本次体验了三个方向,共使用了六个模型。分别是代码相关、知识常识相关和NLP专业领域,都是专业性比较强得问题。这六个模型中有表现好的,当然也有一些确实存在致命的问题。下面我就这三个方向,展开详细的分析:
代码相关:
首先我们先来看一下具体的问答,用到的模型分别为:Model A: ChatPLUG-100Poison、Model B: billa-7b-sft-v1


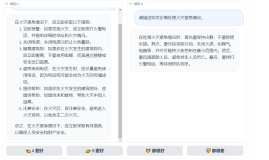
本次我共问了三个问题。一个python相关、两个java相关。其中python相关的比较基础,两个模型回答得都挺不错,java相关的常见题目也基本都回答出来了,其中模型B的答案较详细。最后不太常见的细节问题,两个模型都没有回答出来,而且都乱码了,这一点我认为非常的不好,如果这个题没有在模型的题库中,可以给一个较为友好的提示,直接乱码,实在不好。
知识常识相关
- 我们仍然先来看一下,各个模型的表现情况。本次用到的模型:Model A: qwen-7b-chat-v1、Model B: moss-moon-003-sft-v1


- 第一道题是关于数学的等差数列,我直接用的是系统推荐的题目。很显然,这道题回答的还是非常不错的。区别的话,就是Model B: moss-moon-003-sft-v1回答得要更为详细,更用于看懂,而Model A: qwen-7b-chat-v1则需要有些基础的人看。
- 第二个问题,是我们日常生活观察到的。两个模型都回答错了,而且错得一致,在这方便还是需要加强的。
- 第三个问题,是医学类的常识,两个模型表现得都很好。
NLP专业领域相关
- 本次测试呢?两个模型的差异就比较大了。用到的模型有:Model A: qwen-7b-chat-v1 、Model B: belle-llama-13b-2m-v1。下面我们具体看下:


- 第一个问题,仍然是系统推荐的,基础数学相关的问题,两个模型都很棒,回答的都特别好。
- 第二个问题,是名著相关的,差异就表现出来了。Model A: qwen-7b-chat-v1仍然表现得很好,回答准确,抓住了问题的核心。Model B: belle-llama-13b-2m-v1这次表现得就超级不好,直接乱码了。
- 第三个问题,是中国得传统节日相关问题。Model A: qwen-7b-chat-v1虽然回答的过于简洁,但是也算抓住了问题的核心,Model B: belle-llama-13b-2m-v1则是,完全不知道我在问什么,回答得乱七八糟。
总结:总得来看,我们平时学习经常遇到的问题,像数学相关的都回答得不错,但是广度不够。但是生活上的小细节问题,或者在实际开发中要遇到得小问题,则是没有记录。还有对中国的传统文化了解得不够,国内的东西,这一点还是挺不好的。