





暂时未有相关云产品技术能力~
CSDN博客专家,华为云云享专家,阿里云专家博主,51CTO专家博主,现为推荐算法工程师,研究领域为AI推荐算法、NLP、图神经网络等,发表EI会议论文一篇,CSDN博客访问量破100万。 CSDN博客id:山顶夕景 微信公众号:古道西风瘦码 知识星球:AI算法乐园
2022年04月
 发表了文章
2022-04-25 18:48:51
发表了文章
2022-04-25 18:48:51
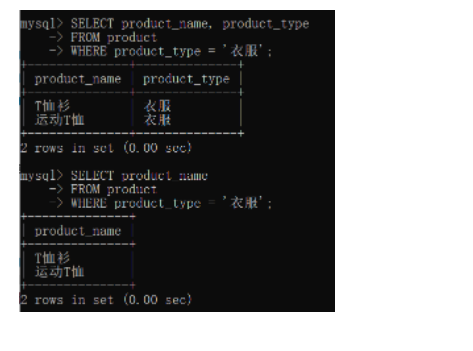 发表了文章
2022-04-25 18:00:10
发表了文章
2022-04-25 18:00:10
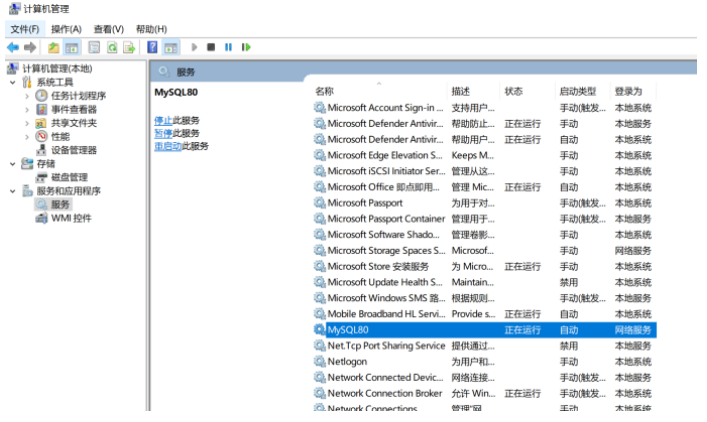 发表了文章
2022-04-25 17:37:22
发表了文章
2022-04-25 17:37:22
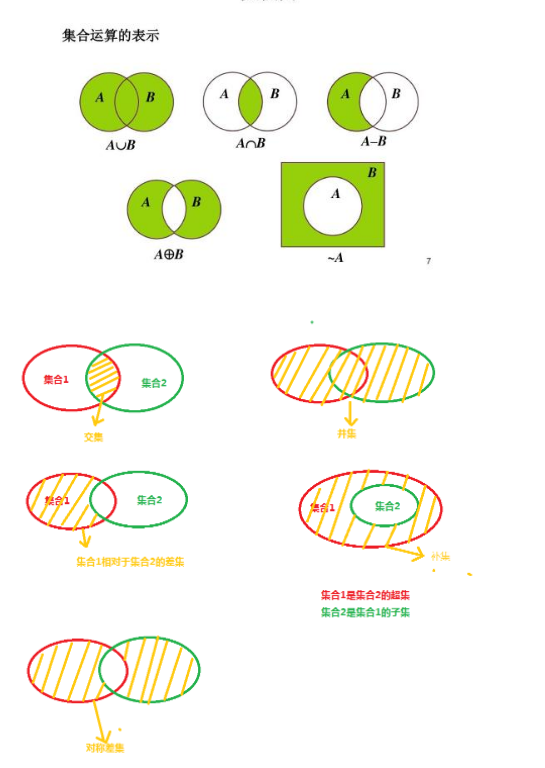 发表了文章
2022-04-25 15:40:02
发表了文章
2022-04-25 15:40:02
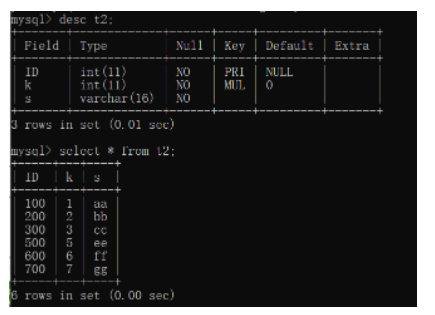 发表了文章
2022-04-25 15:35:24
发表了文章
2022-04-25 15:34:34
发表了文章
2022-04-25 15:35:24
发表了文章
2022-04-25 15:34:34
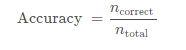 发表了文章
2022-04-25 15:30:09
发表了文章
2022-04-25 15:30:09
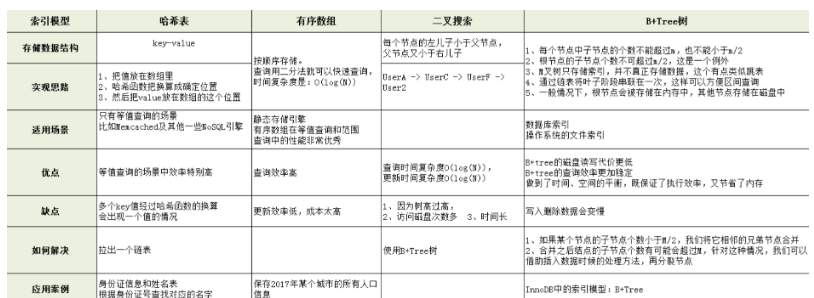 发表了文章
2022-04-25 15:25:19
发表了文章
2022-04-25 15:25:19
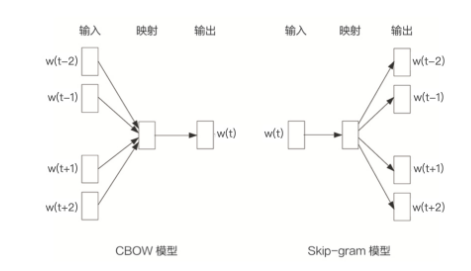 发表了文章
2022-04-25 15:20:17
发表了文章
