1]的bias matrix
#下面这段直接从官方源码复制过来的
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
# 生成网格,大小为[2, h, w],
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
# flatten 大小变成(2,h*w)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
def forward(self, x, mask=None):
B, N, D = x.shape # 这里的输入已经是window_partition后的结果。
# 这里的B_其实是 batch_size * wind_num *wind_num,这里的N是window_size*window_size
qkv = self.qkv(x)
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, D//self.num_heads).permute(2,0,3,1,4)
queries, keys, values = qkv[0], qkv[1], qkv[2]
attn = (queries@keys.transpose(-2,-1)) * self.scale
# 到这里,上面的部分还是和VIT里的是一样的。
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0) # 加上相对位置偏移。
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B//nw, nw, self.num_head, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads,N, N)
# 往后的部分和之前也是一样的。
attn = attn.sortmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, D)
x = self.proj(x)
x = self.proj_drop(x)
return x
SW-MSA
SW-MSA和MSA是共用的一个class实现的,他们的区别就在于SW-MSA的前向中会使用的mask。mask是在block初始化的时候创建的。
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
在前向forward使用时,这里面使用到了一个不太常见的函数。
torch.roll(input, shifts, dims=None)
torch.roll的作用就是滚动元素的位置,原本在最后的元素会回滚到最前方。和shifted_window在解决平移后窗口变多的处理理念是一样的,shifted_window想要把最右边和最下边的零碎窗口放到最前面和最上面,拼凑出完整的新窗口。torch.roll就帮它完成了这一步。
if self.shift_size > 0: # shift_size大于0就说明要使用的是shifted_window了。
if not self.fused_window_process:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
else:
x_windows = WindowProcess.apply(x, B, H, W, C, -self.shift_size, self.window_size)
shifted_window不仅在partition的时候要特殊处理,在reverse的时候也不太一样。
if self.shift_size > 0:
if not self.fused_window_process:
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = WindowProcessReverse.apply(attn_windows, B, H, W, C, self.shift_size, self.window_size)
这部分还是去看源码理解吧。
PatchMerging
直接看一下代码,代码还是很好理解的。
class PatchMerging(nn.Module):
def __init__(self, input_resolution, dim, norm_layer = nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2* dim, bias=False)
self.norm = norm_layer(4*dim)
def forward(self, x):
H, W = self.input_resolution # 就是当前featuremap的大小
B, N, D = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # 从00开始,x轴y轴各间隔一个取一个。
x1 = x[:, 1::2, 0::2, :] # 从10开始,x轴y轴各间隔一个取一个。
x2 = x[:, 0::2, 1::2, :] # 从01开始,x轴y轴各间隔一个取一个。
x3 = x[:, 1::2, 1::2, :] # 从11开始,x轴y轴各间隔一个取一个。
x = torch.cat([x0, x1, x2, x3], -1) # 到这一步新的大小是 (B, H/2, W/2, C*4)
x = x.view(B, -1, 4*D) # 到这一步再把featuremap拉平,(B, H*W/4, C*4)
x = self.norm(x)
x = self.reduction(x)
return x
MLP
MLP的部分和之前没有任何差别。可以自己加dropout进去,我没有加。
class MLP(nn.Module):
def __init__(self, in_features, hidden_features = None, out_feature=None, act_layer=nn.GELU, drop=0):
super().__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.dropout = nn.Dropout(drop)
def forward(self, x):
x = self.f1(x)
x = self.act(x)
x = self.f2(x)
x = self.act(x)
return self.dropout(x)
Swintransformer 与 block
各个组件部分都写完了。现在需要把它组合在一起。
写一个简单的流程逻辑:
class SwinTransformer(nn.Module):
def __init__(xxxxxxxxxxxxxxxxxxxxxxxx):
super().__init__()
## 省略掉一些初始化
# 第一个部件,patchembed
self.path_embed = PatchEmbed(xxxx)
# 第二个部件,pose_embedding
self.absolute_pos_embed = nn.Parameter(xxxx)
# 第三个部件,basicblock
for i_layer in range(self.num_layers):
layer = BasicLayer(xxx)
# 第四个部件,最终的分类头
self.head = nn.Linear(xxxxx)
这里的BasicLayer就是多个transformer block连接起来组成的ModuleList。所以我们再来看一下每个block流程。
class SwinTransformerBlock(nn.Module):
def __init__(self,xxxxxxxx):
super().__init__()
## 忽略一些初始化的内容
# 第一个部件,MSA
self.attn = WindowAttention(xxxx)
# 第二个部件,norm。
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
# 第三个部件 MLP。
self.mlp = Mlp(xxxxx)
# 第四个部件 mask。假如shifted_size >0 需要写一个mask。
attn_mask = xxxxxxxxxxxxxxxxxxxxxxx
# 因为partition和merge都是reverse都是函数而不是class,所以不用在初始化中用。
def forward(self, x):
# 假设输入x的大小是 B, N, D
shortcut = x
# 第一步 window_partition
x = x.view(B,H,W,D)
x_windows = window_partition(xxxxx)
# 这一步得到的结果大小是(B*H/size*W/size,size, size,D)
x_windows = x_windows.view(-1, self.window_size * self.window_size, D)
# 第二步 计算attention
attn_windows = self.attn(x_dinows, mask = self.attn_mask)
#第三步 window_reverse
attn_windows = attn_windows.view(-1,self.window_size, self.window_size, D)
shifted_x = window_reverse(attn_windows, self.window_size, H, W)
# 这一步的结果大小是(B, H, W, D)
x = x.view(B, H * W, D)
# 现在变成了B,N,D
# 第四步 add&LN&MLP
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
