阿里云开发者

已加入开发者社区1029天
勋章

MVP_Star
MVP_Star

阿里博主
阿里博主

学习博主
学习博主

门派掌门
门派掌门




粉丝




技术能力
兴趣领域
- Java
- 数据库
擅长领域
技术认证
暂时未有相关云产品技术能力~
暂无个人介绍
暂无精选文章
暂无更多信息
2025年04月
-
04.03 13:54:16
 发表了文章
2025-04-03 13:54:16
发表了文章
2025-04-03 13:54:16
全模态模型Qwen2.5-Omni开源,7B尺寸实现全球最强性能
通义千问Qwen2.5-Omni-7B正式开源,作为首个端到端全模态大模型,支持文本、图像、音频和视频等多种输入形式,实时生成文本与自然语音合成输出。它在多模态融合任务测评中刷新纪录,性能远超同类模型。Qwen2.5-Omni采用Thinker-Talker双核架构,实现语义理解与语音生成高效协同,以小尺寸7B参数让全模态大模型广泛应用成为可能,现已在魔搭社区和Hugging Face同步开源。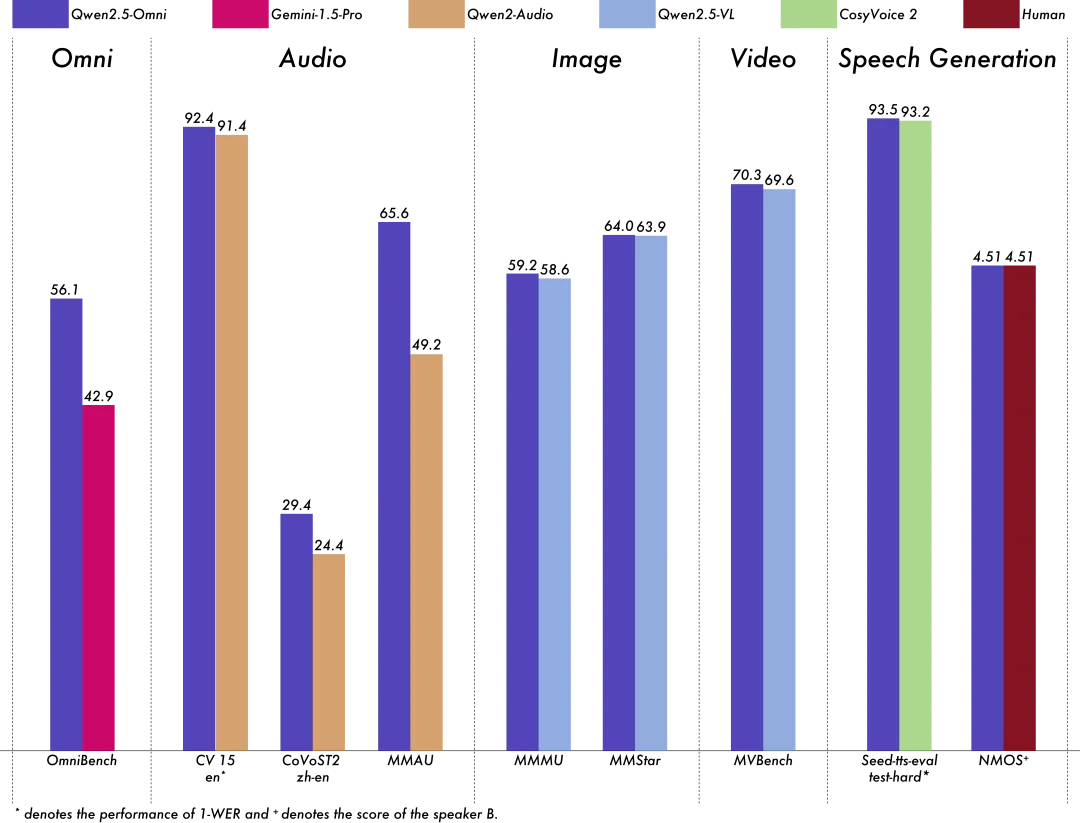
2025年03月
-
03.28 11:40:59发表了文章
2025-03-28 11:40:59
如何与AI结对编程:我与AI的8000行代码实践
作者分享了跟 AI 协作的一些经验,使用中如何对 AI 输入和反馈,经过磨合后,工作效率会大大提升。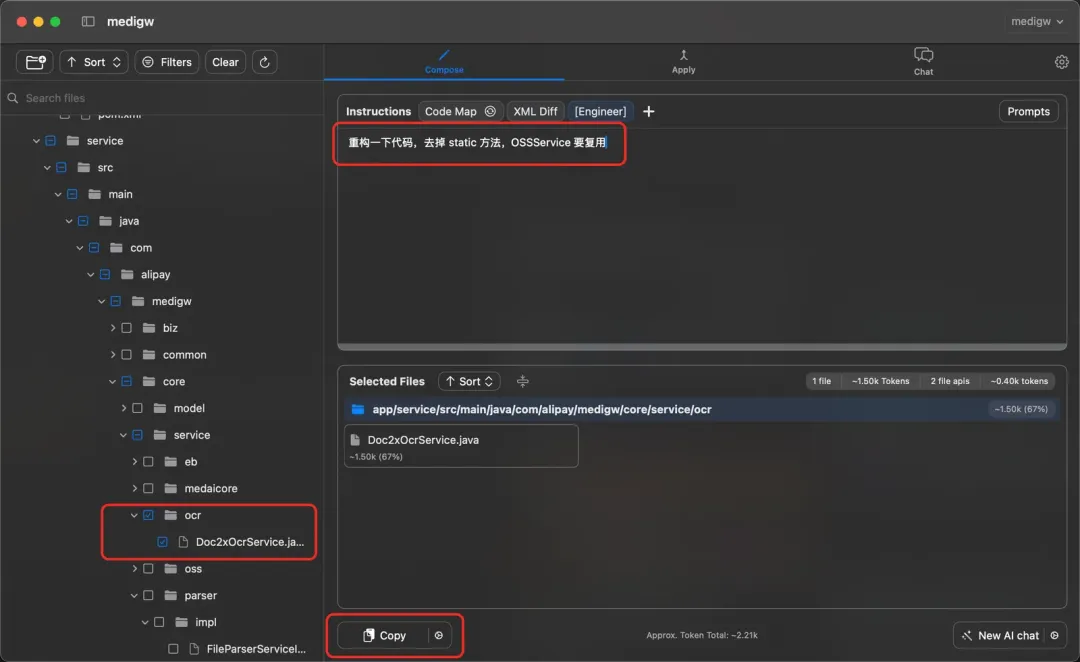
-
03.28 11:36:34发表了文章
2025-03-28 11:36:34
架构革新:揭示卓越性能与高可扩展的共赢秘诀
为了构建现代化的可观测数据采集器LoongCollector,iLogtail启动架构通用化升级,旨在提供高可靠、高可扩展和高性能的实时数据采集和计算服务。然而,通用化的过程总会伴随性能劣化,本文重点介绍LoongCollector的性能优化之路,并对通用化和高性能之间的平衡给出见解。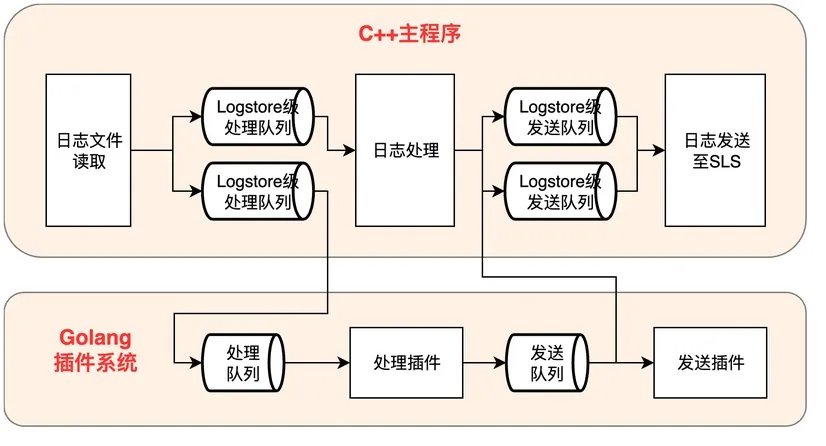
-
03.28 11:29:58发表了文章
2025-03-28 11:29:58
一文了解DeepSeek及应用场景
本文详细介绍了DeepSeek及其应用场景,涵盖了大模型的发展历程、基本原理和分类(通用与推理模型)。文章分析了DeepSeek的具体特性、性能优势、低成本训练与调用特点,以及其技术路线(如MoE、MLA架构),并与竞品进行了对比。此外,还探讨了DeepSeek在金融风控等领域的应用前景。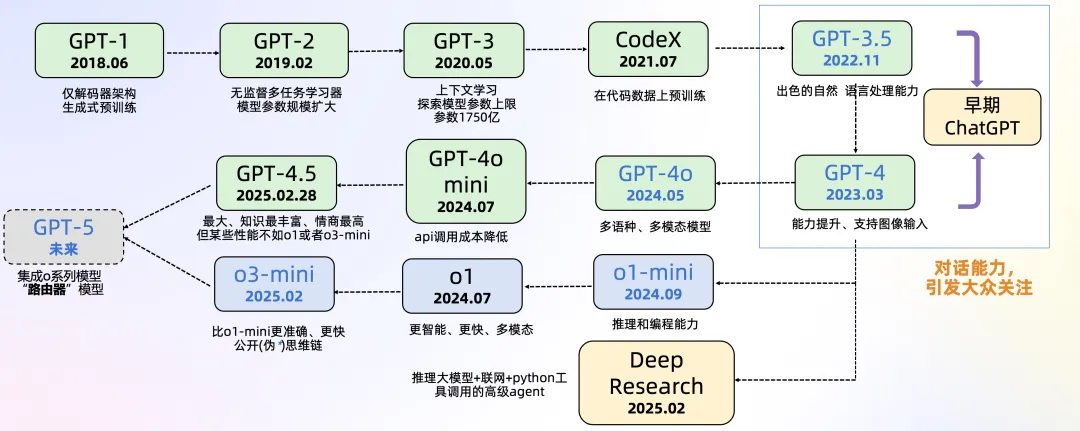
-
03.28 11:11:48发表了文章
2025-03-28 11:11:48
