DataWorks提交任务到 emr 集群跑的时候,在哪里可以设置内存资源?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中提交任务到EMR集群运行时,内存资源的配置通常在任务的执行配置中进行设定:
进入任务配置:在创建或编辑DataWorks中的任务时,找到任务的执行配置部分。
设置资源配置:在资源配置或作业配置区域,您应该能找到与内存相关的设置项,比如为Spark作业设置executor-memory和driver-memory参数,或者为MapReduce作业设置相应的内存限制。
依据需求调整:根据您的任务实际需求和EMR集群的可用资源,合理设置内存大小,以确保任务既能高效运行又不致资源浪费。
在DataWorks中提交任务到EMR集群运行时,设置内存资源主要取决于您使用的组件,如Spark或Kyuubi等。以下是针对不同组件的内存配置指导:
spark-submit命令行中添加相应的参数来调整这些配置,以达到合适的内存分配。spark-submit命令提交任务时,可以在命令中显式指定这些内存配置项。相关链接
DataWorks on EMR集群配置最佳实践 背景信息 https://help.aliyun.com/zh/dataworks/user-guide/best-practices-for-configuring-emr-clusters-used-in-dataworks
可以在作业的配置文件中(如spark-defaults.conf)设置内存相关的参数,例如spark.executor.memory来指定每个执行器的内存大小。
在编写脚本时,可以在脚本内部设置内存使用限制。例如,在编写Python脚本时,可以使用multiprocessing模块的set_executable()函数来限制进程的内存使用。
DataWorks中提交的任务如果运行在EMR集群上,内存资源的设置通常与您配置的EMR集群本身相关。在EMR集群创建时,您需要根据任务需求选择合适的组件版本和实例规格,这些规格会决定任务可用的内存资源。在DataWorks中,您一般无法直接为单个任务配置内存资源,而是依赖于EMR集群的配置。如果您需要调整任务的内存资源,通常需要通过以下方式:
创建或更新EMR集群:在EMR控制台上,您可以创建或更新集群配置,选择具有更多内存的实例类型,或者增加集群中实例的数量。
任务优化:优化任务代码,例如在Spark任务中设置合适的executor-memory和driver-memory参数,或者在Hadoop MapReduce任务中配置mapreduce.map.memory和mapreduce.reduce.memory。
使用独享调度资源组:DataWorks支持使用独享调度资源组,这样可以为特定的工作流或任务分配固定资源,但这需要在DataWorks的调度配置中完成,而不是直接设置任务内存。
可参考文档
在DataWorks提交任务到EMR集群运行时,可以在任务配置或节点配置中设置内存资源。
这些配置决定了任务执行时所使用的计算资源,包括CPU和内存等。合理地配置这些资源对于任务的高效执行至关重要。以下将详细分析如何在DataWorks上为EMR任务配置内存资源。