2022-04-25 15:20:17
 发表了文章
2022-04-25 15:17:35
发表了文章
2022-04-25 15:17:35
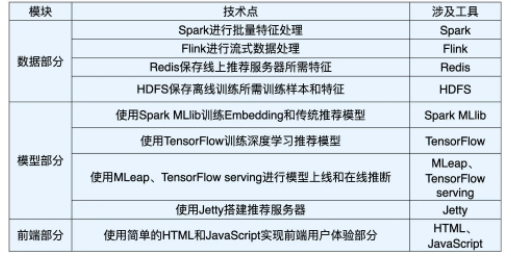 发表了文章
2022-04-25 14:59:25
发表了文章
2022-04-25 14:59:25
 发表了文章
2022-04-25 14:54:51
发表了文章
2022-04-25 14:54:51
 发表了文章
2022-04-25 14:49:52
发表了文章
2022-04-25 14:49:52
 发表了文章
2022-04-25 14:48:38
发表了文章
2022-04-25 14:48:38
 发表了文章
2022-04-25 14:44:58
发表了文章
2022-04-25 14:44:58
 发表了文章
2022-04-25 14:40:48
发表了文章
2022-04-25 14:40:48
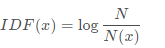 发表了文章
2022-04-25 14:32:25
发表了文章
2022-04-25 14:32:25
 发表了文章
2022-04-25 14:29:01
发表了文章
2022-04-25 14:29:01
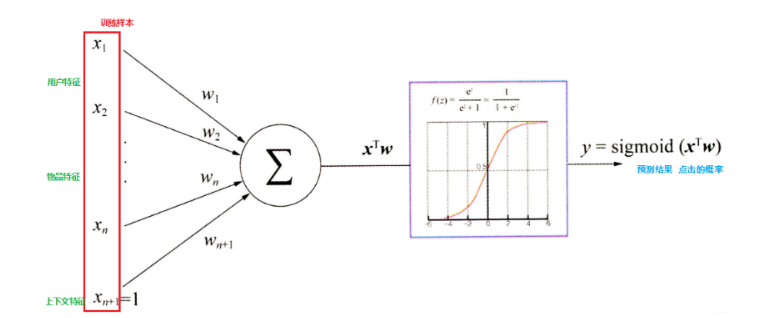 发表了文章
2022-04-24 20:34:35
发表了文章
2022-04-24 20:34:35
 发表了文章
2022-04-24 20:29:00
发表了文章
2022-04-24 20:29:00
 发表了文章
2022-04-24 20:16:25
发表了文章
2022-04-24 20:12:32
发表了文章
2022-04-24 20:16:25
发表了文章
2022-04-24 20:12:32
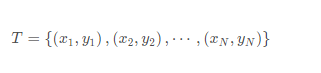 发表了文章
2022-04-24 19:41:19