仅3步!即刻拥有 QwQ-32B,性能比肩全球最强开源模型
本文介绍如何将QwQ-32B开源模型部署到阿里云函数计算FC,并通过云原生应用开发平台CAP实现Ollama和Open WebUI两个FC函数的部署。Ollama负责托管QwQ-32B-GGUF模型,Open WebUI提供用户交互界面。借助CAP平台,用户可快速完成模型部署,无需关注底层资源管理与运维问题,专注于应用创新与开发。CAP提供免运维、弹性伸缩及高可用性的高效开发环境,并采用按量付费模式降低资源成本。方案使用华北2(北京)地域,默认配置部署,预计耗时10~12分钟。体验后建议清理资源以避免额外费用。 -
03.28 11:01:09发表了文章
2025-03-28 11:01:09
AI联网搜索时的prompt小技巧
本文详细介绍了如何利用AI工具,特别是那些具有深度联网搜索能力的大模型,来提高信息检索的效率和准确性。
-
03.27 17:20:47发表了文章
2025-03-27 17:20:47
大模型联网搜索的短板与突破之路
本文作者详细分析了当前大模型在联网搜索功能中存在的几个主要问题,并提供了具体的案例和解决方案。
-
03.27 17:06:52发表了文章
2025-03-27 17:06:52
优雅的参数校验,告别冗余if-else
本文介绍了在 Java Spring Boot 开发中如何使用 JSR 303 和 Hibernate Validator 进行参数校验,以避免冗余的if-else判断。文章涵盖了基本注解的使用、全局异常处理、分组校验、嵌套对象校验、快速失败配置以及自定义校验规则等实用技巧。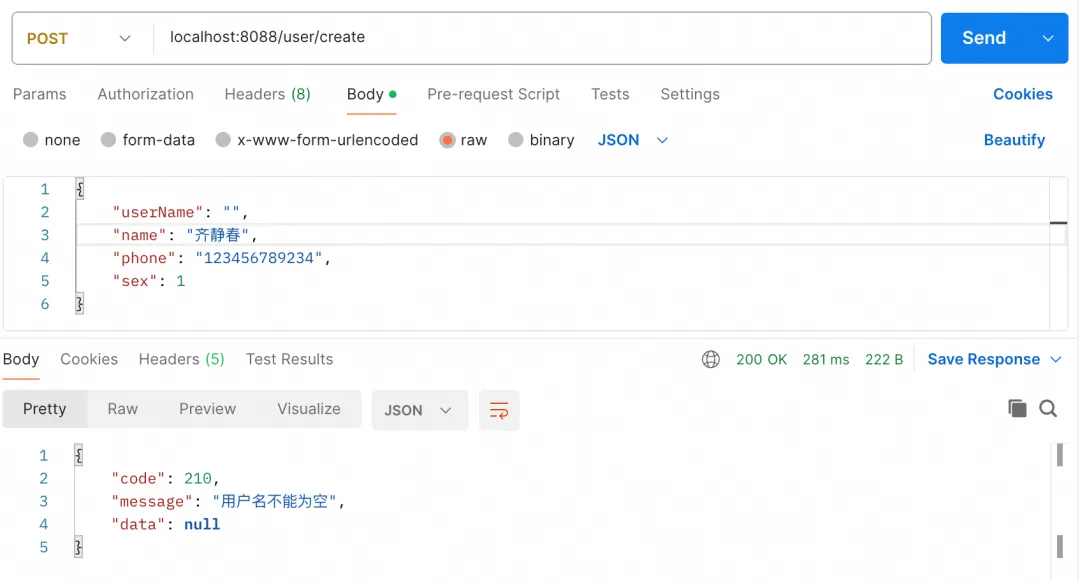
-
03.27 15:32:45发表了文章
2025-03-27 15:32:45
MCP:跨越AI模型与现实的桥梁
本文主要围绕AI技术的进步,特别是Anthropic的Claude 3.7 Sonnet模型在逻辑推理、代码生成和复杂任务执行方面的能力提升及其应用场景。
-
03.27 15:24:14发表了文章
2025-03-27 15:24:14
利用DeepSeek帮我做金融理财
本篇文章将介绍如何搭建一套基于 XXL-JOB + Deepseek 的定时数据分析系统,帮你做一个智能的金融理财助手。
-
03.21 16:33:59发表了文章
2025-03-21 16:33:59
Manus的技术实现原理浅析与简单复刻
作者参考网络相关信息并加上个人理解,对Manus的技术实现原理进行深入分析,并做了一个简单版本的复刻,欢迎大家在评论区互相交流探讨~
-
03.21 16:27:16发表了文章
2025-03-21 16:27:16
性能比肩最强开源,QwQ-32B一键部署,百万Token免费送!
