1 背景
基于snowflake,redshift等在云上数仓的开创性工作,基于对象存储构建数据湖/数仓已经成为一股新的潮流,现在的云上数据库通常都采用计算-存储分离的架构,而不再是传统的share-nothing,这是由对象存储的的高弹性,低成本带来的优势,但是有与对象的存储特性,其在单流性能方面的弱点也很明显。
目前的常见的场景中,如离线分析,基本都只能采用大规模并发的方式大量调用对象存储的API来对冲一部分单流性能的不足。这种方式有一个潜在的默认约定:对象存储的带宽无限,可以无限的通过并发提高带宽和吞吐。这个约定在数据量不是特别大是是符合观察事实的,但是对于大规模业务,S3/Azure/OSS等不无法满足以上约定。
我们先了解一下问题,我们下一篇后面再讨论一下解决措施。
2 三种存算架构 ,网络瓶颈和两种解决方向
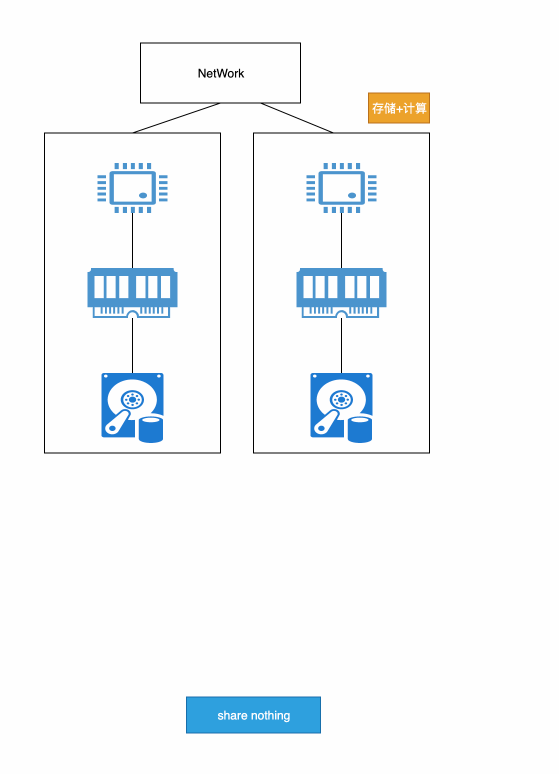
share-nothing在架构上能充分利用磁盘内存的带宽,存算一体,如Doris等追求性能的数据库都是基于此架构来设计。
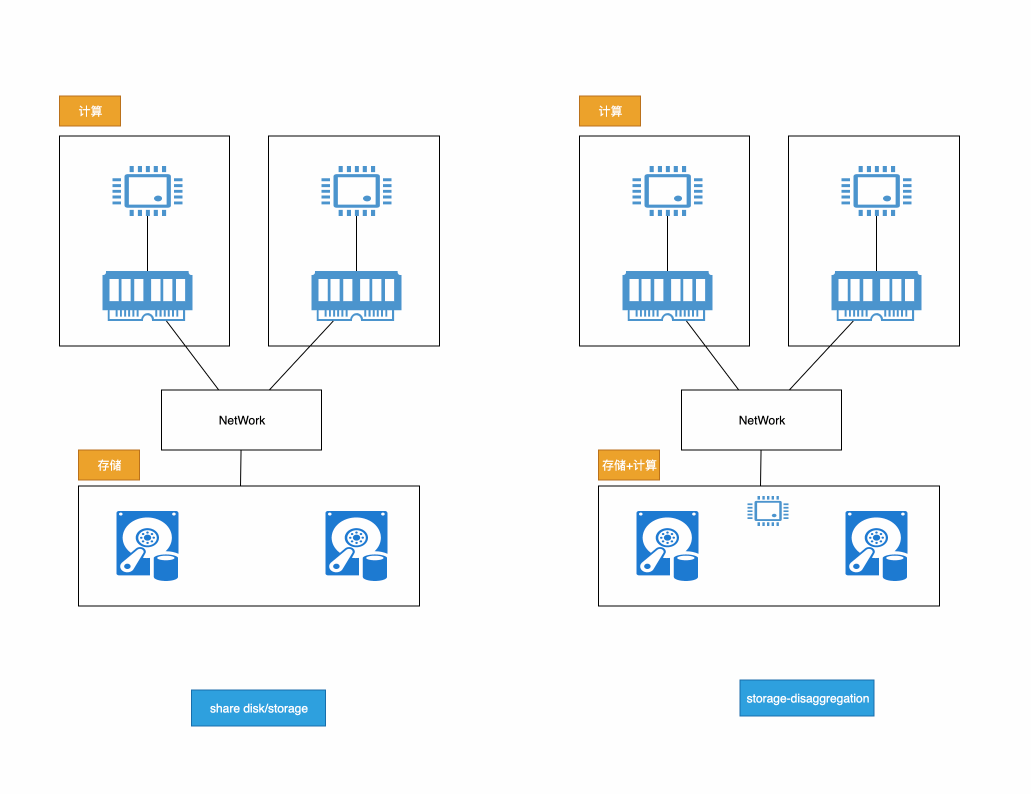
对于云上数据库来说弹性和成本是一个更重要的课题,所以几乎都采用的存算分离的架构,share-Disk(或者share-storage)和storage-disaggregation的架构都可以获得存算分