MaxCompute可以全局设置表全表扫描fullscan吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在MaxCompute中,通常可以通过一些配置或参数设置来控制是否进行全表扫描(fullscan),但不是严格意义上的全局统一设置,以下是相关介绍:
通过MaxCompute SQL配置
在执行MaxCompute SQL时,可以通过设置相关参数来影响是否进行全表扫描。例如,在某些情况下,如果查询语句没有合适的索引或者过滤条件无法有效利用索引,系统可能会默认进行全表扫描。用户可以通过设置 odps.sql.allow.fullscan 参数来控制是否允许全表扫描,当该参数设置为 true 时允许全表扫描,设置为 false 时,如果查询可能导致全表扫描则会报错。不过这是针对具体的SQL作业或会话级别进行设置,不是全局一次性设置后所有操作都生效。
通过数据处理框架配置
在使用MaxCompute与其他数据处理框架(如MR、Spark等)结合时,在框架的相关配置中也可能会有与全表扫描相关的参数设置。例如在Spark on MaxCompute中,可以在Spark的配置参数中设置是否允许全表扫描以及相关的优化策略等,但这也是在具体的作业或应用程序级别进行配置,并非全局统一设置。
虽然MaxCompute没有一个绝对的全局设置来统一控制所有表的全表扫描行为,但可以在不同的作业、会话或应用程序级别根据具体需求灵活配置是否允许全表扫描,以达到优化查询性能和资源利用的目的。
如果当前SQL需要进行全表扫描,可以在SQL语句前加set odps.sql.allow.fullscan=true;
语句并一起提交运行所以不可以全局设置表全表扫描。全表扫描会导致输入量增加从而使成本增加。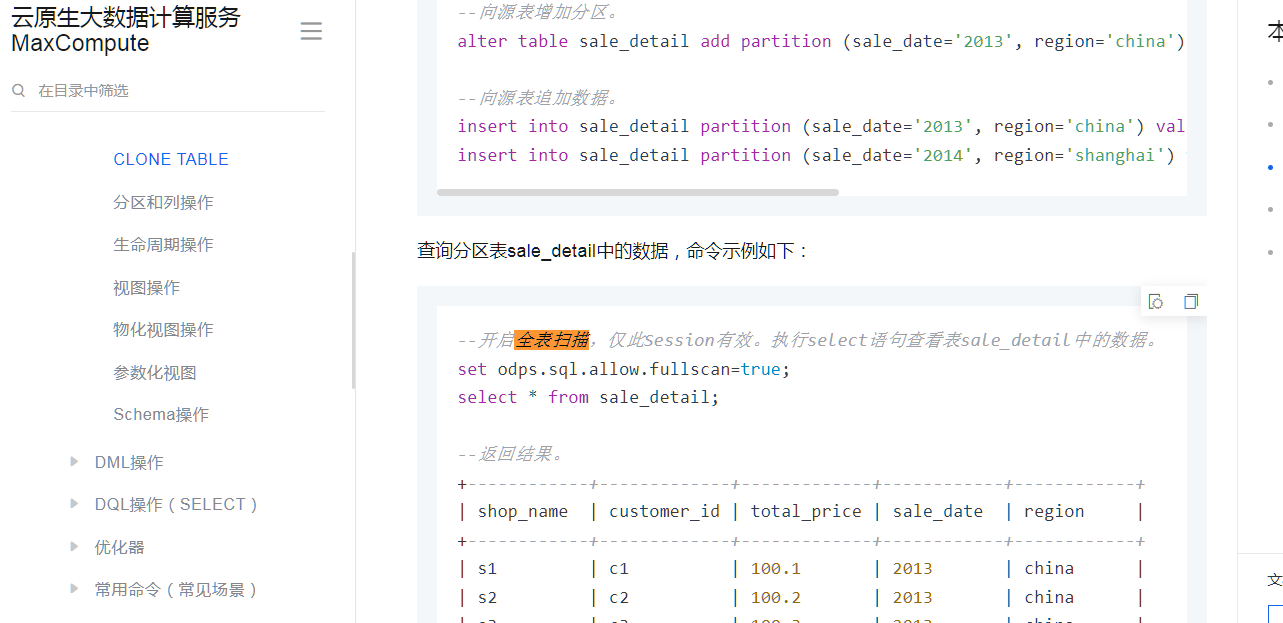
参考链接
https://help.aliyun.com/zh/maxcompute/user-guide/clone-table
回答不易请采纳
可以通过两种方式实现:
Project级别设置:
需要项目空间Owner或者具有Super_Administrator权限的子账号执行。可以通过odpscmd登录相应账号,在命令行中输入 setproject odps.sql.allow.fullscan=true; 或者在管控台的“项目管理”->“参数配置”中,修改『允许分区表全表扫描』的设置为开启状态。
注意:此操作将影响项目内所有查询,可能导致未加分区过滤的查询执行全表扫描,增加计费。
Session级别设置:
对于一次性或特定Session需要全表扫描的情况,可以在执行SQL前设置 set odps.sql.allow.fullscan=true;,此设置仅对当前Session有效。
