flink cdc3.0写入Doris mysql binlog如何保证有序,有按binlog file和pos 排序吗 ?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
没有按binlog file和pos 排序, 确保数据有序性主要依赖于Flink的Exactly-Once语义。
使用 Flink 的水位线(Watermarks):
Flink 的水位线机制可以用来处理事件时间,并保证数据的全局有序性。水位线代表直到某个特定时间的所有数据都已经被处理,这可以帮助 Flink 处理迟到的数据并保证数据的顺序。
确保 Binlog 的有序读取:
Flink CDC 在读取 MySQL Binlog 时,默认情况下会按照 Binlog 的写入顺序来读取数据。因此,只要 Binlog 写入是有序的,Flink CDC 就能保证读取的数据也是有序的。
使用唯一的排序字段:
在写入 Doris 时,确保每条记录都有一个可以用于排序的唯一字段(如时间戳或自增ID)。这样,即使数据在多个分区中,也可以在最终的查询或处理中保证顺序。
在 Flink 作业中配置 MySQL 作为源和 Doris 作为目标。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SourceFunction<RowData> mySqlSource = MySqlSource.<RowData>builder()
.hostname("yourHostname")
.port(3306)
.databaseList("yourDatabase")
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonRowDataDeserializer(new String[]{"f0", "f1"}, new TypeInformation[]{Types.STRING(), Types.STRING()}))
.build();
DataStream<RowData> cdcStream = env.addSource(mySqlSource);
// 写入 Doris
DorisSinkBuilder<RowData> dorisSinkBuilder = new DorisSinkBuilder<RowData>()
.withProperty("fenodes", "yourDorisFeNodes")
.withProperty("username", "yourDorisUsername")
.withProperty("password", "yourDorisPassword")
.withProperty("database", "yourDorisDatabase")
.withProperty("table", "yourDorisTable")
.withProperty("column", "yourDorisColumn");
cdcStream.addSink(dorisSinkBuilder.build()).setParallelism(1);
env.execute("Flink CDC to Doris");
为了保证Flink CDC 3.0在写入Doris时数据的有序性,特别是处理MySQL Binlog数据,可以遵循以下策略和配置:
相关链接
https://help.aliyun.com/zh/flink/developer-reference/mysql-connector/
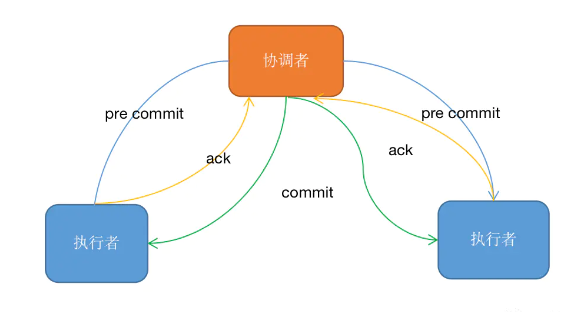
如果在这个过程中发生错误,可以回滚到第一阶段之前的状态,从而保证数据的一致性。
Exactly Once语义:
这是指在数据传输和处理的过程中,每条记录只被处理一次。
Flink CDC结合Doris的Flink Connector可以实现从MySQL数据库中监听数据并实时入库到Doris数仓对应的表中。
Flink CDC会捕获MySQL的变更数据(如INSERT、UPDATE、DELETE等操作),然后通过Flink的流处理能力,将这些变更实时地传输到Doris。