本文介绍如何通过百炼平台调用QwQ-32B开源模型。百炼平台提供的标准化 API 接口,免去了自行构建模型服务基础设施的麻烦,并支持负载均衡及自动扩缩容,确保了 API 调用的高稳定性。此外,结合使用 Chatbox 可视化界面客户端,用户无需进行命令行操作,即可通过直观的图形界面轻松完成 QwQ 模型的配置与使用。 -
03.21 16:24:32发表了文章
2025-03-21 16:24:32
解决隐式内存占用难题
本文详细介绍了在云原生和容器化部署环境中,内存管理和性能优化所面临的挑战及相应的解决方案。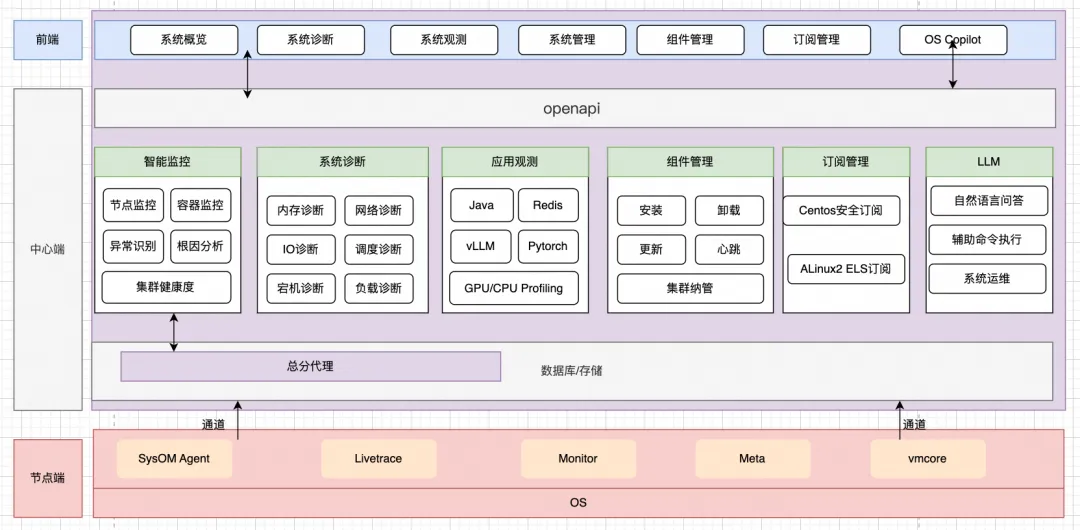
-
03.21 15:56:23发表了文章
2025-03-21 15:56:23
监控vLLM等大模型推理性能
本文将深入探讨 AI 推理应用的可观测方案,并基于 Prometheus 规范提供一套完整的指标观测方案,帮助开发者构建稳定、高效的推理应用。
-
03.21 15:35:31发表了文章
2025-03-21 15:35:31
23招教你掌握大模型提示词技巧
当模型越来越懂人话,我们还需要学习提示语(Prompt)吗?本文总结了23招向AI提问的好方式。
-
03.21 14:55:55发表了文章
2025-03-21 14:55:55
AI 推理场景的痛点和解决方案
一个典型的推理场景面临的问题可以概括为限流、负载均衡、异步化、数据管理、索引增强 5 个场景。通过云数据库 Tair 丰富的数据结构可以支撑这些场景,解决相关问题,本文我们会针对每个场景逐一说明。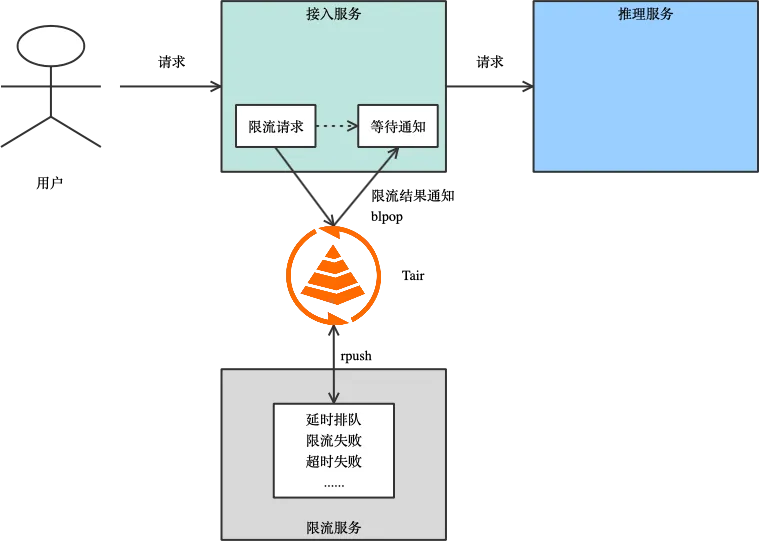
-
03.21 14:41:35发表了文章
2025-03-21 14:41:35
主流多智能体框架设计原理
本文描述了关于智能体(Agents)和多智能体系统(Multi-Agent Systems, MAS)的详尽介绍,涵盖了从定义、分类到具体实现框架的多个方面。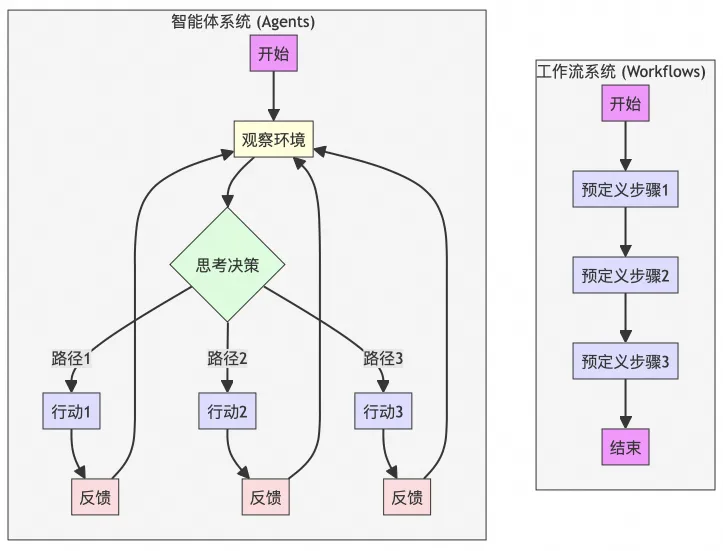
