基于YOLOv5算法的APP弹窗检测方案
在软件应用的各种弹窗中,弹窗识别是比较复杂的,比如不同类型弹窗中有不同的特征,比如网页样式或者浏览器类型等。弹窗的识别是涉及多个环节的,需要针对不同类型的网络流量采取不同的检测方法。由于网络流量较大,因此传统算法往往不能对弹窗进行有效识别。同时,由于弹窗具有隐蔽性和流动性,因此对于弹窗的识别有着非常高的要求,因此有针对性的攻击方式将会极大提升应用的安全性。本文基于YOLOv5算法对不同类型弹窗进行检测,并通过统计不同特征提取算法的特征信息进行匹配训练,对弹窗进行检测效果分析,最后通过算法迭代优化来实现不同类型弹窗的识别效果与检测效果的优化效果匹配,进而提高弹窗识别精度并降低攻击成本!
一、算法方案设计
弹窗识别是应用中的关键功能,主要是针对一些网页,比如网页样式、链接等,传统弹窗识别通常是通过人工方法进行检测的,虽然可以做到快速、准确地将弹窗识别出来,但是在某些场景下,人工检测难以保证识别出正确的弹窗,如当前网页类型为 TCP/IP,且存在未加密弹窗的情况下,弹窗识别结果会很差。因此,本文采用YOLOv5算法来处理一些复杂弹窗行为和检测效果不佳后的弹窗,本文使用YOLOv5在保证识别效果的前提下提高弹窗识别准确率。YOLOv5提出的 MovieLens弹窗检测模型是一个快速、准确、检测结果高效、低成本(<30 ms)的弹窗检测方法。它在 FLURE和 MIUMA MapReduce等 MovieLens模型中都得到了应用。相比于其他弹窗检测模型, MovieLens弹窗检测模型对流量比较灵活,能很好地适应各类情景下的网络流量。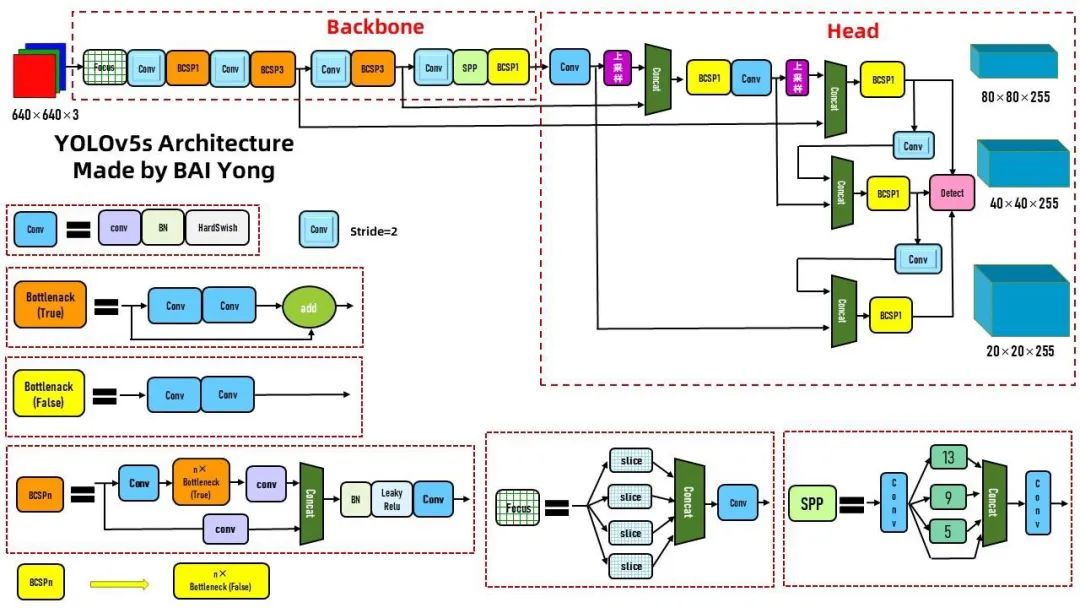
1、预处理
弹窗识别之前需要对弹窗进行预处理,即提取弹窗特征进行处理。弹窗特征包括文本和图片两种,文本特征包括文本颜色、字体、大小、语句之间的相互关系等。其中文本特征和图片特征具有非常重要的作用,文本特征是网页最基本的特征,也是本文研究弹窗识别时需要重点提取的特征,它决定着弹窗识别的结果。本文使用 Raidena方法提取文本特征以及图片特征。Raidena方法利用文本数据进行特征提取数据中更多信息来进行弹窗特征提取,这种方法能够提高提取到的弹窗特征数数量。本文采用基于 Java或 Raidena语言进行特征提取。Java或 Raidena语言都能够很好地提取文本特征信息并且较好地适用于 MovieLens弹窗特征提取。
2、提取特征
YOLOv5是一种基于卷积神经网络的分类算法,利用卷积神经网络来检测一个网页的图片特征。卷积神经网络分为三层,分别代表二维图片图像信息、三维图片图像信息和二维图片图像信息,如图1所示。本文使用 CUBE作为内存函数,在内存中预处理二维图片图像信息、三维图片信息以及二维图片图像信息。CUBE是一种通用的算法实现方法,通常用于图像特征提取和图像分类。CUBE和 MovieLens特征提取的方式大致相同:通过 CUBE模型获取每个像素点代表图像特征值,再将每个像素点对应的原始图像特征值的输入; MovieLens模型则是通过 CUBE函数获取每个像素点对应的原始图像特征值的输出;两种方法都可以在不损失特征值的前提下获得较好的分类效果。
3、验证模型
本文用 LIMARA验证模型,具体流程如图5所示。首先要选择一组训练样本,对其初始化后的特征提取、排序和训练,然后进行识别并生成一个对应网页的弹窗类别,如图6所示,从弹窗类别中抽取15个特征,分别以YOLOv5为训练模型输入YOLOv5中含有两个特征值作为输入特征提取,最后以 Slogan为结果输出弹窗类别。对每一个弹窗进行筛选后,分别采用四种不同的算法对弹窗进行特征提取与特征排序。如图7所示,对每一类训练样本进行排序,然后用YOLOv5中含有两个特征值当做结果输出的弹窗类别,最后使用 Slogan为结果反馈机制来进行用户弹窗特征提取。
