
如何使用dataworks完成自定义SQL在mc中提取数据写入到holo内?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要在DataWorks中使用自定义SQL从MaxCompute(MC)提取数据并写入Hologres(holo),请遵循以下步骤:
准备数据源
创建Hologres数据源
设计自定义SQL
创建数据同步任务
配置自定义SQL提取
holo_extracted_data,Schema为your_schema_name。网络与资源配置
高级设置与验证
启动同步任务
相关链接
Github实时数据同步与分析 实时同步数据至Hologres https://help.aliyun.com/zh/dataworks/use-cases/real-time-synchronization-and-analysis-of-github-data
创建Hologres写入节点:在同一数据开发流程中,添加另一个节点用于将数据写入Hologres。
配置节点:设置每个节点的输入和输出参数,确保它们正确地连接源和目标表。
运行和调度:运行数据流程以执行SQL查询并写入数据,如果需要定期执行,可以设置周期性调度。
-- MaxCompute中提取数据的SQL查询
SELECT *
FROM mc_project.mc_dataset.mc_table
WHERE conditions;
-- 将上述查询结果写入Hologres的SQL语句
CREATE TABLE IF NOT EXISTS holo_dataset.holo_table (
column1 datatype1,
column2 datatype2,
...
);
INSERT INTO holo_dataset.holo_table
SELECT *
FROM (YOUR_MC_QUERY) t
WHERE t.pt = '${bizdate}';
在DataWorks中,你可以使用自定义SQL节点来执行SQL查询,并将结果写入到MaxCompute(mc)表中。以下是步骤:
登录DataWorks控制台。
选择你的项目,然后点击“开发”选项卡。
在开发页面,点击“新建任务”,然后选择“数据集成”。
在数据集成编辑器中,从左侧的组件面板拖拽一个“自定义SQL”节点到画布上。
双击“自定义SQL”节点以打开配置窗口。在这里,你可以输入你的SQL查询语句。例如,如果你想从一个名为source_table的表中提取数据,你可以输入如下的SQL语句:
sql
复制代码运行
