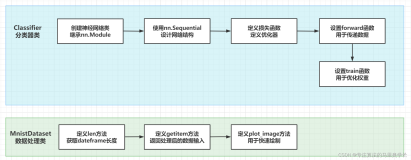
我们在前两篇文章中介绍了如何使用 Keras 构建和训练深度学习模型的基础和中级知识。在本篇文章中,我们将探讨一些更高级的主题,包括模型微调和自定义训练循环。
一、模型微调
模型微调(Fine-tuning)是深度学习中一种常见的技术,用于在一个预训练的模型(例如,ImageNet 上训练的模型)的基础上训练自己的任务。这通常会带来更好的性能,因为预训练的模型已经学习了一些通用的特征。
在 Keras 中,我们可以简单地加载预训练的模型,然后微调它。例如:
from keras.applications import VGG16
from keras.layers import Dense
from keras.models import Model
# 加载预训练的 VGG16 模型,不包括最后的全连接层
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 添加自定义的全连接层
x = base_model.output
x = Dense(1024, activation='relu')(x)
predictions = Dense(200, activation='softmax')(x)
# 构建完整的模型
model = Model(inputs=base_model.input, outputs=predictions)
# 冻结预训练模型的所有层,这样在初期训练中它们的权重不会改变
for layer in base_model.layers:
layer.trainable = False
# 编译和训练模型
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
model.fit(x_train, y_train)
二、自定义训练循环
尽管 Keras 提供了非常方便的 API 来训练模型,但有时我们可能需要更细粒度的控制训练过程。例如,我们可能想要在每个批次后更改学习率,或者在训练中实施一些复杂的策略。
在 Keras 中,我们可以通过自定义训练循环来实现这一点。以下是一个简单的示例:
import tensorflow as tf
from keras import backend as K
# 假设我们已经定义了模型和损失函数
model = ...
loss_fn = ...
# 定义优化器
optimizer = tf.keras.optimizers.Adam()
# 定义训练循环
for x_batch_train, y_batch_train in train_dataset:
with tf.GradientTape() as tape:
logits = model(x_batch_train)
loss_value = loss_fn(y_batch_train, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
在上述代码中,我们首先定义了一个优化器,然后在训练循环中,我们使用 tf.GradientTape 来计算损失函数关于模型可训练权重的梯度,然后使用优化器应用这些梯度。
以上就是本篇关于 Keras 的高级教程的全部内容。希望通过这三篇教程,你已经对如何使用 Keras 进行深度学习有了深入的理解。