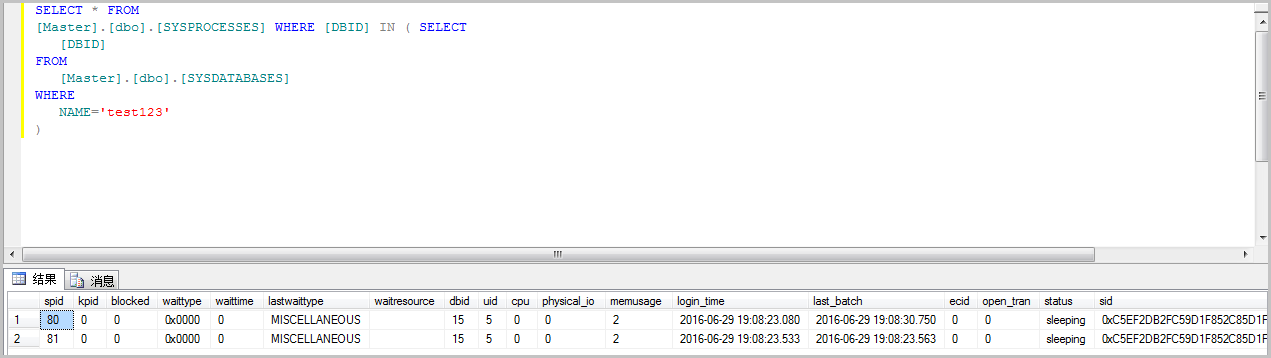
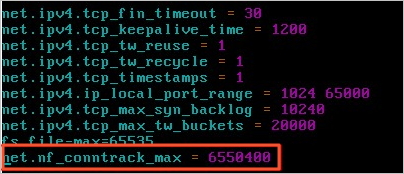
本文提供的检查和处理方法,仅当正在发生行锁等待的情况下才成立。因为RDS MySQL行锁等待默认超时时间为50秒,通常情况下不容易观察到行锁等待的现场,可以通过将innodb_lock_wait_timeout参数设置为较大值来复现问题,但是生产环境不推荐使用过大的innodb_lock_wait_timeout参数值。
1、参考DMS登录RDS数据库,登录RDS数据库。
2、依次单击 性能 > InnoDB锁等待,检查导致锁等待和锁超时的会话。 
3、对于标识为Blocker的会话,即持有锁阻塞其他会话的DML操作,导致行锁等待和行锁等待超时,确认可以接受其对应的事务回滚的情况下,可以将其终止。
 cattt
赞 0
评论 0
cattt
赞 0
评论 0
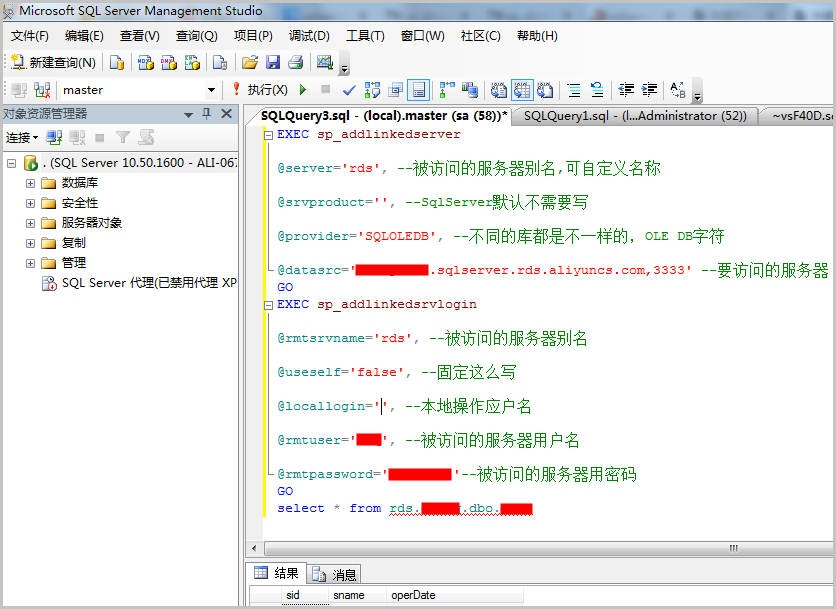
云数据库 RDS SQL Server 版支持Bulk Insert批量导入数据,但是存在一定限制,限制原因是因为会触发RDS for SQL Server 2008R2版本实例的一个BUG,需要在使用时将CheckConstraints选项开启。
通过BCP命令方式
1、生成XML格式文件,示例如下。
bcp jacky.dbo.my_bcp_test format nul /c /t"," /x /f "d:\tmp\my_bcp_test.xml" /U jacky /P xxxx /S "xxx.sqlserver.rds.aliyuncs.com,3333"
2、导入数据,示例如下。
bcp jacky.dbo.my_bcp_test in "d:\tmp\my_test_data_file.txt" /f "d:\tmp\my_bcp_test.xml" /q /k /h "CHECK_CONSTRAINTS" /U jacky /P xxx /S "xxx.sqlserver.rds.aliyuncs.com,3333"
通过JDBC SQLBulkCopy方式
通过JDBC SQLBulkCopy方式批量导入数据的方法如下所示。
SQLServerBulkCopyOptions copyOptions = new SQLServerBulkCopyOptions();
copyOptions.setCheckConstraints(true);
说明:详情请参见通过JDBC驱动程序使用大容量复制。
通过ADO.NET SQLBulkCopy方式
通过ADO.NET SQLBulkCopy方式批量导入数据的方法如下所示,将SqlBulkCopy指定为SqlBulkCopyOptions.CheckConstraints即可。
static void Main()
{
string srcConnString = "Data Source=(local);Integrated Security=true;Initial Catalog=testdb";
string desConnString = "Data Source=****.sqlserver.rds.aliyuncs.com,3433;User ID=**;Password=**;Initial Catalog=testdb";
SqlConnection srcConnection = new SqlConnection();
SqlConnection desConnection = new SqlConnection();
SqlCommand sqlcmd = new SqlCommand();
SqlDataAdapter da = new SqlDataAdapter();
DataTable dt = new DataTable();
srcConnection.ConnectionString = srcConnString;
desConnection.ConnectionString = desConnString;
sqlcmd.Connection = srcConnection;
sqlcmd.CommandText = @"SELECT top 1000000 [PersonType],[NameStyle],[Title],[FirstName],[MiddleName],[LastName],[Suffix],[EmailPromotion]
,[AdditionalContactInfo],[Demographics],NULL as rowguid,[ModifiedDate] FROM [testdb].[dbo].[Person]";
sqlcmd.CommandType = CommandType.Text;
sqlcmd.Connection.Open();
da.SelectCommand = sqlcmd;
da.Fill(dt);
using (SqlBulkCopy blkcpy = new SqlBulkCopy(desConnString, SqlBulkCopyOptions.CheckConstraints))
//using (SqlBulkCopy blkcpy = new SqlBulkCopy(desConnString, SqlBulkCopyOptions.Default))
{
blkcpy.BatchSize = 2000;
blkcpy.BulkCopyTimeout = 5000;
blkcpy.SqlRowsCopied += new SqlRowsCopiedEventHandler(OnSqlRowsCopied);
blkcpy.NotifyAfter = 2000;
foreach (DataColumn dc in dt.Columns)
{
blkcpy.ColumnMappings.Add(dc.ColumnName, dc.ColumnName);
}
try
{
blkcpy.DestinationTableName = "Person";
blkcpy.WriteToServer(dt);
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
finally
{
sqlcmd.Clone();
srcConnection.Close();
desConnection.Close();
}
}
}
private static void OnSqlRowsCopied(