-
03.21 14:03:07发表了文章
2025-03-21 14:03:07
在IDEA中借助满血版 DeepSeek 提高编码效率
通义灵码2.0引入了DeepSeek V3与R1模型,新增Qwen2.5-Max和QWQ模型,支持个性化服务切换。阿里云发布开源推理模型QwQ-32B,在数学、代码及通用能力上表现卓越,性能媲美DeepSeek-R1,且部署成本低。AI程序员功能涵盖表结构设计、前后端代码生成、单元测试与错误排查,大幅提升开发效率。跨语言编程示例中,成功集成DeepSeek-R1生成公告内容。相比1.0版本,2.0支持多款模型,丰富上下文类型,具备多文件修改能力。总结显示,AI程序员生成代码准确度高,但需参考现有工程风格以确保一致性,错误排查功能强大,适合明确问题描述场景。相关链接提供下载与原文参考。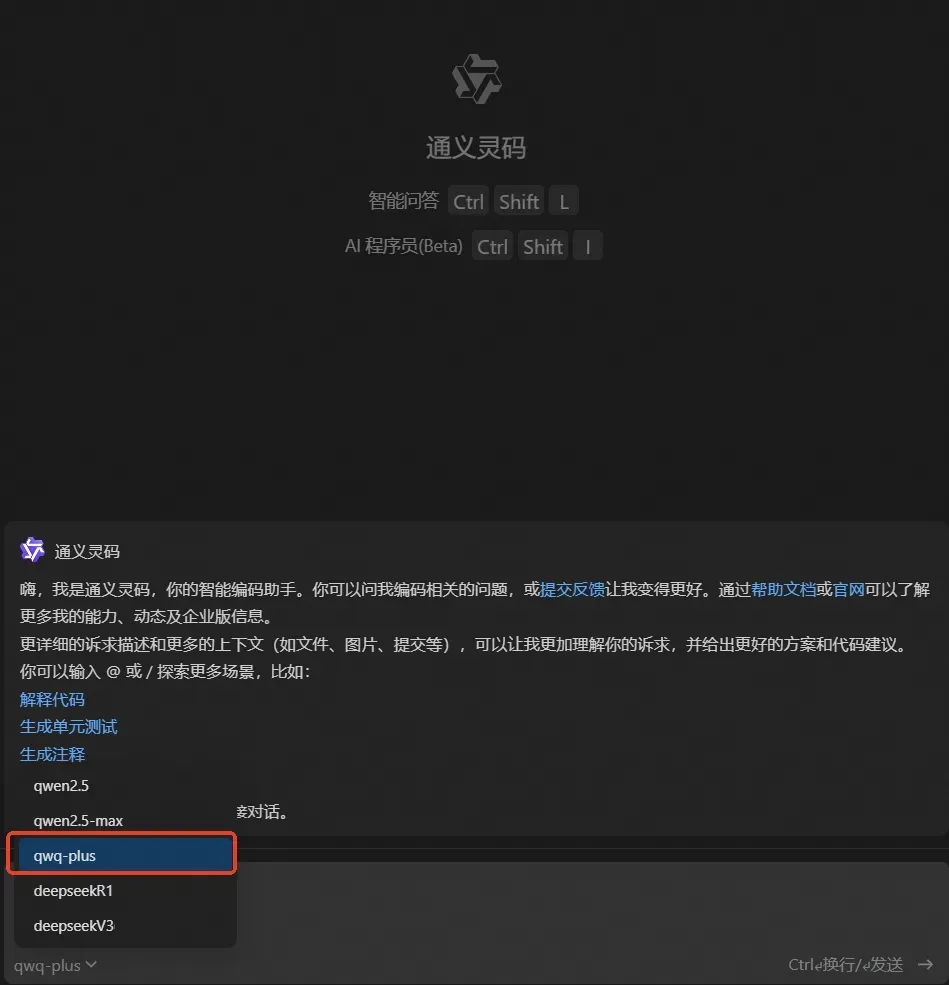
-
03.19 18:07:31
 发布了视频
2025-03-19 18:07:31
发布了视频
2025-03-19 18:07:31
AI数字人直播,上云新势力
AI数字人直播,上云新势力
-
03.19 18:05:55发布了视频
2025-03-19 18:05:55
牧原联合通义大模型,打造智能兽医问诊助手
牧原联合通义大模型,打造智能兽医问诊助手
-
03.14 16:19:31发表了文章
2025-03-14 16:19:31
详解大模型应用可观测全链路
阿里云可观测解决方案从几个方面来尝试帮助使用 QwQ、Deepseek 的 LLM 应用开发者来满足领域化的可观测述求。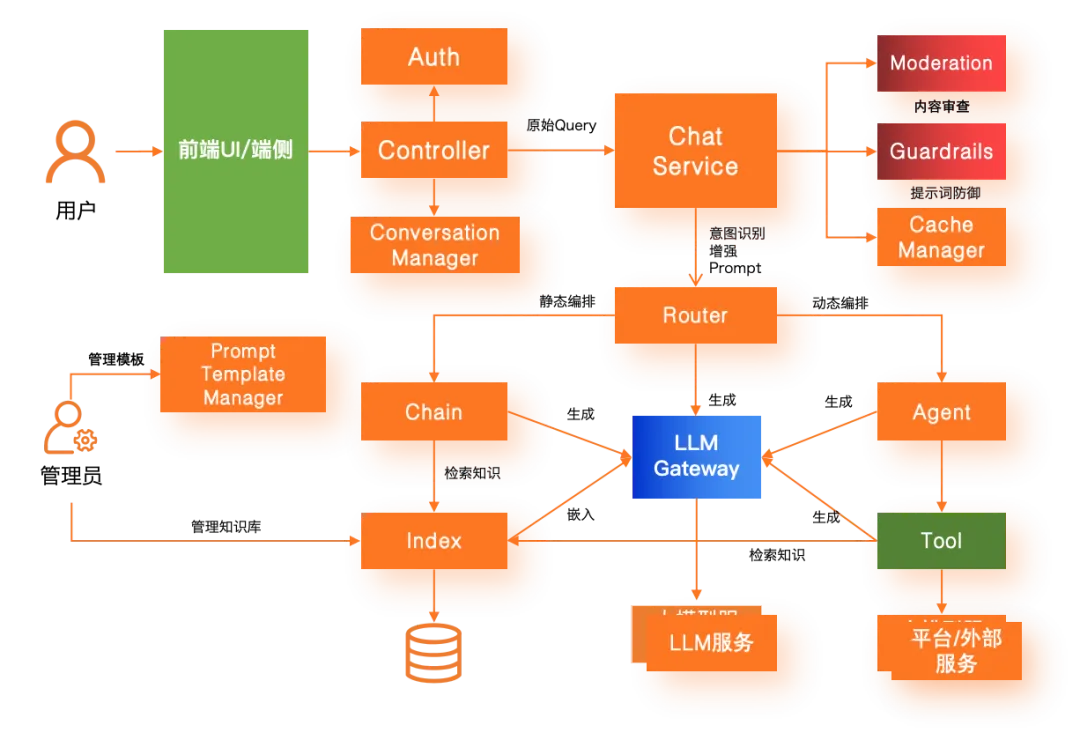
-
03.14 16:07:48发表了文章
2025-03-14 16:07:48
本地部署QWQ显存不够怎么办?