任务配置中设置内存资源
调整资源组:在DataWorks控制台的任务配置页面中,通常会有一个资源组的选项。选择合适的资源组,该资源组应包含足够的内存资源以满足任务需求。新版的通用型资源组可以满足多种任务类型的场景应用,而旧版独享资源组可能需要根据具体任务类型进行选择。
调整内存参数:在某些情况下,可以直接在任务配置中调整内存参数,如设置JVM的内存大小等。这取决于具体的任务类型和EMR集群的配置。
节点配置中设置内存资源
配置节点资源:在EMR集群的配置中,可以设置每个节点的资源,包括CPU和内存等。这些设置将影响在EMR集群上运行的所有任务。例如,对于Spark任务,可以使用--executor-memory参数设定Executor的内存大小,如--executor-memory 2G。
调整节点内存:根据需求,调整节点的内存大小。这可能需要重新配置EMR集群或添加新的节点。
组件配置中设置内存资源
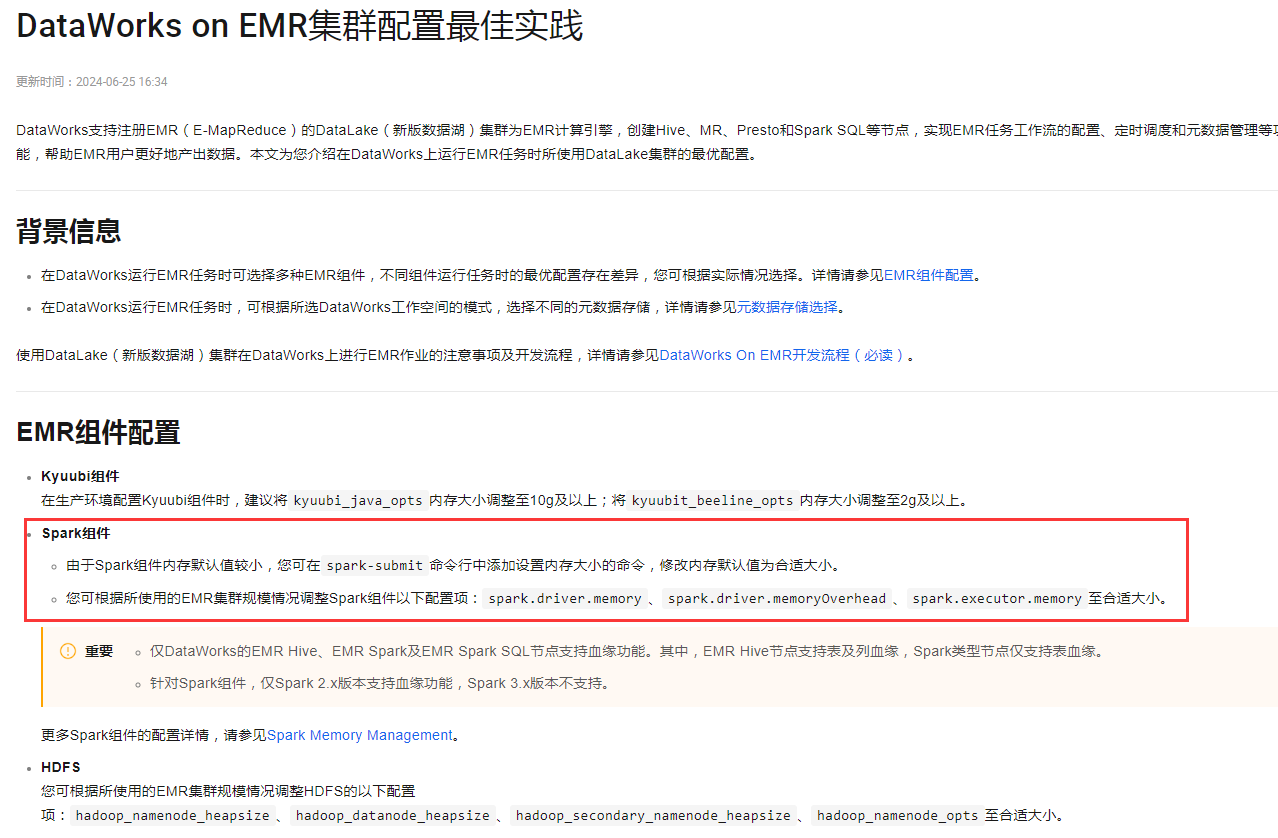
Kyuubi组件:建议在生产环境中将kyuubi_java_opts内存大小调整至10GB及以上,同时将kyuubi_beeline_opts内存大小调整至2GB及以上。
Spark组件:除了可以在spark-submit命令行中设置内存大小,还可以在创建EMR Spark节点时,在高级参数中直接追加自定义Spark参数,如"spark.executor.memory" : "2g"。
HDFS组件:可以调整HDFS的内存配置项,如hadoop_namenode_heapsize、hadoop_datanode_heapsize等,以适应不同的EMR集群规模。
注意事项
资源限制:在设置内存资源时,不要超出EMR集群或DataWorks资源组的限制。
性能优化:合理配置内存资源可以提高任务的执行效率,但过多的内存分配也可能导致资源浪费。因此,请根据任务需求和EMR集群的性能进行权衡。
综上所述,在DataWorks提交任务到EMR集群时,可以通过任务配置、节点配置以及特定组件的配置来设置内存资源。这些配置需要根据实际情况进行调整,以确保任务能够高效且稳定地运行。
在DataWorks提交任务到EMR(E-MapReduce)集群运行时,设置内存资源通常是在任务配置或节点配置中进行的。不过,具体的设置方式可能会因DataWorks的版本和EMR集群的配置而有所不同。以下是一些一般性的指导步骤,供您参考:
一、任务配置中设置内存资源
进入DataWorks控制台:首先,登录到阿里云DataWorks控制台。
选择工作空间和项目:在控制台中,选择您的工作空间和项目。
创建或编辑任务:在数据开发或任务调度页面中,创建新的任务或编辑现有任务。
设置资源组:在任务配置中,通常会有资源组的选项。资源组是用来控制任务执行时所使用的计算资源的,包括CPU、内存等。选择合适的资源组,该资源组应包含足够的内存资源以满足您的任务需求。
调整内存参数(如果可用):在某些情况下,DataWorks可能允许您直接在任务配置中调整内存参数,如设置JVM的内存大小等。这取决于具体的任务类型和EMR集群的配置。
二、节点配置中设置内存资源
