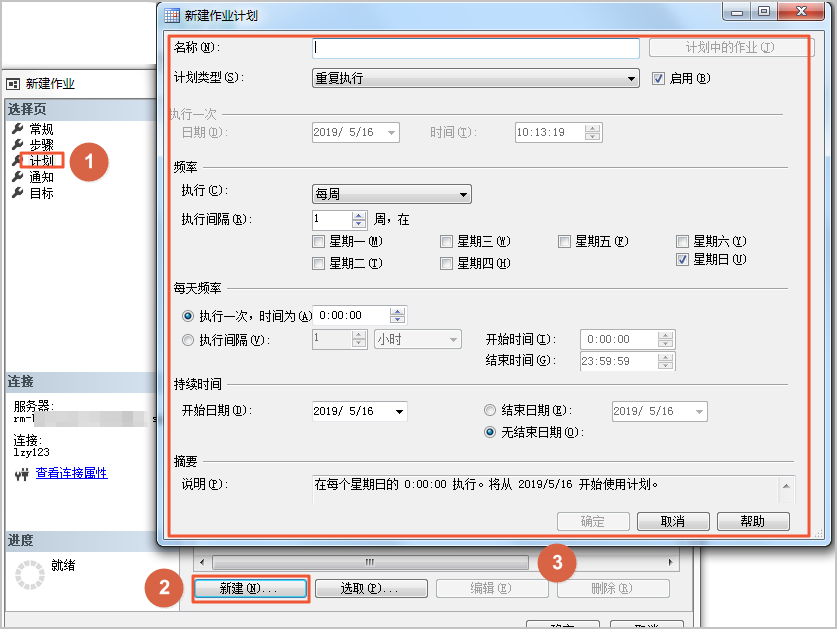
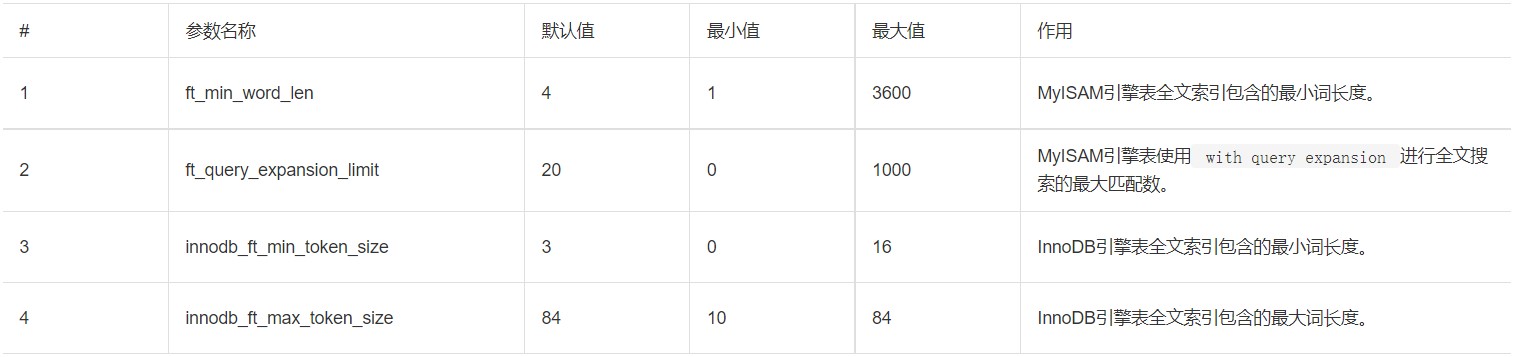
获取Binlog日志
根据实际情况选择合适的Binlog日志获取方法:
远程获取Binlog日志
1、通过客户端连接实例,详情请参见连接实例。
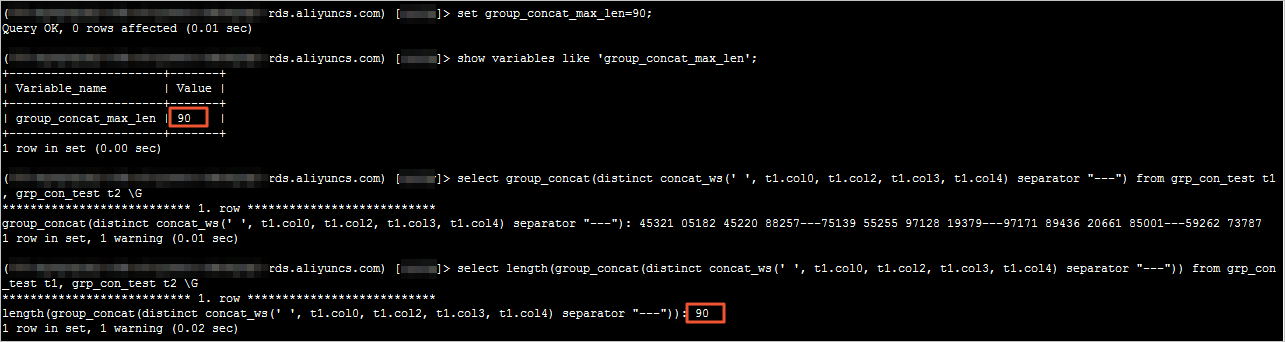
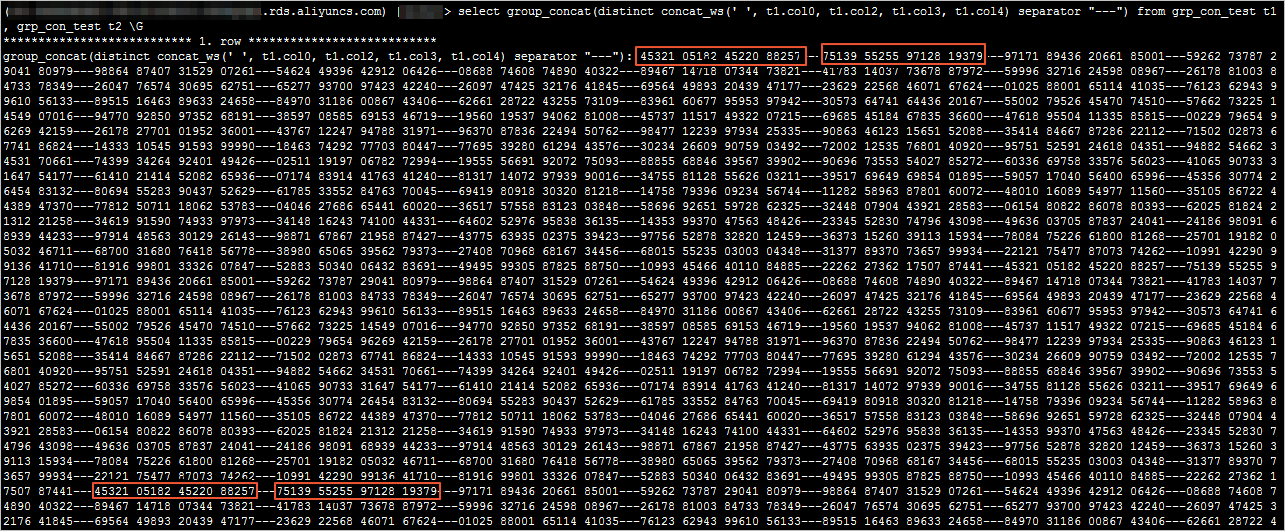
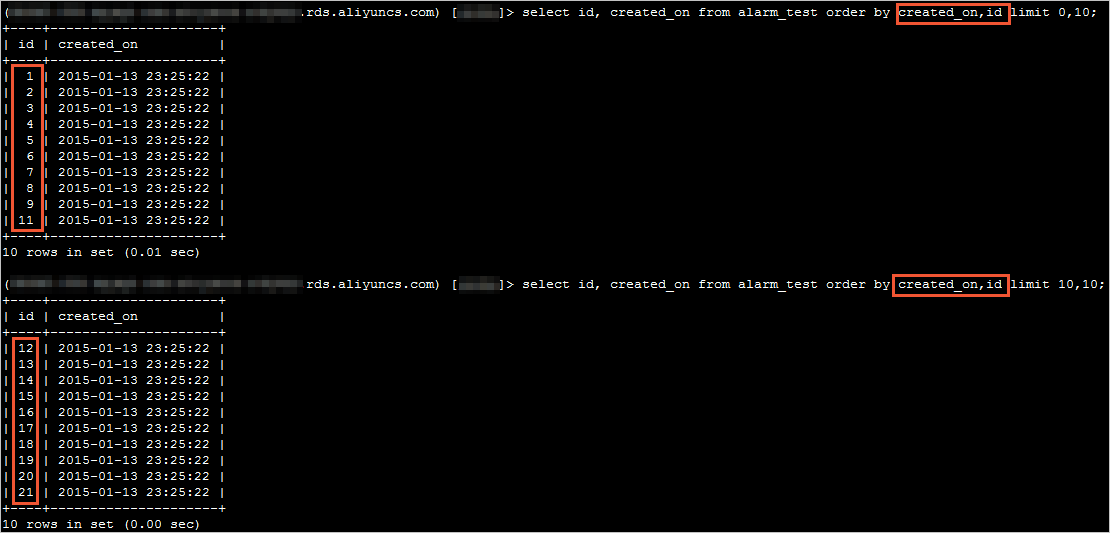
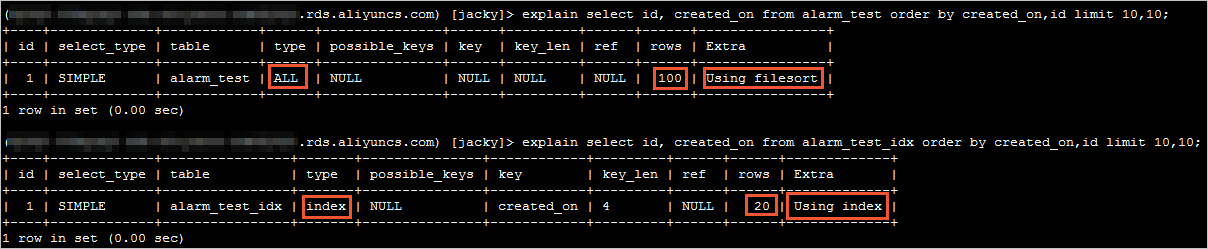
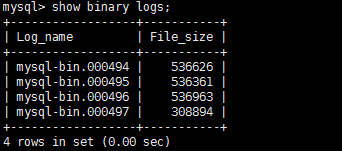
2、执行以下SQL语句,查看并记录logs表中的Log_name值,该值为Binlog日志文件名,例如mysql-bin.xxx。
show binary logs;
系统显示类似如下。
3、根据上一步获取的Binlog文件名,在客户端执行以下命令,远程获取Binlog日志并保存至本地。
mysqlbinlog -u[$User] -p[$Password] -h[$Host] --read-from-remote-server mysql-bin.XXX > [$File_Name]
说明:
[$Host]指云数据库RDS实例远程连接地址。
[$File_Name]远程获取Binlog文件保存在本地的文件名。
[$User]指远程连接使用的用户。
[$Password]远程连接使用的用户密码。
4、执行以下命令,确认远程获取Binlog日志成功。
more [$File_Name]
系统显示类似如下。