object sender, SqlRowsCopiedEventArgs e)
{
Console.WriteLine("Copied {0} so far...", e.RowsCopied);
}
1、本地服务器需要安装Python2.7环境和RDS SDK for Python,RDS SDK for Python的安装方法如下所示。详情请参见RDS SDK for Python使用参考。
a.执行以下命令,安装阿里云SDK核心库。
pip install aliyun-python-sdk-core
b.执行以下命令,安装RDS SDK for Python。
pip install aliyun-python-sdk-rds
2、确认本地服务器能访问RDS实例的外网地址:
a.如果RDS实例还没有外网地址,请参见申请外网地址。
b.如果没有添加白名单,请参见设置白名单。
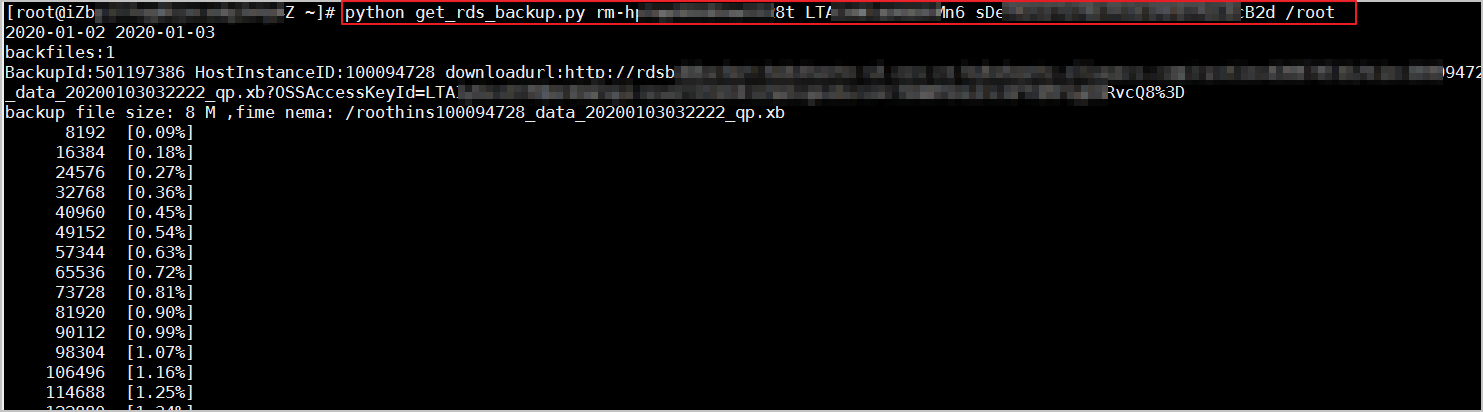
3、将get_rds_backup.py脚本文件下载到本地服务器。
说明:该脚本默认用的公网下载备份文件,如果要用内网下载,请将脚本文件中的第56行换成bak_url = jsload["Items"]["Backup"][i]["BackupIntranetDownloadURL"]后,将修改后的脚本文件重新上传到服务器。
4、参考以下命令,运行get_rds_backup.py脚本文件。
python get_rds_backup.py [$RDS_ID] [$Access_Key_ID] [$Access_Key_Secret] [$Backup_Dir]
说明:
[$RDS_ID]:目标RDS实例的ID,可在RDS实例的基本信息页面查看。比如“rm-hp38xxxxxx2i07”。
[$Access_Key_ID]:RAM用户的密钥ID。如果您还没有RAM用户,请参见创建RAM用户创建。
[$Access_Key_Secret]:RAM用户的密钥。
[$Backup_Dir]:期望保存备份的目录,确保剩余足够的磁盘空间,以免下载失败。
默认下载前一天的备份。如果您需要修改时间范围,可修改脚本中对应的starttime和endtime变量值。
系统显示类似如下。
cattt
赞 0
评论 0
若您需要进行MySQL单库单表恢复,且实例为如下版本时,请参见MySQL单库单表恢复。若其他版本的实例需要恢复数据,且使用了数据库备份DBS产品时,可以通过数据库备份DBS进行单表恢复,详情请参见单表恢复。
MySQL 8.0 高可用版(本地SSD盘)
MySQL 5.7 高可用版(本地SSD盘)
MySQL 5.6 高可用版
通过mysqldump进行库备份及恢复
1、在Linux系统的ECS实例中,安装MySQL客户端工具。
说明:您也可以直接在实例中,使用yum install mysql命令安装MySQL客户端。
a.执行以下命令,下载MySQL客户端工具。
wget http://dev.mysql.com/Downloads/MySQL-5.6/MySQL-server-5.6.21-1.rhel5.x86_64.rpm
b.执行以下命令,安装MySQL客户端工具。
rpm -ivh http://dev.mysql.com/Downloads/MySQL-5.6/MySQL-server-5.6.21-1.rhel5.x86_64.rpm
2、执行以下命令,对RDS实例执行库备份操作。
说明:若您当前环境没有mysqldump命令,您可以执行以下命令,安装mysqldump。
rpm -ivh https://downloads.mysql.com/archives/get/p/23/file/MySQL-client-5.6.21-1.rhel5.x86_64.rpm
说明: [$User]为数据库登录用户。 [$Port]为数据库端口号。 [$Host]为数据库地址。 [$Database_Name]为数据库的库名。
输入密码后,mysqldump将自动完成备份操作,系统显示类似如下。备份的相关信息请参见RDS for MySQL mysqldump选项设置。 
3、执行以下命令,确认成功生成SQL文件。
ll /tmp/db_name.sql
4、若您需要进行RDS实例数据恢复操作,可以根据备份文件,执行以下命令。
mysql -h [$Host] -u [$User] -P [$Port] -p [$Database_Name] < /tmp/db_name.sql
系统显示类似如下,输入密码后,将完成恢复操作。 
通过备份集进行恢复
RDS备份集会将所有数据都进行备份,若你需要恢复数据,请参考以下内容。
1、在Linux系统的ECS实例中,安装MySQL客户端工具。
说明:您也可以直接在实例中,使用yum install mysql命令安装MySQL客户端。
a.执行以下命令,下载MySQL客户端工具。
wget http://dev.mysql.com/Downloads/MySQL-5.6/MySQL-server-5.6.21-1.rhel5.x86_64.rpm
b.执行以下命令,安装MySQL客户端工具。
rpm -ivh http://dev.mysql.com/Downloads/MySQL-5.6/MySQL-server-5.6.21-1.rhel5.x86_64.rpm
2、登录RDS控制台,单击目标实例ID,选择备份恢复,单击目标备份集右侧恢复,创建新的RDS实例。 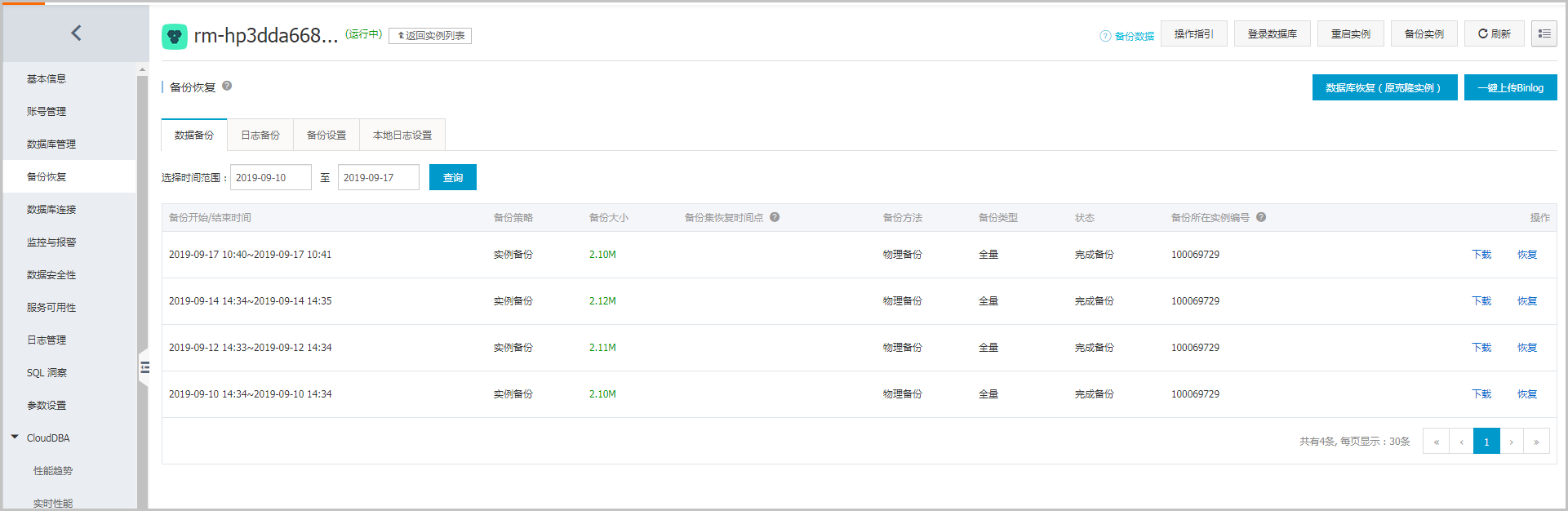
3、确认新实例的数据正常后,您可以将需要的数据从新实例迁移回原实例,详情请参见RDS实例间的数据迁移。
cattt
赞 0
评论 0
本地实例恢复
本地实例恢复请参见RDS备份文件恢复到自建数据库。
增量恢复
1、准备恢复环境: MySQL 5.6:重置root用户的密码,详情请参见官方文档。
MySQL 5.7或8.0:
a.如果您是MySQL 5.7或8.0版本,需要通过skip-grant-tables参数关闭MySQL的认证,再进行授权。
b.登录自建数据库,依次执行以下SQL语句,创建并授权可以远程登录的root用户。
flush privileges;
grant all privileges on *.* to root@'%' identified by '[$Password]';
flush privileges;
说明:[$Password]为root用户的密码。
2、执行以下命令,确定需要开始增量的Binlog位置点。