发表了文章
2022-04-24 19:41:19
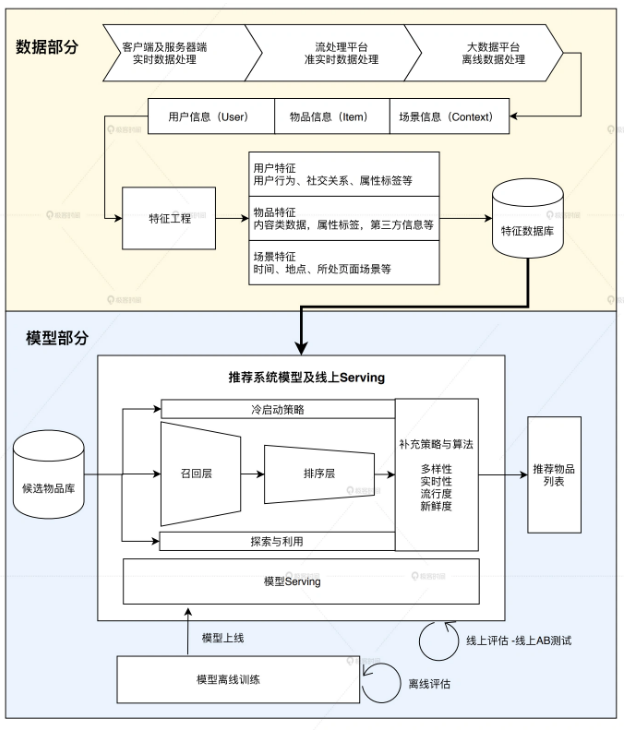 发表了文章
2022-04-24 19:34:02
发表了文章
2022-04-24 19:34:02
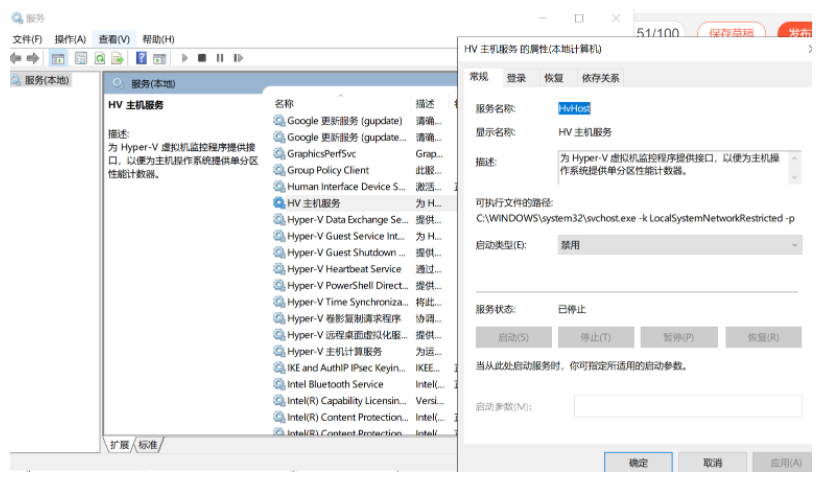 发表了文章
2022-04-24 19:23:36
发表了文章
2022-04-24 19:23:36
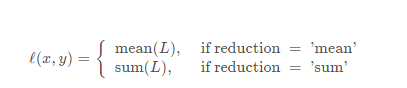 发表了文章
2022-04-24 13:10:33
发表了文章
2022-04-24 13:10:33
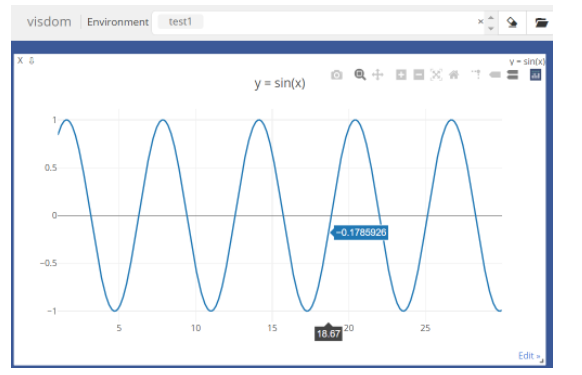 发表了文章
2022-04-24 13:08:00
发表了文章
2022-04-24 13:08:00
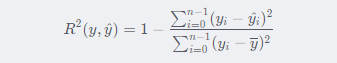 发表了文章
2022-04-24 13:03:20
发表了文章
2022-04-24 13:03:20
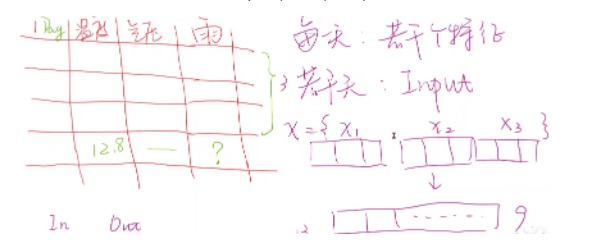 发表了文章
2022-04-24 12:55:05
发表了文章
2022-04-24 12:55:05
 发表了文章
2022-04-24 12:24:31
发表了文章
2022-04-24 11:36:28
发表了文章
2022-04-24 12:24:31
发表了文章
2022-04-24 11:36:28
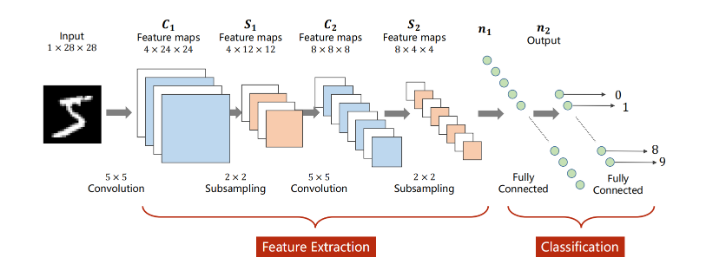 发表了文章
2022-04-24 02:39:18
发表了文章
2022-04-24 02:39:18
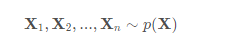 发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28
发表了文章
2022-04-28