控制台直接下载
通过RDS控制台直接下载日志文件,详情请参见下载Binlog日志文件。
mysqlbinlog工具使用介绍
1、在客户端执行以下命令,通过mysqlbinlog工具查看Binlog日志文件内容。
mysqlbinlog -vv --base64-output=decode-rows mysql-bin.XXX | more
说明:
-vv参数为查看具体SQL语句及备注。
--base64-output=decode-rows参数为解析Binlog日志文件。
系统显示类似如下。

2、更多关于Binlog日志的解析,请参见MySQL官方网站。
 cattt
赞 0
评论 0
cattt
赞 0
评论 0
排查方法
当只读实例出现延迟时,可以根据以下排查方法定位问题:
在RDS控制台中查看监控信息,检查只读实例的IOPS,确认只读实例是否存在资源瓶颈。
在RDS控制台查看监控信息,检查只读实例的TPS,确认主实例TPS是否过高。
检查只读实例的Binlog增长量,确定是否存在大事务。
查看慢日志信息,确认是否存在alter,repair和create等DDL操作,详情请参见分析慢日志。
只读实例执行show slave status \G命令,确定是否存在元数据锁。
检查只读实例是否存在无主键表的删除或者更新操作,可以通过在只读实例上执行show engine innodb status\G语句查看,或者执行show open tables语句后,查看输出结果的in_use列的值为1的表。
解决方法
只读实例规格过小
建议您升级只读实例规格,使只读实例的配置大于或者等于主实例的配置,避免由于只读实例规格较小导致延迟,详情请参见变更配置。
主实例的TPS(Transaction Per Second)过高
确认主实例的TPS是否正常,如果TPS过高,则需要对业务进行优化或者拆分,保证主实例的TPS不会导致只读实例出现延迟。TPS相关数据可以通过自治服务的性能趋势页面查看,详情请参见性能趋势。
主实例的大事务
1、在只读实例出现大事务导致延迟时,登录数据库,执行以下SQL语句,确认Seconds_Behind_Master不断变化,而Exec_Master_Log_Pos却保持不变,说明只读实例的SQL线程在执行一个大事务或者DDL操作。然后通过show processlist语句定位具体的线程。
show slave status \G
系统显示类似如下。
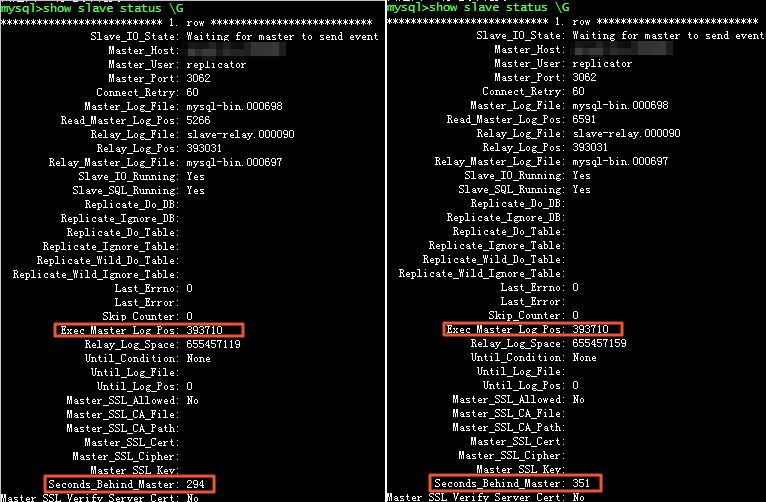
2、建议您将大事务拆分为小事务分别执行。例如在delete语句中增加where条件子句,限制每次删除的数据量,将一次删除操作拆分为多次数据量较小的删除操作进行。这样只读实例可以迅速的完成事务的执行,不会造成数据的延迟。
主实例的DDL语句执行时间长
对于DDL直接引起的只读实例延迟,建议在业务低峰期执行这些DDL。
对于来自主实例的DDL语句在只读实例上被阻塞的情况
a.需要在只读实例上执行show processlist语句,确认SQL线程的状态为“waiting for table metadata lock”。
b.然后使用kill命令终止只读实例上引起阻塞的会话,恢复只读实例和主实例的数据同步,详情请参见解决MDL锁导致无法操作数据库的问题。
cattt
赞 0
评论 0
数据库迁移过程中,会出现数据库中断或者闪断的情况。如出现闪断的情况,请参见更多信息。以下是不同数据库迁移到RDS的方法。
RDS MySQL 版
关于将MySQL数据库迁移到RDS,请参见从自建MySQL迁移至RDS for MySQL。
RDS SQL Server 版
关于将SQL Server数据库迁移到RDS,请参见以下文档:
RDS PostgreSQL 版
关于将PostgreSQL数据库迁移到RDS,请参见以下文档:
RDS PPAS 版
关于将PostgreSQL数据库迁移到RDS,请参见以下文档:
RDS MariaDB TX 版
关于将MariaDB数据库迁移到RDS,请参见使用mysqldump迁移MariaDB TX数据。
更多信息
在数据库迁移过程中会出现中断或者闪断的情况,详情请参见使用限制,出现中断或闪断情况的具体原因如下:
基础版只有一个数据库节点,没有备节点作为热备份,因此当该节点在迁移时,会出现半小时或更长时间的中断。请在非高峰期内进行变更配置,避免影响业务。
非基础版在迁移期间,可能会出现一次约30秒的闪断,虽然不影响正常使用,但是请尽量在非高峰期进行迁移,或确保您的应用有自动重连机制。
云盘实例(非基础版)增加存储空间,绝大多数情况下不会闪断。
cattt
赞 0
评论 0
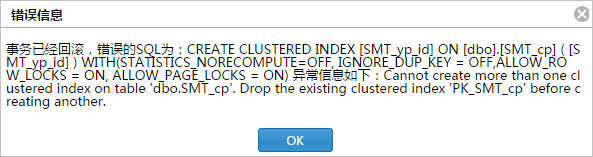
我们建议每个表都要创建聚簇索引。
一个表只能创建一个聚簇索引
如果已创建聚簇索引,再次创建会失败,报错如下。
使用sp_helpindex查看索引
依次执行如下SQL语句,查看索引。
ues [$DB_Name]
go
sp_helpindex '[$Table_Name]'
注: [$DB_Name]为数据库名。 [$Table_Name]为表名。
使用drop index删除聚簇索引
依次执行如下SQL语句,删除聚簇索引。
DROP INDEX [$Index_Name] ON [$DB_Name].[$Table_Name]
注:[$Index_Name]为索引名。
重新计算统计信息
统计信息指的是创建索引时的STATISTICS_NORECOMPUTE选项。一般来说都需要重新计算,详情请参见CREATE INDEX。
注:STATISTICS_NORECOMPUTE的默认值是OFF,即需要重新计算,因为该选项本身就是否定的意思。 云数据库 RDS SQL Server 版
cattt
赞 0
评论 0
使用客户端连接实例,请参见连接实例。
查询语句
use [$DB_Name]
select * from sys.configurations
注:[$DB_Name]为数据库名。
系统显示类似如下。
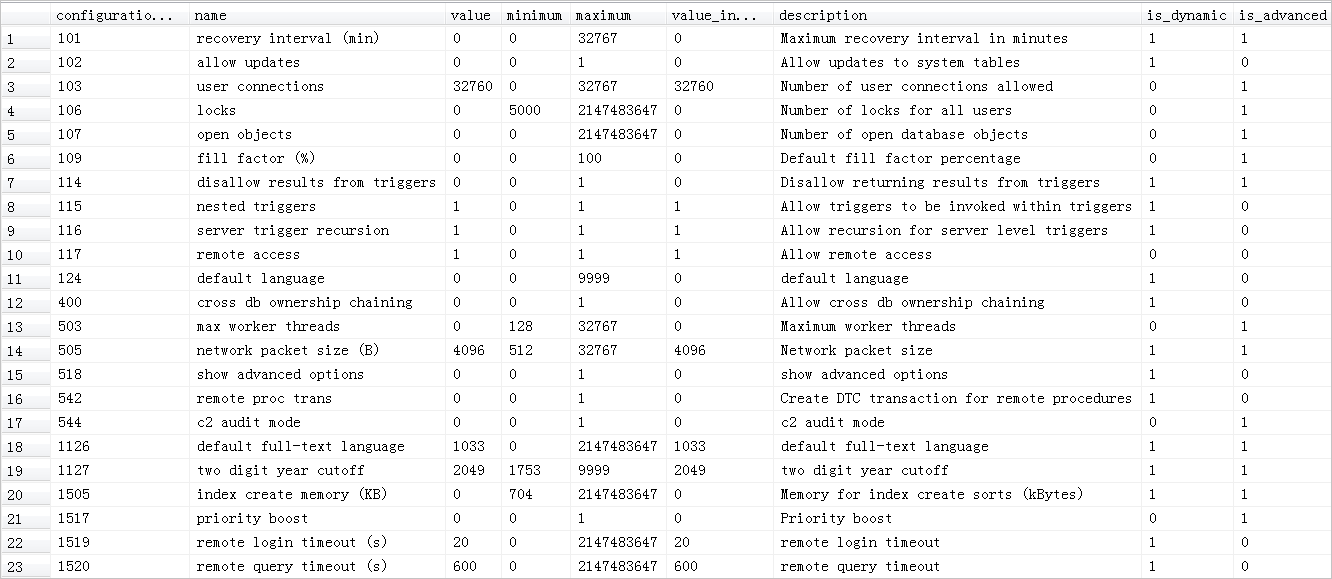
提示:参数详细解释请参见sys.configurations。
use [$DB_Name]
select * from sys.sysfiles
系统显示类似如下。

select name, convert(float,size) * (8192.0/1024.0)/1024 AS Size_MB,* from [$DB_Name].dbo.sysfiles
系统显示类似如下。

select * from sys.dm_io_virtual_file_stats(DB_ID('[$DB_Name]'),[$File_ID])
注:[$File_ID]为上一步获取的fileid。
系统显示类似如下。

