
Flink Job任务设置table.exec.state.ttl = '24h'后,从最新一个ck恢复任务后观察到 还是全量读取数据,请问是正常的吗?指定ck恢复任务感觉没生效呢?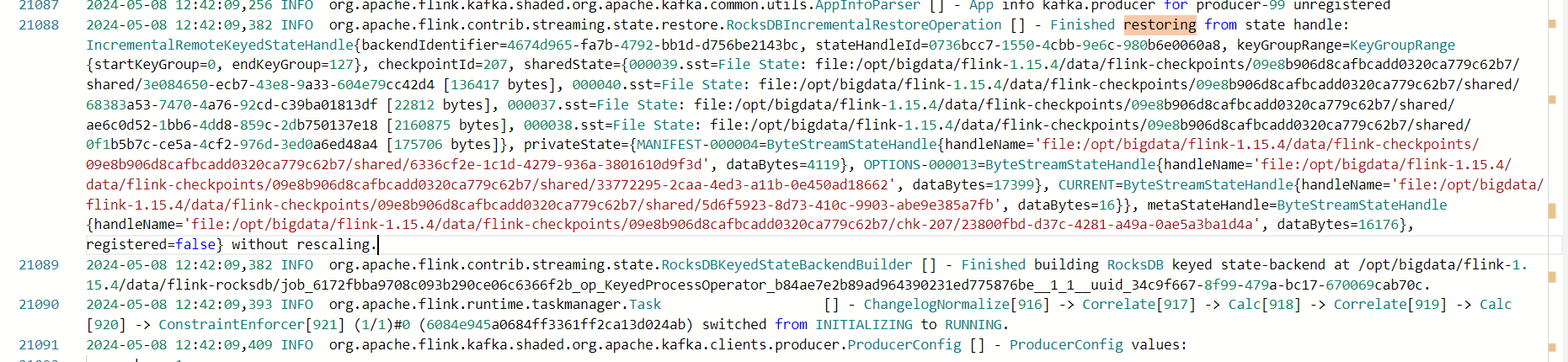
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
设置 table.exec.state.ttl = '24h' 是合理的,意味着您配置了Flink SQL作业的状态(State)存活时间为24小时。这表示作业中维护的状态数据将在24小时后过期并被清除<。此配置有助于控制内存或存储资源的使用,防止无限制地积累状态数据。不过,需要注意的是,一旦状态过期,与之相关的计算可能不再准确,特别是对于窗口聚合或者需要状态持续更新的场景。
请依据您的业务需求来设定这个值,如果业务逻辑中状态数据不需要长期保持,那么24小时是一个可行的设置。但如果依赖长期状态进行计算,则可能需要调整该值或重新考虑您的状态管理策略,以确保数据处理的正确性和连续性。同时,确保所使用的Flink版本支持该配置项,并且理解它对作业行为的影响,特别是在使用minibatch模式时
在 Apache Flink 中,table.exec.state.ttl 是用于控制操作符状态中元素的生存时间的配置项。当达到 TTL 后,这些元素将被自动清理。然而,这个配置并不会影响检查点(checkpoint)或保存点(savepoint)的行为。
当你从最新的检查点恢复 Flink 作业时,它会加载上一次检查点中的所有状态,包括已过期但尚未被清理的状态。这是因为检查点是一个快照,包含了作业运行时的所有状态信息。table.exec.state.ttl 只是在作业运行过程中动态地管理状态,而不是在恢复时立即清除过期状态。因此在你描述的情况下,从检查点恢复任务并重新开始处理数据时,可能会看到全量的数据再次被处理。这是正常的现象,并不意味着 table.exec.state.ttl 配置没有生效。只有在作业继续运行一段时间之后,那些超过 TTL 的状态才会逐渐被清理掉。
如果你希望避免重复处理数据,可以考虑使用幂等性状态(如 RocksDBStateBackend 中的 KeyedState),或者设计你的应用逻辑来容忍这种重复处理。另外也可以通过调整 table.exec.state.ttl 值以适应你的业务需求,使其更接近实际需要的时间范围。
设置了参数 table.exec.state.ttl = '24h',这意呀着作业状态的过期时间为24小时,该设置并不会直接影响从检查点(checkpoint)恢复任务时的数据读取行为。
当Flink作业从最新的检查点恢复时,它会利用检查点中保存的进度信息来继续执行,而不是根据 table.exec.state.ttl 的设置来决定数据读取的起点。这意味着,如果检查点包含了全量的数据状态,那么恢复时自然会从检查点记录的位置开始处理,可能会出现看似“全量读取数据”的情况,但这实际上是恢复流程的一部分,以保证作业的精确一次(exactly-once)语义。
正常的。table.exec.state.ttl和CheckPoint没有什么必然联系。
CheckPoint可以理解为: 将State状态数据持久化,注意这个CheckPoint是在同一时间点 Task/Operator的状态的全局快照。