3月6日阿里云发布并开源了全新推理模型通义千问 QwQ-32B,在一系列权威基准测试中,千问QwQ-32B模型表现异常出色,几乎完全超越了OpenAI-o1-mini,性能比肩Deepseek-R1,且部署成本大幅降低。并集成了与智能体 Agent 相关的能力,够在使用工具的同时进行批判性思考,并根据环境反馈调整推理过程。阿里云人工智能平台 PAI-Model Gallery 现已经支持一键部署 QwQ-32B,本实践带您部署体验专属 QwQ-32B模型服务。 -
03.14 16:02:12发表了文章
2025-03-14 16:02:12
万字长文讲透 RAG在实际落地场景中的优化
本文主要围绕DB-GPT应用开发框架如何在实际落地场景做RAG优化。
-
03.14 15:17:22发表了文章
2025-03-14 15:17:22
2种方式1键部署,快速体验QWQ-32B 模型
QwQ-32B 推理模型现已正式发布并开源,其卓越性能在多项基准测试中表现突出,与全球领先模型比肩。阿里云函数计算 FC 提供算力支持,Serverless+AI 云原生应用开发平台 CAP 提供两种部署方式:模型服务和应用模板,帮助用户快速部署 QwQ-32B 系列模型。用户可通过一键部署体验对话功能或以 API 形式接入 AI 应用。文档详细介绍了前置准备、部署步骤及验证方法,并提供删除项目指南以降低费用。来源:阿里云开发者公众号;作者:肯梦、折原。
-
03.14 15:11:35发表了文章
2025-03-14 15:11:35
从零开始的DeepSeek微调训练实战(SFT)
本文重点介绍使用微调框架unsloth,围绕DeepSeek R1 Distill 7B模型进行高效微调,并介绍用于推理大模型高效微调的COT数据集的创建和使用方法,并在一个medical-o1-reasoning-SFT数据集上完成高效微调实战,并最终达到问答风格优化&知识灌注目的。
-
03.14 14:47:29发表了文章
2025-03-14 14:47:29
大模型无缝切换,QwQ-32B和DeepSeek-R1 全都要
通义千问最新推出的QwQ-32B推理模型,拥有320亿参数,性能媲美DeepSeek-R1(6710亿参数)。QwQ-32B支持在小型移动设备上本地运行,并可将企业大模型API调用成本降低90%以上。本文介绍了如何通过Higress AI网关实现DeepSeek-R1与QwQ-32B之间的无缝切换,涵盖环境准备、模型接入配置及客户端调用示例等内容。此外,还详细探讨了Higress AI网关的多模型服务、消费者鉴权、模型自动切换等高级功能,帮助企业解决TPS与成本平衡、内容安全合规等问题,提升大模型应用的稳定性和效率。
-
03.14 14:38:15发表了文章
2025-03-14 14:38:15
Transformer到底解决什么问题?
本文希望围绕“Transformer到底是解决什么问题的”这个角度,阐述NLP发展以来遇到的关键问题和解法,通过这些问题引出Transformer实现原理,帮助初学者理解。
-
03.14 14:22:48发表了文章
2025-03-14 14:22:48
从零开始教你打造一个MCP客户端
Anthropic开源了一套MCP协议,它为连接AI系统与数据源提供了一个通用的、开放的标准,用单一协议取代了碎片化的集成方式。本文教你从零打造一个MCP客户端。 -
03.14 14:13:21发表了文章
2025-03-14 14:13:21
AI 世界生存手册(二):从LR到DeepSeek,模型慢慢变大了,也变强了
大家都可以通过写 prompt 来和大模型对话,那大模型之前的算法是怎样的,算法世界经过了哪些比较关键的发展,最后为什么是大模型这条路线走向了 AGI,作者用两篇文章共5.7万字详细探索一下。 第一篇文章指路👉《AI 世界生存手册(一):从LR到DeepSeek,模型慢慢变大了,也变强了》
-
03.11 10:15:42发表了文章
2025-03-11 10:15:42
QwQ-32B一键部署,真正的0代码,0脚本,0门槛
阿里云发布的QwQ-32B模型通过强化学习显著提升了推理能力,核心指标达到DeepSeek-R1满血版水平。用户可通过阿里云系统运维管理(OOS)一键部署OpenWebUI+Ollama方案,轻松将QwQ-32B模型部署到ECS,或连接阿里云百炼的在线模型。整个过程无需编写代码,全部在控制台完成,适合新手操作。
-
03.06 18:14:13发表了文章
2025-03-06 18:14:13
AI 世界生存手册(一):从LR到DeepSeek,模型慢慢变大了,也变强了
大家都可以通过写 prompt 来和大模型对话,那大模型之前的算法是怎样的,算法世界经过了哪些比较关键的发展,最后为什么是大模型这条路线走向了 AGI,作者用两篇文章共5.7万字详细探索一下。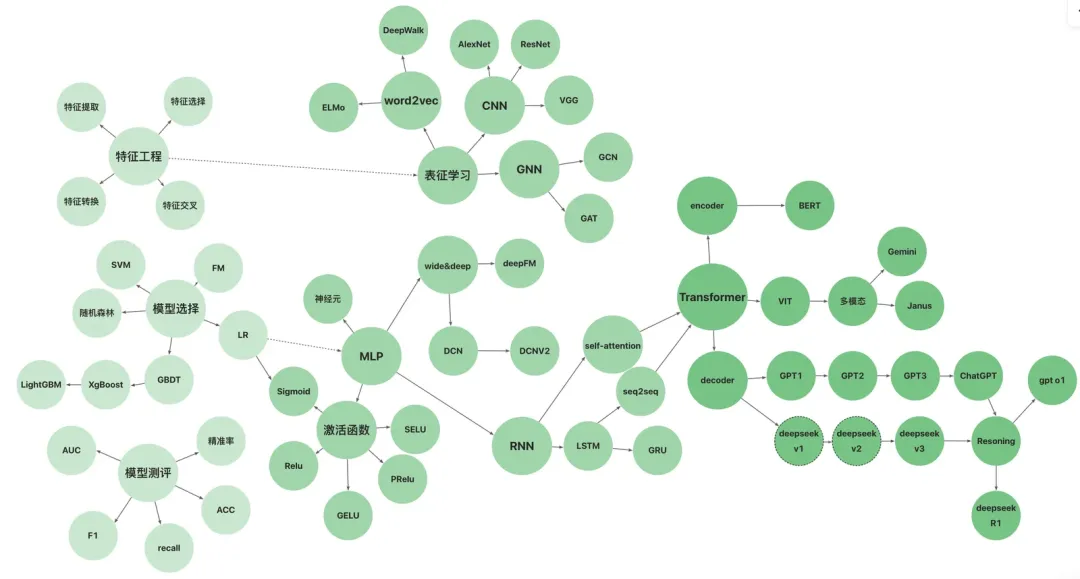
-
03.06 17:59:22发表了文章
2025-03-06 17:59:22
schedule:原来还可以这样让进程让出 CPU?
文章主要讲述通过模拟时钟中断和调度事件来优化和测试虚拟机监控器(VMM)的方法,包括流程设计、寄存器状态的保存与恢复、硬件中断处理规范等细节。
-
03.06 17:52:24发表了文章
2025-03-06 17:52:24
JDK21有没有什么稳定、简单又强势的特性?