Exactly Once语义的实现依赖于一系列复杂的机制,包括事务管理、状态管理和检查点机制。
事件时间戳:
在处理流数据时,可以使用记录的事件时间戳来保证数据的顺序。
即使在乱序到达的情况下,也可以根据时间戳来对数据进行排序,从而保证最终的结果是正确的。
Watermark:
Watermark是一种延迟机制,它允许系统在一定时间内等待迟到的数据,然后再进行处理。
这有助于确保在乱序数据流中,所有的数据都能按照事件时间戳的顺序被正确处理。
binlog的顺序读取:
Flink CDC在读取MySQL的binlog时,会按照binlog的文件和位置(file和pos)进行顺序读取。
这确保了从MySQL捕获的数据是按照其产生的顺序被读取的。
Flink的并行度设置:
在增量数据同步阶段,可以将Flink的并行度设置为1,以确保数据按照顺序被处理。
需要注意的是,这可能会降低数据处理的吞吐量,但在需要保证数据顺序性的场景下是必要的。
Flink CDC 3.0 写入 Doris 时,为了保证有序性,可以采用以下方法:
使用 Flink 的 watermark 机制:在 Flink 中,可以使用 watermark 来处理乱序数据。Watermark 是一种逻辑时钟,用于表示事件时间的顺序。通过设置合适的 watermark,Flink 可以识别出乱序的数据,并按照正确的顺序进行处理。
使用 Flink 的窗口操作:Flink 提供了多种窗口操作,如滑动窗口、滚动窗口等。通过使用窗口操作,可以将数据按照一定的时间范围进行分组,然后在每个窗口内对数据进行排序和聚合。这样可以确保数据的有序性。
使用 Flink 的 keyBy 操作:在进行数据写入 Doris 之前,可以先对数据进行 keyBy 操作,将具有相同 key 的数据分到同一个分区。这样,在 Doris 中,具有相同 key 的数据会被存储在一起,从而保证有序性。
在 Doris 中使用分区表:Doris 支持分区表,可以将数据按照某个字段进行分区。在创建 Doris 表时,可以指定分区键,并将 Flink 写入的数据按照分区键进行分区。这样可以确保相同分区内的数据有序。
在 Doris 中使用主键约束:在 Doris 表中,可以为某些字段设置主键约束。当插入数据时,如果违反了主键约束,Doris 会拒绝插入数据。这样可以确保数据的有序性。
综上所述,可以通过以上方法来保证 Flink CDC 3.0 写入 Doris 时的有序性。具体实现时,可以根据实际需求选择合适的方法。
这个问题可能是由于Flink CDC连接器与Oracle数据库之间的兼容性问题导致的。为了解决这个问题,你可以尝试以下方法:
确保你的Flink和Flink CDC的版本与Oracle数据库的版本兼容。你可以查阅官方文档或者社区讨论来获取更多关于版本兼容性的信息。
检查你的Oracle数据库驱动程序是否正确安装并配置。确保你已经下载了正确版本的Oracle JDBC驱动,并将其添加到Flink的类路径中。
检查你的Flink配置文件(flink-conf.yaml)中的相关设置,如连接字符串、用户名和密码等,确保它们是正确的。
如果问题仍然存在,你可以尝试升级或降级Flink和Flink CDC的版本,以找到一个与你的Oracle数据库兼容的版本。
如果以上方法都无法解决问题,你可以在Flink社区论坛或者GitHub仓库中提交一个issue,详细描述你遇到的问题,以便开发者和其他用户能够提供帮助。
在使用 Apache Flink CDC 3.0 将 MySQL 的 Binlog 数据同步到 Doris 时,保证数据的有序性是一个关键的需求,特别是在处理事务性和依赖于顺序的数据操作时。以下是一些方法和技术,可以帮助确保数据同步过程中保持有序:

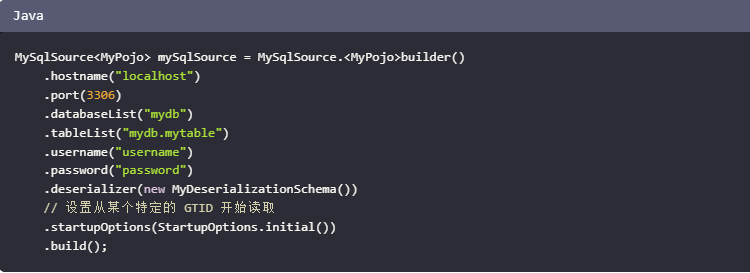
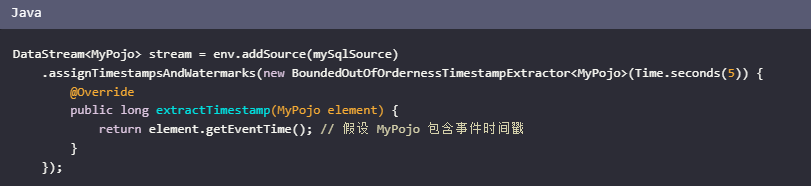
Flink CDC 3.0 支持多种数据库源,包括 MySQL,并且可以通过 Debezium 连接器来读取 MySQL 的 binlog。
