DataWorks表管理中 主题管理、层级管理、物理分类设置好后 怎么批量设置表呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
进入表管理
进入数据开发。
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的数据建模与开发 > 数据开发,在下拉框中选择对应工作空间后单击进入数据开发。新建、查找及编辑目标表
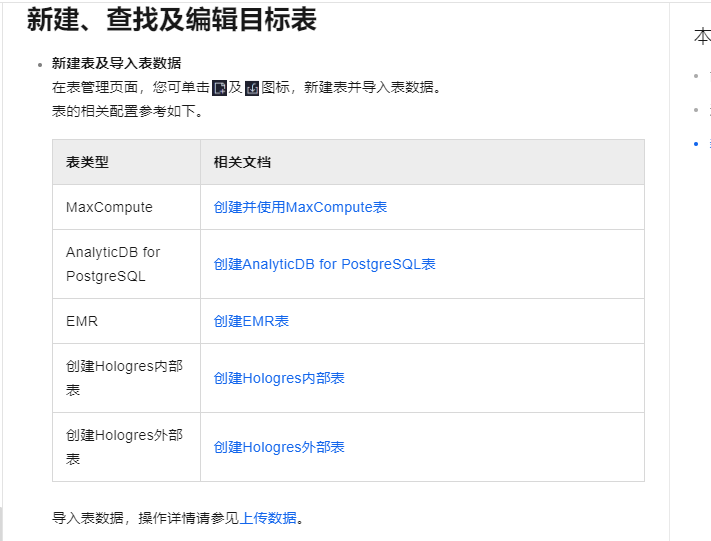
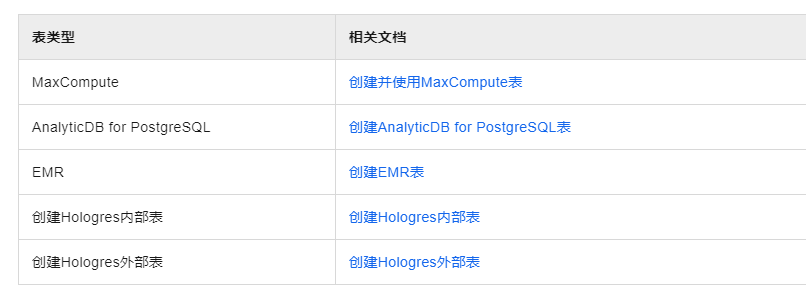
新建表及导入表数据
在表管理页面,您可单击新建及导入图标,新建表并导入表数据。
表的相关配置参考如下。
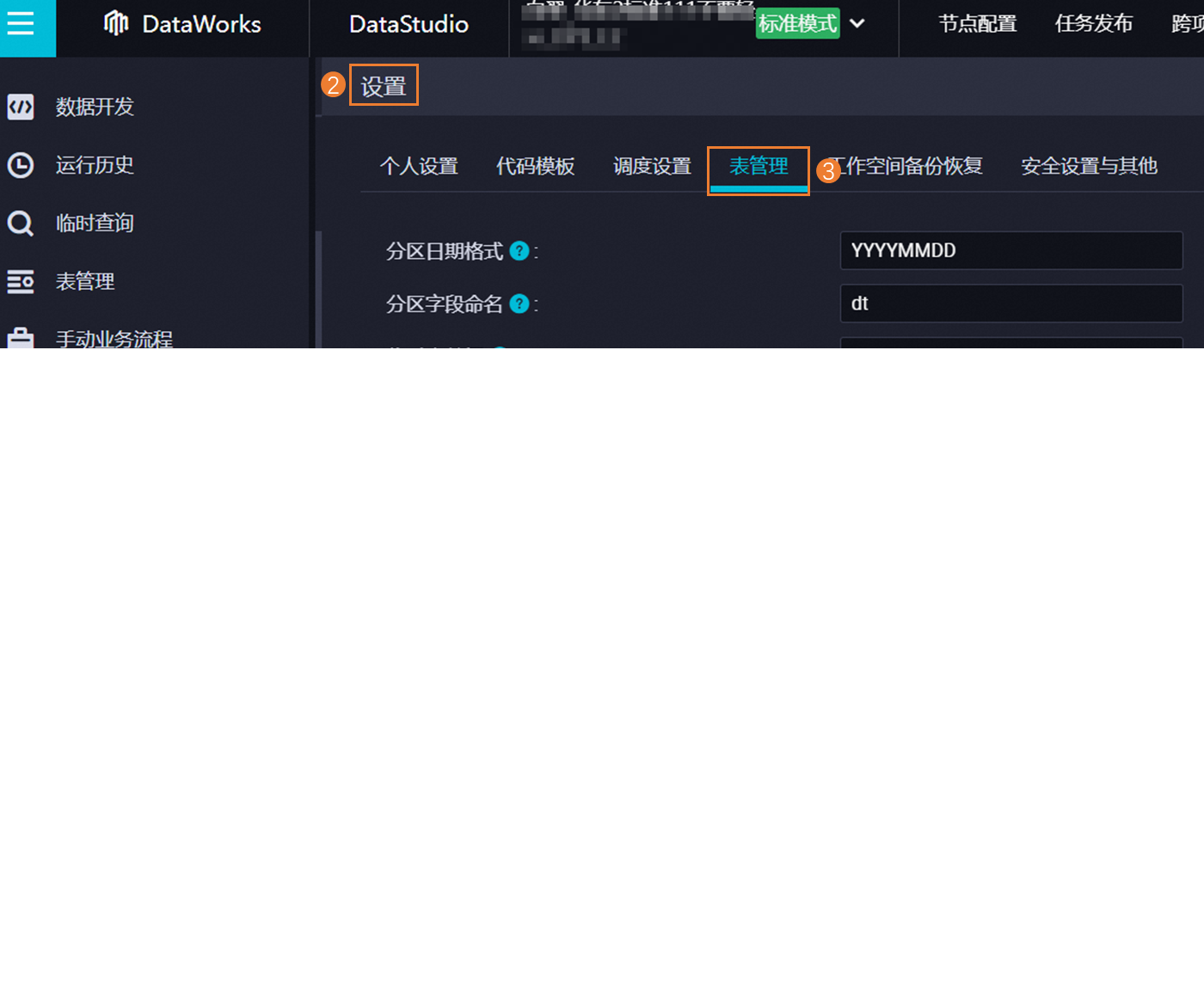
在左侧导航栏单击表管理。
在DataWorks中,如果您已经完成了主题管理、层级管理以及物理分类的设置,想要批量地将现有表格应用这些设置,可以通过以下步骤操作:
进入表管理界面:
筛选和选择表:
批量编辑表属性:


这样,您就可以高效地完成大量表格的主题、层级和物理分类的批量设置了。
相关链接
https://help.aliyun.com/zh/dataworks/user-guide/manage-settings-for-tables
在表管理界面,可以利用搜索框、筛选条件或直接浏览来定位到您想要批量操作的表。比如,根据表名前缀、所在项目或其它属性筛选出一系列需要调整的表。
在批量编辑或设置界面中,您可以为这些表指定或修改 主题 、 层级 以及 物理分类 。确保所选的分类与您的管理需求相匹配。
在DataWorks中,批量设置表的主题、层级和物理分类的方法涉及到表管理功能的正确使用。以下将详细介绍如何在DataWorks中批量设置表的各个方面:
使用限制和进入表管理