说明:xtrabackup_binlog_info文件目录请以实际环境为准,可以使用find命令查看。
cat xtrabackup_binlog_info
系统显示类似如下。
mysql-bin.000688 531167 66ef5f51-94f3-11e5-98cf-40a8f034c4d0:1-405320,
72fb7cf6-94f3-11e5-98cf-a0d3c1f98c98:1-3082798,
79f98899-5d2d-11e4-a7c9-ecf4bbc08418:1-365786,
7e88493e-5d2d-11e4-a7c9-ecf4bbc06cb8:1,
a9285f36-9d56-11e4-8a2c-d89d672a9530:1-29549875,
ac2d9725-9d56-11e4-8a2c-d89d672af420:1-4838217
说明:mysql-bin.000688是应用的起始Binlog文件,531167是开始位置点(start position)。
3、从控制台下载备份所在实例编号一致的Binlog文件。本文以mysql-bin.000688和mysql-bin.000689文件为例。
4、依次执行以下命令,使用tar命令解压下载的备份文件。
tar xvpf mysql-bin.000688.tar
tar xvpf mysql-bin.000689.tar
5、通过mysqlbinlog命令分析文件内容,确定增量恢复到的时间点。
mysqlbinlog -v --base64-output=decode-rows mysql-bin.0006XX > 689.log
6、执行以下命令,查看689.log文件,确认想要恢复的时间点。
vi 689.log
7、执行以下命令,进行增量恢复,待命令执行完毕后,增量恢复完成。
mysqlbinlog mysql-bin.000688 mysql-bin.000689 --start-position=531167 --stop-datetime="16-05-16 18:05:03" | mysql -uroot -p[$Password] -P[$Port] -h[$Host_IP]
说明:
-p参数和[$Password]间不要有空格,[$Password]请自行替换为实际密码。
[$Host_IP]参数请指定非127.0.0.1的主机IP。
[$Port]为数据库端口。
mysqlbinlog命令格式如下所示。
mysqlbinlog binlog_file1 binlog_file2 ... binlog_filen --start-position=xxxx --stop-datetime="YY-mm-dd hh:mm:ss" | mysql -uroot -pyour_password -Pmysql_port -hyour_host_ip
--database db_name指定仅增量恢复指定数据库db_name的数据。
--start-position指定开始恢复的Binlog位置点,该位置点应存在于指定的第一个binlog文件。
--stop-position指定恢复到的Binlog位置点,该位置点应存在于指定的最后一个binlog文件。
--start-datetime指定开始恢复的时间点(从第一个等于或大于该时间点的Binlog事件开始)。
以本地时间时区为准,格式为MySQL可以接受的时间格式,比如"2016-05-16 08:01:05"或"16-05-16 08:01:05"。
--stop-datetime指定停止恢复的时间点(在第一个等于或大于该时间点的Binlog事件停止)。
以本地时间时区为准,格式为 MySQL 可以接受的时间格式,比如"2016-05-16 08:01:05" 或 "16-05-16 08:01:05"。
如果您是MySQL 5.7或8.0版本进行增量备份出现以下报错时,需要通过skip-grant-tables参数关闭MySQL的认证,再进行授权。
ERROR 1227 (42000) at line 7: Access denied; you need (at least one of) the SUPER privilege(s) for this operation
cattt
赞 0
评论 0
在使用RDS MySQL的过程中,由于某些原因,例如被SQL注入、SQL执行效率较差、DDL语句引起表元数据锁等待等,会出现运行时间很长的查询。
说明:元数据锁等待的问题请参考解决MDL锁导致无法操作数据库的问题。
由于SQL执行效率差而导致的长时间查询。
由于被SQL注入而导致的长时间查询。
由于DDL语句引起表元数据锁等待。
长时间执行的查询带来的问题
通常来说,除非是BI/报表类查询,否则长时的查询对于应用缺乏意义,而且会消耗系统资源,比如大量长时间查询可能会引起CPU、IOPS和连接数过高等问题,导致系统不稳定。
如何避免长时间执行的查询
避免长时间执行查询的方法请参考如下:
应用方面应注意增加防止SQL注入的保护措施。
在新功能模块上线前,进行压力测试,避免执行效率很差的SQL大量执行。
尽量在业务低峰期进行索引创建删除、表结构修改、表维护和表删除操作。
如何处理长时间执行的查询
cattt
赞 0
评论 0
内存是重要的性能参数,内存使用率过高会导致系统响应速度变慢,严重时内存会耗尽,实例会进行主备切换,导致业务中断。因此我们需要在内存异常升高时及时排查问题,避免影响业务。
1、登录RDS管理控制台,在页面左上角,选择实例所在地域。
2、找到目标实例,单击实例ID。在左侧导航栏中单击 参数设置。
3、将performance_schema参数值修改为ON,如果已经为ON请忽略此步骤。
提示:该操作会重启实例,造成连接中断,重启前请做好业务安排,谨慎操作。
a、单击performance_schema参数右侧的修改按钮,将值修改为ON,然后单击 确定。
b、单击页面右上角 提交参数,等待实例重启完成即可。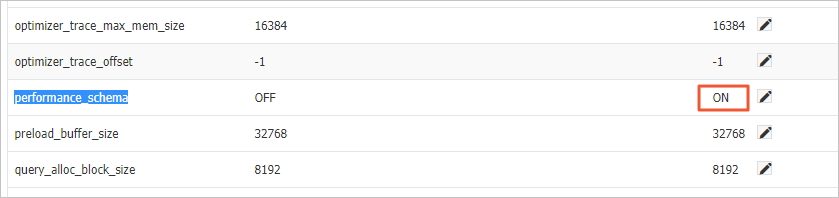
4、使用DMS或客户端连接MySQL实例,依次执行如下SQL语句,打开内存监控。
update performance_schema.setup_instruments set enabled = 'yes' where name like 'memory%';
select * from performance_schema.setup_instruments where name like 'memory%innodb%' limit 5;