离,share-Disk上存储只是单纯的存储,依然解决存储和计算间带宽的限制,而storage-disaggregation在存储端带有一定的少量计算能力,存储测的计算能力相比计算侧很小,但是其能发挥重要的作用。
注意一点,对于storage-disaggregation来说其存储测带有计算能力,其计算侧也可以带有存储能力,典型的就是OSSFS的实现,其会将数据缓存在主机上,但是只缓存部分数据,这样其实该架构就形成 计算侧:大计算小存储 + 存储测:大存储小计算的一种混合模式。
计算侧的存储能力和存储侧的计算能力,都可以为我们解决网络瓶颈。我们在实践的过程中可以得出的一些普遍结论:
-
存储到计算的网络带宽有限
-
存储内部的带宽远远大于存储到计算之间的带宽
-
数据处理的时机约靠近存储,网络数据越少,对计算任务的收益越大
理想情况下,完全缓存在计算侧后,网络流量为0;如果完全不缓存,全部使用pushdown利用存储测的能力,那么带宽的减少量依赖于结果数据与原始数据的比例(数据的selectivity。
3 本地缓存的优势
如jindoFs,juiceFs,OSSFs等典型的基于对象存储的查询引擎,都会再本地进行数据的缓存,来提供数据的访问效率,另外如Alluxio之类的缓存机器也可以归为此类。基于缓存的系统,对热点的加速明显,缓存越大效果约明显,
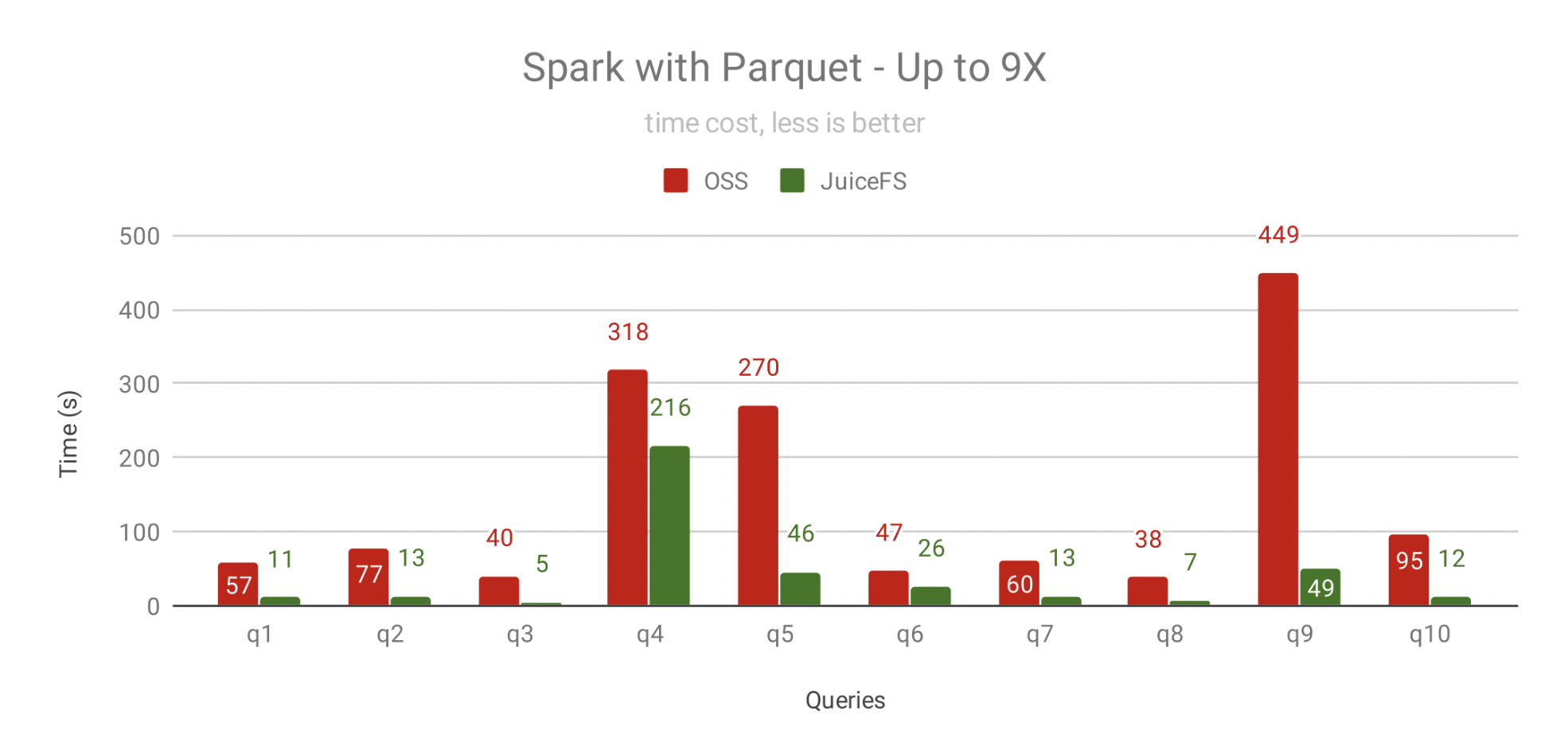