如果您是在EMR集群上运行特定的计算节点(如Spark、Hive等),则可能需要在节点配置中设置内存资源。
进入EMR控制台:登录到阿里云EMR控制台,找到并管理您的EMR集群。
配置节点资源:在EMR集群的配置中,您可以设置每个节点的资源,包括CPU、内存等。这些设置将影响在EMR集群上运行的所有任务。
调整节点内存:根据您的需求,调整节点的内存大小。这可能需要重新配置EMR集群或添加新的节点。
三、注意事项
资源限制:在设置内存资源时,请确保不要超出EMR集群或DataWorks资源组的限制。
性能优化:合理配置内存资源可以提高任务的执行效率,但过多的内存分配也可能导致资源浪费。因此,请根据您的任务需求和EMR集群的性能进行权衡。
文档和社区资源:阿里云官方文档和开发者社区是获取最新信息和解决问题的好去处。如果遇到问题,请查阅相关文档或寻求社区的帮助。
请注意,由于DataWorks和EMR的功能和界面可能会随着版本更新而发生变化,因此上述步骤仅供参考。在实际操作中,请根据您所使用的DataWorks版本和EMR集群配置进行相应的调整。
在DataWorks提交任务到EMR集群运行时,内存资源配置可以通过以下几个方面进行设置:
kyuubi_java_opts内存大小调整至10GB及以上,同时将kyuubi_beeline_opts内存大小调整至2GB及以上。Spark组件配置:
spark-submit命令行参数调整。例如,可以使用--executor-memory来设定Executor的内存大小,如--executor-memory 2G。spark.driver.memoryspark.driver.memoryOverheadspark.executor.memoryHDFS配置:
hadoop_namenode_heapsizehadoop_datanode_heapsizehadoop_secondary_namenode_heapsizehadoop_namenode_optsDataWorks界面配置:
"spark.eventLog.enabled" : false,这些配置会被自动转换为--conf key=value的形式应用于任务中。综上所述,内存资源的设置既可以通过直接修改EMR集群中组件的配置文件(如Kyuubi和Spark的配置),也可以在DataWorks任务提交时通过命令行参数或界面提供的高级配置选项进行调整。确保根据实际工作负载和资源需求合理配置,以达到最佳性能。
在阿里云DataWorks中创建表不成功可能由多种原因造成。以下是一些常见的原因及其解决方法:
如果您使用DataWorks控制台创建表时遇到问题,可以尝试直接在MaxCompute中执行DDL(数据定义语言)语句来创建表。以下是一个简单的示例:
CREATE TABLE IF NOT EXISTS my_table (
id INT,
name STRING,
age INT
);
如果在DataWorks控制台中创建表失败,您可以尝试以下步骤:
如果您能提供具体的错误信息,我可以帮助您更准确地诊断问题所在。
在DataWorks中提交任务到EMR集群运行时,设置内存资源通常涉及到对EMR集群的组件配置。对于不同的组件,如Kyuubi或Spark,需要调整对应的配置参数以确保任务运行时有足够的内存资源。