权限要求:只有空间管理员或项目所有者可以定义表格式、主题及层级。如果需要帮助进行操作,可以授权目标账号相应的角色权限。
进入数据开发页面:登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的“数据建模与开发 > 数据开发”,在下拉框中选择对应的工作空间后进入数据开发。
进入表管理:在数据开发页面,按照指引进入表管理的设置页面,在该页面可以定义表格式、主题和层级。
定义表相关格式
分区日期格式:用于设置分区表进行分区时的日期格式,默认为YYYYMMDD。
分区字段命名:建议使用dt作为分区字段的标识。
临时表前缀:临时表的前缀标识,默认前缀为t,符合该前缀的临时表将不会被纳入自动解析。
上传表(导入表)前缀:示例表的前缀为upload,用于标识上传或导入至DataStudio的表。
定义表主题
创建主题:在表管理页面,添加新主题或修改、删除已有主题。若父主题选择根主题则创建的是一级主题;若选择已有主题,则为子主题。支持最多创建两级主题。
挂载表至主题:主题定义完成后,在创建表时,可选择将目标表挂载至相应主题下。不同工作空间的表类型包括MaxCompute、AnalyticDB for PostgreSQL等。
定义表层级和物理分类
设计表层级:通常可划分为数据引入层ODS(Operational Data Store)、公共维度层DIM(Dimension)、明细数据层DWD(Data Warehouse Detail)、汇总数据层DWS(Data Warehouse Summary)、应用数据层ADS(Application Data Service),以更好地组织、管理和数据维护。
设计物理分类:基于业务视角对表进行更详细的分类,例如基础业务层、高级业务层等。
批量设置表属性
批量操作步骤:通过表管理界面,先过滤出需要批量设置的表,多选这些表后进行批量操作。在批量操作界面,可以统一设置选中表的主题、层级和物理分类。
注意事项:确保所有被批量操作的表均符合新的设置条件,避免因错误分类影响后续数据处理。