SELECT * FROM source_table;
点击“确定”保存你的SQL查询。
接下来,你需要添加一个“写入”节点来将查询结果写入到MaxCompute表中。再次从左侧的组件面板中拖拽一个“写入”节点到画布上,并将其连接到“自定义SQL”节点。
双击“写入”节点以打开配置窗口。在这里,你需要指定目标表的信息,包括项目名、工作空间名、表名以及写入模式等。例如,如果你要将数据写入到名为target_table的表中,你可以输入如下的配置信息:
项目名:your_project_name
工作空间名:your_workspace_name
表名:target_table
写入模式:插入/更新
点击“确定”保存你的写入配置。
最后,点击工具栏上的“发布”按钮以提交并运行你的任务。任务完成后,你可以在MaxCompute中查看target_table的内容,确认数据已经成功写入。
使用DataWorks完成自定义SQL从MC提取数据并写入Hologres,您可以遵循以下步骤:
创建DataWorks数据开发任务:在DataWorks中创建一个SQL任务,设置数据源为MaxCompute。
编写SQL查询语句,从MaxCompute中提取所需数据。
配置数据目标:配置任务的输出数据源为Hologres。确保已配置Hologres的连接信息,并测试连通性。
自定义SQL:在SQL任务中编写自定义SQL查询,将MC中的数据提取出来。
设置数据写入:配置SQL任务的输出设置,包括目标表名、写入模式(如:追加、覆盖)等。
运行任务:保存并运行SQL任务,数据将从MaxCompute读取并写入到Hologres。
监控与调度:可以设置任务的调度策略,例如定时执行。
监控任务运行状态,确保数据正确导入。
要在DataWorks中使用自定义SQL从MaxCompute(MC)提取数据并写入到Holo中,您可以按照以下步骤操作:
登录到阿里云DataWorks控制台。
在左侧导航栏中,选择“开发”。
点击“新建项目”,输入项目名称和描述,然后点击“确定”。
在项目页面中,点击“新建资源”,选择“数据集成”,然后点击“新建任务”。
在新建任务页面中,填写任务名称、描述等信息,然后选择“自定义脚本”作为任务类型。
在任务配置页面中,选择“源”为“MaxCompute”,并填写相关配置信息,如项目名称、表名等。
选择“目标”为“Holo”,并填写相关配置信息,如数据库连接信息等。
在“自定义脚本”编辑框中,编写SQL语句来提取所需的数据。例如:
sql
复制代码运行
SELECT * FROM your_table_name;