注:该命令是在线打开内存统计,所以只会统计打开后新增的内存对象,打开前的内存对象不会统计,建议您打开后等待一段时间再执行后续步骤,便于找出内存使用高的线程。
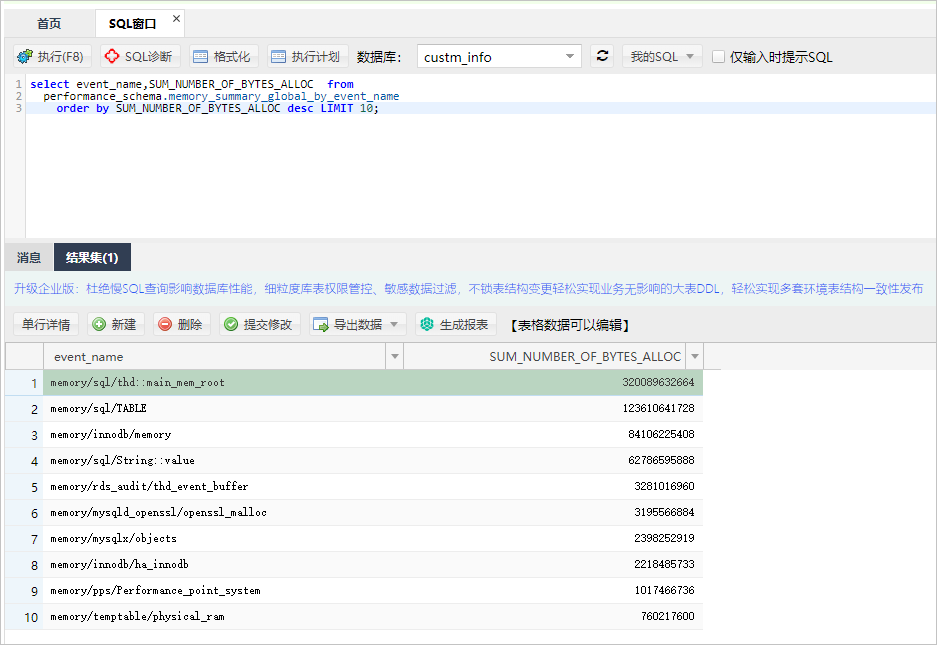
5、您可以参考如下SQL语句统计事件和线程的内存消耗量,并进行排序展示。
a、统计事件消耗内存。
select event_name,
SUM_NUMBER_OF_BYTES_ALLOC
from performance_schema.memory_summary_global_by_event_name
order by SUM_NUMBER_OF_BYTES_ALLOC desc
LIMIT 10;
系统显示类似如下。
b、统计线程消耗内存。
select thread_id,
event_name,
SUM_NUMBER_OF_BYTES_ALLOC
from performance_schema.memory_summary_by_thread_by_event_name
order by SUM_NUMBER_OF_BYTES_ALLOC desc
limit 20;
系统显示类似如下。 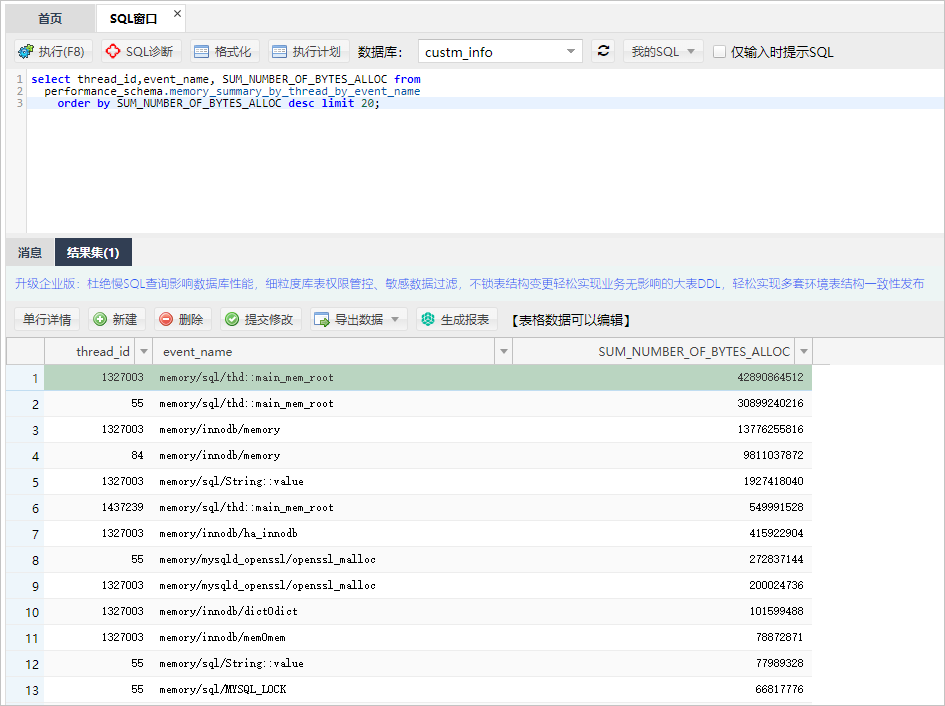
6、找到问题事件或线程后,您可以排查业务代码和环境,解决内存高的问题。
cattt
赞 0
评论 0
前提条件
出现问题后请先确认您的实例版本,不同版本处理方法不同:
对于MySQL 5.6、5.7版本的实例,升级实例存储空间后即可解锁实例,关于如何升级实例存储空间,请参见变更配置,升级后等待一段时间(5分钟左右),RDS实例会进行解锁。若实例存储空间已到最大值,请提交工单联系客服临时解锁实例,再进行后续操作。
对于MySQL 5.5版本的实例,请提交工单联系客服临时解锁实例,再进行后续操作。
注意事项
执行本方案前需要注意以下内容:
清理临时文件有延迟,请耐心等待实例已使用空间的下降。
由于MySQL 5.7开始采用独立的临时表空间ibtmp1,可以通过重启实例或升级磁盘空间的方式释放空间。对于MySQL5.5/5.6实例,在不升级磁盘空间的前提下,比较好的解决方法是在同地域同可用区购买相同配置的RDS实例,通过DTS工具将数据迁移到新实例中。
操作步骤
本小节主要介绍如何迁移数据:
1、同地域同可用区购买相同配置的RDS实例,具体信息请参见创建RDS for MySQL实例。
2、登录RDS管理控制台,在右上角单击迁移数据库进行迁移,具体迁移配置请参见RDS实例间的数据迁移。
后续维护
若锁定问题已解决,请参考以下步骤,预防再次出现锁定问题:
在资源不足时,自动扩容存储空间,详情请参见设置存储空间自动扩容。
避免出现执行效率很差的SQL大量执行的情况。
尽量在业务低峰期进行索引创建删除、表结构修改、表维护和表删除操作。
建议您监控和清理执行时间过长的会话或事务。
cattt
赞 0
评论 0
操作步骤
对于MySQL 5.5、5.6、5.7和8.0版本的实例,在紧急情况下建议扩容实例存储空间,扩容后需要耐心等待一段时间(5分钟左右),方可解锁实例,关于如何升级实例配置,请参见变更配置。若您无法扩容实例存储空间,请参见以下方法处理:
1、通过DMS连接实例,详情请参见通过DMS登录RDS MySQL。
2、执行以下SQL语句,查看数据库的会话。
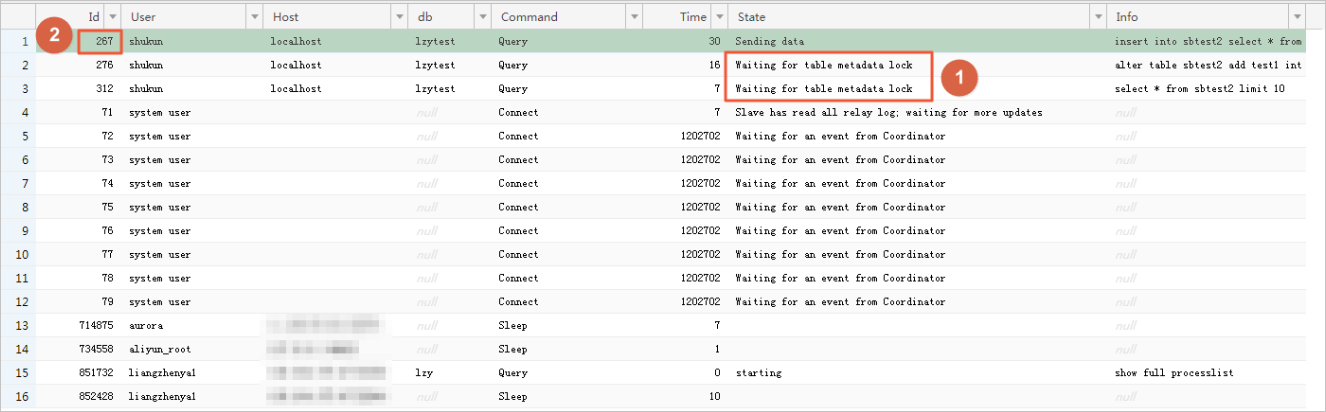
show processlist
3、单击显示结果中的State,进行状态排序,在状态栏查看是否有大量“Copy to tmp table”、“Sending data”等信息,再根据右侧Info列确定是哪个SQL语句在建立临时表,然后记录该语句的ID值。 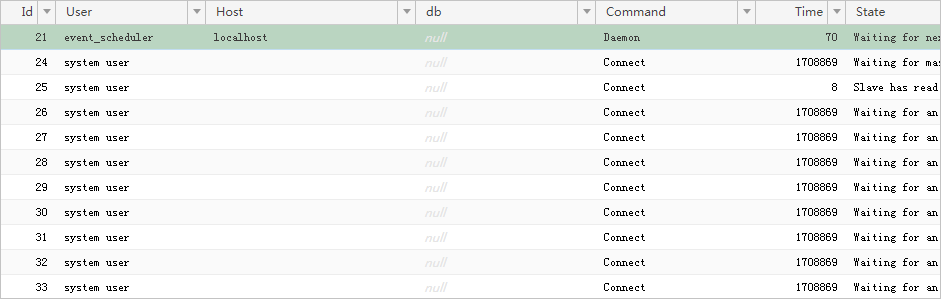
4、执行以下SQL语句,终止会话。
kill [$ID];
说明:[$ID]为上一步获取的ID值,注意确认终止该会话不会影响业务。
后续维护
若锁定问题已解决,请参考以下步骤,预防再次出现锁定问题:
在资源不足时,实例自动扩容存储空间,详情请参见设置存储空间自动扩容。
针对查询产生的临时文件,应该优化SQL语句,避免频繁使用order by、group by操作,可以适当的将tmp_table_size和max_heap_table_size值调大,但是为了减少磁盘使用而调高tmp_table_size和max_heap_table_size并不明智,因为内存资源远比磁盘资源宝贵。您可以通过explain加SQL语句查看是否使用内部临时表,示例如下,在Extra字段中有“Using temporary”字样,则代表会使用内部临时表。
explain select * from alarm group by created_on order by default;
系统显示类似如下。 
针对binlog cache,应该减少执行大事务的情况,尤其应该减少在多个连接同时执行大事务的情况,如果大事务比较多,可以适当将binlog_cache_size值调大,但是同样不建议为了节省磁盘空间调整这个参数,建议使用短连接执行大事务,降低临时空间开销。
建议您监控磁盘使用率,及时清理数据或进行数据拆分,使磁盘使用率不超过80%。
cattt
赞 0
评论 0
MySQL可以通过optimize table语句释放表空间,重组表数据和索引的物理页,减少表所占空间和优化读写性能。但是执行optimize table语句过程时,数据会复制到新建的临时表中,会增加实例的磁盘使用率。当实例剩余磁盘不足以容纳临时表时,建议先扩容磁盘空间,如何扩容请参见变更配置。
通过命令行操作
1、连接MySQL数据库,详情请参见连接MySQL数据库。
2、执行以下SQL语句,释放表空间。
optimize table [$Database1].[Table1],[$Database2].[Table2]
说明:
a、[$Database1]与[$Database2]为数据库名,[Table1]与[Table2]为表名。
b、在innodb引擎中执行optimize table语句时,会出现以下提示信息,该信息是正常执行返回的结果,您可忽略信息。确认返回“ok”即可。详情请参见OPTIMIZE TABLE Statement。
Table does not support optimize, doing recreate + analyze instead
通过DMS操作
1、登录MySQL数据库,详情请参见通过DMS登录MySQL数据库。
2、在左侧选择目标实例的实例ID,然后双击目标库,右键单击任意表名,然后选择批量操作表。
