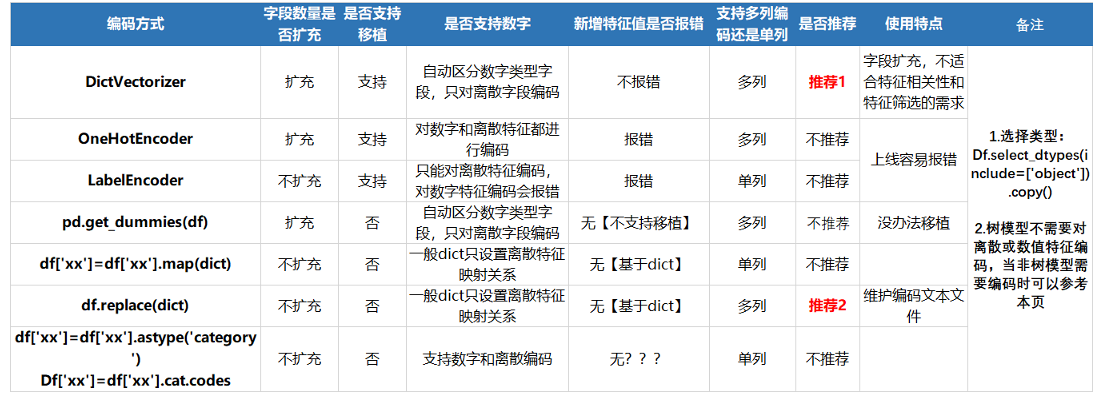
总结机器学习中7种离散特征编码方式优缺点
2023-07-19
160
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议》和
《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
本文涉及的产品
简介:
整理总结对比了7种机器学习离散特征编码方式的优缺点

目录
相关文章
|
5天前
|
机器学习/深度学习
数据采集
监控
|
5天前
|
机器学习/深度学习
人工智能
并行计算
人工智能平台PAI产品使用合集之机器学习PAI中特征重要性的原理不知道如何解决
阿里云人工智能平台PAI是一个功能强大、易于使用的AI开发平台,旨在降低AI开发门槛,加速创新,助力企业和开发者高效构建、部署和管理人工智能应用。其中包含了一系列相互协同的产品与服务,共同构成一个完整的人工智能开发与应用生态系统。以下是对PAI产品使用合集的概述,涵盖数据处理、模型开发、训练加速、模型部署及管理等多个环节。
30
0
0
|
5天前
|
机器学习/深度学习
算法
|
5天前
|
机器学习/深度学习
数据采集
算法
【Python机器学习专栏】使用Scikit-learn进行数据编码
【4月更文挑战第30天】本文介绍了Python Scikit-learn库在机器学习数据预处理中的作用,尤其是数据编码。数据编码将原始数据转化为算法可理解的格式,包括标签编码(适用于有序分类变量)、独热编码(适用于无序分类变量)和文本编码(如词袋模型、TF-IDF)。Scikit-learn提供LabelEncoder和OneHotEncoder类实现这些编码。示例展示了如何对数据进行标签编码和独热编码,强调了正确选择编码方法的重要性。
26
0
0
|
5天前
|
机器学习/深度学习
存储
数据采集
|
5天前
|
机器学习/深度学习
数据可视化
算法
|
5天前
|
机器学习/深度学习
数据可视化
算法
|
5天前
|
机器学习/深度学习
数据采集
数据可视化
|
5天前
|
机器学习/深度学习
数据挖掘
Python
|
5天前
|
机器学习/深度学习
算法
热门文章
最新文章
1
【一文看懂】使用hape部署分布式版Havenask
2
【一文解读】阿里自研开源核心搜索引擎 Havenask简介及发展历史
3
阿里云开源离线同步工具DataX3.0介绍
4
【深入浅出】阿里自研开源搜索引擎Havenask变更表结构
5
盘古:阿里云飞天分布式存储系统设计深度解析
6
odps是什么?
7
阿里云MaxCompute(大数据)公开数据集---带你玩转人工智能
8
Kibana:数据分析的可视化利器
9
一分钟了解阿里云产品:大数据计算服务MaxCompute概述
10
独家专访阿里集团副总裁贾扬清:我为什么选择加入阿里巴巴?
1
C语言开发《力学:弹跳球模拟实战》
8
2
使用 PAI-DSW x Free Prompt Editing图像编辑算法,开发个人AIGC绘图小助理
19
3
Qt编程中,第一个Hello world程序
13
4
springsecurity和jwt区别
72
5
高效爬取Reddit:C#与RestSharp的完美结合
25
6
ClickHouse(07)ClickHouse数据库引擎解析
22
7
Java一分钟之——Java模块系统:模块化开发(Jigsaw)
39
8
Java一分钟之——异常分类:检查异常与运行时异常
19
9
深入解析xLSTM:LSTM架构的演进及PyTorch代码实现详解
14
10
Java一分钟之——异常链:追踪错误源头
22