
综合运用数据分析与数据挖掘课程中的数据探索、数据预处理、分析建模等理论知识,能够根据不同的业务的场景,选定不同的数据分析与数据挖掘模型,并能够通过Python语言及第三方库编程实现,培养学生数据分析思维,为学生今后从事数据分析相关工作奠定基础
数据处理
对数据进行质量探索,包括重复值,缺失值,异常值,不一致的值等
1. # 加载数据 2. import pandas as pd 3. credits_data=pd.read_csv("data/项目一/tmdb_5000_credits.csv") 4. credits_data.shape# 查看数据的维度
两张表的数据处理
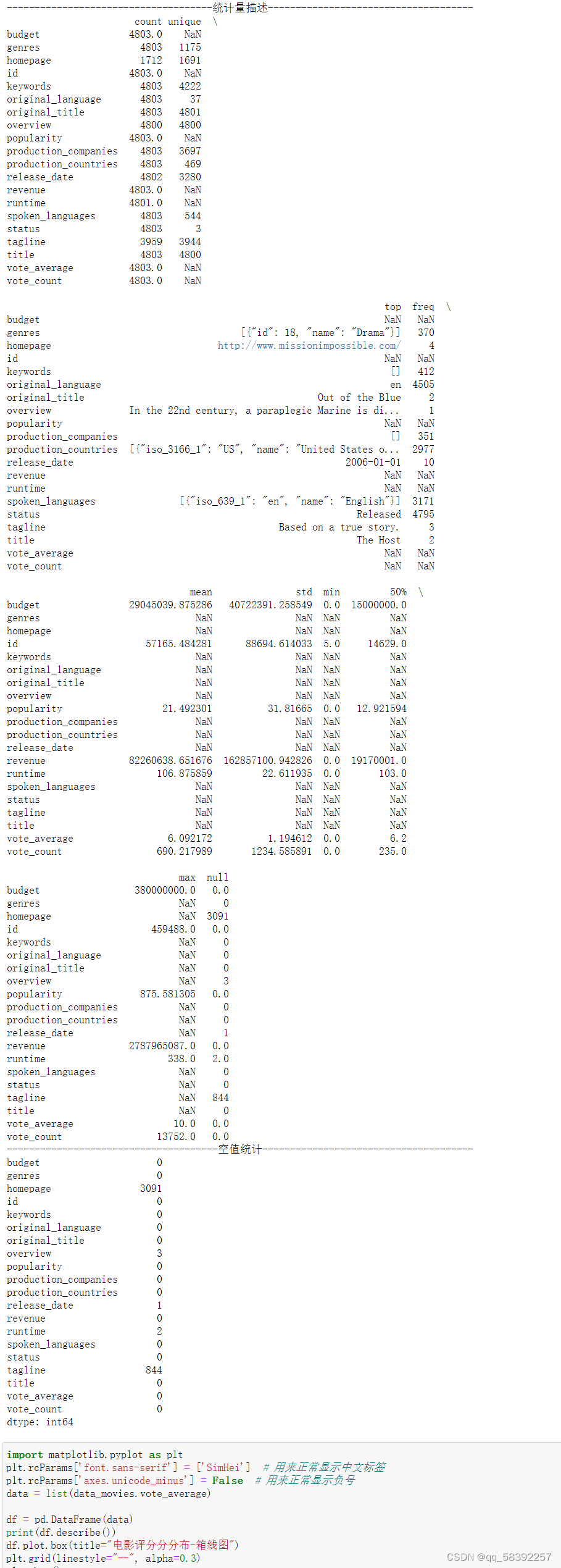
1. print('-------------------------------------统计量描述-------------------------------------') 2. explore = credits_data.describe(percentiles=[], include='all').T # percentiles参数是指定计算多少的分位数表 3. explore['null'] = len(credits_data) - explore['count'] # describe()函数自动计算非空值数,需要手动计算空值数 4. print(explore.head()) 5. explore = explore[['null', 'max', 'min','mean']] 6. explore.columns = [u'空值数', u'最大值', u'最小值',u'平均值'] # 表头重命名 7. # explore.to_csv('data/项目一/credits_data统计量描述.csv') # 保存结果 8. print('--------------------------------------空值统计--------------------------------------') 9. print(credits_data.isnull().sum())
描述性分析