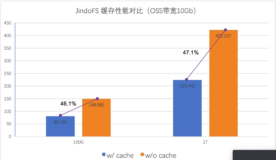
对于交互式查询,经常要对热点数据做反复查询的,上图是同一个查询重复 3 次后的结果,上图中JuiceFS 依靠缓存的热点数据大幅提升性能,10 个查询中的 8 个有几倍的性能提升,提升幅度最少的 q4 也提升了 30%。
4 算子下推的优势
对于下推,目前常见的是要场景是数据湖场景,以及对冷数据(已经归档到对象的数据)的查询场景,在这个场景下,计算侧不足以存放所有数据,直接拉取数据到计算侧会消耗大量的时间,并且对单流的查询响应时间通常不是特别敏感,可以通过增加并发读来提升系统的整体吞吐。
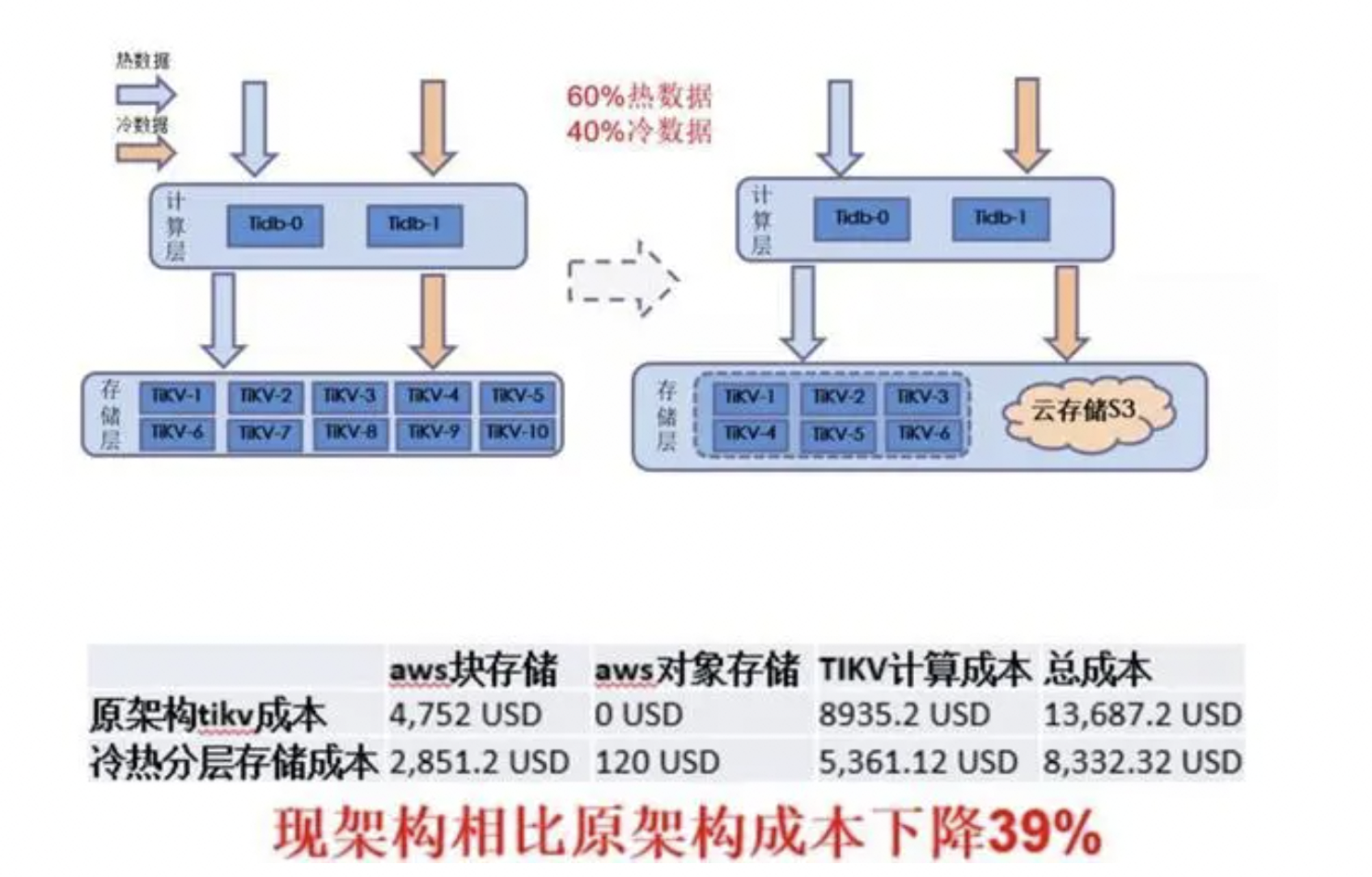

前人的研究表明(TiDB Hackathon 2021 冷热数据分层存储主),利用S3的算子下推,在成本节约39%的基础上,性能可以做到存算一体的模型持平甚至有时候还有更好一些。
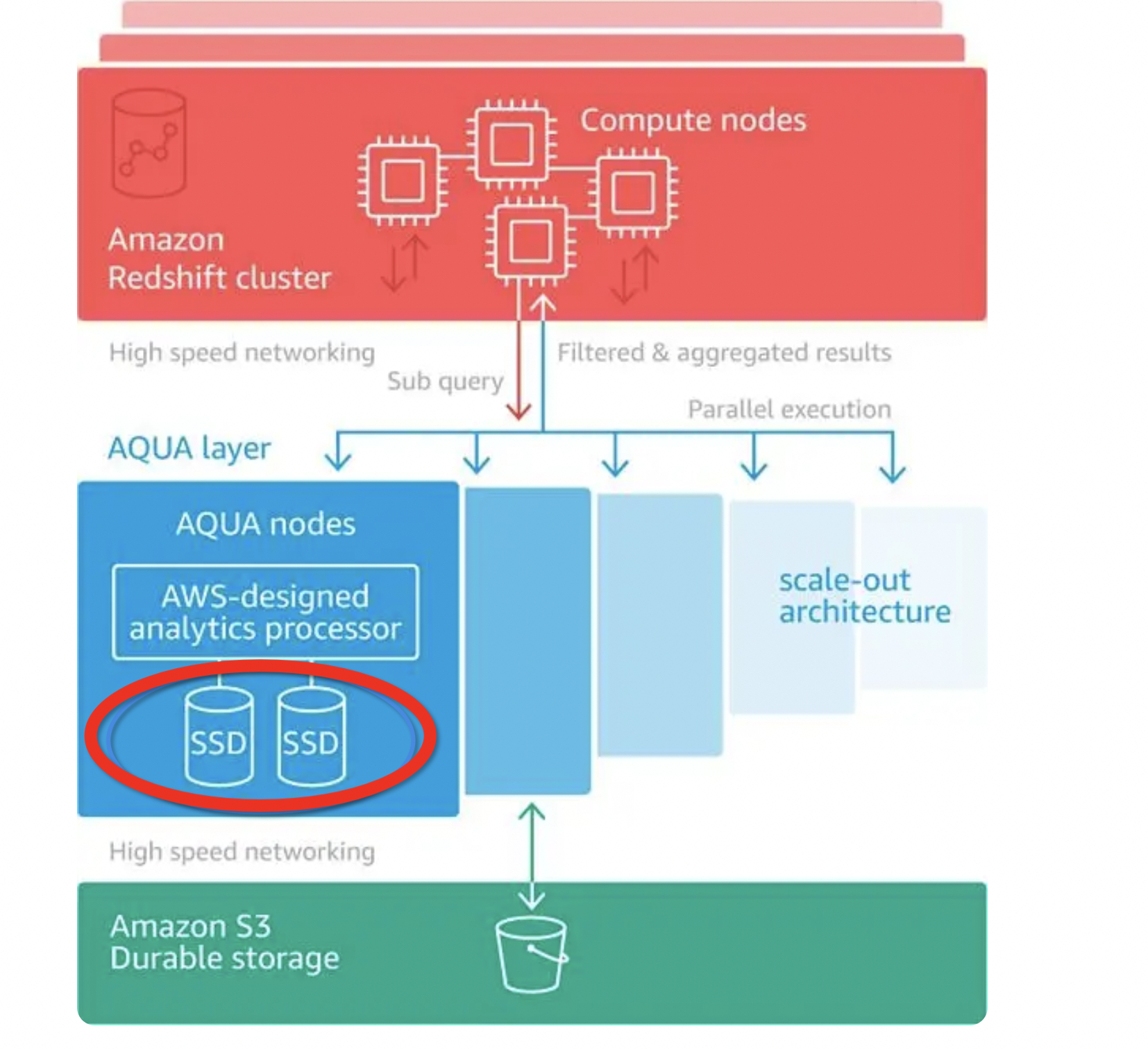
下推另外一个典型产品的是Aqua,提高查询的速度,其能帮助计算侧。但其实Aqua不是完全的下推,它不是实现在对象存储内部,Aqua可以理解为是一种近存储的下推+缓存的结合体。目前基于Aqua的实现细节的资料不多,个人推测真是因为Aqua并非是在对象存储内部实现,其无法充分利用存储内部的带宽,所以再Aqua的节点上都加上了SDD,作为环境带宽不足的手段。