3、勾选需要释放空间的表名,然后依次选择表维护>优化表。 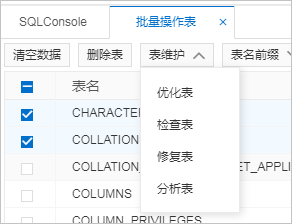
4、在弹出的对话框中确认变更信息正确,然后单击确认即可。
cattt
赞 0
评论 0
前提条件
对于RDS MySQL 5.5、5.6、5.7和8.0版本的实例,建议您提前扩容磁盘,保证磁盘使用率不超过80%,扩容方法请参见变更配置。其次建议您清理无用日志或数据。
注意事项
执行清理无用本地日志步骤前,请先查看以下注意事项:
Binlog文件记录实例的事务信息,是RDS实例高可用和可恢复性的基础,建议不要关闭。可以通过一键上传Binlog功能上传到OSS来释放磁盘空间或者修改本地Binlog设置,详情请参见本地Binlog设置。
清理Binlog文件有延迟,请耐心等待实例日志空间使用量的下降。
一键上传Binlog会在后台异步提交清理任务,且清理任务会将已写入的Binlog上传到OSS(非用户购买的OSS)上,然后再从实例空间中删除Binlog文件,当前正在被写入的Binlog文件由于未完成写入,是不可以被清理的。因此,清理过程会有一定延迟,建议您单击一键上传Binlog后耐心等待一定时间,请勿多次单击该按钮,可以在基本信息页中查看磁盘空间是否减小。
由于DML等操作(比如涉及大字段的DML操作)会快速生成Binlog,可能会导致上传Binlog文件到备份空间并且从实例空间中删除的处理速度跟不上实例生成Binlog文件的速度,在这种情况下,建议您考虑升级磁盘空间,并且排查Binlog快速生成的原因。
一键上传Binlog
1、登录RDS管理控制台,在页面左上角,选择实例所在地域。
2、找到目标实例,单击实例ID。
3、在左侧导航栏中单击备份恢复。
4、在右上角单击一键上传Binlog,在弹出的对话框中单击确定。
说明:
a、一键上传Binlog功能会有一定延迟,请耐心等待15分钟左右。
b、本操作会删除除最新的两个本地日志文件外的所有日志文件,如果只有两个日志文件,本操作不会删除任何文件。
c、基础版实例不支持一键上传Binlog功能,建议您参见修改本地日志(Binlog)文件设置删除本地日志。 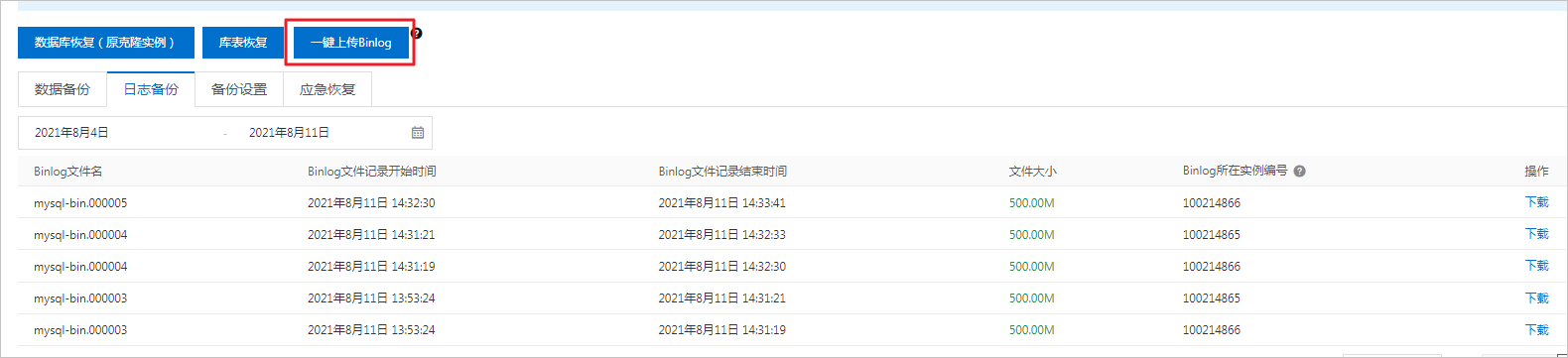
修改本地日志(Binlog)文件设置
1、登录RDS管理控制台,在页面左上角,选择实例所在地域。
2、找到目标实例,单击实例ID。
3、在左侧导航栏中单击备份恢复。
4、选择本地日志设置页签,单击本地日志保留策略,根据您的实际情况,设置对应的值。
说明:保留时长若设置为0,表示本地不保存Binlog日志,直接上传至OSS。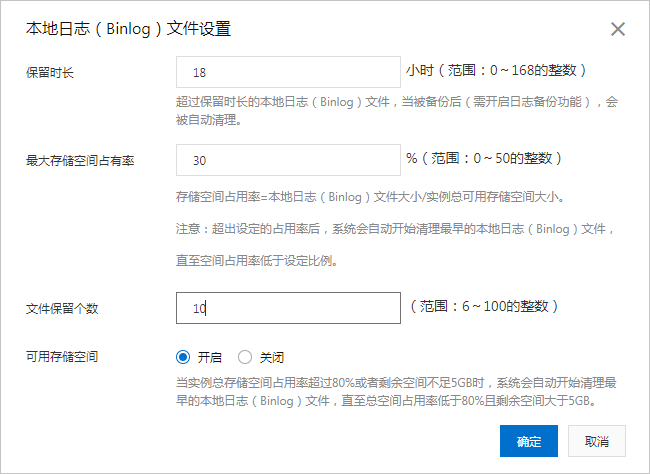
后续维护
若锁定问题已解决,为了预防再次出现锁定问题,建议设置在资源不足时,实例自动扩容存储空间的功能,详情请参见设置存储空间自动扩容。
cattt
赞 0
评论 0
前提条件
请确认您的RDS MySQL实例版本是否可以执行操作步骤。
确认内核小版本大于等于20190815。如果内核小版本小于20190815,需要在升级后才能执行清理数据的操作,如何升级小版本请参见升级内核小版本。 
请提交工单联系客服临时解锁实例,再进行后续操作。
注意事项
操作步骤
根据实际情况选择相应的方法处理。
扩容实例
您可以扩容磁盘空间,具体扩容操作请参见变更配置。等待一段时间(5分钟左右),RDS实例会进行解锁。
删除无用数据
1、通过DMS连接实例,详情请参见通过DMS登录RDS MySQL。
2、执行以下SQL语句,查看数据库的文件大小,确认其中可以删除的历史数据或无用数据。
SELECT file_name, concat(TOTAL_EXTENTS,'M') as 'FIle_size' FROM INFORMATION_SCHEMA.FILES order by TOTAL_EXTENTS DESC
系统显示类似如下。
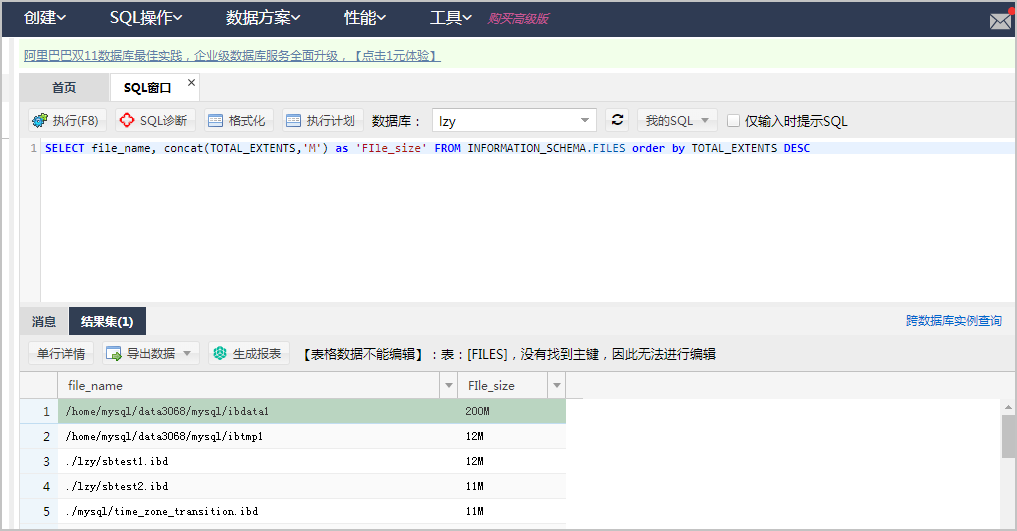
3、使用drop或者truncate命令清理数据。
a、drop:使用drop table [$Databases_Name].[$Table_Name]SQL语句,删除不需要的表。
说明: [$Databases_Name]为数据库的库名。 [$Table_Name]为表名。
b、truncate:使用truncate table [$Databases_Name].[$Table_Name]SQL语句,删除不需要的表。
4、清理后需要耐心等待一段时间(5分钟左右),RDS实例才会解锁。
后续维护
若锁定问题已解决,请参考以下步骤,预防再次出现锁定问题:
在资源不足时,实例自动扩容存储空间,详情请参见设置存储空间自动扩容。
对于经常有删除操作的表,容易产生数据空洞,建议在业务低峰期使用以下SQL语句回收空间。有关optimize table命令请参见释放MySQL实例的表空间。
optimize table [$Databases_Name].[$Table_Name]
cattt
赞 0
评论 0
连接数满会导致客户端无法连接到RDS for MySQL数据库。通常是由空闲连接过多、和活动连接过多两种原因导致的。
空闲连接过多
通过DMS或者kill命令来终止当前空闲会话,详细步骤请参见RDS for MySQL如何终止会话。
修改应用,长连接模式需要启用连接池的复用功能(建议也启用连接检测功能)。
修改应用,短连接模式需要在代码中修改查询结束后调用关闭连接的方法。
对于非交互模式连接,在控制台的参数设置里设置wait_timeout参数为较小值。wait_timeout参数控制非交互模式连接的超时时间(单位秒,默认值为24小时即86400秒),当非交互式连接空闲时间超过wait_timeout指定的时间后,RDS实例会主动关闭连接。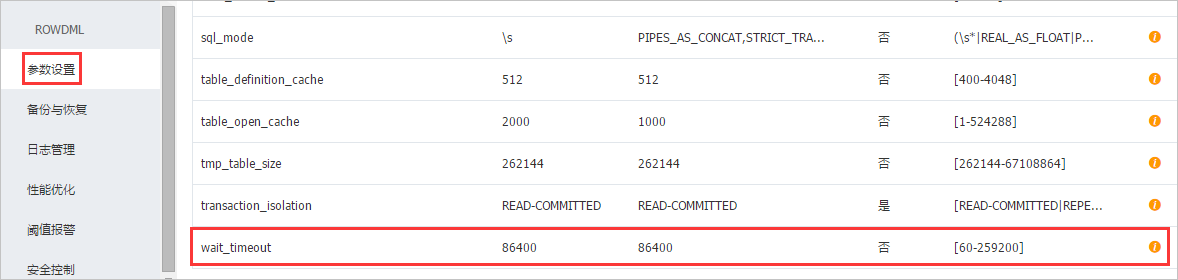
对于交互模式连接,在控制台的参数设置里设置interactive_timeout参数为较小值。interactive_timeout参数控制交互模式连接的超时时间(单位秒,默认值为2小时即7200秒),当交互式连接空闲时间超过interactive_timeout指定的时间后,RDS实例会主动关闭连接。
活动连接过多
cattt
赞 0
评论 0
通过自治服务(CloudDBA)访问实例诊断报告
1、登录RDS管理控制台,单击实例列表,选择目标实例所在地域。然后单击目标实例ID,进入基本信息页面。
2、在左侧导航栏中,依次单击自治服务>诊断报告,进入诊断报告页面。