SELECT DB_NAME(dbid) AS DBNAME,
(SELECT text FROM sys.dm_exec_sql_text(sql_handle)) AS SQLSTATEMENT
FROM master..sysprocesses WHERE open_tran > 0
系统显示类似如下。

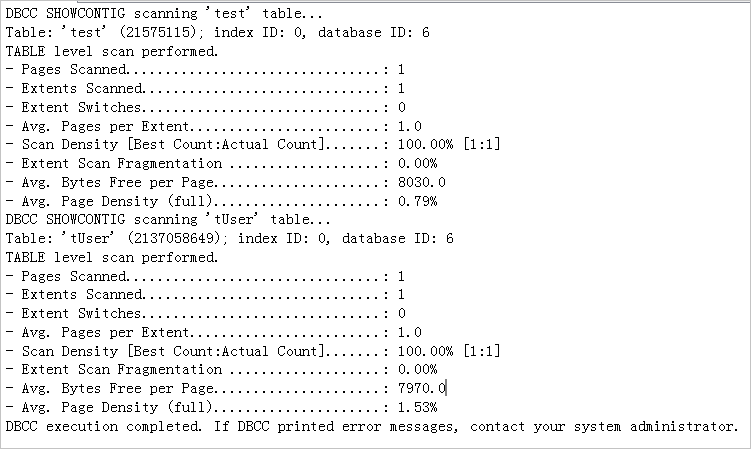
DBCC SHOWCONTIG
系统显示类似如下,显示指定表或者视图的数据以及索引的碎片情况,详细解释请参考DBCC SHOWCONTIG。
select * from sys.dm_db_index_physical_stats(DB_ID(N'[$DB_Name]'),NULL,NULL,NULL,DEFAULT)
系统显示类似如下。

SELECT
p.spid, p.status, p.hostname, p.loginame, p.cpu, r.start_time, r.command,
p.program_name, text
FROM
sys.dm_exec_requests AS r,
master.dbo.sysprocesses AS p
CROSS APPLY sys.dm_exec_sql_text(p.sql_handle)
WHERE
p.status NOT IN ('sleeping', 'background')
AND r.session_id = p.spid
系统显示类似如下。

cattt
赞 0
评论 0
查看实例空间的大小
登录RDS控制台,在基本信息页面查看实例空间情况。

查看数据库的大小
1、使用客户端连接实例,关于如何连接实例,请参见连接实例。
2、在SQL窗口中执行如下SQL语句。
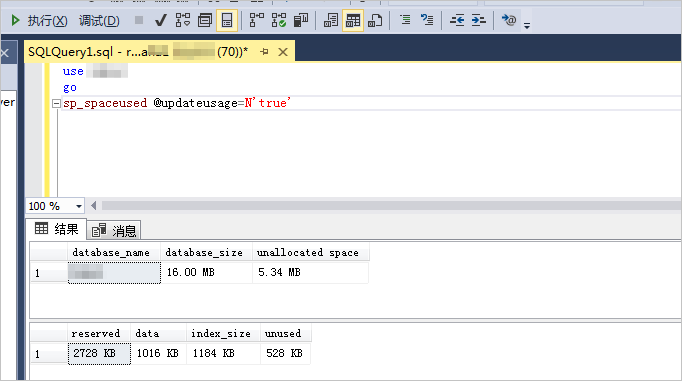
use [$DB]
go
sp_spaceused @updateusage=N'true'
注:[$DB]为数据库的库名。
系统显示类似如下。
提示:字段介绍如下所示。
3、查看所有的数据库,则需要使用脚本来实现,脚本如下所示。
USE master
go
DECLARE @insSize TABLE(dbName sysname,checkTime VARCHAR(19),dbSize VARCHAR(50),logSize VARCHAR(50))
INSERT INTO @insSize ( dbName, checkTime, dbSize, logSize )
EXEC sp_msforeachdb 'select ''?'' dbName,CONVERT(VARCHAR(19),GETDATE(),120) checkTime,LTRIM(STR(SUM(CASE WHEN RIGHT(FILENAME,3)<>''ldf'' THEN convert (dec (15,2),size) * 8 / 1024 ELSE 0 END),15,2)+'' MB'') dbSize,
LTRIM(STR(SUM(CASE WHEN RIGHT(FILENAME,3)=''ldf'' THEN convert (dec (15,2),size) * 8 / 1024 ELSE 0 END),15,2)+'' MB'') logSize from ?.dbo.sysfiles'
SELECT * FROM @insSize ORDER BY CONVERT(DECIMAL,LTRIM(RTRIM(SUBSTRING(dbSize,1,LEN(dbSize)-2)))) DESC
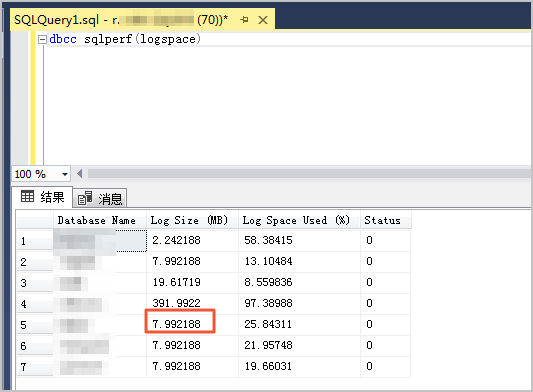
该输出结果包含日志文件的大小,查看日志文件的大小的SQL语句如下所示。
dbcc sqlperf(logspace)
系统显示类似如下。
查看数据库中表的大小
1、使用客户端连接实例,关于如何连接实例,请参见连接实例。
2、在SQL窗口中执行如下SQL语句。
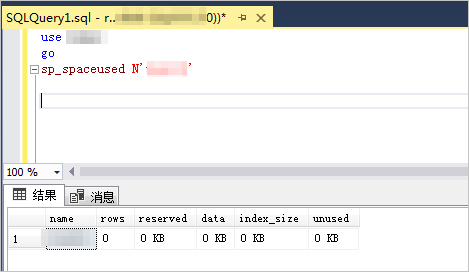
use [$DB]
go
sp_spaceused N'[$Table]'
注:[$Table]为数据库的表名。
系统显示类似如下。
3、查看该库所有的表,则需要使用脚本来实现,脚本如下所示。
use [$DB]
go
declare @tabSize table(name nvarchar(100),rows char(20),reserved varchar(18) ,data varchar(18) ,index_size varchar(18) ,nnused varchar(18) )
insert into @tabSize exec sp_msforeachtable 'sp_spaceused ''?'''
select * from @tabSize order by convert(int,replace(data,'KB','')) desc,2 desc
排查方法
针对云数据库RDS SQL Server版阻塞问题,排查建议如下。
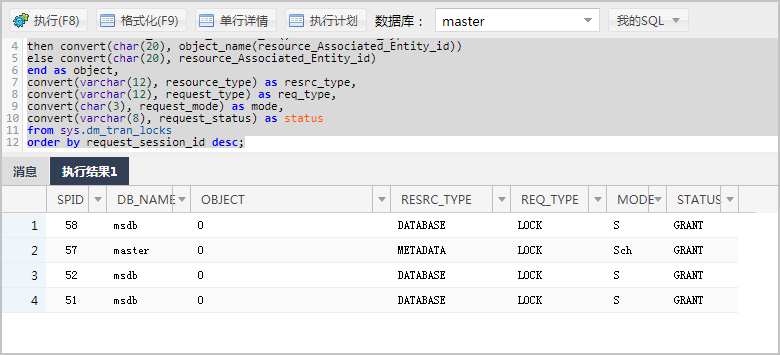
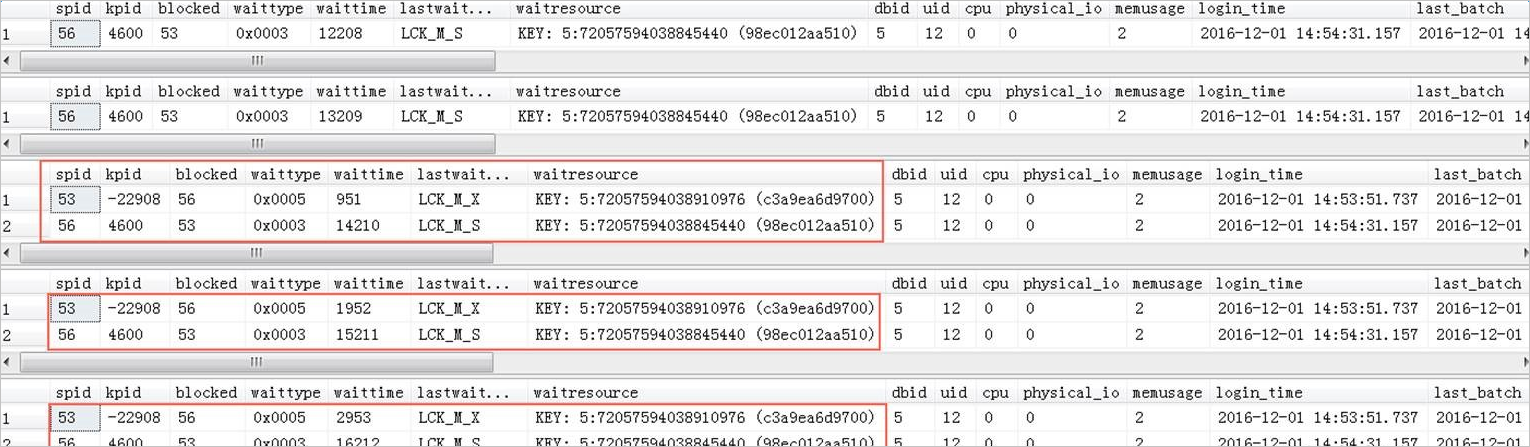
1、循环监控sys.sysprocesses,获取阻塞信息。blocked列的值为阻塞头session_id,waitresource为被阻塞的session等待的资源。操作代码如下。
while 1=1
begin
select * from sys.sysprocesses where blocked<>0;
waitfor delay '00:00:01'
end
说明:循环间隔时间可以自定义。此处以00:00:01为例。
系统显示类似如下。