5 缓存的问题
在上面我们讨论了基于缓存来解决网络带宽的问题,但是这里也有几个问题
-
计算侧的存储空间比较小 ,统计在大数据场景下,数据量都是上P,上T,客户端缓存不足以承担数据的存储
对于这个问题,我们可以使用Alluxio等集群式存储来解决,但这也带来了一些新的问题,以单独部署容量巨大的Alluxio集群为例:Alluxio和存储之间的带宽也是受限的。
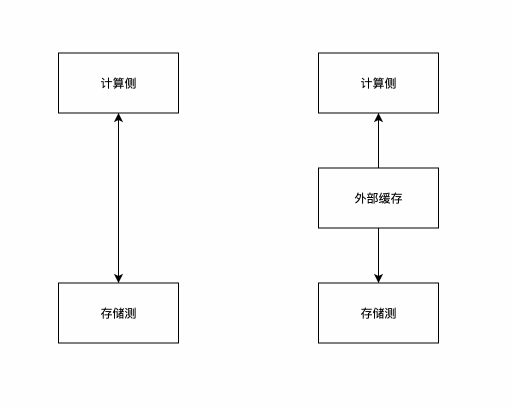
归根接地Alluxio对于存储系统来说也是另外一种形式的计算侧,对计算来说有成为了外部的存储测。以Alluxio为代表的外部存储系统并不能解决网络带宽有限的实时。
b.缓存的第二个问题,数据一致性。
这个很好理解,如果数据在存储侧进行了更新,但是计算侧不能感知到或者感知有延迟,那么其计算结果可能会有偏差。尽管可以用append only等设计来进行规避,但是其他架构的应用用到了缓存就必须容忍不一致是个事实。
c.数据第一次访问时依然需要拉取全量数据。
在数据未缓存前,第一获取数据依然会收到网络瓶颈的影响,对于上面第一点讨论的alluxio的外部集训搭建的方案也一样。
上面的几类问题我们总结一下,完善的解决方法似乎是:
-
缓存系统要充分利用 存储 or 计算 内部带宽大于系统间带宽的事实