这意味着在发出实际的查询语句之前,你需要先执行这条命令,然后在同一Session中执行全表扫描的查询。
MaxCompute(原名ODPS)是阿里巴巴集团开发的一种大数据计算服务,它提供了一种分布式的大规模数据处理能力。在MaxCompute中,可以通过设置表的属性来控制查询时的扫描方式。
对于全表扫描(fullscan),MaxCompute并没有提供全局设置的方法。全表扫描通常是由于查询语句或优化器选择的结果,而不是通过全局设置来实现的。然而,你可以通过一些方法来减少全表扫描的发生:
优化查询语句:确保你的查询语句尽可能高效,避免不必要的全表扫描。例如,使用索引、分区和过滤条件等技术来限制扫描的数据量。
调整表属性:你可以为表设置合适的属性,如分区键、排序键等,以帮助优化器更好地选择执行计划。这些属性可以帮助MaxCompute更有效地处理数据,从而减少全表扫描的发生。
使用物化视图:如果你经常需要对某个表进行复杂的查询操作,可以考虑创建物化视图。物化视图是一种预先计算并存储结果集的方式,它可以提高查询性能并减少全表扫描的发生。
需要注意的是,尽管可以通过上述方法来减少全表扫描的发生,但在某些情况下,全表扫描可能是必要的,特别是在处理大量数据或复杂查询时。因此,在进行查询优化时,需要权衡各种因素,包括查询性能、资源消耗和业务需求。
在MaxCompute中,全表扫描(full scan)指的是读取表中的所有数据,这通常发生在没有使用分区或索引优化查询的情况下。MaxCompute设计为适合批量处理大规模数据集,因此对于大数据量的表,避免不必要的全表扫描对于提高查询效率和降低成本是非常重要的。
MaxCompute并没有一个特定的全局设置来控制是否允许全表扫描。相反,优化查询性能和避免全表扫描更多的是通过以下几个方面来实现:
分区表:合理地设计表的分区可以极大地减少查询需要扫描的数据量。例如,如果数据按日期分区,那么只需要查询特定日期范围内的数据,就可以避免扫描整个表。
索引:虽然MaxCompute不像某些关系型数据库那样支持传统意义上的索引,但它支持一些优化技术,如Join优化等,可以帮助减少数据扫描量。
选择性:确保WHERE子句中有足够的筛选条件来缩小数据范围,这有助于减少扫描的数据量。
使用MapReduce/Graph/UDF等:对于某些复杂的数据处理场景,可以使用MaxCompute提供的MapReduce、Graph等功能来更有效地处理数据。
成本意识:了解MaxCompute的计费模型,并确保你的查询和数据设计是成本效益最大化的。
为了防止不必要的全表扫描,你需要在设计和执行查询时考虑到上述因素。如果你希望对用户的查询行为进行限制或监控,可能需要通过项目管理策略或其他管理手段来实施,比如通过培训用户正确编写查询语句,或者开发一些内部工具来审查和优化SQL语句。