说明:图中字段的解释,请参见sys.sysprocesses官方文档。
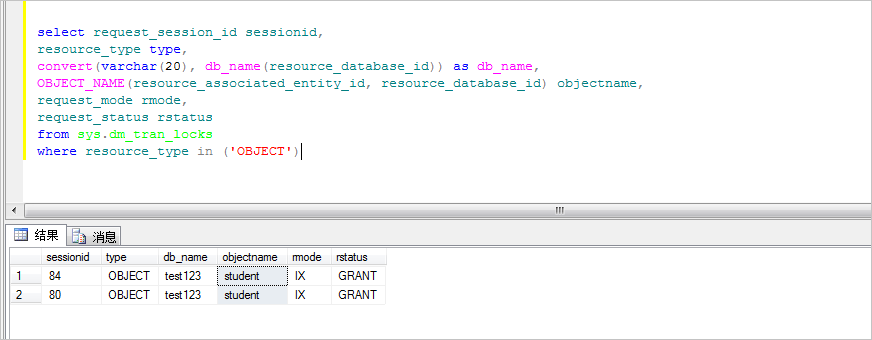
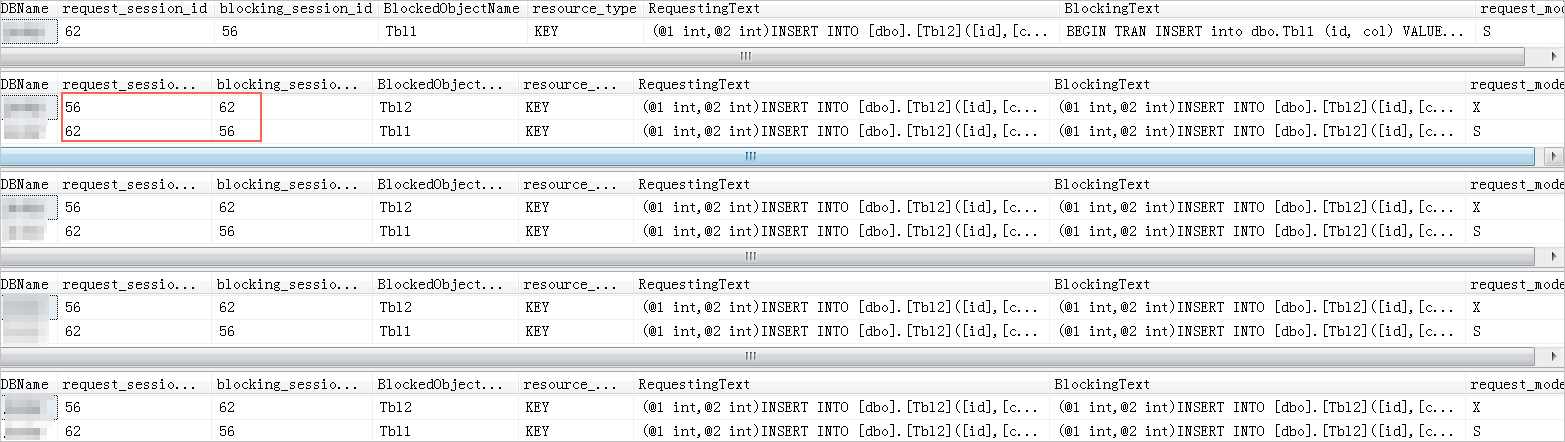
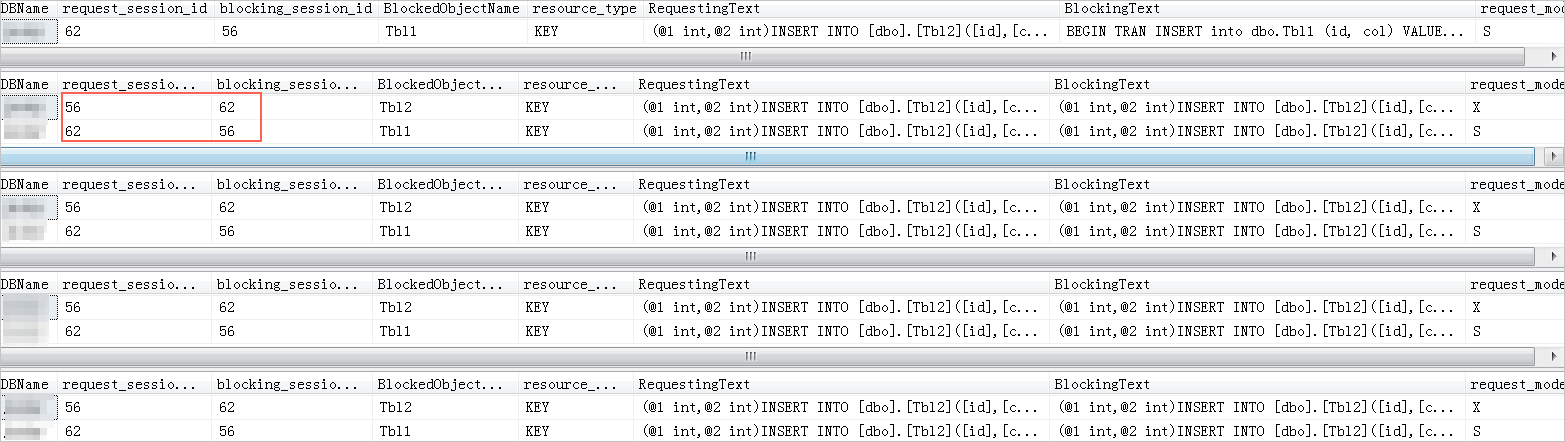
2、循环监控sys.dm_tran_locks,sys.dm_os_waiting_tasks等视图,可以得到阻塞图谱。Request_session_id是被阻塞的session_id,RequestingText是被阻塞的语句,blocking_session_id是阻塞头session_id,BlockingText是阻塞头语句。操作代码如下。
while 1=1
Begin
SELECT db.name DBName,
tl.request_session_id,
wt.blocking_session_id,
OBJECT_NAME(p.OBJECT_ID) BlockedObjectName,
tl.resource_type,
h1.TEXT AS RequestingText,
h2.TEXT AS BlockingText,
tl.request_mode
FROM sys.dm_tran_locks AS tl
INNER JOIN sys.databases db ON db.database_id = tl.resource_database_id
INNER JOIN sys.dm_os_waiting_tasks AS wt ON tl.lock_owner_address = wt.resource_address
INNER JOIN sys.partitions AS p ON p.hobt_id = tl.resource_associated_entity_id
INNER JOIN sys.dm_exec_connections ec1 ON ec1.session_id = tl.request_session_id
INNER JOIN sys.dm_exec_connections ec2 ON ec2.session_id = wt.blocking_session_id
CROSS APPLY sys.dm_exec_sql_text(ec1.most_recent_sql_handle) AS h1
CROSS APPLY sys.dm_exec_sql_text(ec2.most_recent_sql_handle) AS h2
waitfor delay '00:00:01'
End
系统显示类似如下。
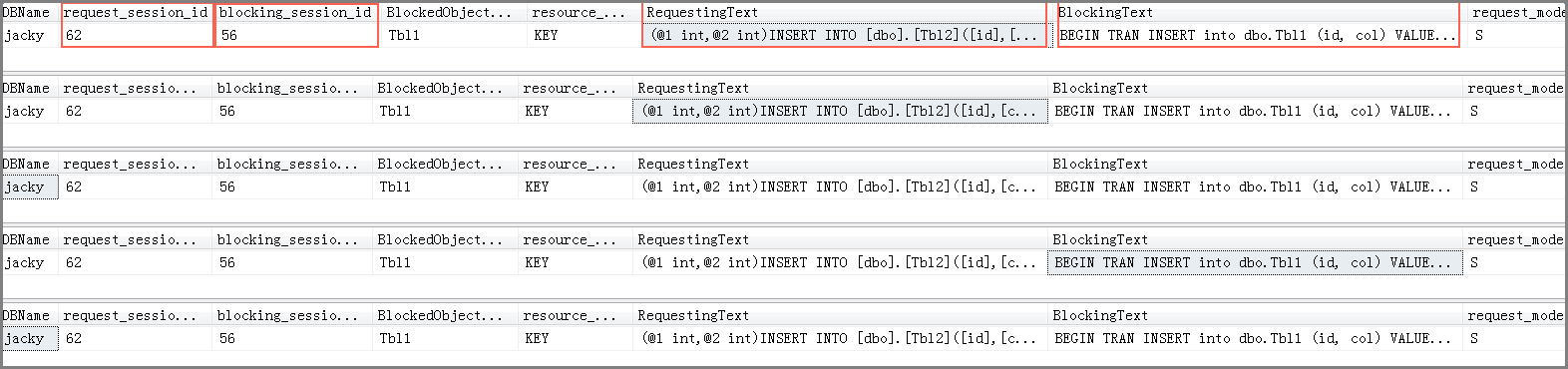
说明:
DBName:数据库名称。
request_session_id:当前请求的session ID,即被阻塞的session。
blocking_session_id:阻塞头session ID。
BlockedObjectName:被阻塞的session操作的对象。
resource_type:等待的资源类型。
RequestingText:当前session执行的语句,即被阻塞的语句。
BlockingText:阻塞头session执行的语句。
request_mode:当前session请求的锁模式。
调优建议
可以参考以下步骤,进行调优。
1、关闭阻塞头连接,可以帮助快速解除阻塞。
2、查看是否有长时间未提交的事务,及时提交事务。
3、如果有S锁参与阻塞,并且应用允许脏读,可以使用with nolock这个查询hint,让查询语句避免申请锁,从而避免阻塞,例如 select * from table with(nolock);。
4、检查应用程序逻辑,按顺序访问某个资源。
cattt
赞 0
评论 0
如果要实现存储emoji表情到RDS MySQL实例,需要客户端、到RDS实例的会话连接、RDS实例三个方面统一使用utf8mb4字符集。
客户端:客户端需要保证输出字符串的字符集为utf8mb4。
到RDS实例的会话连接:支持utf8mb4字符集。以常见的JDBC连接为例,需要使用MySQL Connector/J 5.1.13及以上的版本,JDBC的连接串中,建议不配置characterEncoding选项。
RDS实例:在RDS控制台将character_set_server参数设置为utf8mb4,且数据库和表的字符集也要设置为utf8mb4。