后续操作和维护
查找和编辑表信息:在表管理页面,可以通过表主题或引擎元数据查看展示目标表。通过引擎类型、表名称、环境信息等筛选并自定义显示顺序,快速找到目标表进行按需展示和编辑。
提交变更生效:对表进行的编辑需提交至相应环境,修改操作才会生效。这适用于各种表类型,如MaxCompute、AnalyticDB for PostgreSQL等。
综上所述,在DataWorks中批量设置表的主题、层级和物理分类主要通过表管理功能实现。需要注意权限要求、正确定义各类参数,并通过批量操作界面统一进行设置。同时,要确保后续操作和维护的顺利进行,以便有效管理数据表。
在DataWorks中,为了更好地管理和组织大量的数据表,你可以使用主题管理、层级管理和物理分类等功能。这些功能可以帮助你对表进行分组和分类,从而使得数据管理更加有序。当你已经设置了主题、层级和物理分类之后,批量设置表的过程通常涉及以下几个步骤: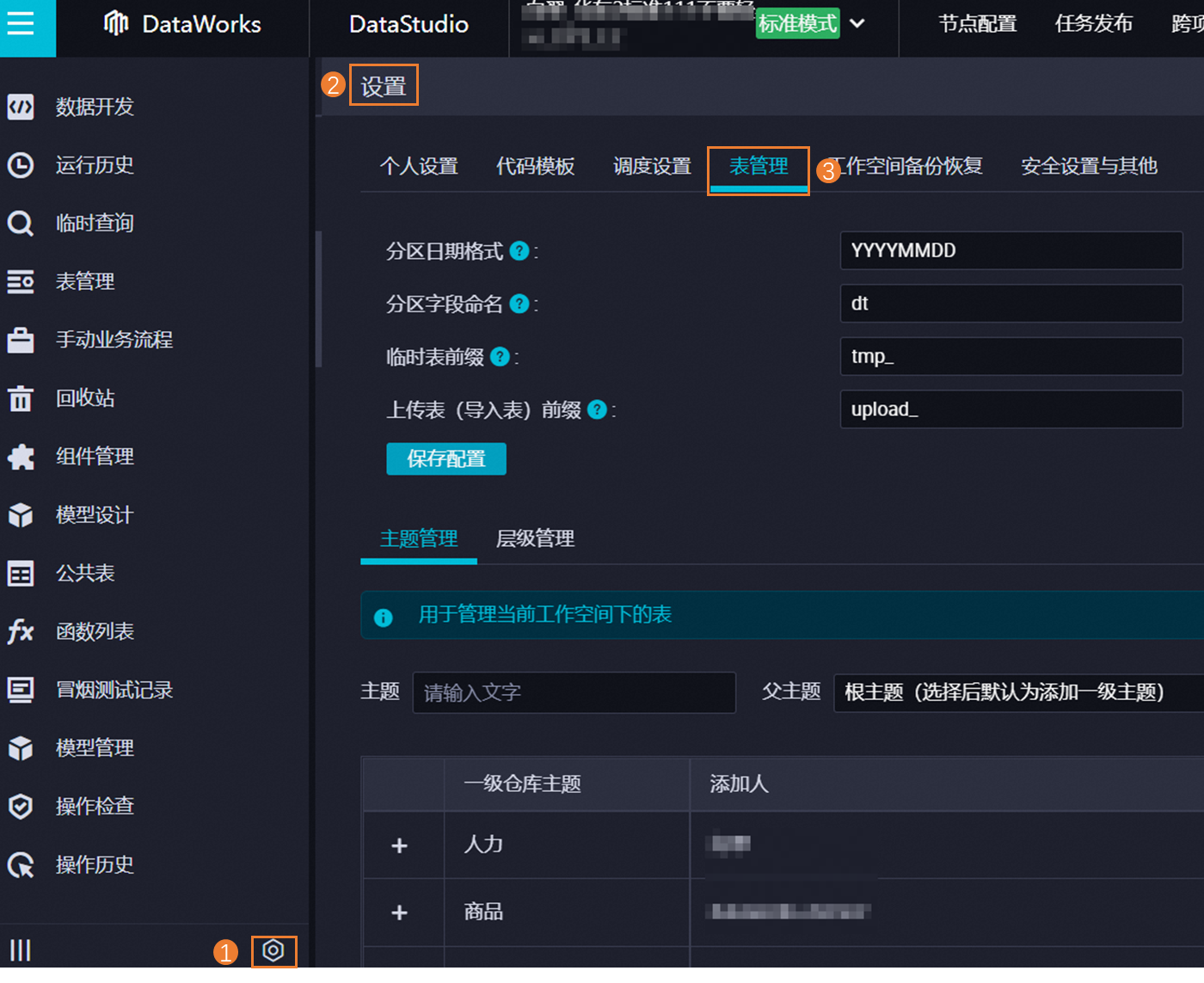
首先,你需要准备一个包含所有表信息的文件,如CSV文件或Excel表格,其中应该包括表的基本信息(如表名、描述等),以及与之关联的主题、层级和物理分类等信息。
DataWorks提供了批量导入表的功能,你可以通过上传之前准备好的文件来批量创建表,并且同时指定表的所属主题、层级和物理分类。
如果表已经存在,但是需要批量修改它们的主题、层级和物理分类,你可以尝试使用DataWorks提供的批量修改表属性的功能。通常,你可以在表管理界面找到这样的选项。
对于更高级的需求,你可以利用DataWorks的API来实现自动化批量设置表的功能。通过编写脚本或程序,调用相应的API接口来更新表的元数据,包括它们的主题、层级和物理分类等。
假设你已经有了一个CSV文件 tables.csv,其中包含了表名、主题、层级和物理分类等信息,你可以尝试以下方法来批量设置这些表的属性:
导入CSV文件:
使用API:
table_name,theme_name,level_name,physical_category
user_profile,User,Public,Bronze
order_details,Order,Public,Silver
...
import csv
import requests
# 假设这是你的DataWorks API端点
api_endpoint = "https://your_dataworks_api_endpoint.com"
api_key = "your_api_key"
def update_table_properties(table_name, theme, level, physical_category):
url = f"{api_endpoint}/tables/{table_name}"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
data = {
"theme": theme,
"level": level,
"physical_category": physical_category
}
response = requests.put(url, json=data, headers=headers)
if response.status_code == 200:
print(f"Updated properties for table {table_name}")
else:
print(f"Failed to update table {table_name}: {response.text}")
with open('tables.csv', mode='r') as file:
csv_reader = csv.DictReader(file)
for row in csv_reader:
update_table_properties(row['table_name'], row['theme_name'], row['level_name'], row['physical_category'])
请注意,上述示例代码仅供参考,实际使用时需要根据DataWorks提供的具体API文档进行调整。
如果你需要进一步的帮助或者有其他具体问题,请随时告诉我。
在DataWorks中,一旦完成了主题管理、层级管理以及物理分类的设置,若需批量更新现有表的这些属性,可以通过以下步骤操作: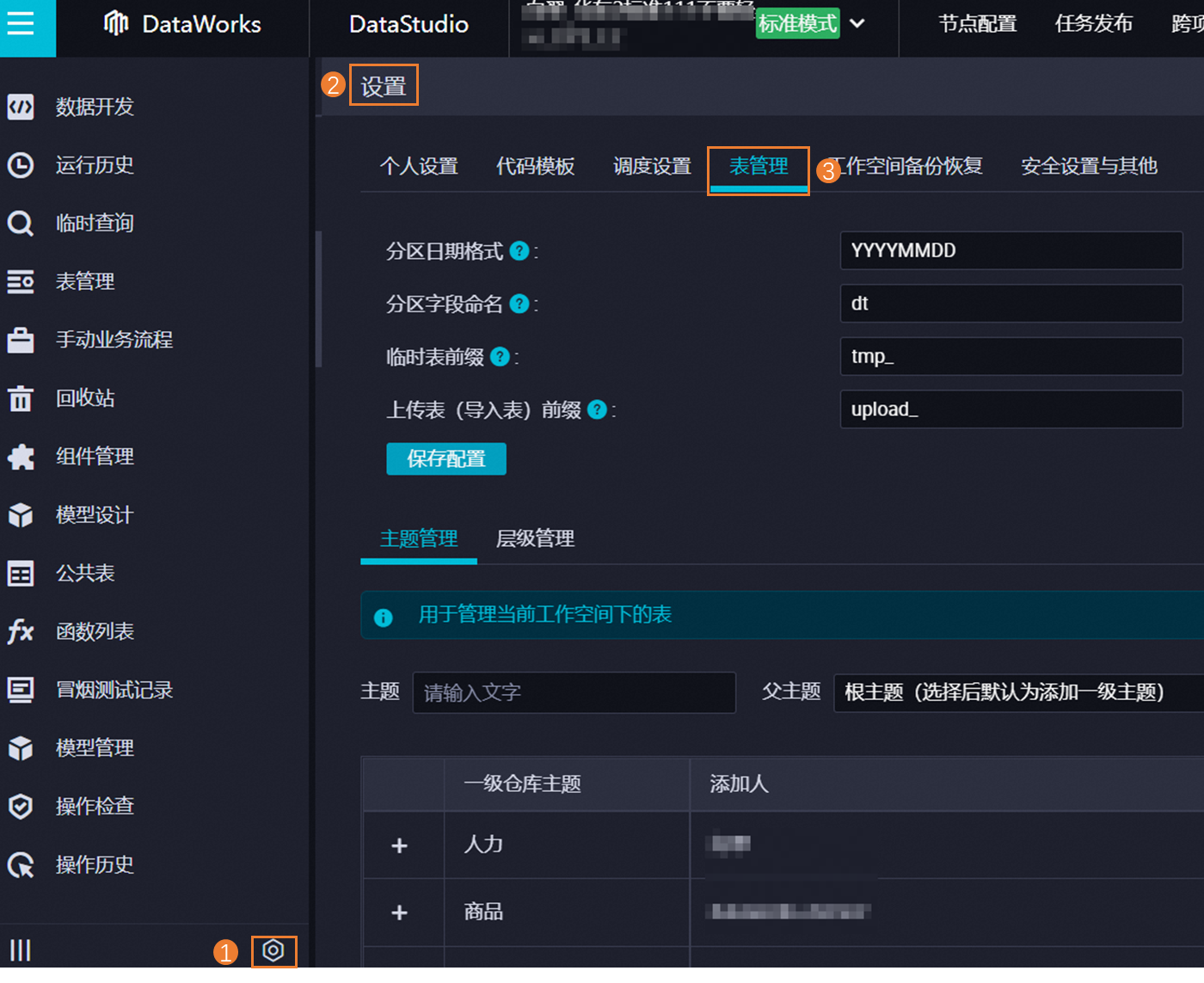
进入表管理界面:
筛选目标表:
批量编辑表属性:
执行脚本或任务:
验证结果:
使用脚本任务批量更新表元数据:
创建一个 数据开发 任务,选择合适的脚本类型(如MaxCompute SQL、Python等)。
编写脚本以编程方式更新表的元数据信息,如修改表的主题、层级和物理分类。这通常涉及到对DataWorks的元数据管理接口的调用或直接执行DDL语句调整表的注释信息(MaxCompute中可以使用ALTER TABLE语句的COMMENT选项来添加描述信息,间接实现分类标记)。
在脚本中循环遍历需更新的表列表,为每张表执行相应的更新操作。
按模板(批量)
单击目标表名右侧的按钮,在弹出的批量设置分区表达式页面输入分区表达式,单击确认。数据质量将通过表配置的分区表达式来匹配调度节点每天产出的表分区。如果您需要批量为表配置分区表达式,则可以单击设置分区表达式按钮为选中的表批量添加分区表达式。
参考文档https://help.aliyun.com/zh/dataworks/user-guide/configure-monitoring-rules-based-on-a-monitoring-rule-template?spm=a2c4g.11186623.0.i232
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。