对于使用 Flink CDC 将 MySQL 的 binlog 数据写入 Doris 的场景,确保记录按照 binlog 文件和位置(file/pos)有序是非常重要的,尤其是当需要保持事务的一致性时。
在 MySQL 的 binlog 中,每个变更记录都有一个唯一的标识符,即文件名和位置(log_file_name/log_pos)。这些信息可以帮助确定事件发生的顺序。Flink CDC 通常会利用这些信息来确保读取的事件是有序的。但是在分布式流处理框架中,如 Apache Flink,要完全保证全局有序性是比较困难的,因为这需要所有任务都串行执行。Flink CDC 可以通过配置来尽量接近这个目标,比如使用 Keyed Stream 或者通过特定的排序策略来实现。
在使用 Apache Flink CDC 3.0 将 MySQL 的 binlog 数据写入 Doris 时,保证数据的有序性是非常重要的,尤其是在处理事务和依赖于顺序的操作时。Flink CDC 本身提供了机制来确保数据的有序性,特别是在处理 MySQL binlog 时。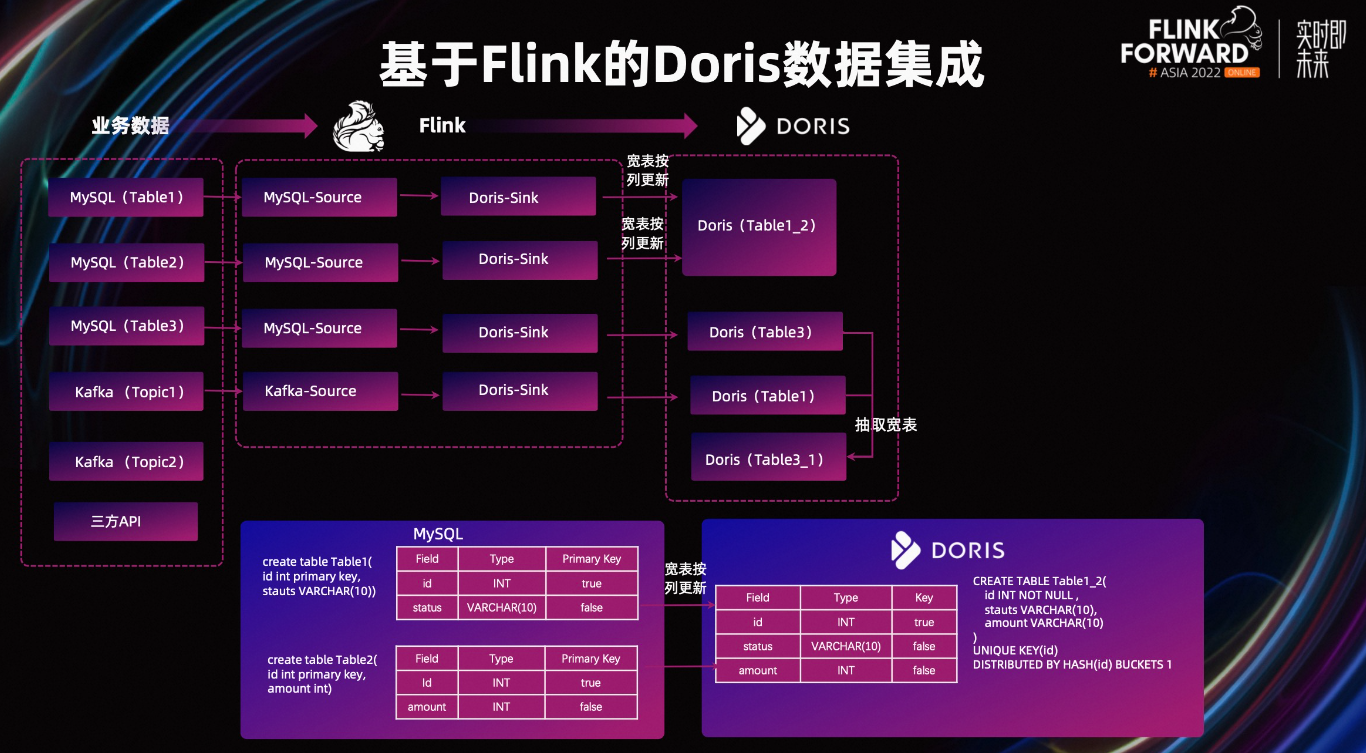
MySQL 的 binlog 文件是按时间顺序记录的,并且每个 binlog 事件都有一个唯一的 position。Flink CDC 在读取 binlog 时会按照 binlog 文件和 position 的顺序进行读取,从而保证了数据的有序性。
Flink CDC 使用 Debezium 作为底层的 binlog 读取器。Debezium 会按照 binlog 文件和 position 的顺序读取事件,并将这些事件发送到 Flink 的 Source 端。
为了进一步保证数据的有序性,Flink 提供了 watermark 和 event time 的概念。你可以通过配置 Flink CDC 的 Source 来生成 watermarks,并基于 event time 进行窗口操作或状态管理。
// 创建 Flink CDC Source
MySqlSourceBuilder<String> builder = MySqlSource.<String>builder()
.hostname("your_mysql_host")
.port(your_mysql_port)
.databaseList("your_database")
.tableList("your_table")
.username("your_username")
.password("your_password")
.deserializer(new JsonDebeziumDeserializationSchema()) // 使用 JSON 格式反序列化
.includeSchemaChanges(true) // 是否包含 schema 变更事件
.startupOptions(StartupOptions.initial()) // 从最新的 binlog 位置开始读取
.setParallelism(1); // 设置并行度为 1,以保证单线程顺序处理
DataStreamSource<String> source = env.fromSource(builder.build(), WatermarkStrategy.noWatermarks(), "MySQL CDC Source");
在 Sink 端,你需要确保数据写入 Doris 时也保持有序。Doris 支持多种写入方式,包括通过 MySQL 协议、HTTP API 或者 Broker Load 等。为了保证有序性,你可以采取以下几种方法:
设置 Flink Sink 的并行度为 1,以确保单线程顺序写入。
sink.setParallelism(1);
如果你需要按某个字段进行分组,可以使用 keyBy 操作来保证每个分组内的数据有序。
source.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
// 根据你的逻辑提取 key
return extractKey(value);
}
})
.addSink(sink);
如果默认的 Sink 不能满足需求,你可以实现一个自定义的 Sink,确保在写入 Doris 时保持有序。