CheckPoint是Flink在输入的数据集上间隔性的生成checkpoint barrier,并通过barrier将时间间隔段内的数据划分到相应的CheckPoint中。一旦Flink程序意外崩溃时,重新运行程序时可以有选择的从这些快照中恢复所有算子之前的状态,从而保证数据一致性。
table.exec.state.ttl:指定空闲状态的最短时间,(注意是未更新的状态的空闲时间,如果状态更新了,则更新状态时间)默认是0,不会清除状态,注意:这个可能会导致内存溢出等问题。
——参考链接。
在 Flink 中,table.exec.state.ttl 配置项是用于设置 Flink SQL 作业中状态(state)的存活时间(Time-To-Live, TTL)的。这个配置项可以帮助管理作业的状态大小,通过自动清理长时间未使用的状态来避免状态过大导致的问题。
当你设置 table.exec.state.ttl = '24h' 时,你实际上是在告诉 Flink,对于所有的状态(除非有特别指定其他TTL值的状态),它们在被创建或最后一次更新后的24小时内如果没有被再次访问或更新,那么这些状态应该被自动清理掉。
这个设置本身在大多数场景下是合理的,特别是对于那些希望限制状态大小,或者对于过期数据不感兴趣的场景。然而,是否“正常”还取决于你的具体应用场景和需求:
应用场景:如果你的作业处理的是实时数据流,并且数据的时效性很重要(比如,只关心最近24小时内的数据),那么这个设置就是合适的。但如果你需要保留更长时间的数据以支持复杂查询或回溯分析,那么这个设置可能就不合适了。
性能考虑:虽然TTL可以帮助管理状态大小,但频繁的状态清理可能会对性能产生一定影响。如果状态清理成为性能瓶颈,你可能需要考虑优化TTL设置或调整其他配置。
版本兼容性:确保你的 Flink 版本支持 table.exec.state.ttl 配置项。虽然这是一个常用的配置项,但不同版本的 Flink 在具体实现上可能有所不同。
特定状态的TTL:Flink 还允许你为特定的表或状态设置不同的 TTL 值。如果你的作业中有多种类型的数据,且它们的时效性需求不同,那么可以考虑为它们分别设置不同的 TTL 值。
总之,table.exec.state.ttl = '24h' 是否正常取决于你的具体需求和应用场景。在做出决策之前,请仔细考虑上述因素。
Flink 中,table.exec.state.ttl 是用于控制操作符状态中元素的生存时间的配置项。当达到 TTL 后,这些元素将被自动清理。然而这个配置并不会影响检查点或保存点的行为。当你从最新的检查点恢复 Flink 作业时,它会加载上一次检查点中的所有状态,包括已过期但尚未被清理的状态。这是因为检查点是一个快照,包含了作业运行时的所有状态信息。table.exec.state.ttl 只是在作业运行过程中动态地管理状态,而不是在恢复时立即清除过期状态。因此在你描述的情况下,从检查点恢复任务并重新开始处理数据时,可能会看到全量的数据再次被处理。这是正常的现象,并不意味着 table.exec.state.ttl 配置没有生效。只有在作业继续运行一段时间之后,那些超过 TTL 的状态才会逐渐被清理掉。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