这篇文章主要介绍了Java虚拟线程的发展及其在AJDK中的实现和优化。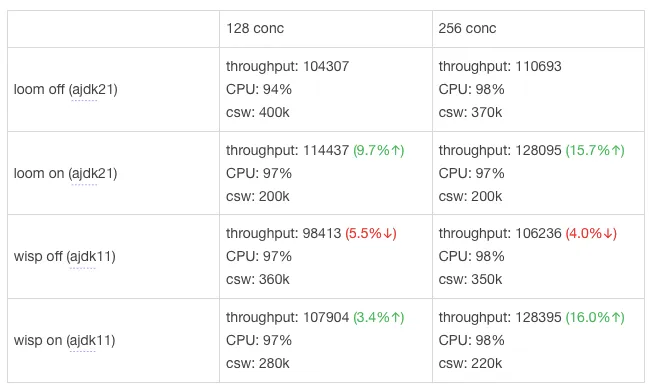
-
03.06 17:30:45发表了文章
2025-03-06 17:30:45
满血上阵,DeepSeek x 低代码创造专属知识空间
本文介绍了如何结合阿里云百炼和魔笔平台,快速构建一个智能化的专属知识空间。通过利用DeepSeek R1等先进推理模型,实现高效的知识管理和智能问答系统。 5. **未来扩展**:探讨多租户隔离、终端用户接入等高级功能,以适应更大规模的应用场景。 通过这些步骤,用户可以轻松创建一个功能全面、性能卓越的知识管理系统,极大提升工作效率和创新能力。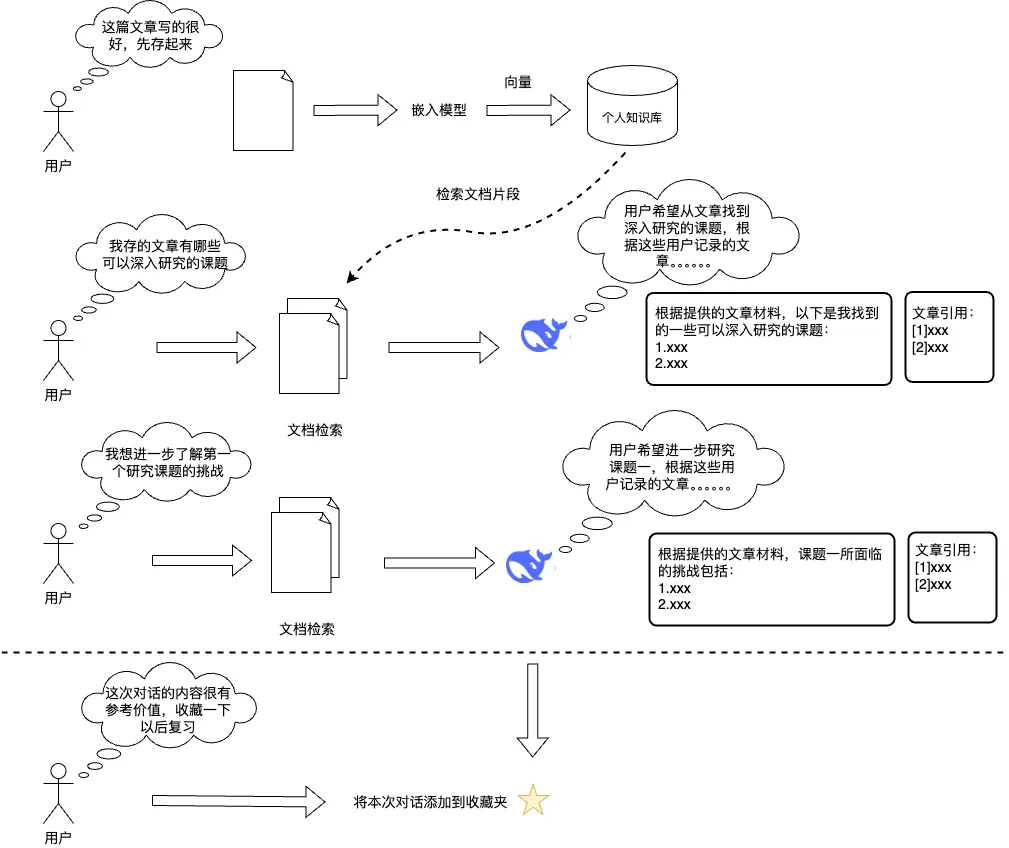
-
03.06 17:02:27发表了文章
2025-03-06 17:02:27
校招阿里这三年,聊点非技术的
作者总结了在阿里的三年时间中所收获的宝贵经验和成长感悟。 -
03.06 16:57:47发表了文章
2025-03-06 16:57:47
技术小白如何利用DeepSeek半小时开发微信小程序?
通过通义灵码的“AI程序员”功能,即使没有编程基础也能轻松创建小程序或网页。借助DeepSeek V3和R1满血版模型,用户只需用自然语言描述需求,就能自动生成代码并优化程序。例如,一个文科生仅通过描述需求就成功开发了一款记录日常活动的微信小程序。此外,通义灵码还提供智能问答模式,帮助用户解决开发中的各种问题,极大简化了开发流程,让普通人的开发体验更加顺畅。
-
03.06 16:18:27发表了文章
2025-03-06 16:18:27
ComfyUI:搭积木一样构建专属于自己的AIGC工作流(保姆级教程)
通过本篇文章,你可以了解并实践通过【ComfyUI】构建自己的【文生图】和【文生动图】工作流。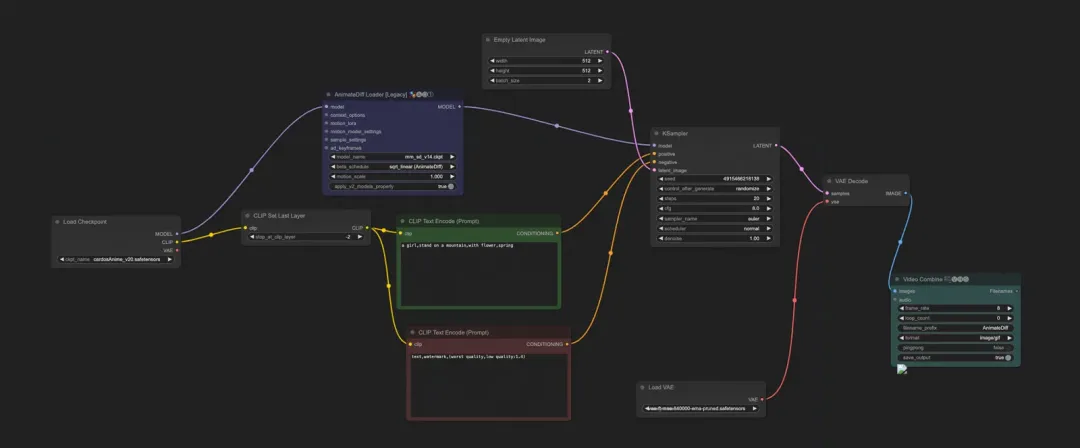
-
03.06 15:58:37发表了文章
2025-03-06 15:58:37
一篇关于DeepSeek模型先进性的阅读理解
本文以DeepSeek模型为核心,探讨了其技术先进性、训练过程及行业影响。首先介绍DeepSeek的快速崛起及其对AI行业的颠覆作用。DeepSeek通过强化学习(RL)实现Time Scaling Law的新范式,突破了传统大模型依赖算力和数据的限制,展现了集成式创新的优势。文章还提到开源的重要性以及数据作为制胜法宝的关键地位,同时警示了业务发展中安全滞后的问题。
-
03.06 15:52:45发表了文章
2025-03-06 15:52:45
一招解决数据库中报表查询慢的痛点
本文旨在解决传统数据库系统如PostgreSQL在处理复杂分析查询时面临的性能瓶颈问题。
2025年02月
-
02.28 16:10:05发表了文章
2025-02-28 16:10:05
使用A10单卡24G复现DeepSeek R1强化学习过程
本文描述DeepSeek的三个模型的学习过程,其中DeepSeek-R1-Zero模型所涉及的强化学习算法,是DeepSeek最核心的部分之一会重点展示。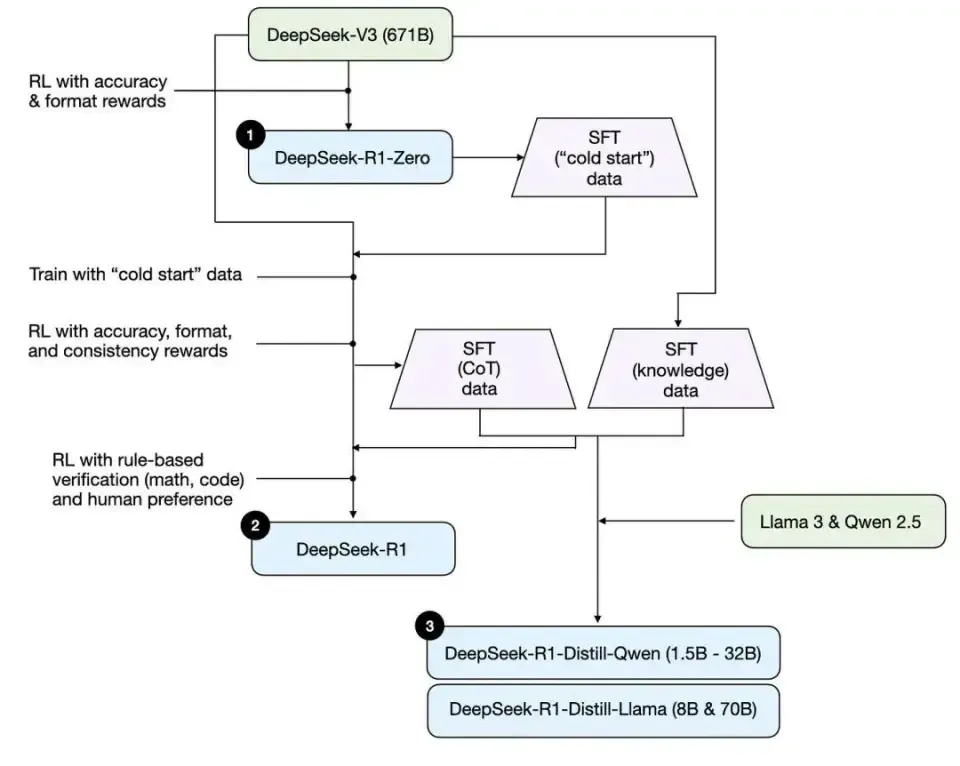
-
02.28 15:53:32发表了文章
2025-02-28 15:53:32
大模型推理主战场:通信协议的标配
DeepSeek加速了模型平权,大模型推理需求激增,性能提升主战场从训练转向推理。SSE(Server-Sent Events)和WebSocket成为大模型应用的标配网络通信协议。SSE适合服务器单向推送实时数据,如一问一答场景;WebSocket支持双向实时通信,适用于在线游戏、多人协作等高实时性场景。两者相比传统HTTPS协议,能更好地支持流式输出、长时任务处理和多轮交互,满足大模型应用的需求。随着用户体量扩大,网关层面临软件变更、带宽成本及恶意攻击等挑战,需通过无损上下线、客户端重连机制、压缩算法及安全防护措施应对。