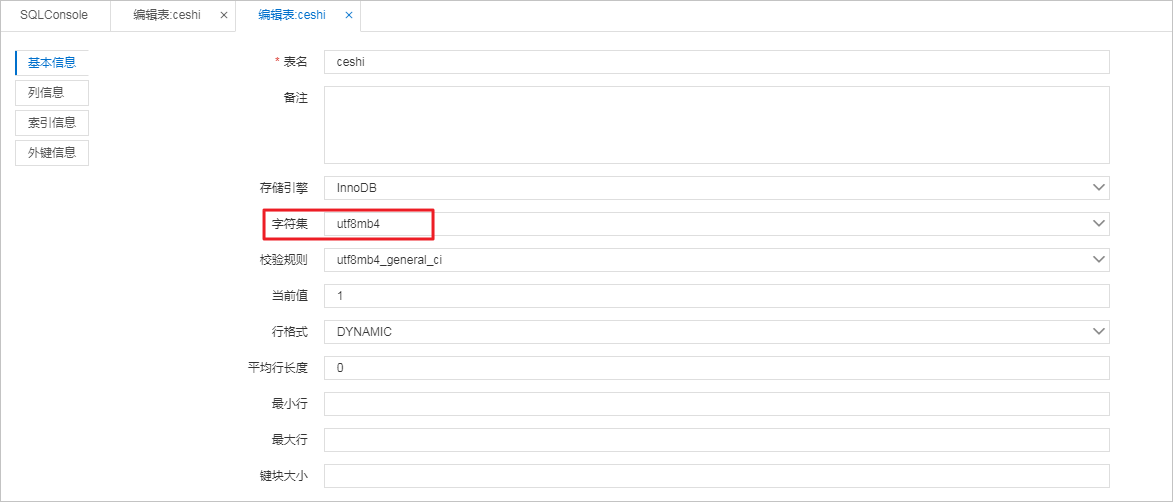
修改字符集
如果字符集不符合以上基本原则,请参见RDS MySQL字符集相关说明修改字符集。
说明:由utf8修改为utf8mb4字符集不会影响之后的数据质量,且已经存在的数据也不受影响,但是数据存储空间会有所增加。
cattt
赞 0
评论 0
pt-online-schema-change
pt-online-schema-change提供在线修改表结构等功能,搭配RDS MySQL 5.5使用可以避免在修改表结构的过程中阻塞应用对表数据的访问。由于RDS MySQL 5.6支持online-ddl功能,可以直接在业务低峰期进行操作,也可以结合pt-online-schema-change使用。
无论RDS MySQL 5.5还是5.6版本,是否使用pt-online-schema-change,在修改表结构过程中都有可能遇到等待表元数据锁的情况(waiting for table metadata lock)。如果出现这种情况,请参考RDS MySQL表上Metadata lock的产生和处理。
表及数据维护操作请在业务低峰期进行。
样例用表
CREATE TABLE `x` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`password` varchar(10) DEFAULT NULL,
`recommend_level` double(5,0) DEFAULT NULL,
`name` varchar(30) DEFAULT '101' COMMENT 'change',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4;
增加字段
1、登录服务器,执行如下命令,增加字段。
pt-online-schema-change --no-version-check --execute --alter "add column c1 int" h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=x
注:
h=xxx.mysql.rds.aliyuncs.com:RDS实例地址。
P=3306:RDS实例端口。
u=jacky:RDS实例用户。
p=xxx:RDS实例用户密码。
D=jacky:RDS实例数据库。
t=x:RDS实例表名称。
系统显示类似如下。
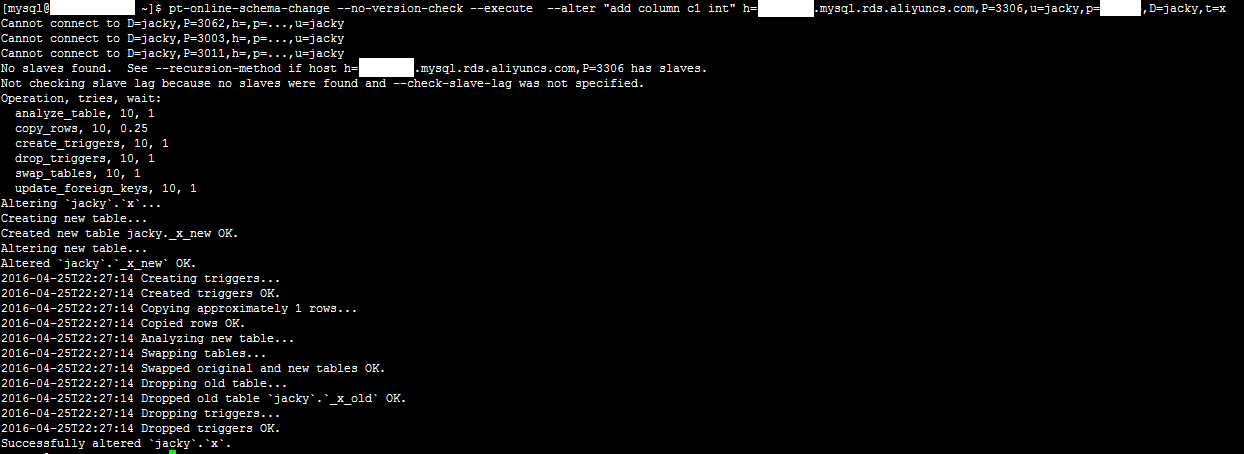
2、登录数据库,执行如下SQL语句,确认添加成功。
show create table x \G
系统显示类似如下。
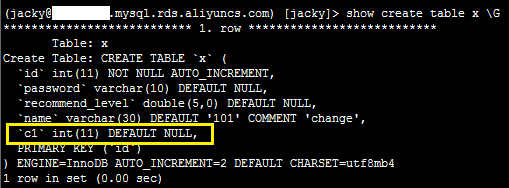
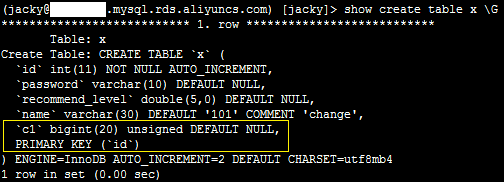
删除字段
1、登录服务器,执行如下命令,删除字段。
pt-online-schema-change --no-version-check --execute --alter "drop column c1" h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=x
2、登录数据库,执行如下SQL语句,确认删除字段成功。
show create table x \G
系统显示类似如下。
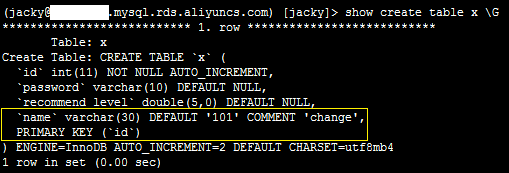
修改字段类型
1、登录服务器,执行如下命令,修改字段类型。
pt-online-schema-change --no-version-check --execute --alter "modify column c1 bigint unsigned" h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=x
2、登录数据库,执行如下SQL语句,确认修改字段类型成功。
show create table x \G
系统显示类似如下。
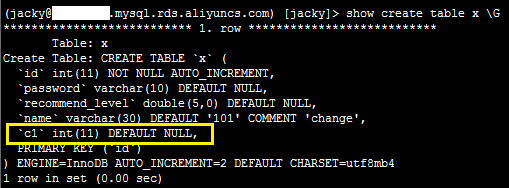
添加索引
1、登录服务器,执行如下命令,添加索引。
pt-online-schema-change --no-version-check --execute --alter "add key idx_c1 (c1)" h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=x
2、登录数据库,执行如下SQL语句,确认添加索引成功。
show create table x \G
系统显示类似如下。
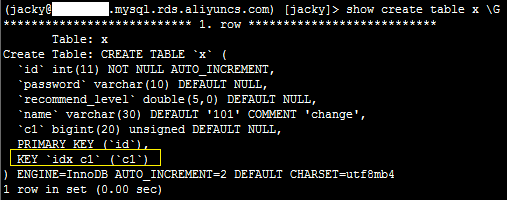
删除索引
1、登录服务器,执行如下命令,删除索引。
pt-online-schema-change --no-version-check --execute --alter "drop key idx_c1" h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=x
2、登录数据库,执行如下SQL语句,确认删除索引成功。
show create table x \G
系统显示类似如下。
pt-archiver
pt-archiver是Percona官方提供的归档工具,用于归档大型表中的记录到另一个表或文件。
样例用表
CREATE TABLE `my_tab` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`areaID` varchar(50) DEFAULT NULL,
`area` varchar(60) DEFAULT NULL COMMENT '中文注释测试',
`father` varchar(12) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_area` (`area`)
) ENGINE=InnoDB AUTO_INCREMENT=3162 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT KEY_BLOCK_SIZE=8;
归档到操作系统文件
1、登录数据库,执行如下SQL语句,确认源表数据的行数。
select count(*) from my_tab;
系统显示类似如下。
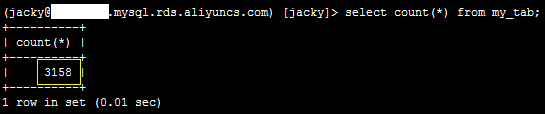
2、登录服务器,执行如下命令,归档到操作系统文件。
pt-archiver --source h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=my_tab --charset=utf8 --file '/var/tmp/%Y-%m-%d-%D.%t' --where "id > 3008" --limit 1000 --commit-each --no-version-check
注:
h=xxx.mysql.rds.aliyuncs.com:RDS实例地址。
P=3306:RDS实例端口。
u=jacky:RDS实例用户。
p=xxx:RDS实例用户密码。
D=jacky:RDS实例数据库。
t=my_tab:RDS实例表名称。
--source:指定要被归档的数据源。
--charset=utf8:使用的字符集,需与表字符集一致,否则指定--no-check-charset参数。
--file:指定目标操作系统文件名。
--where "id > 3008":指定where过滤条件,过滤出要归档的数据。
--limit 1000:每条语句读取和归档的数据行数,默认是1。
--commit-each:每次获取和归档数据后,commit提交。
--no-version-check:不做版本检查,RDS MySQL必须设置。
3、归档后,登录数据库,执行如下SQL语句,确认数据行数减少150行。
select count(*) from my_tab;
系统显示类似如下。
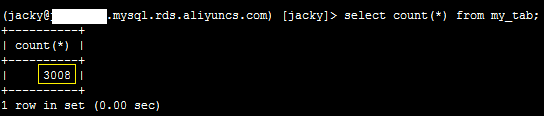
4、登录服务器,执行如下命令,发现归档操作系统文件中,包含150行数据。
wc -l /var/tmp/xxx-jacky.my_tab
系统显示类似如下。