确保 Doris 的配置支持顺序写入。例如,如果你使用的是 MySQL 协议写入 Doris,确保 Doris 的表结构和索引设计能够支持高效的数据写入。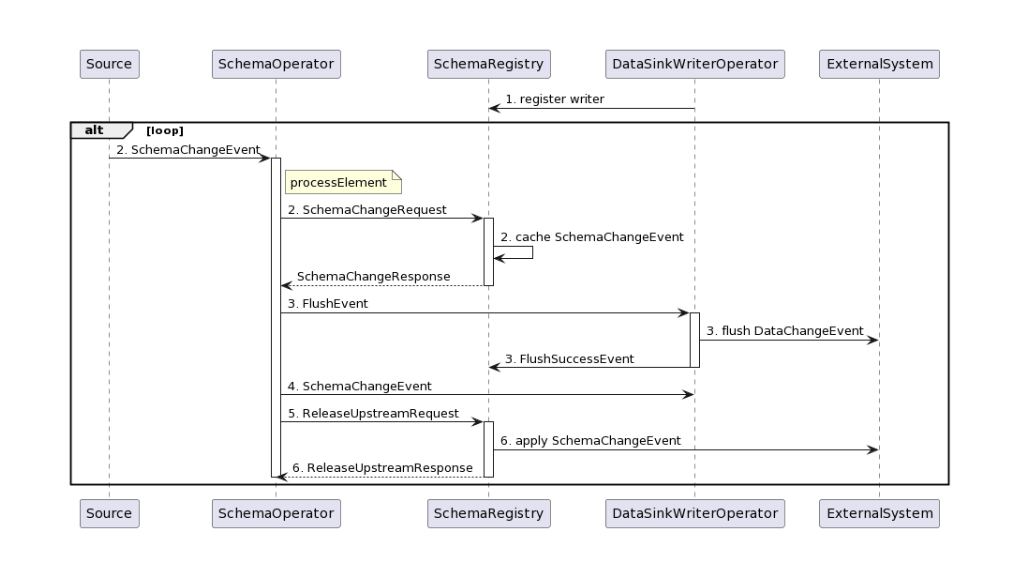
以下是一个完整的示例,展示了如何使用 Flink CDC 3.0 读取 MySQL binlog 并写入 Doris,同时保证数据的有序性。
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
public class MysqlToDorisCDC {
public static void main(String[] args) throws Exception {
// 创建 Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建 Flink CDC Source
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("your_mysql_host")
.port(your_mysql_port)
.databaseList("your_database")
.tableList("your_table")
.username("your_username")
.password("your_password")
.deserializer(new JsonDebeziumDeserializationSchema()) // 使用 JSON 格式反序列化
.includeSchemaChanges(true) // 是否包含 schema 变更事件
.startupOptions(StartupOptions.initial()) // 从最新的 binlog 位置开始读取
.build();
// 从 Source 读取数据
DataStreamSource<String> source = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL CDC Source");
// 设置 Sink 的并行度为 1,以保证单线程顺序写入
MyDorisSink dorisSink = new MyDorisSink();
source.setParallelism(1).addSink(dorisSink);
// 启动 Flink 任务
env.execute("MySQL to Doris CDC Job");
}
// 自定义 Doris Sink
public static class MyDorisSink extends RichSinkFunction<String> {
@Override
public void invoke(String value, Context context) throws Exception {
// 实现写入 Doris 的逻辑
// 例如:通过 JDBC 或 HTTP API 写入 Doris
}
}
}
通过上述配置和步骤,你可以确保 Flink CDC 3.0 在读取 MySQL binlog 并写入 Doris 时保持数据的有序性。如果还有其他具体需求或问题,请提供更多详细信息以便进一步诊断。
Flink CDC里mysql通过cdc到doris,mysql的opts只到秒,那写入顺序咋保证?
Flink CDC里mysql通过cdc到doris,mysql的opts只到秒,那写入顺序咋保证?如果1年内更新了两次,可能顺序就不对,比如cp设置1秒,那1秒内累计的数据一个批次到doris,doris不按照顺序写吧?
参考答案:
增量阶段并行度只有1就是为了保证顺序,且全局为1。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/599258?spm=a2c6h.12873639.article-detail.44.50e24378TRW91E
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。