-
02.28 15:30:22发表了文章
2025-02-28 15:30:22
IDEA中使用DeepSeek满血版的手把手教程来了!
本文主要介绍阿里云推出的AI编码助手——通义灵码在代码编写、智能问答、bug修复等方面的功能。
-
02.28 15:27:30发表了文章
2025-02-28 15:27:30
LLM 联网搜索,到底是咋回事?
本文展示从零开始搭建一个本地聊天助手的过程,涵盖了模型部署、搜索逻辑设计、内容提取与整合等关键步骤,特别介绍了如何让模型具备联网搜索能力。
-
02.28 15:23:52发表了文章
2025-02-28 15:23:52
我是如何基于 DeepSeek-R1 构建出高效学习Agent的?
本文介绍了名为“通俗讲解专家”的高效学习智能体,该智能体基于 DeepSeek-R1 模型构建,旨在通过生活化例子、概念讲解、简单记法和图示(SVG)四种方式帮助用户快速掌握复杂概念。文章详细描述了“通俗讲解专家”的提示词框架,包括角色定位、技能设定和输出规范,并提供了具体的使用方法。
-
02.28 11:38:43发表了文章
2025-02-28 11:38:43
进行GPU算力管理
本篇主要简单介绍了在AI时代由‘大参数、大数据、大算力’需求下,对GPU算力管理和分配带来的挑战。以及面对这些挑战,GPU算力需要从单卡算力管理、单机多卡算力管理、多机多卡算力管理等多个方面发展出来的业界通用的技术。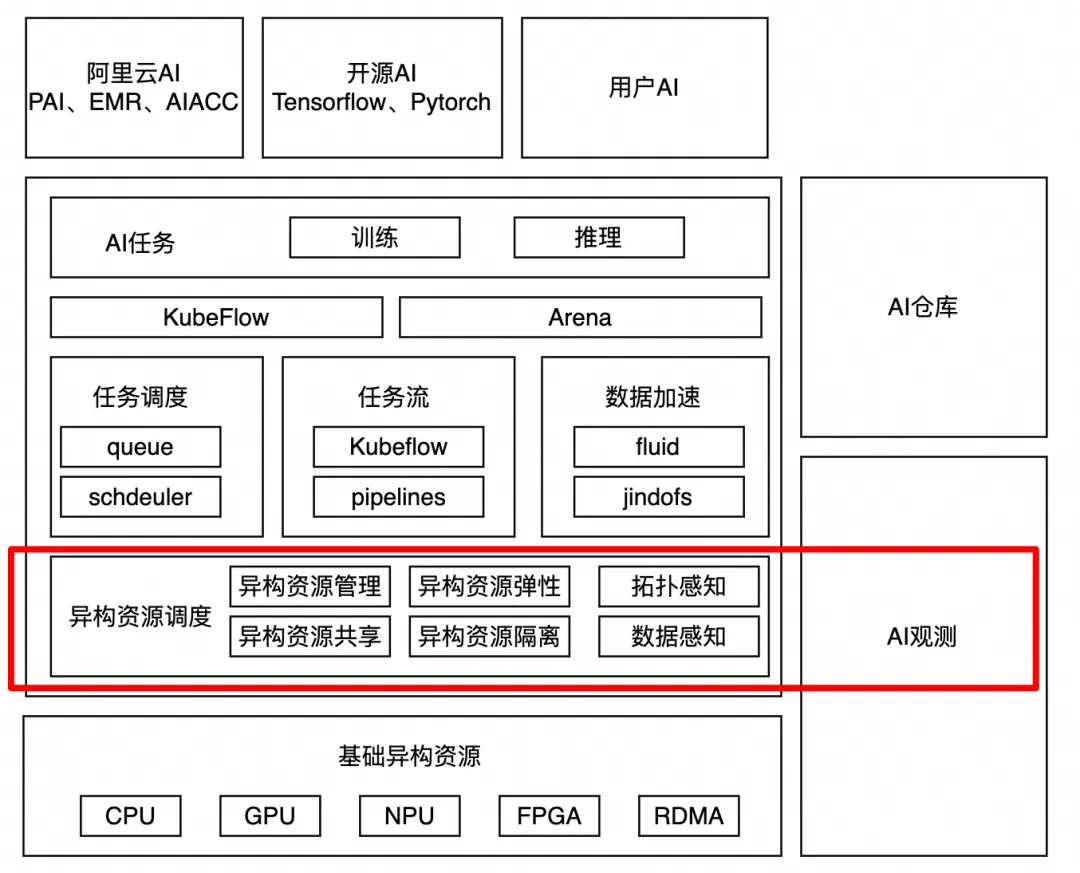
-
发表了文章
2025-11-06
AI时代,我们为何重写规则引擎?—— QLExpress4 重构之路
-
发表了文章
2025-11-06
TinyAI :全栈式轻量级 AI 框架
-
发表了文章
2025-11-06
容器可观测新视角: SysOM延时监控助力定位业务抖动原因
-
发表了文章
2025-11-06
Midscene.js 实战与源码剖析:如何重塑 UI 自动化
-
发表了文章
2025-11-06
ReAct范式深度解析:从理论到LangGraph实践
-
发表了文章
2025-11-06
如何让Agent更符合预期?基于上下文工程和多智能体构建云小二Aivis的十大实战经验
-
发表了文章
2025-10-30
AI出码率70%+的背后:高德团队如何实现AI研发效率的量化与优化
-
发表了文章
2025-10-30
在性能优化时,如何避免盲人摸象
-
发表了文章
2025-10-30
基于Spring AI Alibaba 的 DeepResearch 架构与实践
-
发表了文章
2025-10-30
让Agent系统更聪明之前,先让它能被信任
-
发表了文章
2025-10-23
《AI大模型时代老板必修课》
-
发表了文章
2025-10-23
AI Agent的未来之争:任务规划,该由人主导还是AI自主?——阿里云RDS AI助手的最佳实践
-
发表了文章
2025-10-23
从0到1:天猫AI测试用例生成的实践与突破
-
发表了文章
2025-10-23
AI Coding实践:CodeFuse + prompt 从系分到代码
-
发表了文章
2025-10-23
C3仓库AI代码门禁通用实践:基于Qwen3-Coder+RAG的代码评审
-
发表了文章
2025-10-23
开源新发布|PolarDB-X v2.4.2开源生态适配升级
-
发表了文章
2025-10-23
【智造】AI应用实战:6个agent搞定复杂指令和工具膨胀
-
发表了文章
2025-10-17
揭秘 Claude Code:AI 编程入门、原理和实现,以及免费替代 iFlow CLI
-
发表了文章
2025-10-17
从人工到AI驱动:天猫测试全流程自动化变革实践
-
发表了文章
2025-10-17
Qoder + ADB Supabase :5分钟GET超火AI手办生图APP
滑动查看更多
-
提交了问题