当使用SELECT语句时,屏显最多只能显示10000行结果,同时返回结果要小于10 MB。当SELECT语句作为子句时则无此限制,SELECT子句会将全部结果返回给上层查询。
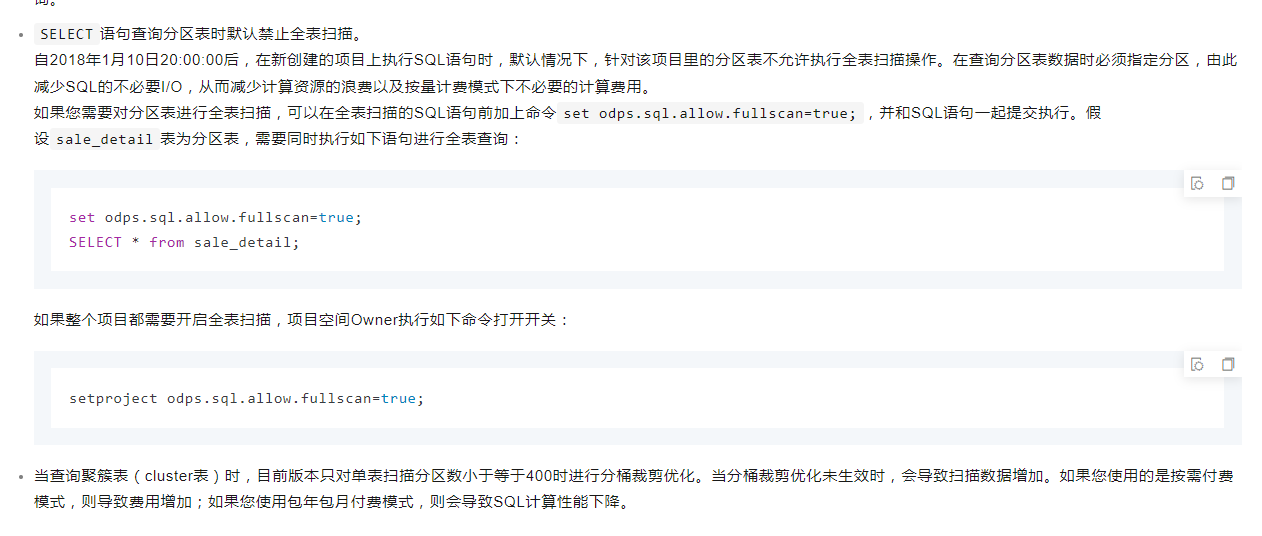
SELECT语句查询分区表时默认禁止全表扫描。
自2018年1月10日20:00:00后,在新创建的项目上执行SQL语句时,默认情况下,针对该项目里的分区表不允许执行全表扫描操作。在查询分区表数据时必须指定分区,由此减少SQL的不必要I/O,从而减少计算资源的浪费以及按量计费模式下不必要的计算费用。
如果您需要对分区表进行全表扫描,可以在全表扫描的SQL语句前加上命令set odps.sql.allow.fullscan=true;,并和SQL语句一起提交执行。假设sale_detail表为分区表,需要同时执行如下语句进行全表查询:
set odps.sql.allow.fullscan=true;
SELECT * from sale_detail;
如果整个项目都需要开启全表扫描,项目空间Owner执行如下命令打开开关:
setproject odps.sql.allow.fullscan=true;
当查询聚簇表(cluster表)时,目前版本只对单表扫描分区数小于等于400时进行分桶裁剪优化。当分桶裁剪优化未生效时,会导致扫描数据增加。如果您使用的是按需付费模式,则导致费用增加;如果您使用包年包月付费模式,则会导致SQL计算性能下降。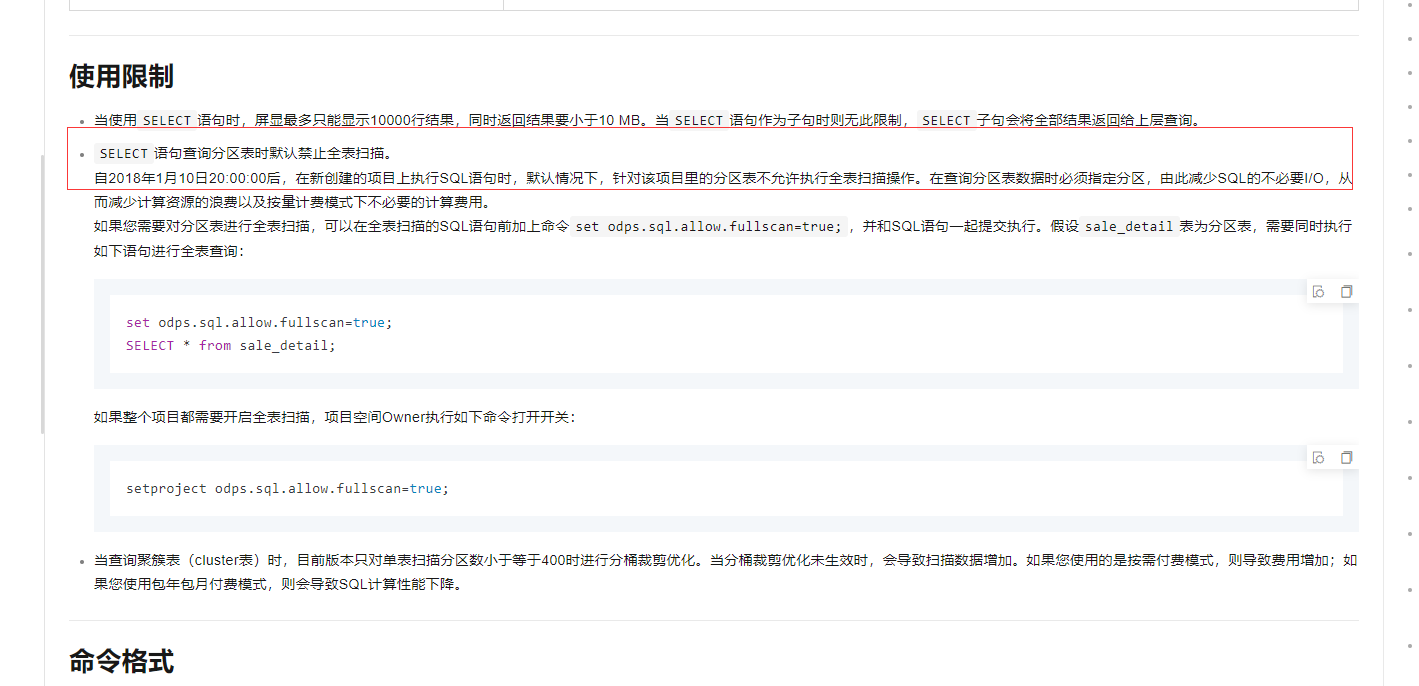
参考文档https://help.aliyun.com/zh/maxcompute/user-guide/select-syntax
在阿里云的大数据计算服务 MaxCompute 中,全局设置表的全表扫描(fullscan)并不是一个直接的配置选项。MaxCompute 的查询优化器会根据查询的复杂性和数据分布自动决定是否进行全表扫描。然而,你可以通过一些方法和技巧来影响或控制查询的行为。
MaxCompute 支持 SQL Hints 来指导查询优化器的行为。你可以使用 /*+ hint */ 语法来指定某些优化策略。虽然 MaxCompute 没有直接提供 FULL SCAN 的 Hint,但你可以通过其他方式间接影响查询行为。
/*+ MAPJOIN */ 提示如果你希望强制进行全表扫描而不是使用索引或其他优化,可以尝试使用 MAPJOIN 提示来确保小表被加载到内存中,从而避免索引的使用。
SELECT /*+ MAPJOIN(small_table) */ *
FROM large_table
JOIN small_table
ON large_table.id = small_table.id;