归档到另外一个表中
可以将数据归档到同实例不同库下的表中,也可以将数据归档到不同实例下的表中。归档操作前,目标表要存在。
归档到同实例不同库下的表
1、登录服务器,执行如下命令,归档到同实例不同库下的表。
pt-archiver --source h=rds01.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=my_tab --charset=utf8 --dest h=rds01.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=my_db,t=my_tab --where "id > 2000" --limit 1000 --commit-each --no-version-check
注:--dest为指定归档到的目标表。
2、登录数据库,执行如下SQL语句,发现目标表中增加了1008行数据。
select count(*) from my_tab;
系统显示类似如下。
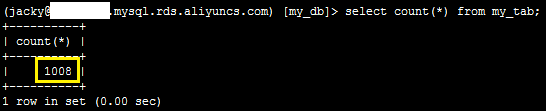
3、登录数据库,执行如下SQL语句,源表中减少了1008行数据,剩余2000行数据。
select count(*) from jacky.my_tab;
系统显示类似如下。

归档到不同实例下的表
1、登录服务器,执行如下命令,归档到不同实例下的表。
pt-archiver --source h=rds01.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=my_tab --charset=utf8 --dest h=rds02.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=my_tab --where "id > 500" --limit 1000 --commit-each --no-version-check
2、登录数据库,执行如下SQL语句,发现目标表中增加了1500行数据。
select count(*) from my_tab;
系统显示类似如下。

3、执行如下SQL语句,源表中减少了1500行数据,剩余500行数据。
select count(*) from jacky.my_tab;
系统显示类似如下。

通过bulk insert加速归档过程
当需要归档的数据量很大,比如第一次做归档的时候,可以考虑通过尝试bulk insert的方式来加速归档过程,命令如下所示。
pt-archiver --source h=rds01.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=rd_test,t=large_tab_04 --charset=utf8 --dest h=rds02.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=large_tab_04 --where "1=1" --limit 5000 --commit-each --bulk-insert --no-version-check --statistics
注:
--bulk-insert:批量插入数据,会自动启用--bulk-delete和--commit-each,每次插入行数通过--limit选项指定。
--statistics:显示pt-archiver本次操作的统计信息。
cattt
赞 0
评论 0
说明:由utf8修改为utf8mb4字符集不会影响之后的数据质量,且已经存在的数据也不受影响,但是数据存储空间会有所增加。