已经进行过诊断:在诊断报告页面单击实例诊断报告列表右侧的查看报告,即可查看实例诊断报告的详细信息。
如果没有进行过诊断:
a、在诊断报告页面单击发起诊断。
b、选择需要发起诊断的时间范围,然后单击确认,查看诊断报告即可。
说明: 诊断报告列表可以保存最近30天内的诊断记录,超过时间后数据将会被自动删除。 PostgreSQL 10.0版本和PPAS 10.0版本无法选择起始时间,默认生成当前时间的诊断报告。 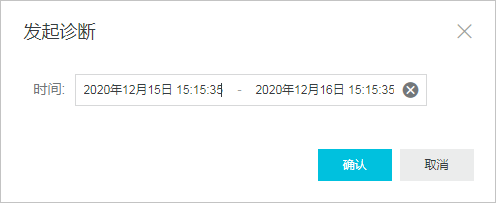
通过数据库自治服务访问实例诊断报告
1、登录数据库自治服务控制台,单击实例监控,单击目标实例ID。
说明:如果您控制台没有发现您的实例,需要您参见实例接入简介先接入数据库实例。
2、单击左侧的诊断报告,即可查看已有的报告。如果您还需要进行诊断,可以单击左上角的发起诊断,生成新的诊断报告。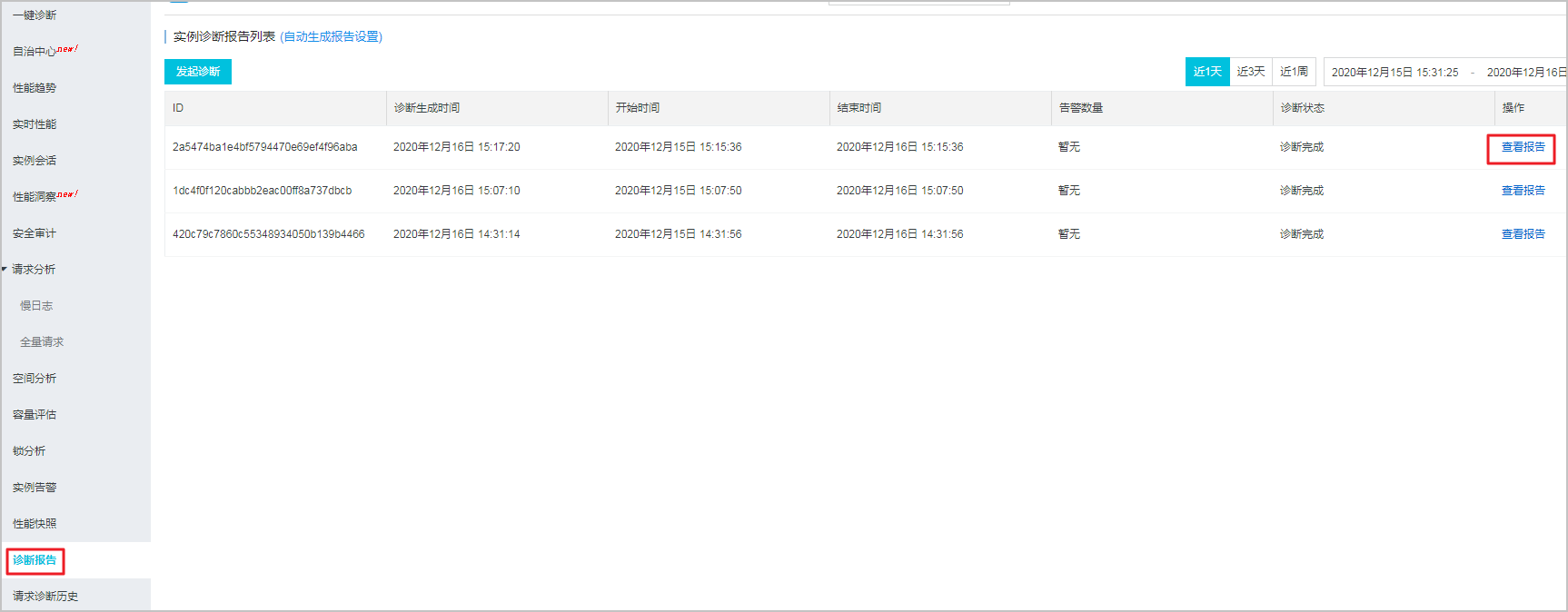
通过DMS访问实例诊断报告
1、登录RDS管理控制台,单击实例列表,选择目标实例所在地域。然后单击目标实例ID,进入基本信息页面。
2、单击页面右上角的登录数据库,进入数据管理控制台页面,输入对应的数据库信息登录即可。
3、右键单击目标实例,依次选择性能>一键诊断,此时会跳转到数据库自治服务(Database Autonomy Service,简称DAS)。
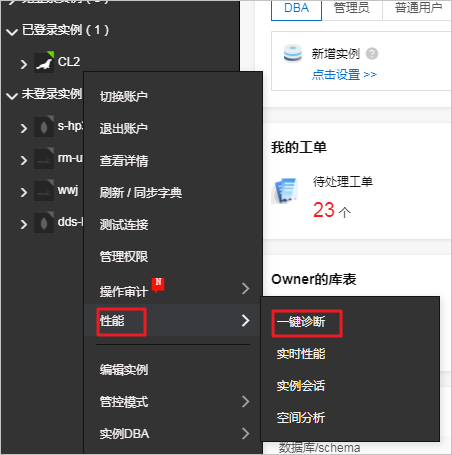
说明:对于第一次登录DAS的用户需要对DAS进行授权。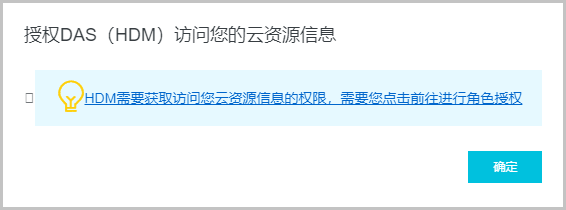
4、单击左侧的诊断报告,即可查看已有的报告。如果您还需要进行诊断,可以单击左上角的发起诊断,生成新的诊断报告。
cattt
赞 0
评论 0
查看空间使用状况
方法一
通过RDS管理控制台的监控页面查看空间使用情况,详情请参见查看资源和引擎监控。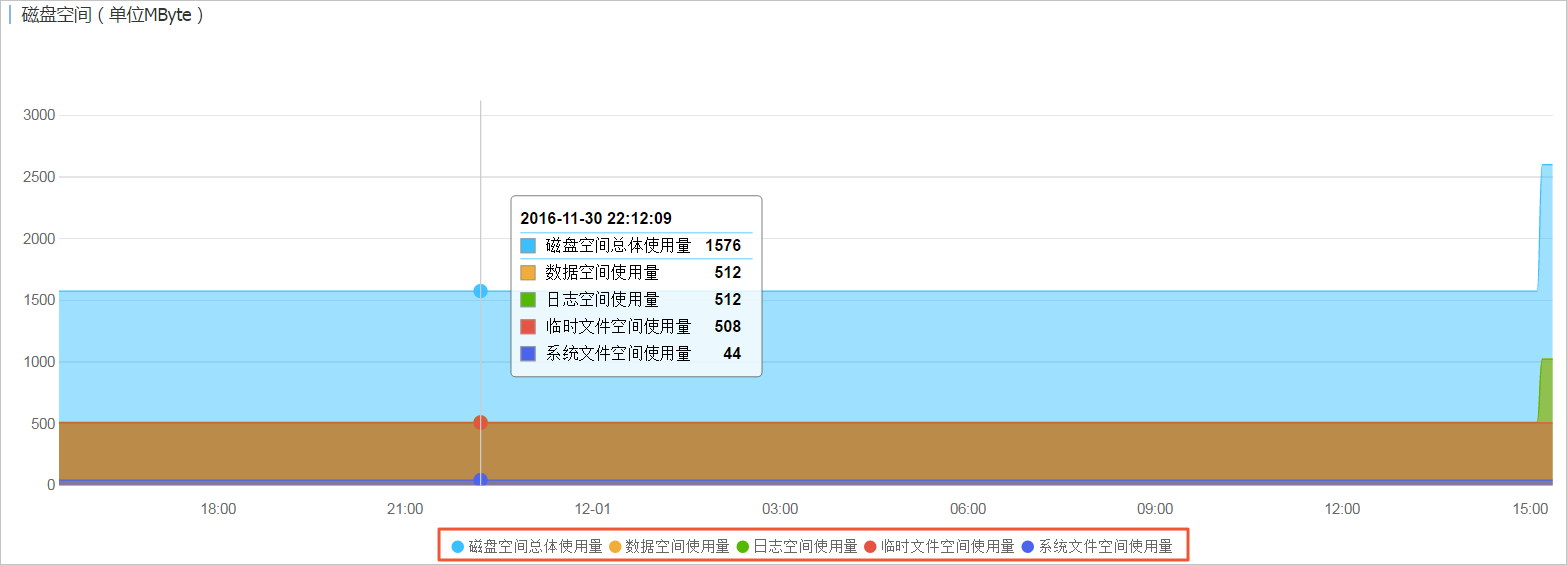 参数说明如下。
参数说明如下。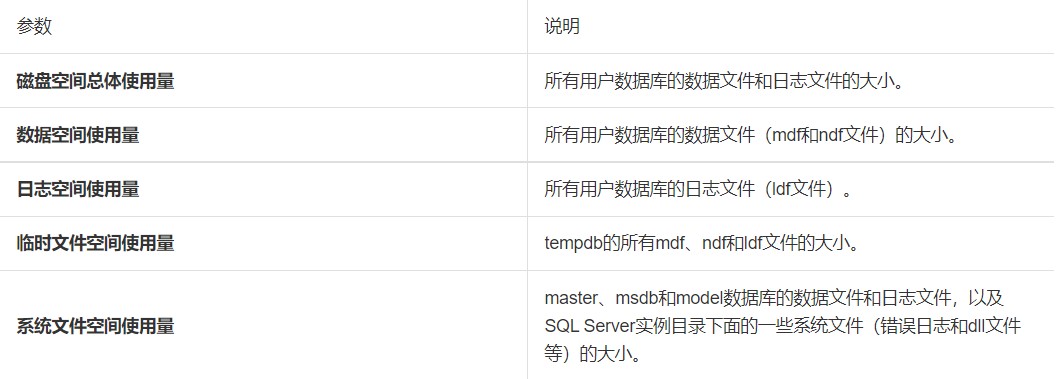
方法二
通过SQL语句查看所有数据库的数据文件(mdf和ndf文件)和日志文件(ldf文件)的大小,详情请参见RDS for SQL Server如何查看实例、数据库及表占用的空间大小。
方法三
可是用相关工具查看空间使用状况,具体使用方法可参见SQL Server数据库空间查看工具。
解决空间满自动锁问题
升级实例的存储空间
升级实例存储空间后即可解锁实例,关于如何升级实例存储空间,请参见变更配置,若实例存储空间已到最大值,请提交工单联系客服临时解锁实例,再进行后续操作。
日志文件占用量高的解决方法
解决方法一
1、客户端连接实例后执行以下语句。
select name,log_reuse_wait,log_reuse_wait_desc from sys.databases;
2、若log_reuse_wait_desc的值是LOG_BACKUP,请收缩事务日志。 说明:若日志文件非常大,日志备份的时间会比较长,并且在收缩日志文件时,如果遇到未提交的事务,会导致单次收缩效果不明显。在单次收缩效果不明显的情况下,建议您再次收缩事务日志。
解决方法二
事务日志增长过快的根本原因是事务较多或者有大事务。例如,一个事务中操作了500万行数据,在有这种大事务的情况下,建议您将事务拆分,每个事务操作10万行数据,分50次执行。
a、依次执行以下SQL语句,查看数据库的空闲空间。
USE [$DB_Name];
SELECT SUM(unallocated_extent_page_count) AS [free pages],
(SUM(unallocated_extent_page_count)*1.0/128) AS [free space in MB]
FROM sys.dm_db_file_space_usage;
说明:[$DB_Name]指数据库名。
b、找到空间使用率较高的数据库,然后执行以下语句,收缩该数据库。
DBCC SHRINKDATABASE([$DB_Name]);
也可以执行以下命令来收缩单个文件。
DBCC SHRINKFILE(file_id,[$Size]);
说明:[$Size]指收缩以后的大小,而不是要收缩多少,单位MB。
a、重启实例来快速释放临时文件的空间。
b、及时释放临时表、行版本、表变量等。
cattt
赞 0
评论 0
1、使用客户端连接实例,请参见连接实例。
2、执行如下SQL语句,查看各个数据库的内存使用情况。
select count(*)*8/1024 as 'cache size(MB)',
case database_id
when 32767 then 'ResourceDb'
else DB_NAME(database_id)
end as 'datebase'
from sys.dm_os_buffer_descriptors
group by DB_NAME(database_id),
database_id
order by 'cache size(MB)' desc
3、若需要查看sys.dm_os_memory_clerks表的内存使用情况,则执行如下SQL语句。
select * from sys.dm_os_memory_clerks
cattt
赞 0
评论 0
一键诊断
推荐您使用该方式进行处理。
注意:您也可以生成实例诊断报告,分析处理问题,详情请参见诊断报告。
1、登录RDS控制台。
2、单击实例列表,单击目标实例ID。
3、选择自治服务>一键诊断。
4、查看当前实例活跃会话,确认SQL语句中执行的时间较长且状态为“sending data”。 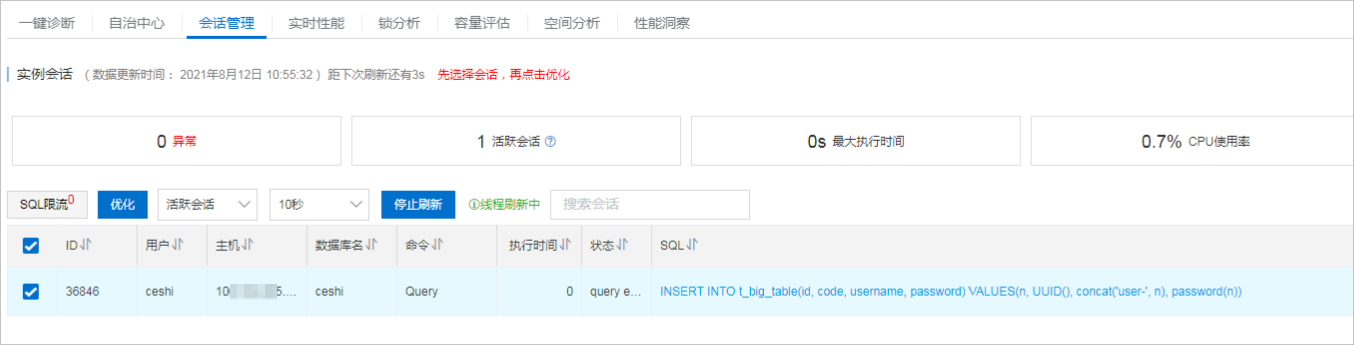
5、勾选该会话,单击优化,通过优化中的建议,根据您实际情况做出相应优化,例如是否需要创建索引。 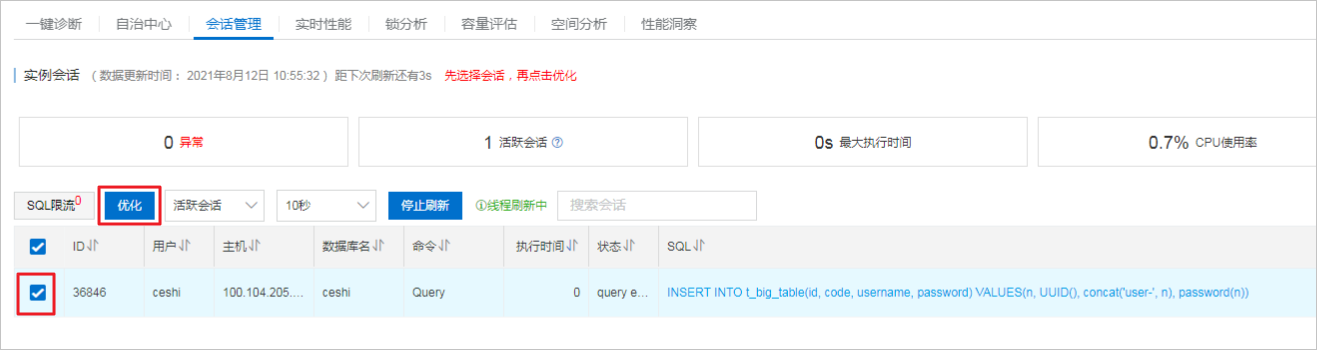
6、若没有直接给出优化建议,单击左侧导航栏的慢SQL,结合会话列表和慢SQL信息进行优化。
结束问题查询
您可以通过DMS控制台上的实例会话或命令查询或结束问题查询,建议您结束物理读(Physical_sync_read和Physical_async_read)高的查询。
说明:RDS实例在连接数满的情况下,无法通过DMS或者MySQL命令行工具连接登录实例,建议您先在RDS控制台的参数设置中将wait_timeout参数(单位秒)设置为比较小的值(比如60),让RDS实例主动关闭空闲时间超过60秒的连接,以便稍后可以通过DMS或者MySQL命令行工具连接访问实例。