-
缓存系统和存储系统要保持强一致
-
系统应该在首次获取时也要能避免网络瓶颈。
目前似乎没有完全的银弹,一些实践中的解决方案我们留到后面讨论。
6 pushDown的问题
pushDown方案可以让技术侧完全不用存储数据,只需要将查询条件给存储侧,就能将数据量大大的减少,极大的释放网络层面的压力。所以存储侧S3-Select和Oss-Select诞生后,我们曾经给予厚望,期望能在大范围上使用已解决云上数仓/数据湖面临的带宽问题。但是实际上目前该特性使用面并不广,其问题我们接着讨论。
1 pushDown性能无优势
业界有很多对S3-select的测试和使用,基于目前的经验总结来看,S3-select单请求在查询延时上相比在计算侧 load+process并无优势,甚至更慢。原因很好理解:存储侧不具备大规模计算的资源,pushDown并不能加快计算。
2 pushDown的功能还不完善
计算常用的的算子有,filter scan,projection,aggregation,sort,jion。
filter scan,projection,比较好实现,存储侧做完pushdown给计算侧组合起来就可以用,aggregation在存储侧只能做针对文件的操作,计算侧拿到结果需要再聚合一下。
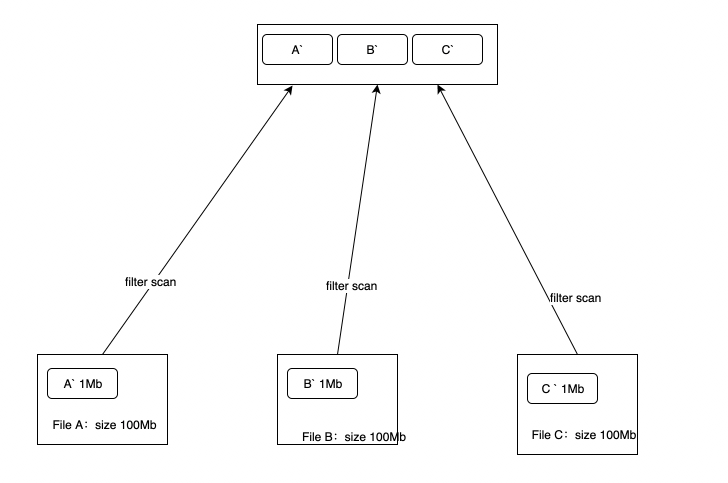
