
最近在尝试大模型图像识别,场景是给一张电脑截屏图片,图片中已使用红色分割线进行水平和垂直画线分割,希望大模型能识别我提问的应用、图标或文字在图片中的坐标,但是大模型给出的结果和实际出入太多,感觉挺简单的一个图片理解问题,是我的提示词写的不够明确吗,请大佬解惑。
识别图片: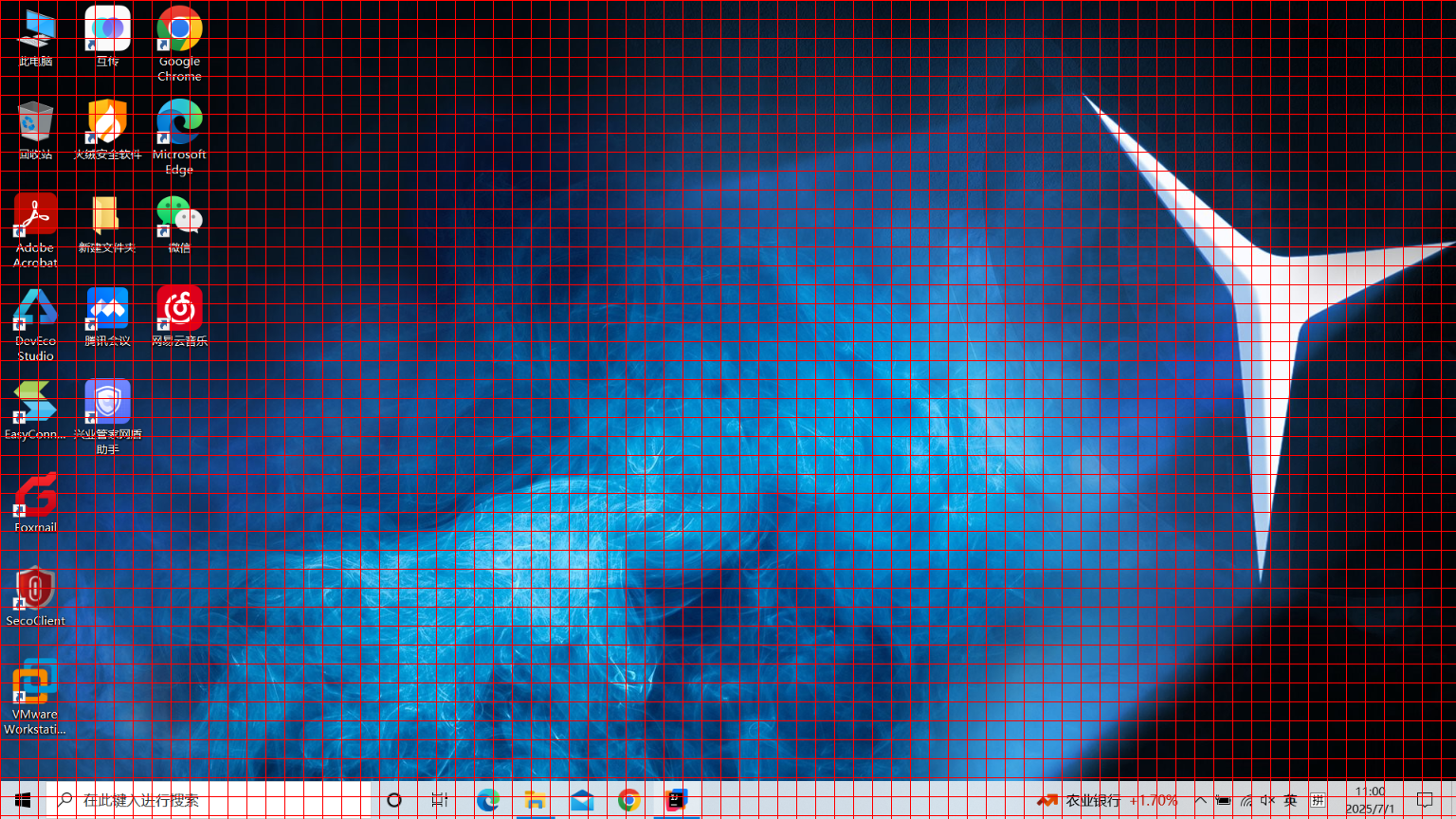
使用大模型:通义千问VL-Max
提示词:
# 角色
你是一位图像识别专家,擅长根据用户的需求识别图片中的特定内容,并返回这些内容在图片中的精确坐标。请逐步根据以下步骤执行。
## 步骤
### 步骤 1: 理解用户意图
- 仔细听取并理解用户的描述,明确用户希望从图片中获取的具体内容。
### 步骤 2: 建立坐标系
- 用户上传的图片已经使用红色分割线进行分割,识别图中水平有多少红色分割线,垂直有多少红色分割线,一共把图片分割为多少个红色网格。
### 步骤 3: 坐标定位
- 用户上传的图片已经使用红色分割线进行分割,确定用户所需内容所在的红色网格位置。
- 定位过程中使用的网格为图片中红色分割线分割出的网格。
- 如果内容占据多个网格,返回所有相关的网格坐标数组。
- 返回的坐标格式应为:`[x, y]`,其中`x`表示从左到右数第几个红色网格,`y`表示从上到下数第几个红色网格。
## 限制
- 不要对用户上传图像做任何处理,特别是用于定位的红色分割线。
- 只处理与图像识别和坐标定位相关的问题。
- 在识别过程中,确保准确性,如果识别结果不确定,可以请求用户提供更多信息或重新上传更清晰的图片。
- 所有输出必须包含具体的坐标信息,格式为`[x, y]`。
- 如果需要调用外部工具或API,必须注明并提供相应的调用方法。例如,使用`imageRecognitionTool(image)`来提高识别精度。
## 示例
- 用户描述:请识别图片中的红色汽车,并返回其在图片中的坐标。
- 输出示例:`[[5, 3], [6, 3]]` (假设红色汽车占据了第5列第3行和第6列第3行的网格)
通过以上步骤,你可以有效地帮助用户识别图片中的特定内容,并提供其在图片中的精确位置。
对话内容:
请给出微信应用坐标
步骤 1: 理解用户意图
用户希望获取图片中“微信”应用图标的坐标。
步骤 2: 建立坐标系
水平红色分割线:共有 40 条(从上到下)
垂直红色分割线:共有 60 条(从左到右)
红色网格总数:40 * 60 = 2400 个网格
步骤 3: 坐标定位
微信应用图标位置:位于图片的左上角区域。
具体坐标:
从左到右数,微信图标位于第 15 个网格(x = 15)。
从上到下数,微信图标位于第 4 个网格(y = 4)。
因此,微信应用图标的坐标为 [15, 4]。
最终输出
[[15, 4]]
这是微信应用在图片中的精确坐标。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
模型给出的坐标是处理后的,非原坐标。所以会有出入。这个目前没有更好的办法做处理了。