通过实例会话结束问题查询
注意:需要业务应用先停止提交问题查询的操作,否则会出现不断重连的情况。
在一键诊断的会话管理页面。选中目标会话,单击结束选中会话即可。 
通过命令行结束问题查询
1、通过DMS连接实例,详情请参见通过DMS登录RDS MySQL。
2、执行show processlist;SQL语句查询,查看当前执行的查询语句。 说明:若当前执行会话比较多,您也可以执行show full processlist;语句进行查询。
3、执行以下SQL语句,结束相关会话。 kill [$ID] 说明:[$ID]为上一步查询结果中ID列的值。
通过SQL诊断功能优化查询
1、通过DMS控制台登录实例。
2、单击页面上方的SQL窗口,选择对应的库。
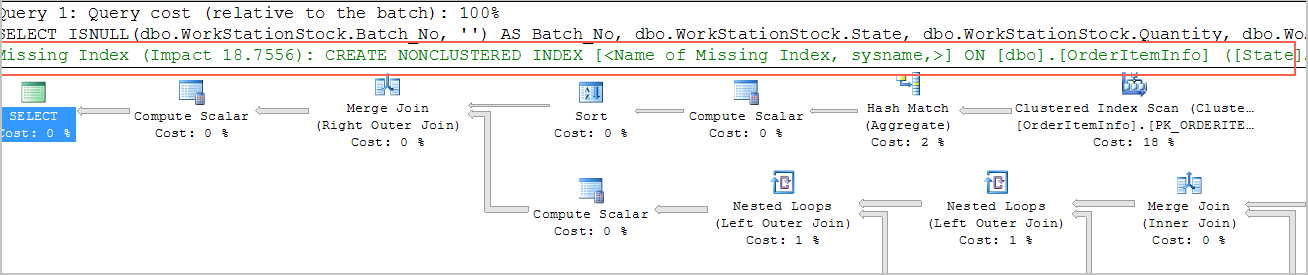
3、将查询语句粘贴到SQL窗口,单击SQL诊断,即可得到优化建议。
4、根据您实际情况,选择优化建议进行处理。例如添加索引,确认执行查询成本会大幅减少。
cattt
赞 0
评论 0
应用负载(QPS)高
对于因应用负载高导致CPU使用率高的状况,使用SQL进行优化的余地不大,建议您从应用架构、实例规格等方面来处理问题。请参考以下方法:
升级实例规格,增加CPU资源,详情请参见变更配置。
增加只读实例,将对数据一致性不敏感的查询(比如商品种类查询、列车车次查询)转移到只读实例上,分担主实例压力,详情请参见创建MySQL只读实例。
使用阿里云PolarDB-X云原生分布式数据库,自动进行分库分表,将查询压力分担到多个RDS实例上。
使用阿里云云数据库Memcache或者云数据库Redis,尽量从缓存中获取常用的查询结果,减轻RDS实例的压力。
对于查询数据比较静态、查询重复度高、查询结果集小于1MB的应用,考虑开启查询缓存(Query Cache)。
说明: 能否从开启查询缓存(Query Cache)中获益需要经过测试,具体设置请参见RDS MySQL 版查询缓存(Query Cache)的设置和使用。
慢SQL导致查询成本高
解决该问题的原则:定位效率低的查询、优化查询的执行效率、降低查询执行的成本。
1、通过以下方式定位效率低的查询:
show processlist;
show full processlist;
系统显示类似如下。  查询时间长、运行状态为Sending data、Copying to tmp table、Copying to tmp table on disk、Sorting result、Using filesort的查询会话可能均包含性能问题。
查询时间长、运行状态为Sending data、Copying to tmp table、Copying to tmp table on disk、Sorting result、Using filesort的查询会话可能均包含性能问题。
若在QPS高导致CPU使用率高的场景中,查询执行时间通常比较短,show processlist;命令或实例会话中可能会不容易捕捉到当前执行的查询。但是您可以通过执行以下SQL语句进行查询。 explain [$SQL]
您可以通过执行类似kill [$ID];的命令来终止长时间执行的会话,终止会话请参见RDS MySQL 版如何终止会话。关于长时间执行会话的管理,请参见RDS MySQL 版管理长时间运行查询。 说明:[$ID]为该查询语句对应的会话ID。
通过数据库自治服务DAS查看当前执行的查询:
a.登录数据库自治服务控制台。
b.依次单击目标实例右侧的性能>实例会话。  c.单击SQL列中的查询文本,即可显示完整的查询和其执行计划。
c.单击SQL列中的查询文本,即可显示完整的查询和其执行计划。
2、得到需要优化的查询语句后,可以通过DMS控制台上的SQL诊断来获取优化建议。诊断报告同样适用于排查历史实例CPU使用率高的问题:
a.通过DMS控制台登录实例。
b.单击页面上方的SQL窗口,选择对应的库。
c.将查询语句粘贴到SQL窗口,单击SQL诊断,即可得到优化建议。 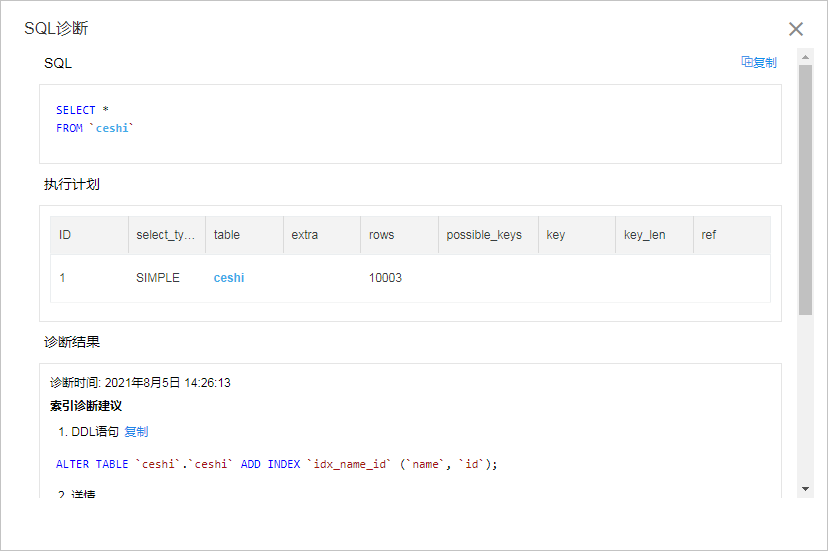
3、根据您实际情况,选择优化建议进行处理。例如添加索引,确认执行查询成本会大幅减少。
cattt
赞 0
评论 0
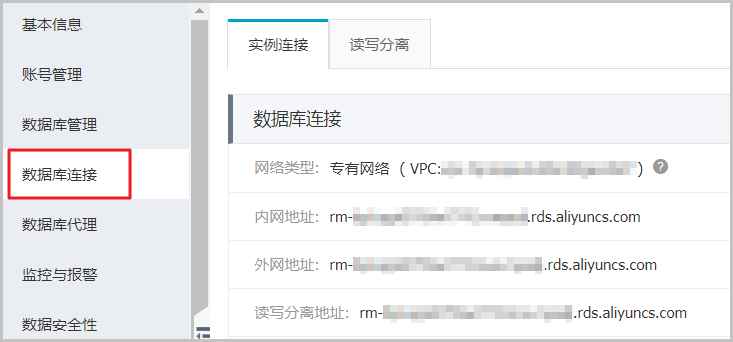
1、检查您使用的连接地址是否为RDS的内网地址。如果是,需要改为外网地址。 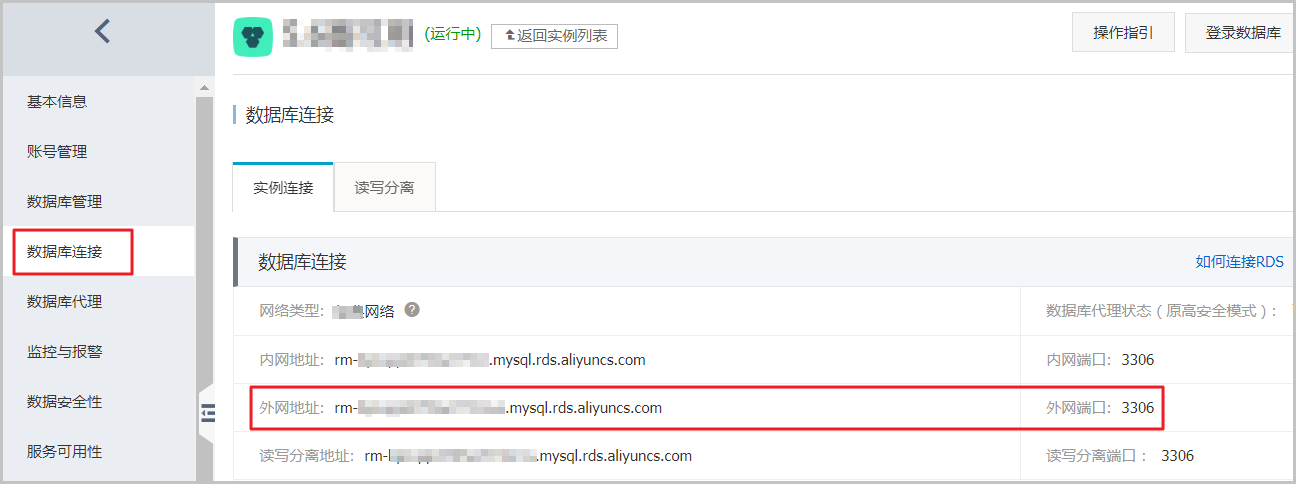
说明:
如果RDS实例没有外网地址,请申请外网地址。
ECS和DMS以外的设备无法通过内网访问RDS(除非使用物理专线)。
2、检查是否已设置RDS白名单。如果未设置,请参见设置白名单。 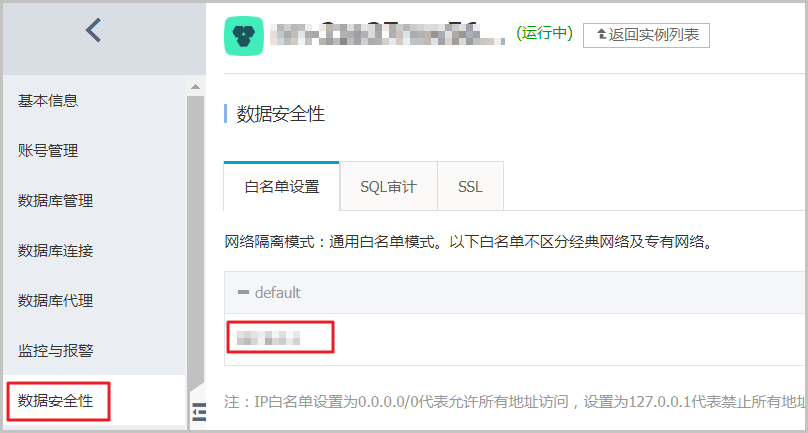
3、检查白名单是否设置成了0.0.0.0。正确格式为0.0.0.0/0。
说明:
该地址允许任何设备访问RDS实例,有安全风险,请谨慎使用。
4、如果您已设置白名单,那么连接失败很可能是因为您在白名单中添加的设备公网IP地址并非设备真正的出口IP地址。原因如下所示。
说明: 关于确认设备公网IP地址的方法,请参见定位本地IP。
公网IP地址不固定,可能会变动。
IP地址查询工具或网站查询的公网IP地址不准确。
cattt
赞 0
评论 0
参考以下方法解决问题:
白名单中只有默认地址127.0.0.1。该地址表示不允许任何设备访问RDS实例。需在白名单中添加设备的IP地址,具体操作请参见设置白名单。
白名单设置成了0.0.0.0。正确格式应该为0.0.0.0/0。
说明:该地址允许任何设备访问RDS实例,请谨慎使用。
1、如果使用的是专有网络的内网连接地址,请确保ECS内网IP地址添加到了专有网络的分组。
2、如果使用的是经典网络的内网连接地址,请确保ECS内网IP地址添加到了经典网络的分组。
3、如果通过公网连接,请确保设备公网IP地址添加到了经典网络的分组,专有网络的分组不适用于公网。
1、公网IP地址不固定,可能会变动。
2、IP地址查询工具或网站查询的公网IP地址不准确。
说明:关于确认设备公网IP地址的方法,请参见以下链接。
RDS for MySQL或MariaDB TX如何定位本地IP地址
RDS for PostgreSQL或PPAS如何定位本地IP地址
cattt
赞 0
评论 0
ECS通过内网无法访问RDS的解决办法