sort和jion这个两个操作就比较麻烦了,针对join,很明显数据是分散在多个文件中的,直观来讲对于对象存储的pushdown不具备可操作性。但前人的一些研究表明,bloomfilterpushDown是可以在下推场景实现的,可以将一个小表的bloomfilter计算出来,作为参数传递给存储,所以对于join,bloomfilter构建(building phase)阶段,是无法下推的,但是jion的执行阶段(probing phase)是可以下推的。再filter scan,projection,jion,aggregation的算子中,我们都可以做的网络带宽的减少,如上图所示:我们的原始数据A,B,C分别是100Mb,原始文件需要的带宽是【A+B+C=300M】,但是实际获取的A`,B`,C`只有1M,那么最终带宽【A`+B`+C`=3M】减少比例为90%。
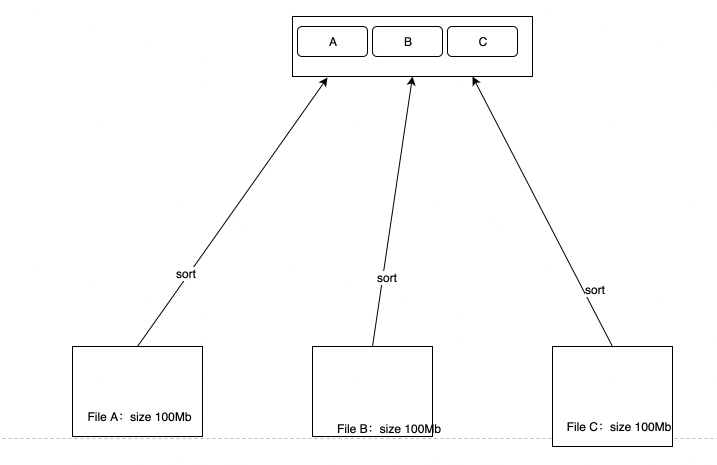
对于sort,理论上可以在存储侧针对文件做一轮局部sort,在计算侧再做一次全局sort。但是实际上这们做不能减少任何网络流量,纯粹的就是把部分计算放在了存储侧,存储侧计算能力有限,这么做并不划算。目前S3Select并不支持sort接口,个人认为也是考虑到此原因。
基于上面的优点和问题,我们下一篇后面再讨论一下解决措施。
----更新一下,说解决不够严谨,后面再讨论一下优化方向。