如果你不希望查询优化器使用分区修剪(partition pruning),可以通过编写查询时忽略分区信息来实现全表扫描。
假设你有一个按日期分区的表 sales,并且你想进行全表扫描:
-- 不使用分区信息
SELECT * FROM sales;
-- 或者显式列出所有分区
SELECT * FROM sales
WHERE dt IN ('2023-01-01', '2023-01-02', '2023-01-03', ...);
如果你希望总是进行全表扫描,可以考虑将数据存储在一个非分区表中。这样,查询优化器就没有分区信息可以利用,只能进行全表扫描。
CREATE TABLE sales_non_partitioned AS
SELECT * FROM sales;
TUNNEL 命令如果你只是想导出整个表的数据,可以使用 TUNNEL 命令来下载数据。这本质上是一个全表扫描操作。
TUNNEL 导出数据tunnel download sales <local_path>
有时候,通过修改 SQL 语句本身可以间接地迫使查询优化器进行全表扫描。例如,使用 UNION ALL 或其他复杂的子查询结构。
UNION ALLSELECT * FROM sales
UNION ALL
SELECT * FROM sales
WHERE 1=0; -- 这个条件永远为假,只是为了触发全表扫描
虽然 MaxCompute 没有直接的全局设置来强制全表扫描,但你可以通过上述方法间接影响查询优化器的行为。在实际应用中,建议先评估全表扫描的必要性,并考虑其对性能和成本的影响。如果确实需要全表扫描,可以结合具体情况选择合适的方法。
开启全表扫描可以通过如下两种方式实现:
Project级别:设置setproject odps.sql.allow.fullscan=true ;
Session级别:设置set odps.sql.allow.fullscan=true;,需要与SQL语句一起提交。
注意:
1、 Project级别打开全表扫描需要通过odpscmd登录主账号或拥有 Super_Administrator权限的子账号执行对应命令,或者在管控台-项目管理-参数配置,更改『允许分区表全表扫描』的设置。
2、 Project级别打开全表扫描后,会导致没有加分区过滤的任务扫描全表,计费会有所增加。
其它参数配置,可以参考set参数。https://help.aliyun.com/zh/maxcompute/user-guide/set-operations?spm=a2c6h.13066369.question.5.23cb38d1MO2vIK
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。