控制台上修改字符集参数
如何修改character_set_server参数,请参见设置实例参数。
使用SQL语句修改数据库字符集
修改列时,当前列中的所有行都会立即转化为新的字符集。alter table会对表加元数据锁(metadata lock), 详情请参见RDS MySQL表上Metadata lock的产生和处理。
ALTER DATABASE [$Database] CHARACTER SET [$Character_Set] COLLATE [$Collation_Name];。说明:
[$Database]为数据库的库名。
[$Character_Set]为字符集名称。
[$Collation_Name]为排序规则名称,即字符序。
ALTER TABLE [$Table] CONVERT TO CHARACTER SET [$Character_Set] COLLATE [$Collation_Name];。说明:[$Table]为表名。
ALTER TABLE [$Table] MODIFY [$Column_Name] [$Field_Type] CHARACTER SET [$Character_Set] COLLATE [$Collation_Name];。说明:
[$Column_Name]为字段名。
[$Field_Type]为字段类型。
如下SQL语句所示,分别将dbsdq库、tt2表、tt2表中的c2列修改为utf8mb4字符集。
alter database dbsdq character set utf8mb4 collate utf8mb4_unicode_ci;
use dbsdq;
alter table tt2 convert to character set utf8mb4 collate utf8mb4_unicode_ci;
alter table tt2 modify c2 varchar(10) character set utf8mb4 collate utf8mb4_unicode_ci;
使用Navicat修改数据库字符集
使用Navicat连接数据库,选择连接的名称,右键单击库的名称,单击编辑数据库,在字符集右侧选择需要的字符集,单击确认即可。
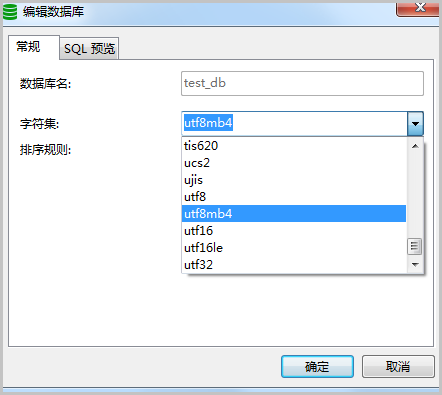
右键单击对应的表,单击设计表,然后单击选项,在字符集右侧选择需要的字符集,单击保存即可。
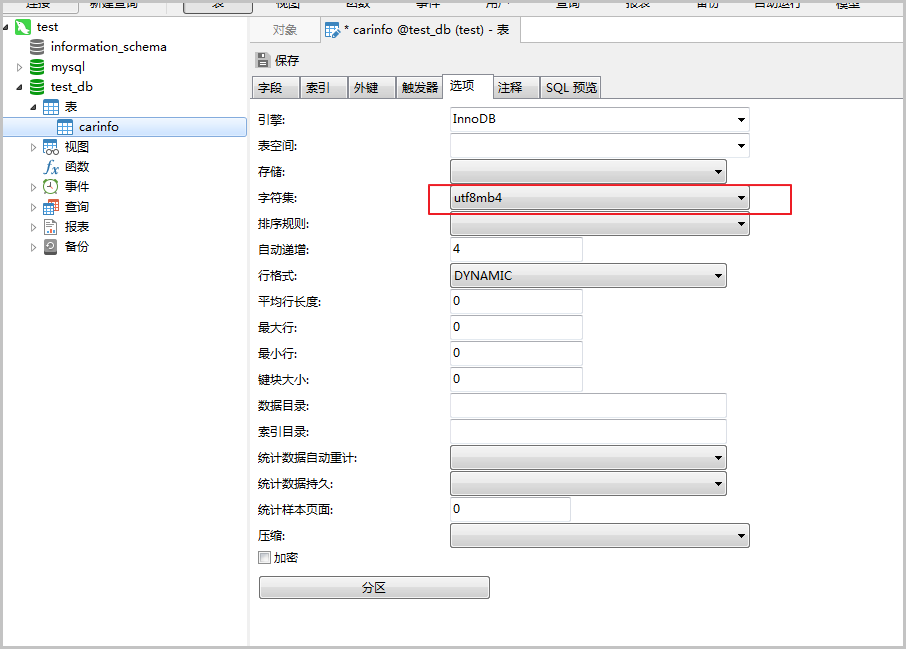
单击字段,选择对应的字段,选择需要的字符集,单击保存即可。
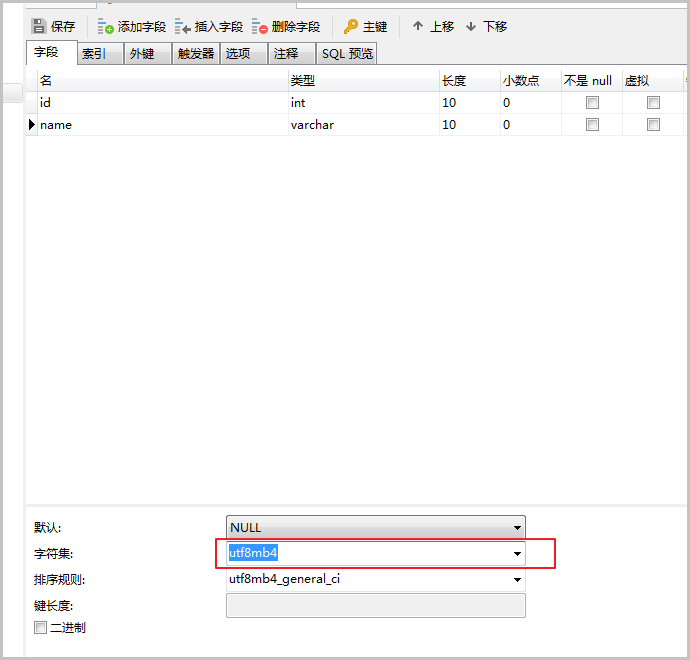
cattt
赞 0
评论 0
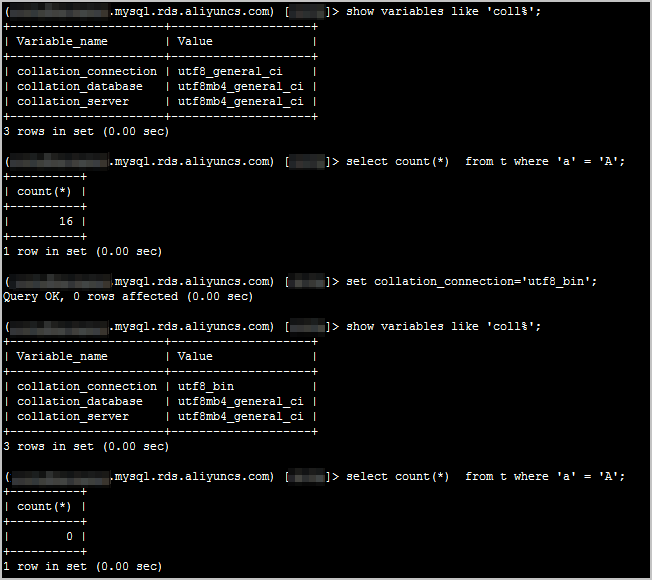
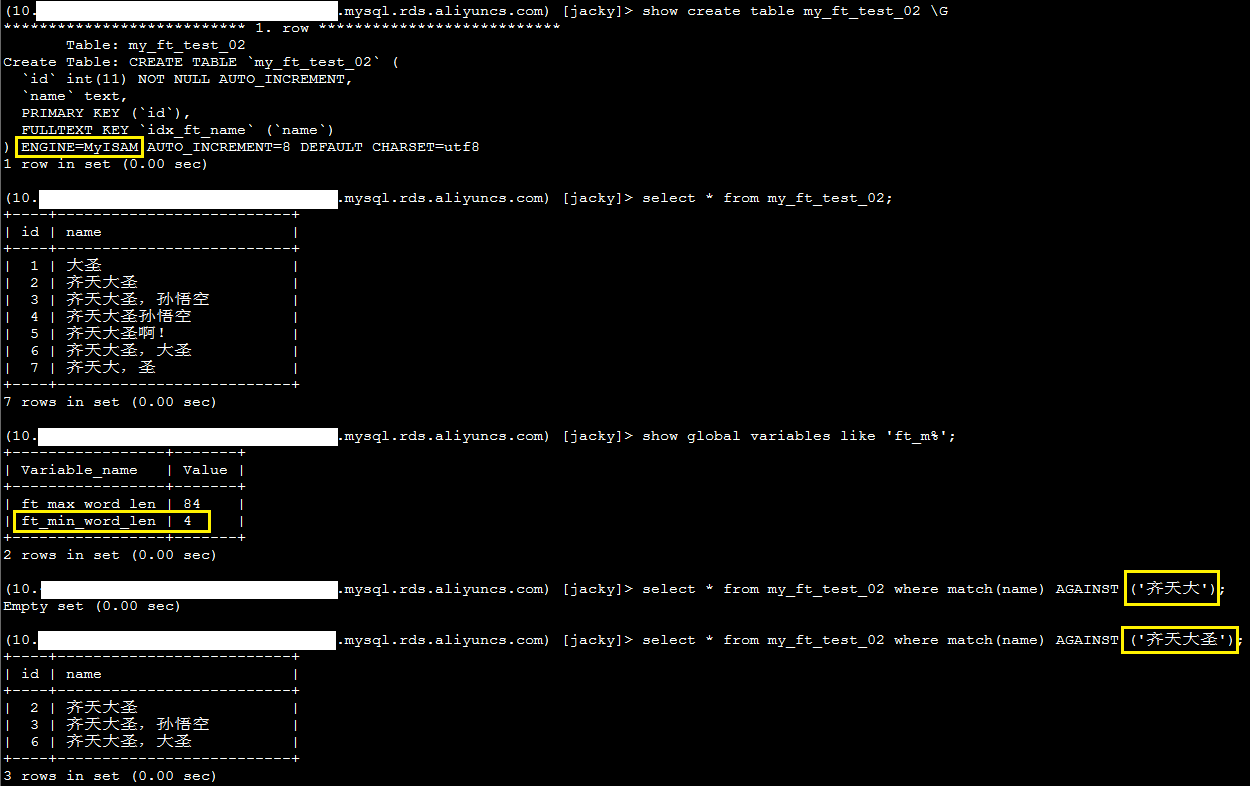
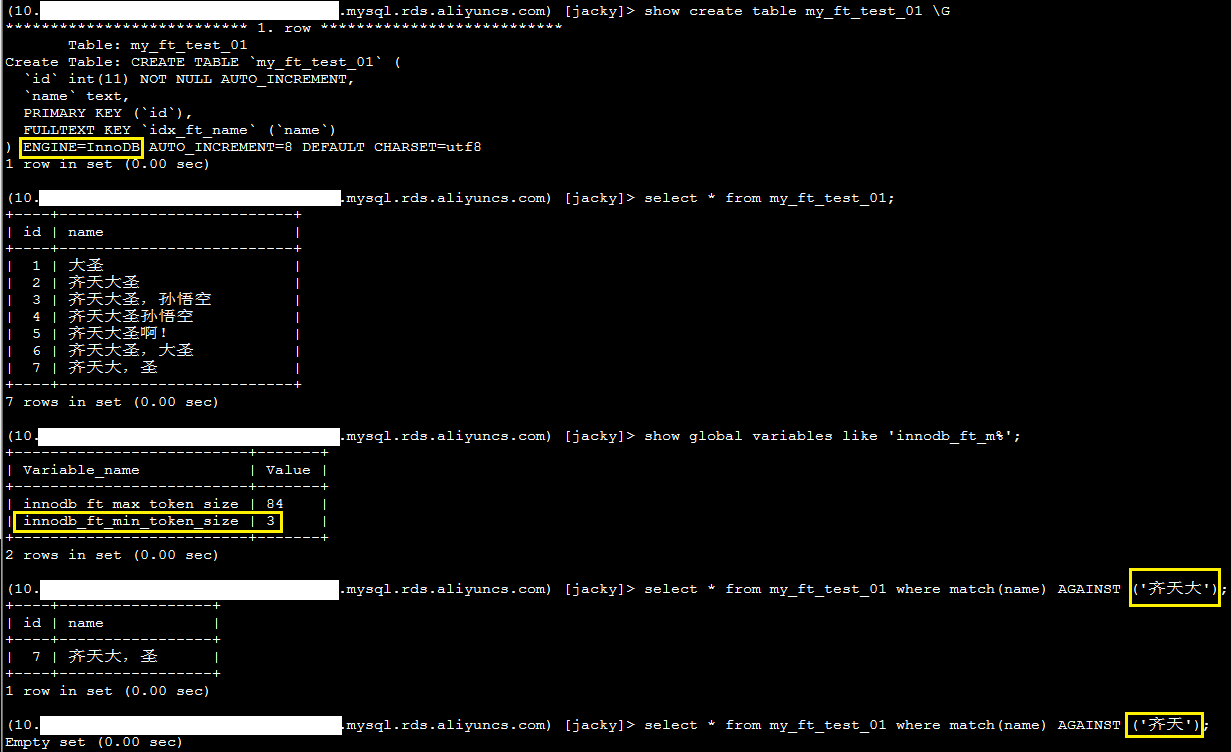
MySQL全文检索支持扩展检索,具体请参考带查询扩展的全文检索。ft_query_expansion_limit参数的作用是指定MyISAM引擎表使用with query expansion进行全文搜索的最大匹配数,下面以一个例子来说明其作用。
1、执行如下SQL语句,确认ft_query_expansion_limit参数值当前设置为20。
show global variables like 'ft_qu%';
系统显示类似如下。