二、算法验证与优化
本文对弹窗检测方法进行了验证,主要包括两部分内容:一是首先分析弹窗的内容,分析弹窗特征与算法如何实现最佳的匹配;二是利用训练好的YOLOv5算法通过输入数据集验证其有效性。在实验中我们采用样本数量为1000个,每次输入1个样本信息作为测试变量对样本进行实验(见图3),通过上述两步方法验证算法有效性,同时将测试样本中已识别出来的500个样本作为改进数据集进行训练。本文对优化后的YOLOv5算法进行了优化,如图4所示:从上述改进数据集中可以看到本文提高了准确率和精确度,但是由于对数据数量的要求过高,因此优化之后的YOLOv5算法比原先更难实现。
1、样本选择
由于本文的算法目标是检测弹窗,因此首先要考虑样本的鲁棒性和稳定性。样本鲁棒性是指在不同的测试环境下,样本在识别过程中不会产生明显的差异。在测试环境下我们选取1000个样本作为训练集,在不同测试环境下,检测样本都是不同的,如果仅根据一组数据进行训练验证其准确性,那么将会极大地降低算法准确率。因此需要进行多组测试来获得样本之间的鲁棒性,因此选择500个样本作为测试集。
2、训练方法
为了实现YOLOv5,需要将测试样本中已识别出来的样本进行训练,本文采用了预训练(BP)和实时监控(LM)两种方式。预训练主要用于分类识别,在本实验中针对弹窗进行预训练后直接通过ResNet10算法完成;实时监控则采用 TRIM视频分析软件对弹窗进行实时监控分析训练得到实时状态网络输出结果。本测试以一个弹窗作为训练样本开始进行训练。实验按照以下步骤进行:首先使用预训练好的弹窗样本匹配并进行预处理(如图6所示);其次设置测试样本变量为500个并将其训练样本(如表1所示);最后检测样本通过预处理后生成训练样本(如表1所示)与训练样本(如表2所示)。通过上述步骤可以看出,本文在预处理阶段已经根据训练样本中已识别出来并生成训练样本了结果。
3、性能提升
针对YOLOv5算法在数据量巨大的情况下性能提升有限的情况,提出一种改进方法,在数据集数量为1000,提取300个样本后在执行训练过程中进行训练时间提高到50分钟。对数据集进行训练时需要多次刷新不同的分类器(如图7所示)以获取更加精确的分类器样本值,使样本识别效率得到明显提升。首先我们使用 LSTM对训练样本进行处理(如图8所示)。在 LSTM处理时首先对分类器样本信息进行抽取,并用 Hadoop和 Lens滤波后对输入进行预处理:过滤掉不同分类器样本中出现的无关类别数后再经过参数化后得到最后标签。由于数据太多会导致计算量过大,而训练时间过长又会导致学习率过低(如图9所示)。针对上述问题通过 BMP模型与 LSTM结合得到一种优化方法用于训练模型:采用 BMP函数进行训练,先采用 LSTM算法对数据集进行预处理得到训练后标签数量为300个的分类器样本值(见表2)。
三、总结
在本次的YOLOv5算法中,经过多次迭代优化,最终实现了对弹窗中关键字符和图像的识别。对于每个关键字符,从网络侧提取每个字符信息中相应的关键字,并从图像侧提取图像中主要元素组成的多尺度图像特征;对于每个图像特征,使用自适应的模型训练,将训练得到的特征对图像进行分割从而得出重要的特征集合并在其中训练相应的分类图像特征;对于每一个关键字符,利用自适应模型训练不同的特征匹配策略以达到不同的匹配效果;并且,还使用自适应模型来评估弹窗图片的总体特征以及每种弹窗图片中潜在的攻击方式和不同类型弹窗中最常用的攻击方式之间的相似度。此外,基于YOLOv5算法来识别弹窗还可进一步提高检测精度。对于弹窗图像识别系统来说,利用多种检测方法来提升弹窗识别效果具有非常重要的意义。本文在传统机器学习和人工智能领域已经取得了一些优秀的研究成果。