点击“保存”按钮,完成任务创建。
返回项目页面,找到刚刚创建的任务,点击任务名称进入任务详情页面。
在任务详情页面中,点击“运行”按钮,启动任务执行。
等待任务执行完成,您可以在“同步历史”选项卡中查看任务执行情况和结果。
注意:请确保您已经正确配置了MaxCompute和Holo的连接信息,并且具有相应的权限。此外,根据您的需求,可能需要调整SQL语句以提取特定的数据。
要在DataWorks中使用自定义SQL从MaxCompute(MC)提取数据并写入Hologres(Holo),您可以使用DataWorks提供的数据集成(Data Integration)功能来实现这一目标。以下是详细的步骤和示例:
首先,您需要在MaxCompute中创建一个表,作为数据源。
接下来,您需要在Hologres中创建一个表,作为数据的目的地。
使用DataWorks的数据集成功能来创建一个任务,该任务将从MaxCompute读取数据并通过自定义SQL查询提取所需的数据,并将这些数据写入Hologres。
假设您已经在MaxCompute中创建了一个名为source_table的表,并且在Hologres中创建了一个名为destination_table的表。现在我们将创建一个数据集成任务来实现数据的迁移。
登录DataWorks控制台:
进入数据集成:
新建任务:
配置任务:
mc_to_holo_sql_task。配置源:
source_table。SELECT column1, column2, column3
FROM source_table
WHERE some_condition;
配置目标:
destination_table。设置任务调度:
保存并发布任务:
运行任务:
以下是使用DataWorks UI创建数据集成任务的大致步骤和截图示意。请注意,这里的步骤和截图是基于假设的情况,实际界面可能会有所不同。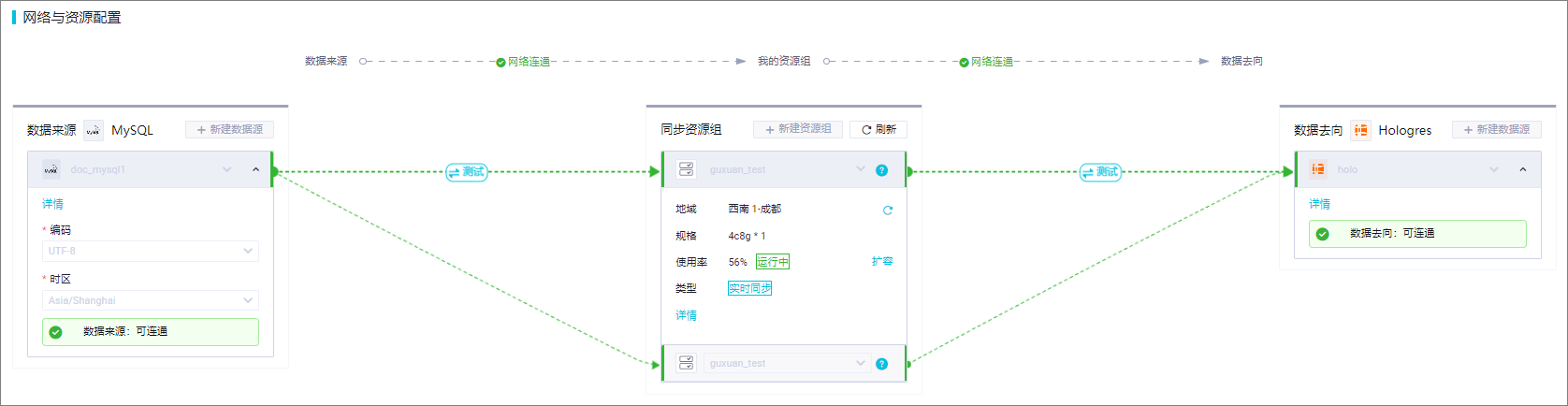
source_table。destination_table。希望这些信息对您有所帮助!如果您需要更详细的步骤或遇到具体问题,请随时告诉我。
要在DataWorks中使用自定义SQL从MaxCompute(原名ODPS,简称MC)中提取数据并写入Hologres,您可以遵循以下步骤进行操作:
准备数据源:
创建数据同步任务:
mc_to_holo_data_sync。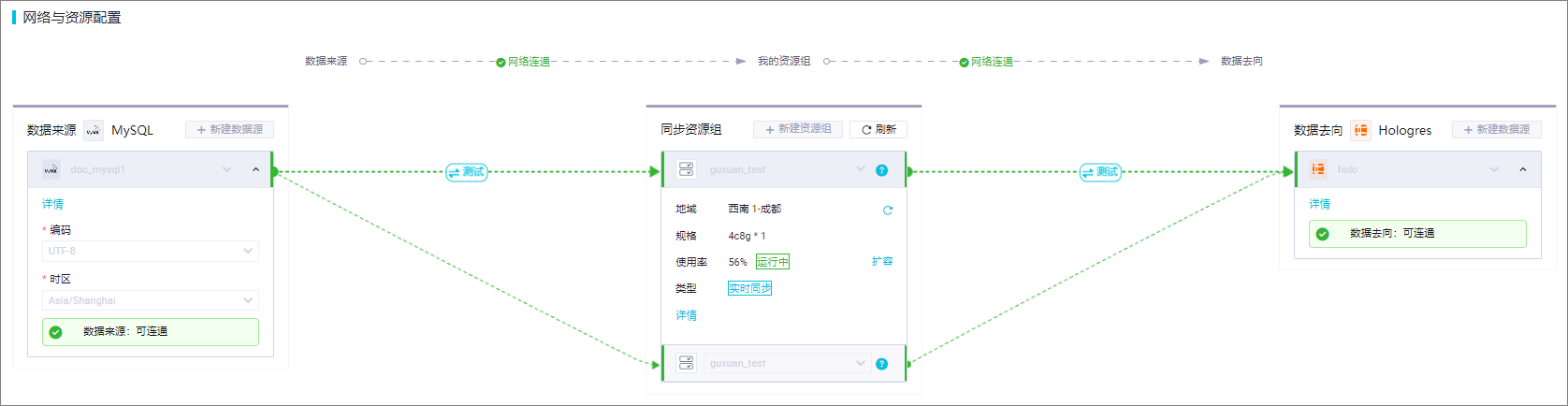
配置自定义SQL提取数据:
