
摄影:产品经理中奖中了一顿饭
在Python中,如果要判断一个字符串是否在另一个字符串里面,我们可以使用in关键字,例如:
>>> a = '你说我是买苹果电脑,还是买windows电脑呢?' >>> if '苹果' in a: ... print('苹果这个词在a字符串里面') ... 苹果这个词在a字符串里面
如果有多个句子和多个关键字,那么可以使用for循环来实现:
sentences = ['你说我是买苹果电脑,还是买windows电脑呢?', '人生苦短我用Python', '你TM一天到晚只知道得瑟', '不不不,我不是说你,我是说在座的各位都是垃圾。' '我CNM你个大SB' ] keywords = ['垃圾', 'CNM', 'SB', 'TM'] for sentence in sentences: for keyword in keywords: if keyword in sentence: print(f'句子: 【{sentence}】包含脏话:【{keyword}】')
运行效果如下图所示:

现在如果有100000000个句子,有1000个关键字,那么你需要对比1000亿次才能全部查询完成。这个时间代价太大了,如果Python一秒钟能运行500万次查询(实际上没有这么快),那么1000亿次查询需要20000秒,接近6小时。而且,由于in关键字的时间复杂度为O(n),如果有大量长句子,查询时间会更长。
例如,我们要从下面的句子里面寻找CNM。
sentences = ['你说我是买苹果电脑,还是买windows电脑呢?', '人生苦短我用Python', '你TM一天到晚只知道得瑟', '不不不,我不是说你,我是说在座的各位都是垃圾。', '我CNM你个大SB', '各位同学,Good Morning!', '网络这个单词,它的英文为Network', '我不想听到有人说CNM!' ]
如果使用常规方法,那么我们的做法是:
CNM在你说我是买苹果电脑,还是买windows电脑呢?中吗?不在!CNM在人生苦短我用Python吗?不在!- ……
- ……
CNM在我CNM你个大SB吗?在!CNM在各位同学,Good Morning!吗?不在!CMN在网络这个单词,它的英文为Network吗?不在!CNM在我不想听到有人说CNM!吗?在!
于是就知道了,CNM在sentences列表下标为4和7的这两个句子中。
下面,我们换一个看起来更笨的办法:
要找到CNM在哪几句里面,可以变成:寻找C、N、M这三个字母在哪几句里面。然后,再找到同时有这三个字母的句子:
C在4, 7句N在4,6,7句M在2, 4,5,7句
所以,{4, 7} 与 {4, 6, 7} 与 {4, 5, 7}做交集,得到{4, 7}说明CNM这个词很有可能是在第4句和第7句。
为什么说很可能呢?因为假如再添加一句话:今天我们学习三个单词:Cat, Network, Morning。这一句也会被认为包含CNM这个词,但实际上它只是同时包含了C、N、M三个字母而已。
接下来,有人会问了:原来直接查询CNM的时候,只需要查询8次就可以了。现在你分别查询CNM要查询24次。你是修复了查询时间太短的bug吗?
回答这个问题之前,我们再来看另一个问题。
Python里面,当我要判断字母C是不是在句子我不想听到有人说CNM!里面时,Python是如何工作的?
实际上,它的工作原理可以写成:
sentence = '我不想听到有人说CNM!' for char in sentence: if char == 'C': print('C在这个字符串中') break
如果要判断C、N、M是不是都在这个字符串我不想听到有人说CNM!中,同一个字符串会被遍历3次。有没有办法减少这种看起来多余的遍历操作呢?
如果我们把我不想听到有人说CNM!这个句子转成字典会怎么样:
sentence = '我不想听到有人说CNM!' sentence_dict = {char: 1 for char in sentence} for letter in 'CNM': if letter in sentence_dict: print(f'字母{letter}在句子中!')
这样一来,只需要在生成字典的时候遍历句子一次,减少了2次冗余遍历。并且,判断一个元素是否在字典里面,时间复杂度为O(1),速度非常快。
我不想听到有人说CNM!生成的字典为{'我': 1, '不': 1, '想': 1, '听': 1, '到': 1, '有': 1, '人': 1, '说': 1, 'C': 1, 'N': 1, 'M': 1, '!': 1}。那么如果要把列表里面的所有句子都这样处理,又怎么存放呢?此时,字典的Key就是每一个字符,而Value可以是每一句话在原来列表中的索引:
sentences = ['你说我是买苹果电脑,还是买windows电脑呢?', '人生苦短我用Python', '你TM一天到晚只知道得瑟', '不不不,我不是说你,我是说在座的各位都是垃圾。', '我CNM你个大SB', '各位同学,Good Morning!', '网络这个单词,它的英文为Network', '我不想听到有人说CNM!'] index_dict = {} for index, line in enumerate(sentences): print(index, line) for char in line: if not char.strip(): continue if char in index_dict: index_dict[char].add(index) else: index_dict[char] = {index}
生成的字典为:
{'B': {4}, 'C': {4, 7}, 'G': {5}, 'M': {2, 4, 5, 7}, 'N': {4, 6, 7}, 'P': {1}, 'S': {4}, 'T': {2}, 'd': {0, 5}, 'e': {6}, 'g': {5}, 'h': {1}, 'i': {0, 5}, 'k': {6}, 'n': {0, 1, 5}, 'o': {0, 1, 5, 6}, 'r': {5, 6}, 's': {0}, 't': {1, 6}, 'w': {0, 6}, 'y': {1}, '。': {3}, '一': {2}, '不': {3, 7}, '个': {4, 6}, '为': {6}, '买': {0}, '人': {1, 7}, '位': {3, 5}, '你': {0, 2, 3, 4}, '到': {2, 7}, '单': {6}, '只': {2}, '各': {3, 5}, '同': {5}, '听': {7}, '呢': {0}, '在': {3}, '圾': {3}, '垃': {3}, '大': {4}, '天': {2}, '学': {5}, '它': {6}, '座': {3}, '得': {2}, '想': {7}, '我': {0, 1, 3, 4, 7}, '文': {6}, '是': {0, 3}, '晚': {2}, '有': {7}, '果': {0}, '瑟': {2}, '生': {1}, '用': {1}, '电': {0}, '的': {3, 6}, '知': {2}, '短': {1}, '络': {6}, '网': {6}, '脑': {0}, '苦': {1}, '英': {6}, '苹': {0}, '词': {6}, '说': {0, 3, 7}, '还': {0}, '这': {6}, '道': {2}, '都': {3}, '!': {5, 7}, ',': {0, 3, 5, 6}, '?': {0}}
生成的字典这么长,看起来非常可怕。但是别慌,毕竟不是你人肉寻找。对Python来说,字典里面无论有多少个Key,它的查询时间都是一样的。
现在,我们要寻找C、N、M,于是代码可以写为:
index_list = [] for letter in 'CNM': index_list.append(index_dict.get(letter, {})) common_index = set.intersection(*index_list) # 对包含各个字母的索引做交集,得到同时包含3个字母的句子 print(f'这几个句子里面同时含有`C`、`N`、`M`:{common_index}') for index in common_index: print(sentences[index])
运行结果如下:

所以,对于一组需要被查询的关键字,也可以这样搜索:
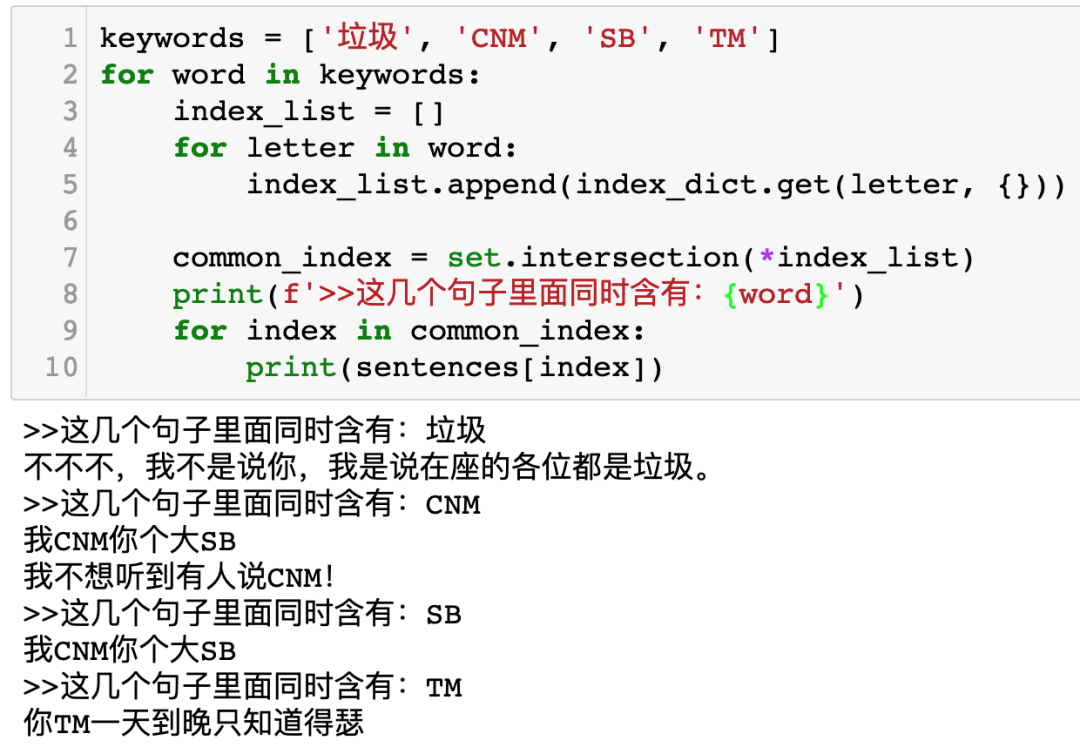
keywords = ['垃圾', 'CNM', 'SB', 'TM'] for word in keywords: index_list = [] for letter in word: index_list.append(index_dict.get(letter, {})) common_index = set.intersection(*index_list) print(f'>>这几个句子里面同时含有:{word}') for index in common_index: print(sentences[index])
运行效果如下图所示:
看完这篇文章以后,你已经学会了倒排索引(Inverted-index)。这是Google搜索的核心算法之一。
可以看出,对于少量数据的搜索,倒排索引并不会比常规方法节约多少时间。但是当你有100000000条句子,1000个关键词的时候,用倒排索引实现搜索,所需要的时间只有常规方法的1/10甚至更少。
最后回到前面遇到的一个问题,当句子里面同时含有字母C、N、M,虽然这三个字母并不是组合在一起的,也会被搜索出来。这就涉及到搜索引擎的另一个核心技术——分词了。对于英文而言,使用空格来切分单词就好了。但是对于中文来说,不同的汉字组合在一起构成的词语,字数是不一样的。甚至有些专有名词,可能七八个字,但是也要作为整体来搜索。
分词的具体做法,又是另外一个故事了。