1、检查ECS实例的内网IP地址是否已添加到RDS实例的白名单。如果未添加,可以在实例列表页面中查看实例IP。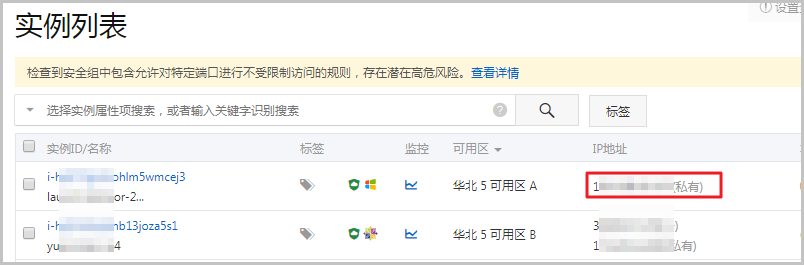 2、然后在RDS控制台中添加白名单,详情请参见设置白名单。
2、然后在RDS控制台中添加白名单,详情请参见设置白名单。 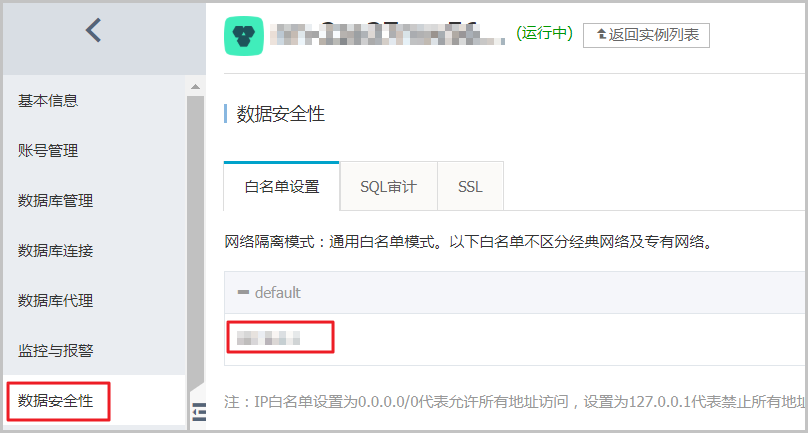
3、检查白名单是否设置成了0.0.0.0,正确格式应该为0.0.0.0/0。
说明:该地址允许任何设备访问RDS实例,有安全风险,请谨慎使用。
4、如果开启了高安全白名单模式,请进行以下检查:
ECS以外的设备无法访问RDS的解决办法
ECS以外的设备访问RDS时,可以通过外网地址进行连接。如果通过外网地址连接失败,解决办法如下所示。
1、检查是否已设置RDS白名单。如果未设置,请参见设置白名单。 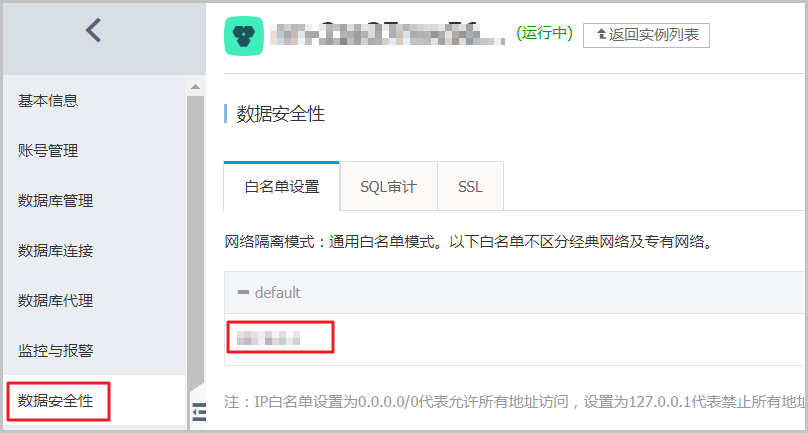
2、检查白名单是否设置成了0.0.0.0。正确格式为0.0.0.0/0。
说明:该地址允许任何设备访问RDS实例,有安全风险,请谨慎使用。
3、如果开启了高安全白名单模式,需确保设备公网IP地址是添加到了经典网络的分组。
说明:专有网络的分组不适用于公网。
4、如果您已设置白名单,那么连接失败很可能是因为您在白名单中添加的设备公网IP地址并非设备真正的出口IP地址。原因如下所示。
说明:关于确认设备公网IP地址的方法,请参见定位本地IP。
公网IP地址不固定,可能会变动。
IP地址查询工具或网站查询的公网IP地址不准确。
cattt
赞 0
评论 0
本文只适用于ECS以外的设备访问RDS实例的情况。如果是ECS实例访问RDS实例,可以在ECS实例的详情页面查看准确的公网IP地址和内网IP地址。
单击 数据库,选择 postgres,单击页面上方的 工具 > 查询工具。 
执行如下SQL语句,查看显示结果中 query 列的值为 SELECT 所对应的client_addr列的IP,即为本地设备公网IP。
select datname, pid, usename,client_addr, client_hostname, client_port,query from pg_stat_activity;
系统显示类似如下。 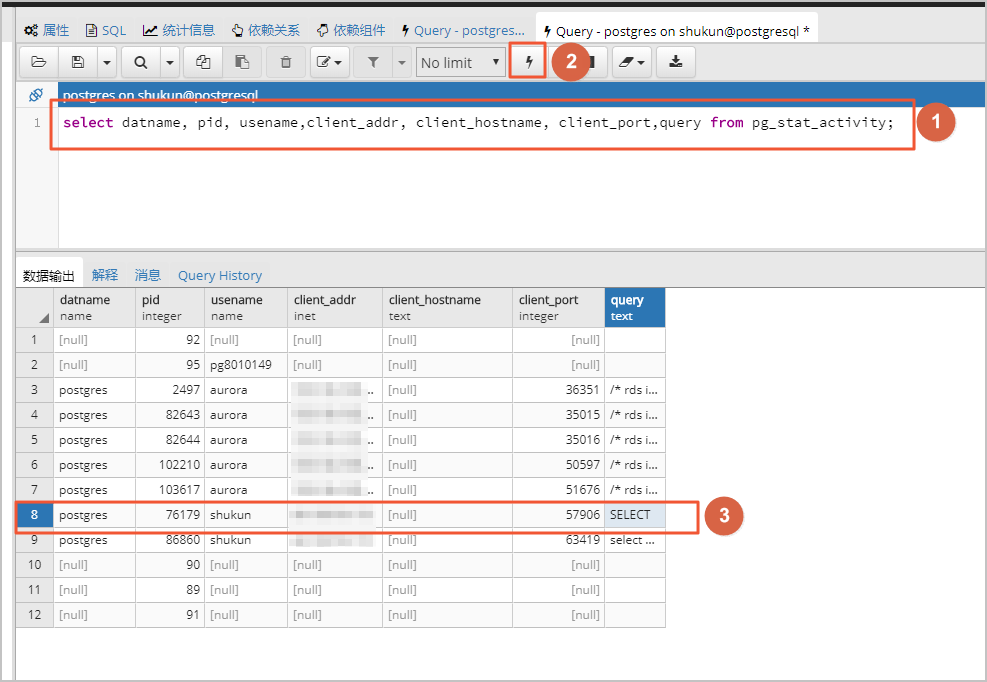
cattt
赞 0
评论 0
连接数过多导致客户端无法连接到RDS PostgreSQL数据库,并提示以下错误。
FATAL: remaining connection slots are reserved for non-replication superuser connections
解决方案
若还有剩余的会话窗口请参考以下步骤,在剩余的会话窗口中执行以下结束连接数进程。如果没有剩余的连接会话窗口且不方便执行重启实例的操作,请提交工单联系阿里云技术支持。
1、选择SQL操作>SQL窗口,执行以下SQL语句,检查当前连接数的限制。
show max_connections;
系统显示类似如下。 
2、执行以下SQL语句,查看当前连接数并记录将要结束的连接数PID。
select * from pg_stat_activity;
系统显示类似如下。 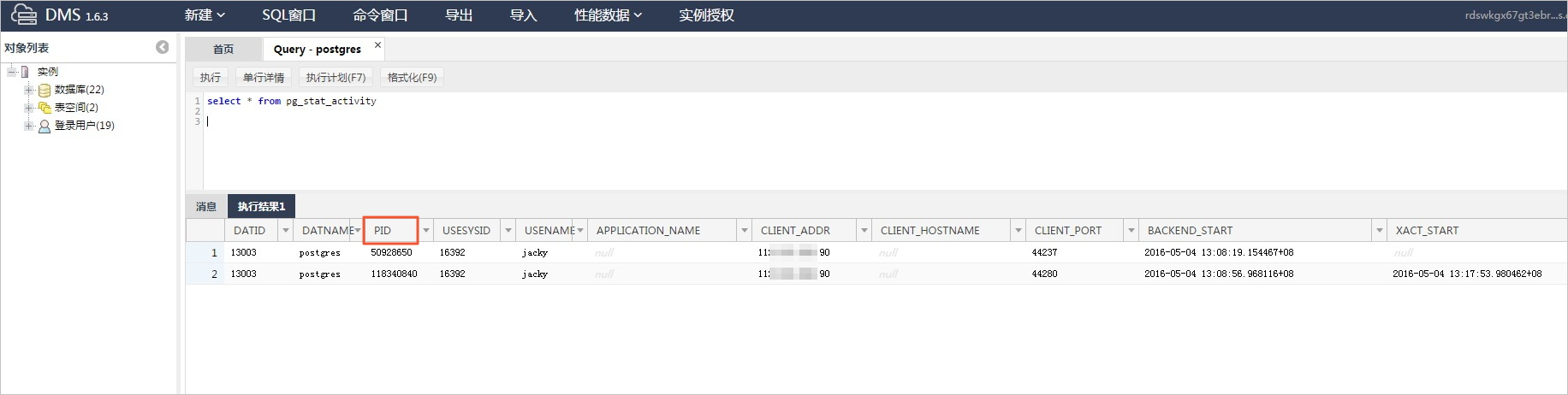
cattt
赞 0
评论 0
String userName = "XXX";
String userPwd = "XXX";
String url="jdbc:sqlserver://rds.sqlserver.rds.aliyuncs.com:3433;DatabaseName=dbtest";
java.sql.Connection dbConn = DriverManager.getConnection(url, userName, userPwd);
Object sta = dbConn.createStatement();
String sql = "create table student"+ "(id int , name varchar(10))";
int row = ((Statement) sta).executeUpdate(sql);
System.out.println("successfully");
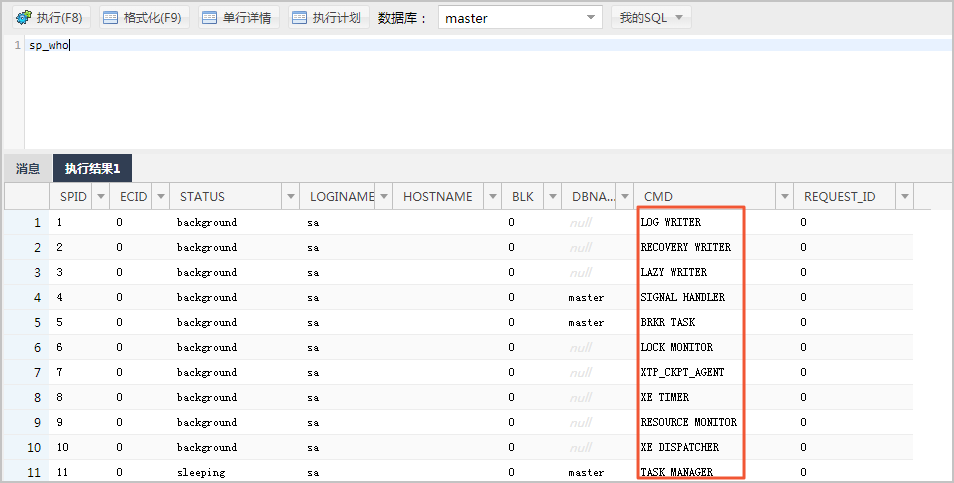
主要介绍RDS MySQL的如下2种方式来终止会话。
通过DMS终止
登录RDS数据库,关于如何登录RDS数据库,请参考通过DMS登录RDS数据库。
在页面上方选择 性能 > 实例会话。 
在弹出的会话框中选择新版并进行授权,仅首次登录需授权。
通过Shift、Ctrl键选择多个会话,然后通过kill选中会话按钮来终止相关会话。 
通过kill命令终止
提示:RDS实例在连接数已满的情况下,是无法通过DMS或者MySQL命令行工具连接实例的。如果无法通过DMS或MySQL命令行工具连接,建议先在控制台的参数设置中将wait_timeout参数(单位秒)设置为比较小的值(比如60),让RDS实例主动关闭空闲时间超过60秒的连接,以便稍后可以通过DMS或者MySQL命令行工具连接访问实例。
show processlist;
系统显示类似如下。 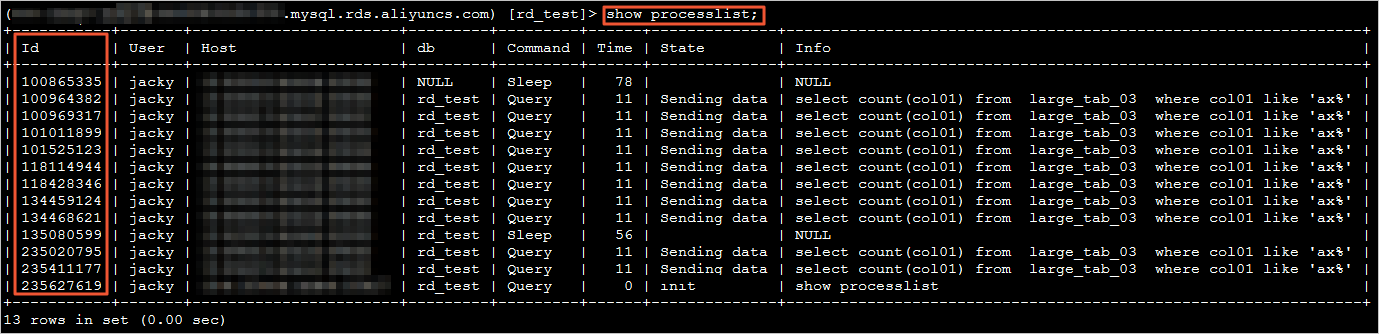
kill [$ID];
注:[$ID]为上一步记录的Id。
系统显示类似如下。 
cattt
赞 0
评论 0
默认情况下,不同账号下的ECS和RDS之间无法通过内网互通。您可以通过下列方法,最终达成ECS访问另外其他账号下的RDS实例,推荐使用方法一。
方法一:迁移RDS实例到ECS所属的阿里云账号
具体操作如下:
1.用ECS实例所属的阿里云账号重新购买RDS实例,详情请参见购买RDS实例。
2.将原RDS实例的数据迁移到新的RDS实例,详情请参见RDS实例间的数据迁移。
3.释放原RDS实例。
方法二:云企业网或VPN网关
如果一定要保持ECS和RDS在不同的阿里云账号下,则参考下列步骤:
1.确保ECS和RDS的网络类型都是VPC。
方法三:公网访问
不通过内网访问RDS,而通过公网访问RDS。详情请参见如何连接到RDS。
cattt
赞 0
评论 0
阿里云帮助中心: https://help.aliyun.com/
阿里云内容设计团队出没于此,一大波优质阿里云相关内容随时袭来~





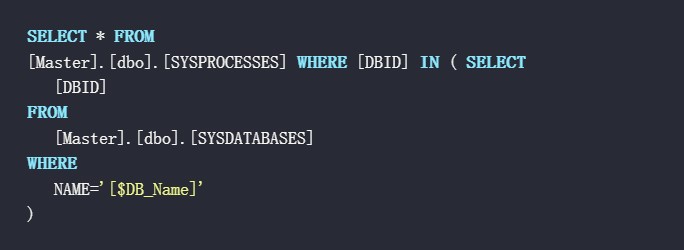 说明:[$DB_Name]为数据库名。
说明:[$DB_Name]为数据库名。