导入表数据
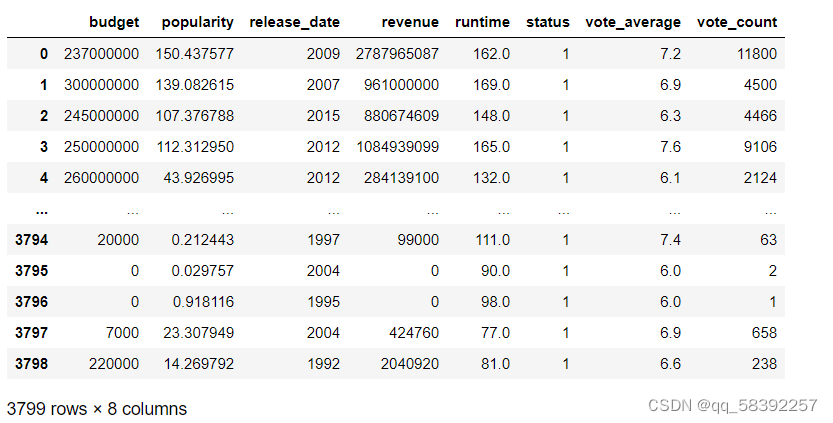
1. #导入tmdb_5000_movies表中的数据 2. data_movies=pd.read_csv("data/项目一/tmdb_5000_movies.csv") 3. data_movies.head(2)

描述性分析
数据划分
选取我们所需要的字段进行划分数据集,使用特征选取函数,选取六个最好的特征进行建模。
1. x=data_L.drop("vote_average",axis=1) #自变量 2. y=data_L["vote_average"]# 因变量
1. from sklearn.model_selection import train_test_split 2. #划分数据集 训练集80%测试集20% 3. x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state=42)
数据建模
随机森林模型
随机森林是一种有监督学习算法。就像它的名字一样,它创建了一个森林,并使它拥有某种方式随机性。所构建的“森林”是决策树的集成,大部分时候都是用“bagging”方法训练的。bagging 方法,即 bootstrapaggregating,采用的是随机有放回的选择训练数据然后构造分类器,最后组合学习到的模型来增加整体的效果。简而言之,随机森林建立了多个决策树,并将它们合并在一起以获得更准确和稳定的预测
1. import numpy as np 2. import matplotlib.pyplot as plt 3. from sklearn.ensemble import RandomForestRegressor 4. from sklearn.model_selection import train_test_split 5. from sklearn.multioutput import MultiOutputRegressor 6. # #定义模型 7. regr_rf = RandomForestRegressor() 8. # 集合模型 9. regr_rf.fit(x_train, y_train) 10. # 利用预测 11. y_rf = regr_rf.predict(x_test) 12. #评价 13. print(regr_rf.score(x_test, y_test)) 14. # y_rf.round(1)
模型评估
学习曲线也是有很好的走向,重合了大部分的真实值,其中budget,popularity, release_date, revenue, runtime, vote_count字段是影响评分的主要因素,在自变量确定的情况下使用模型能够很好的对评分进行准确的的预测。一部电影能有很不错的收益,参与影评的人也多,在全国的流行度也高,这想当然是一部高分电影。也充分说明了随机森林就是根据多决策的方式进行结果的准确预测
1. import numpy as np 2. import matplotlib.pyplot as plt 3. from sklearn.ensemble import RandomForestRegressor 4. from sklearn.model_selection import train_test_split 5. from sklearn.multioutput import MultiOutputRegressor 6. from sklearn.model_selection import train_test_split 7. x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state=93) 8. # #定义模型 决策树的个数设置150 树的最大深度10 9. regr_rf = RandomForestRegressor(n_estimators=150,max_depth=10,random_state=0) 10. 11. # 集合模型 12. regr_rf.fit(x_train, y_train) 13. # 利用预测 14. y_rf = regr_rf.predict(x_test) 15. #评价 16. print(regr_rf.score(x_test, y_test))

结果预测
查看预测结果60%以上预测的值与实际值是差不多的

随机森林是一种很好的算法是对Bagging算法进行了改进,在解决本次问题中,随机森林会是一个不错的选择。最重要的是,它为你选择的特征提供了一个很好的重要性表示。同时可以处理许多不同属性的特征类型。随机森林是从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。而电影的评分也是受到多个因素的影响产不同的结果,这就需要进行多方面的决策, 当输入样本进入的时候,随机森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类,然后看看哪一类被选择最多,就准确的预测这个样本,这也极大提高了预测电影评分的准确度。
源码及数据已上传资源,需要联系丝发!