SELECT * FROM mc_database.mc_table WHERE condition,确保SQL符合MaxCompute的语法规范。目标表映射与自定义:
在目标表映射区域,如果Hologres中已有对应表,直接选择并配置映射规则;如果没有,则需定义目标表的Schema和表名,以及必要的字段映射和类型转换规则。例如,定义目标Schema名为holo_dataset,表名为holo_table。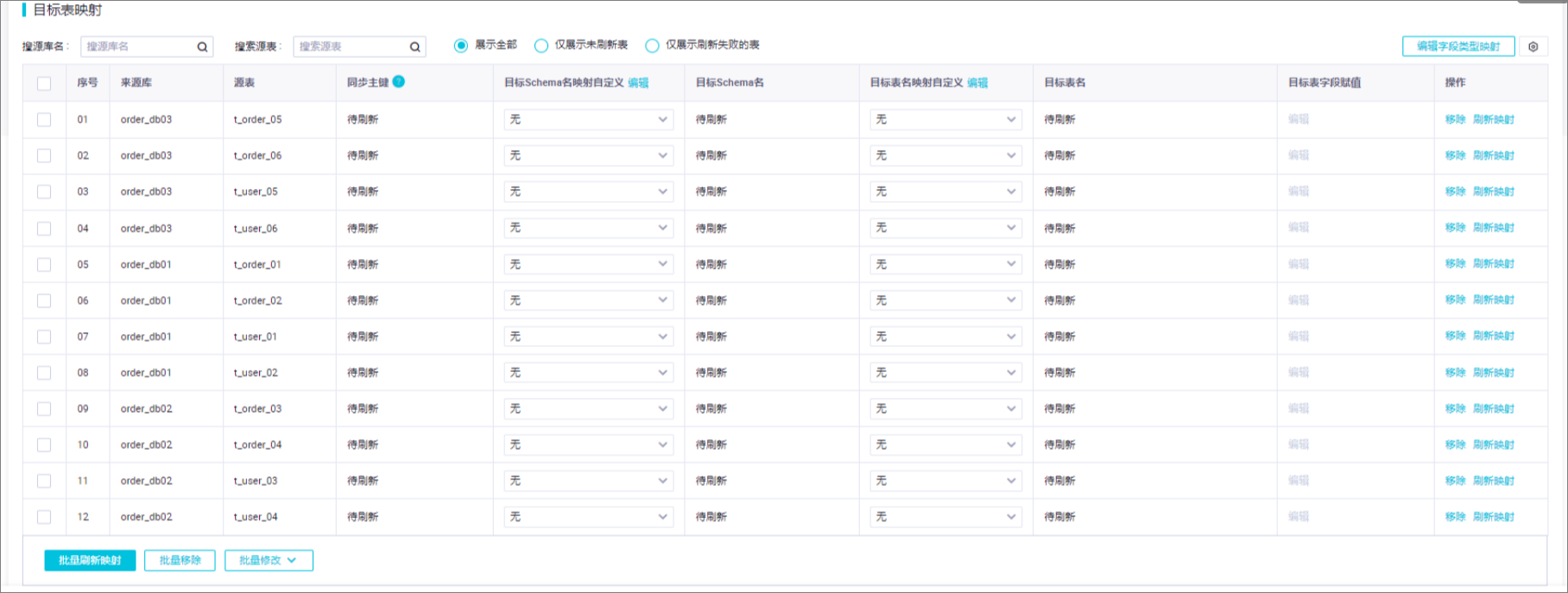
可以利用正则表达式匹配源表名,将数据写入到相应的逻辑表中,如将符合特定模式的表数据写入到预设的Hologres表中。
网络与资源配置:
高级设置与验证:
通过以上步骤,您可以实现从MaxCompute中通过自定义SQL提取数据,并将其写入到Hologres中,满足特定的数据处理和分析需求。
在目标业务流程下,右键选择 新建资源 > MaxCompute > File,在弹出的新建资源对话框,单击新建。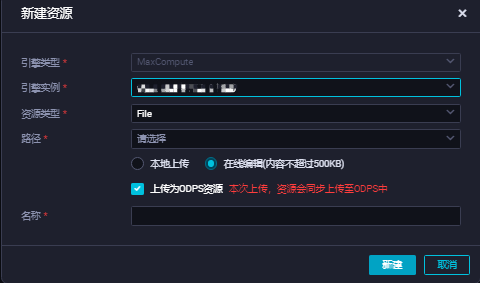
目标业务流程下,右键选择新建资源 > MaxCompute > Python,在新建资源对话框,填写资源名称后,单击新建。比如讲将资源名称命名为read_holo.py。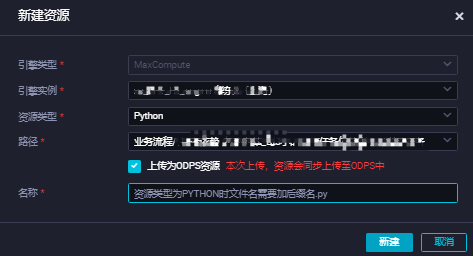
在目标业务流程下,右键选择新建节点 > ODPS Spark,在新建节点对话框,填写节点名称后,单击确认。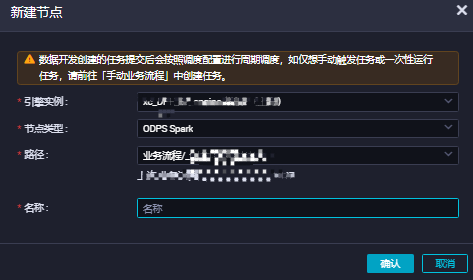
在目标业务流程画板,右键选择spark_read_holo > 运行节点。
作业运行后,将会打印作业日志,其中包含MaxCompute作业的诊断信息、Logview链接地址、Spark-UI的Jobview链接地址等。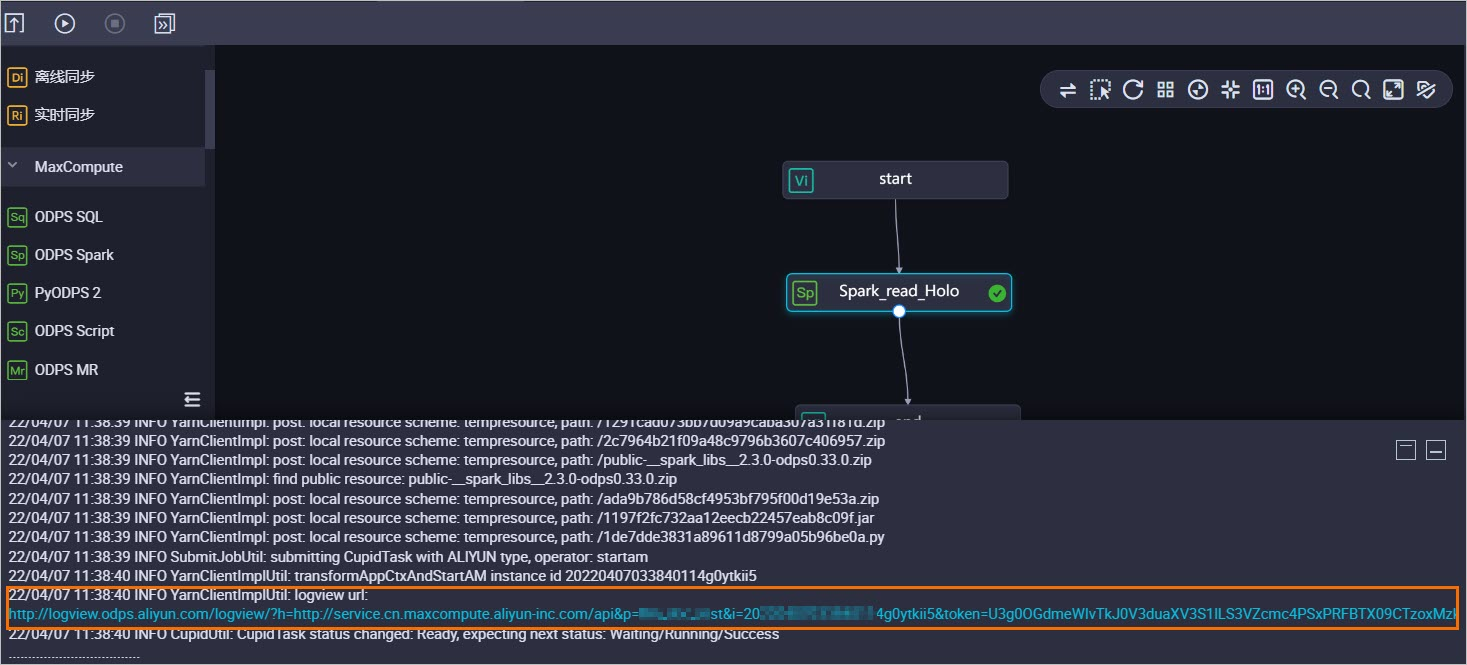
——参考链接。
准备数据源:
MaxCompute数据源配置:确保您的DataWorks项目已配置了MaxCompute数据源,用于数据提取。
Hologres数据源配置:同样,配置Hologres数据源,确保网络与权限设置正确,以便数据写入。这包括访问ID、访问Key以及正确的Endpoint等信息
创建数据同步任务:
登录DataWorks控制台,进入 数据集成 页面。
点击 创建同步任务 ,选择 自定义SQL 作为数据来源类型,而不是直接选择表。
配置自定义SQL提取:
在任务创建界面,编写SQL查询语句以从MaxCompute中提取所需数据。例如,如果您想提取某一天的数据,SQL可能类似于:SELECT * FROM your_mc_table WHERE dt = '2023-04-01'。
确认SQL正确无误后,继续进行下一步配置。
配置Hologres为目标端:
在任务配置中,指定Hologres作为目标数据源。
选择或自定义目标表名和Schema名,确保与Hologres中的表结构相匹配。如果需要,可以应用之前提到的表名和Schema名映射规则
字段类型映射与冲突处理:
检查并配置源表字段与目标表字段之间的类型映射,确保数据类型兼容。DataWorks提供了默认映射规则,但您也可以根据需要自定义
。
设置冲突处理模式(如Replace, Update, Ignore),根据业务需求决定如何处理已存在数据的更新问题。
网络与资源配置:
确保任务配置中的网络设置正确,选择合适的数据源和资源组。对于整库实时同步任务,至少需要配置2CU资源
。
测试数据源与资源组的连通性,确保网络畅通无阻。
预检查与启动任务:
在完成所有配置后,进行预检查,确认无误。
最后,启动数据同步任务,观察任务执行日志,监控数据同步进度与状态
这个步骤哈:
创建数据源:首先,确保您已经在DataWorks中创建了MaxCompute和Hologres的数据源。您可以通过DataWorks的数据源管理页面进行创建和管理
。
编写自定义SQL:在DataWorks的数据开发模块中,创建一个SQL节点,编写您的自定义SQL查询,以从MaxCompute中提取所需的数据。
创建数据集成任务:使用DataWorks的数据集成模块,创建一个新的数据同步任务。在这个任务中,配置源为MaxCompute,目标为Hologres,并使用您编写的自定义SQL作为数据来源
。
配置Hologres数据源:在数据集成任务中,确保您配置了正确的Hologres数据源,并设置了目标表的名称和结构,以便数据可以正确写入
。
任务调度与执行:配置好数据同步任务后,您可以设置任务的调度策略,并启动任务以执行数据同步。在任务执行过程中,您可以监控任务的状态和进度
编写自定义SQL查询以从MC中提取所需的数据,运行任务以执行SQL查询并将结果写入Holo。
参考文档https://help.aliyun.com/zh/dataworks/user-guide/sql-query?spm=a2c4g.11186623.0.i61
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