2024-03-14
程序员为什么不能一次性写好,需要一直改Bug?
-
提交了问题
2024-03-08
让 AI 写代码,能做出什么样的项目?
-
提交了问题
2024-02-21
开动脑洞,你最想用Sora生成什么样的视频?
-
提交了问题
2024-02-05
如果用你的专业送上新春祝福,会是什么样的?
-
提交了问题
2024-01-18
如何看黄铭钧院士点赞PolarDB,称「云数据库正进入2.0时代,AI与云数据库深度结合大有可为」?
-
提交了问题
2024-01-17
只允许用 AI 写代码,不允许程序员手写,你怎么看这种做法?
-
提交了问题
2023-12-28
你时常焦虑吗?浅聊技术人对抗焦虑的方法
-
提交了问题
2023-12-22
你曾经担任的角色是 CodeReviewer 还是 被 CodeReviewer ?
-
提交了问题
2023-12-14
偏向锁被废弃了?谈谈你背的那些“八股文”
-
提交了问题
2023-12-07
站在业务技术团队的开发视角,你认同“可读性”是代码的第一优先级要求吗?
-
提交了问题
2023-12-01
技术人上下班通勤时间会做些什么?
滑动查看更多
-
 手办会说话?00后女生用AI打破次元壁【请开发者喝咖啡05】发布时间:2025-04-29 17:19:27 视频时长:3分21秒 播放量:227本期开发者,小C。本期AI硬件,赛博大舞台,一款能让角色手办开口说话的智能底座。
手办会说话?00后女生用AI打破次元壁【请开发者喝咖啡05】发布时间:2025-04-29 17:19:27 视频时长:3分21秒 播放量:227本期开发者,小C。本期AI硬件,赛博大舞台,一款能让角色手办开口说话的智能底座。 -
 AI+教育,『少年云助学计划』助力25万乡村师生云上学习发布时间:2025-04-29 17:18:48 视频时长:4分30秒 播放量:266“少年云助学计划”已为全国乡村学校建设300所AI云教室,惠及25万师生,这一数字教育普惠工程,依托AI大模型与云计算等技术,让“少年们”能够走出世界,与全球科学能够真正接轨。
AI+教育,『少年云助学计划』助力25万乡村师生云上学习发布时间:2025-04-29 17:18:48 视频时长:4分30秒 播放量:266“少年云助学计划”已为全国乡村学校建设300所AI云教室,惠及25万师生,这一数字教育普惠工程,依托AI大模型与云计算等技术,让“少年们”能够走出世界,与全球科学能够真正接轨。 -
 支付宝率先接入!魔搭社区上线「MCP广场」与1400款MCP服务发布时间:2025-04-29 17:17:59 视频时长:1分41秒 播放量:4294月15日,中国第一AI开源社区魔搭(ModelScope)推出全新MCP广场,上架千余款热门的MCP服务,包括支付宝、MiniMax等全新MCP服务在魔搭独家首发。魔搭社区为AI开发者提供丰富的MCP服务及调试工具,并支持第三方平台集成和调用,通过开源开放的方式加速Agent及AI应用的创新和落地。
支付宝率先接入!魔搭社区上线「MCP广场」与1400款MCP服务发布时间:2025-04-29 17:17:59 视频时长:1分41秒 播放量:4294月15日,中国第一AI开源社区魔搭(ModelScope)推出全新MCP广场,上架千余款热门的MCP服务,包括支付宝、MiniMax等全新MCP服务在魔搭独家首发。魔搭社区为AI开发者提供丰富的MCP服务及调试工具,并支持第三方平台集成和调用,通过开源开放的方式加速Agent及AI应用的创新和落地。 -
AI数字人直播,上云新势力发布时间:2025-03-19 18:07:31 视频时长:3分36秒 播放量:197国产AI数字人在东南亚“爆红”特看数字人如何通过云电脑重塑生产力
-
牧原联合通义大模型,打造智能兽医问诊助手发布时间:2025-03-19 18:05:56 视频时长:0分44秒 播放量:383央视点赞AI技术! 牧原联合通义大模型,打造智能兽医问诊助手
滑动查看更多