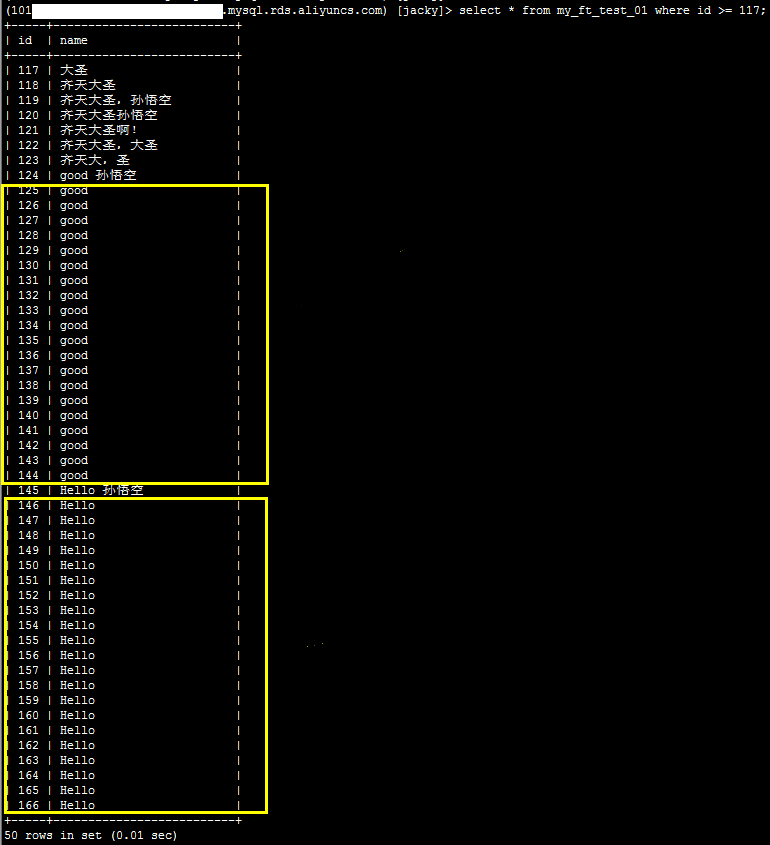
2、执行如下SQL语句,查看当前表中相关的记录情况。
select * from my_ft_test_01 where id >= 117;
系统显示类似如下,good和Hello都出现20次。
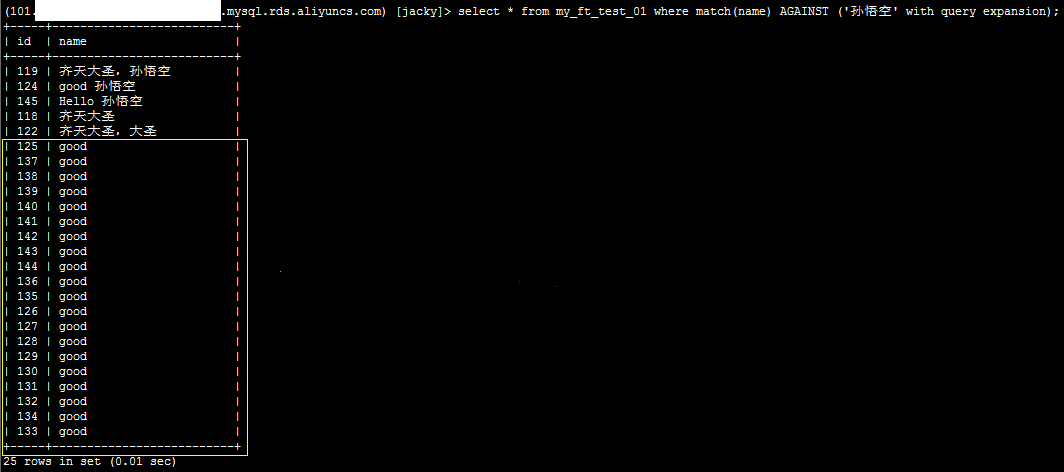
3、执行如下SQL语句,查看使用查询扩展的结果。
select * from my_ft_test_01 where math(name) AGAINST ('孙悟空' with query expansion);
系统显示类似如下,返回结果中包含good。
cattt
赞 0
评论 0
字符集是数据库设计过程中需要详细考虑的一点,您需要根据业务场景、用户数据等方面来综合考虑。
字符编码的介绍
1、登录RDS实例,请参见连接MySQL实例。
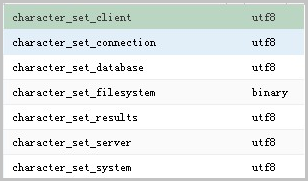
2、依次执行如下SQL语句,查看相应数据库的字符集。
use [$DB_Name];
show variables like '%character%';
说明:[$DB_Name]为数据库名。
系统显示类似如下。
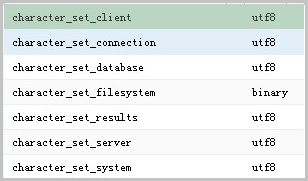
说明:
a.以上参数必须保证除了character_set_filesystem外的参数都统一,才不会出现乱码的情况。
b.character_set_client、character_set_connection以及character_set_results是客户端的设置。
c.character_set_system、character_set_server以及character_set_database是服务器端的设置。
d.服务器端的参数优先级是character_set_database > character_set_server > character_set_system。
保证数据库字符编码正确
1、执行如下SQL语句,修改客户端字符集。
set names [$Character_Set]
说明:[$Character_Set]为字符集。
2、执行如下SQL语句,修改character_set_database参数。
ALTER DATABASE [$DB_Name] CHARACTER SET = [$Character_Set] COLLATE = [$Rules];
说明:[$Rules]为字符集规则。
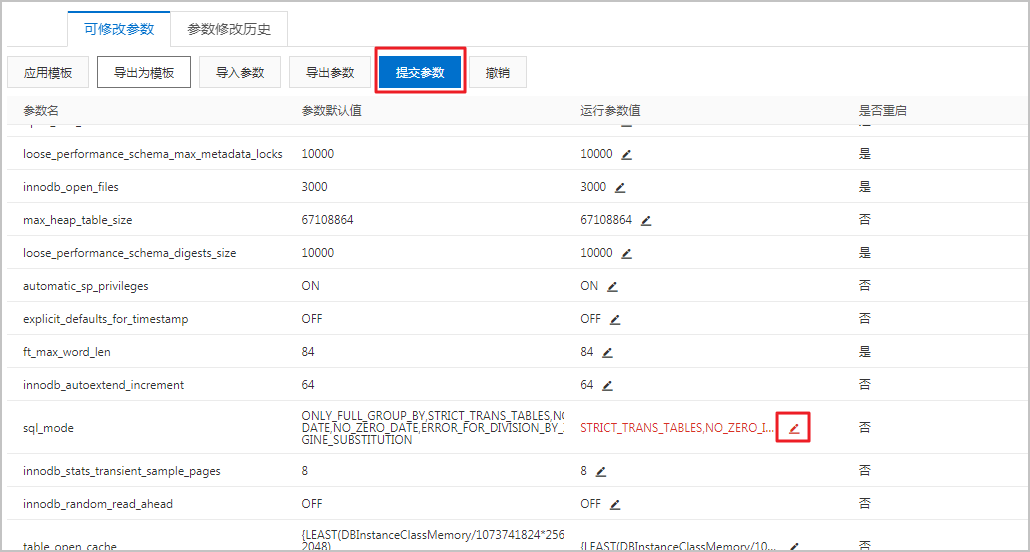
3、登录RDS管理控制台,在页面左上角,选择实例所在地域。找到目标实例,单击实例ID。在左侧导航栏中单击参数设置。
4、在可修改参数页签下查找到character_set_server进行修改,然后单击确定。
说明:修改character_set_server参数需要重启实例,建议在业务低峰期进行操作。 修改character_set_server参数
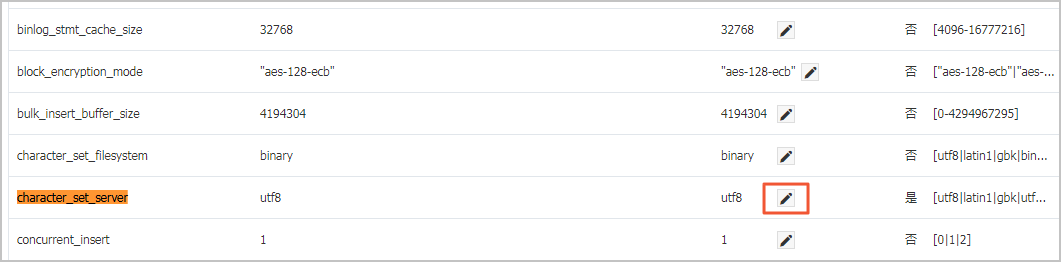
5、在页面右上角单击提交参数,在弹出的对话框中单击确定,等待实例重启即可。
说明:该参数修改后,仅对开启高权限账号的实例后,创建的数据库有效,对当前数据库无效。
6、character_set_system暂时不提供更改,但是由于其优先级最低,因此影响不大。做完上述的设置之后基本上可以保证不会出现乱码,在代码中设置客户端字符编码时建议通过第1步的SQL语句来修改客户端的设置。
cattt
赞 0
评论 0
查看时区
1、参考连接MySQL实例,连接MySQL实例。
2、在SQL窗口使用如下SQL语句,查看时区设置。
show global variables like '%time_zone%';
系统显示类似如下。
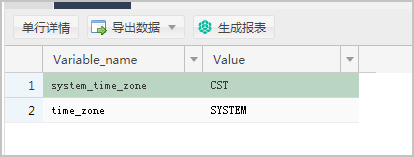
提示:
system_time_zone:系统默认时区。
time_zone:当前使用的时区。
使用控制台修改时区
提示:修改时区需要重启实例。
1、登录RDS管理控制台,在页面左上角,选择实例所在地域。
2、找到目标实例,单击实例ID,在左侧导航栏中单击 参数设置。
3、在可修改参数页签下查找到default_time_zone进行修改,然后单击 确定。
提示:可以参考修改框中的提示进行修改。
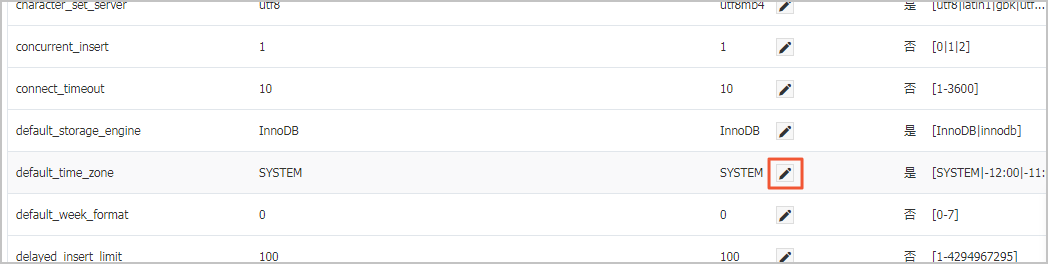
提示:default_time_zone支持部分半时区情况,例如+5:30,详情请参见右侧的 可修改参数值。
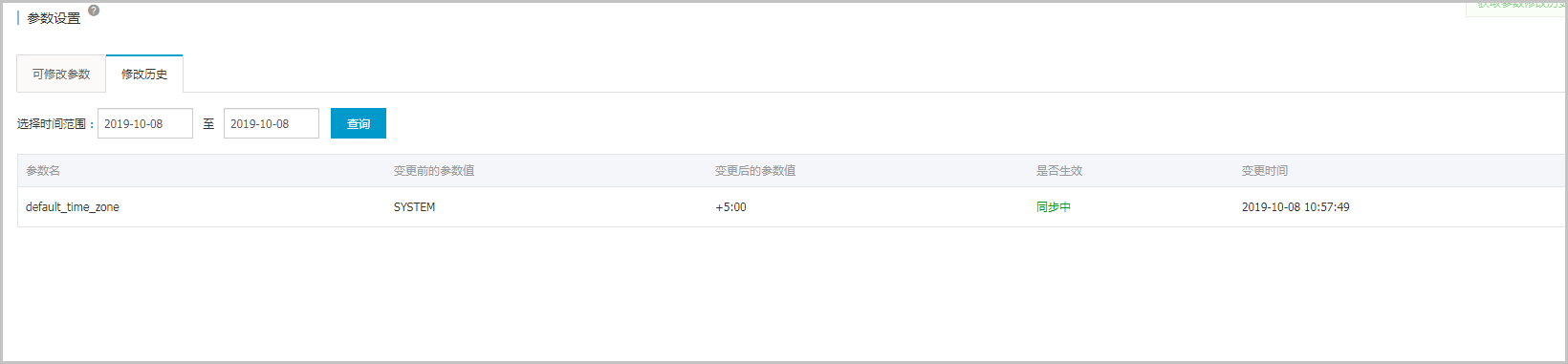
4、在右上角单击 提交参数,在弹出的对话框中单击 确定,单击 修改历史 查看状态,然后等待实例重启即可。
5、修改成功后如下图所示,显示已生效。 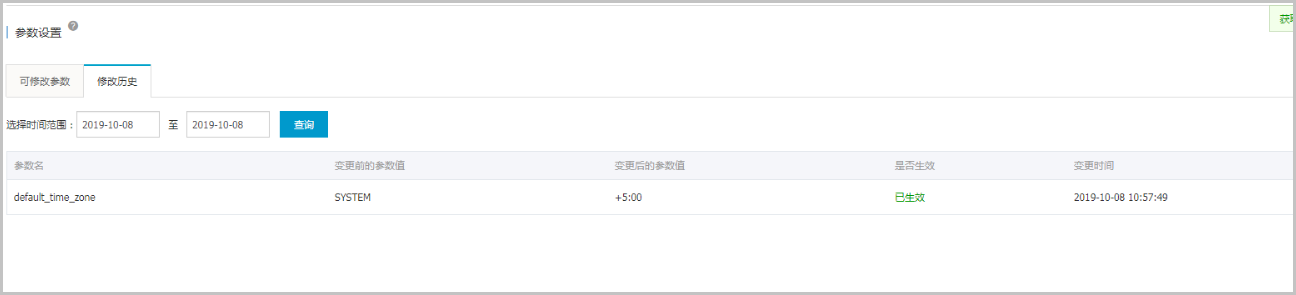
cattt
赞 0
评论 0
在RDS MySQL中,查看增量数据可以通过SQL洞察功能、Binlog日志以及DTS数据订阅三种方式进行查看。以下是不同查看方式的详细信息。
SQL洞察功能
SQL洞察会记录所有DQL、DML和DDL操作信息,这些信息是系统通过网络协议分析所得。但是SQL洞察功能并不会解析实际的参数值,而且在SQL查询量较大时会丢失少量的记录。因此,SQL洞察功能仅能较粗略地统计增量数据。更多关于SQL洞察功能的信息,请参见SQL洞察。
Binlog日志
Binlog可以精确地记录数据库中所有增删改操作的信息,通过该日志可以准确地恢复用户的增量数据。RDS的Binlog会先存储于实例中,之后系统会定期上传到OSS中进行备份,最后清理实例中的Binlog。如何获取Binlog日志请参见云数据库RDS MySQL版远程获取Binlog日志并解析Binlog日志。
DTS数据订阅
DTS的数据订阅功能可以将RDS的增量数据实时推送给用户,您可以定制增量数据,选择部分表的结构或者数据的增量进行订阅。更多关于数据订阅的信息,请参见数据订阅。
cattt
赞 0
评论 0
阿里云帮助中心: https://help.aliyun.com/
阿里云内容设计团队出没于此,一大波优质阿里云相关内容随时袭来~