- 论文题目:The Predictron: End-To-End Learning and Planning
所解决的问题?
提出predictron结构,一种abstract model来表示马尔可夫奖励过程。端到端直接训练,相对来说能够省去一些没有必要的计算开销。但同时也损失了一些可解释性。
背景
基于模型的强化学习主要的思想聚焦于两个问题:1. 学习模型。2. 基于这个所学的模型进行规划。模型可以表示为MRP或者MDP的形式,规划的话就是基于这个所学的模型去评估值函数并且给出策略。以往一般的工作都是将二者分开,各玩各的,这样的话,智能体就并不能很好地去适应全局的目标函数。

所采用的方法?
Predictron由四部分组成:

这第四点可能优点难以理解,作者也举了个例子(k − s t e p k-stepk−step predictron):


如上图中的最右边的显示的那样,展开有:

网络结构

表示函数f ff是一个两层的卷积神经网络。之后定义一个core,里面结合了MRP model、λ -network到一个可重复模块中:

代码实现
定义编码网络和core网络:
# a two-layer convolutional network as the state representation self.embed = nn.Sequential( nn.Conv2d(C, hid_dim, kernel_size=kernel_size, padding=padding), nn.BatchNorm2d(hid_dim, momentum=bn_momentum), nn.ReLU(), nn.Conv2d(hid_dim, hid_dim, kernel_size=kernel_size, padding=padding), nn.BatchNorm2d(hid_dim, momentum=bn_momentum), nn.ReLU()).to(self.device) def clones(module, N): "Produce N identical layers." return nn.ModuleList([deepcopy(module) for _ in range(N)]) self.cores = clones( Core(input_dims=(hid_dim, H, W), hid_dim=hid_dim, kernel_size=kernel_size), core_depth).to(self.device)
前向和loss计算:
# 1. 先观测编码到s。 x = self.embed(x) self.buffer.reset() # 2. 之后进入N个core中 for core in self.cores: x, val, rwd, gam, lam = core(x) self.buffer.store(rwd, gam, lam, val) # 3. value计算 self.value_net_f = deepcopy(self.cores[0].value_net).to(self.device) val = self.value_net_f(self.flatten(x)) self.buffer.finish_path(last_val=val) # 4. 拿标签算loss: pret, g_lam_ret = self.buffer.get() y_tile = y.unsqueeze(1).expand_as(pret) ploss = self.loss_fn(pret, y_tile) lloss = self.loss_fn(g_lam_ret, y) loss = ploss + lloss
完整代码可以参考:
Pytorch实现:https://github.com/cying9/predictron-pytTensorflow实现:https://github.com/zhongwen/predictron
取得的效果?
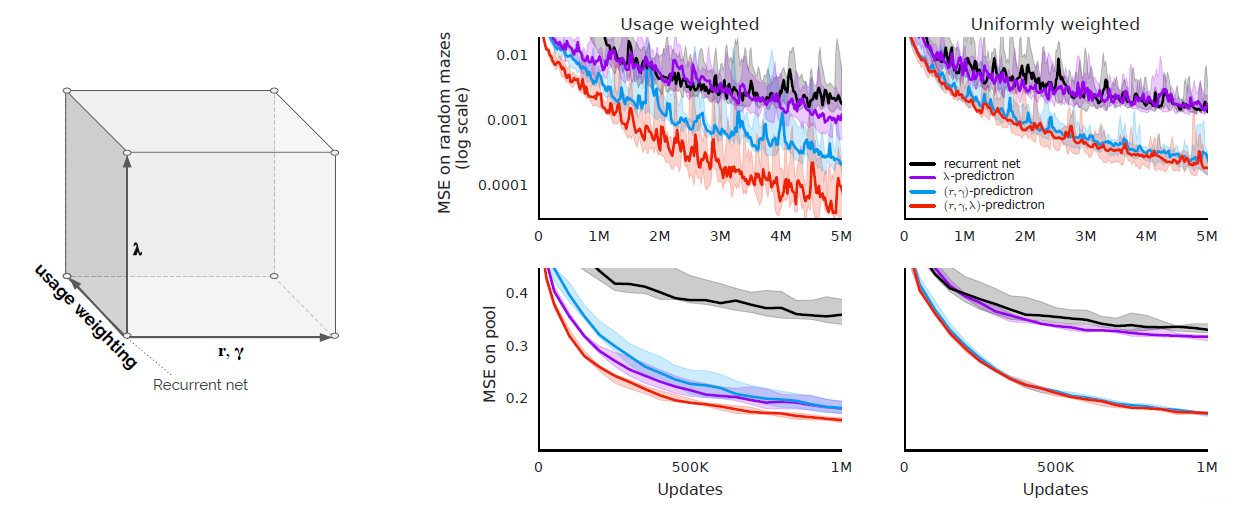
作者与循环神经网络,还有几组子对比实现进行了比较。这个思想在【Nature论文浅析】基于模型的AlphaGo Zero也是有用到的。
所出版信息?作者信息?
作者是大名鼎鼎的David Silver。