对于Kyuubi组件,在生产环境配置时,建议将kyuubi_java_opts内存大小调整至10g及以上,并把kyuubi_beeline_opts内存大小调整至2g及以上
。对于Spark组件,由于默认内存值可能较小,可以在spark-submit命令行中添加设置内存大小的命令来修改默认值。此外,根据EMR集群的规模,可以调整spark.driver.memory、spark.driver.memoryOverhead、spark.executor.memory等配置项至合适的大小
可以从这几个方面来设置配置:
Spark组件配置:
通过spark-submit命令行,您可以添加参数来调整内存大小,例如--executor-memory 2G来设定Executor内存。
根据任务需求,调整以下Spark配置参数至合适大小:
spark.driver.memory: 设定Driver的内存大小。
spark.driver.memoryOverhead: 设定Driver额外的内存开销。
spark.executor.memory: 设定每个Executor的内存大小。
Kyuubi组件配置(如果适用):
在生产环境中,建议将kyuubi_java_opts内存大小调整至10GB或以上,以及将kyuubi_beeline_opts内存大小调整至2GB或以上。
通过EMR Spark节点的高级参数配置:
在创建EMR Spark节点时,可以在高级参数配置中直接追加自定义Spark参数,例如"spark.eventLog.enabled" : false,DataWorks会自动转换为命令行参数形式下发到集群。
利用“queue”参数选择合适的YARN调度队列,以及通过“priority”设定任务的优先级,间接影响任务的资源分配
节点中使用资源
创建完成EMR JAR资源后,如果您需要在节点中直接使用资源,您需要右键资源,选择引用资源,引用方式如下图所示。
说明
节点中引用资源后,会自动添加一条@resource_reference{"resourcename},表示节点内已经引用该资源。
详细的引用操作步骤可参见创建EMR MR节点。
参考文档https://help.aliyun.com/zh/dataworks/user-guide/create-and-use-an-emr-jar-resource?spm=a2c6h.13066369.question.5.594d555dMYNGtj
创建EMR资源
进入数据开发页面。
登录DataWorks控制台。
在左侧导航栏,单击工作空间列表。
选择工作空间所在地域后,单击相应工作空间后的快速进入 > 数据开发。
鼠标悬停至新建图标,单击新建资源 > EMR > EMR JAR或EMR File。
您也可以找到相应的业务流程,右键单击EMR,选择新建资源 > EMR > EMR JAR或EMR File。
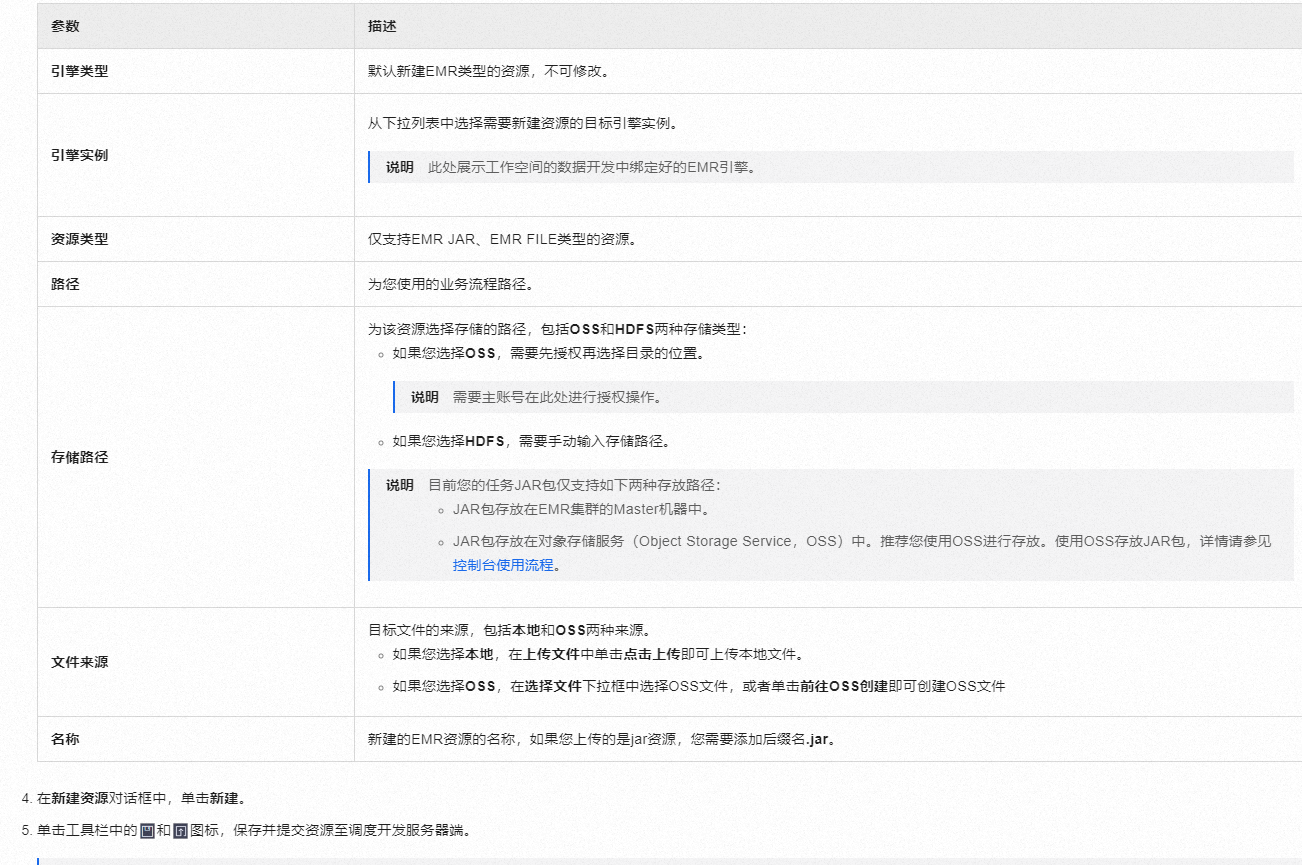
在新建资源对话框中,配置各项参数。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。